







A Benchmark on Tricks for Large-scale Image Retrieval
摘要
文中主要介绍,一些预处理和post-处理的一些trick,在不改变网络结构或者度量的前提下,单独使用这些trick或者综合使用这些trick,能够较好的提升大规模图像检索的表现。
简介
目前应用在图像检索中的,度量技术受到很多关注,很多文章根据改变网络结构,改变loss函数。在小的验证集合中进行验证证明有效性,这样的做法是不全面的因为小的验证集并不能很好的验证网络。所以对于大规模图像检索验证有效性很有必要。
本文主要分析大规模检索中一些trick的有效性。使用一个简单的网络并在这个网络上加入各种trick,通过各种实验来验证trick以及trick组合的有效性,本文的主要贡献如下
- 通过大规模图片检索实验,我们分析了预处理以及post-processing的影响,。
- 通过对多个trick的组合,能够显著的提升模型的检索能力。
预处理的trick
在大规模数据集中验证,有许多的问题需要考虑其中最重要的两点是。第一,如何消除大规模数据集的噪音。 第二, 如何快速的评估运算,因为大规模数据集需要大量运算与显存。
- 训练数据的清洗
数据清洗的目的在于,最大化类间的变化以及最小化类内的变化。使用DBSCAN算法进行聚类,根据生成的质心是那种不同形式的数据集(TR1, TR2, TR3)被构建。
TR1
通过视觉检测发现GLD v1是噪音小可信度高的数据集合,使用数据进行训练。为了能够进行半监督学习,训练模型出去出测试集合的feature,然后使用DBSCAN聚类,每一个类别作为新的虚拟标签。
TR2
由于GLD v2有很多的诱导图片,比如文档,肖像以及自然景观,在训练阶段使用这些图片,这样使得噪音和真正的关键点在嵌入空间有较大的的差别,然后将这些诱导数据再做聚类,然后将这些诱导类别和TR1相结合。这样就有了集合TR2
TR3
使用二分类网络剔除GLD v2中的风景图片,然后将图片中的每个类进行聚类,选择类别最多的那个质心类,摒弃其他的质心类。
- 小规模的验证
验证阶段主要是为了节省时间,但是测试集合又需要反映出数据分布,从训练集合中抽取2%,分别为测试集合和索引集合。然后包含一个噪音类的虚拟簇,这是因为GLD v2包含有噪音,这样分布能够更加的贴合数据集。
试验结果

第一列表示没有清洗过的图片含有大量噪音,第二列是经过DBSCAN清洗过的含有的噪音较少。
对三种数据进行试验结果如下
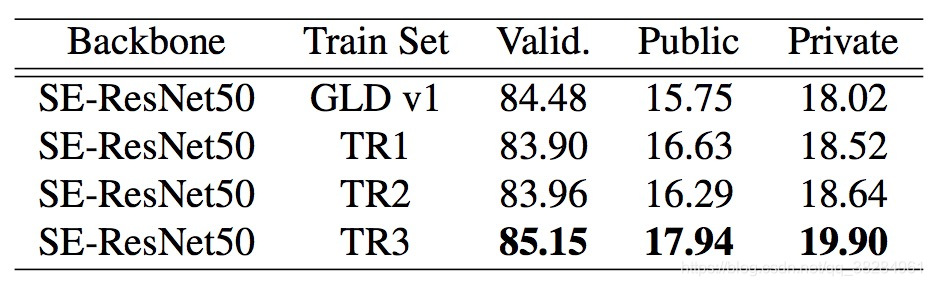
通过试验发现,数据净化能够提升准确率。
学习表达方式
这部分主要关注如何将不同类别的pooling与loss function相结合,在post-processing阶段进行特征融合。
- Pooling方法
一般的对最后一层feature map获取的pooling方法,对于模型的效果有着非常重要的影响,文中主要使用了三种方法,SPoC, MAC, GeM
- Objectives
文中设计了两种通用Loss集合的方法,不同的Loss组合能够促进模型的表达能力,有利于特征融合。
Xnet + Triplet
文中发现使用triplet 与分类Loss 交叉熵(Xent)能够对模型效果有较好的提升。
N-pair + Angular
使用配对的ranking Loss组合,例如N-pair + Angular。
使用trick后的结果展示
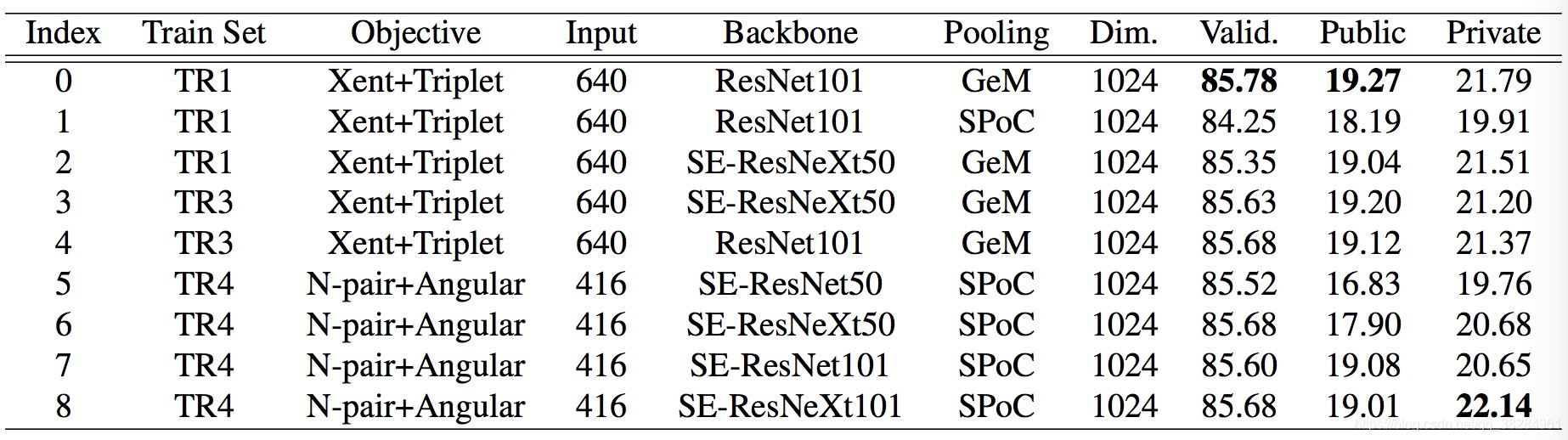
训练单一模型
- 对于N-pair + Angular模型,使用256 x 256 作为训练的输入图片,416 x 416作为推理阶段的输入。Xent + Triplet 模型,输入320 x 320 的像素作为训练阶段的图片输入,640 x 640是推理阶段的输入。输出维度都是1024维度。
- 在实验中发现MAC pooling是效果最差的池化。
- Xent Loss 对图片的质量比较敏感。
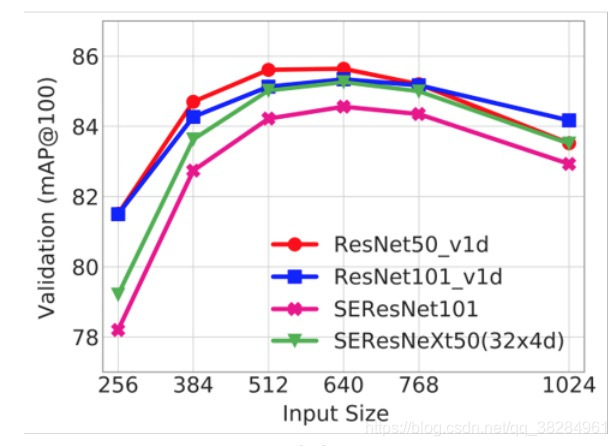
输入图片的大小对模型的影响
post-processing Tricks
这一部分主要介绍一些实例级图像检索的trick,包括特征融合,数据增强,查询扩张, reranking。尽管每一个trick在不同的研究中被证明是有效的。
文中主要研究将不同的trick组合到一起,对模型产生的影响。
多特征融合
特征融合主要是探讨什么样的特征融合后才能够很好的提升模型的能力,这一部分主要研究,是不是将表现最好的特征融合到一起后,模型能够在推理过程中得到真正的提升。
DBA 和 QE(扩展查询)-rerank的方法
数据增强主要是使用带权重的特征点以及KNN得到的前k个特征点相加代替每个特征点,DBA所做的事情就是这样的,其中权重w如下
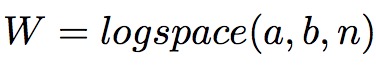
其中logspace函数,生成10a到10b 的n个点
和DBA 类似,查询扩展是一个有效的办法来增加图像检索的质量,通过或得一个查询的丰富表达。 首先从database中找出前k个与query最近邻的图片。然后将这些近邻向量与原始的query进行结合。这个处理过程需要重复必要的次数。最后融合的query被用于产生排序的检索图片,其中加总使用权重是w 来自于上面的w公式。
PCA白化
PCA白化将从DBA和QE产生的4096维度缩小到额1024维度。然后再使用一个L2正则化。
Reranking
当检索到k个图像,重新排序这些图片能够增加检索的准确度,与以往trick不同的是,只有在这k个检索图片中出现检索目标的时候才有效,下面主要介绍了两种不同的re-ranking的办法。
- 图搜索,Diffusion 这个方法可以促进小目标的检索效果,一般来说这个机制一般应用到最后一步。并且最大化分数。
- 局部匹配
试验结果
对尺度特征
多尺度特征实验中建议选择4~6个进行concat这样可以避免加大运算量。
DBA/QE 和 PCA白化
将DBA/QE 与PCA白化结合有两种方式,(1)对concat特征使用PCA降维后,跟上DBA/QE,(2)对每个特征使用DBA/QE,然后使用PCA白化方法。 文中的试验选择的是第二类方法,其中DBA和QE选择的k=1能够取得很好的效果。
附录一, pooling tricks
- SPoc Pooling, 首先需要一个sum pooling
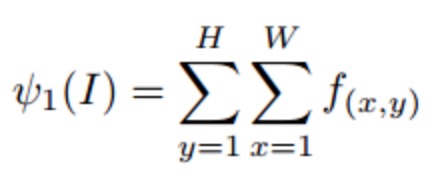
然后再给每一个像素加上高斯权重,加大图像中心部分的权重,使识别的注意力更加集中在图像的中心区域,淡化图像边缘信息。
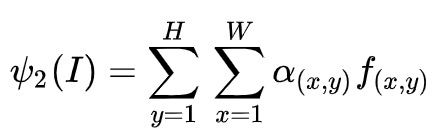
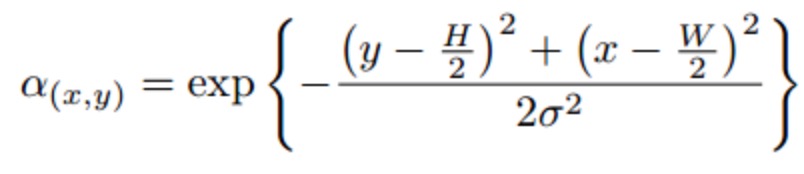
然后再进行PCA降低维, L2正则化
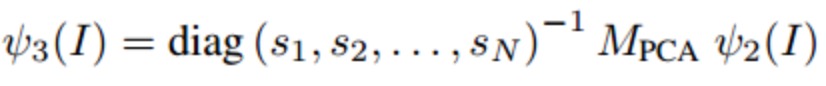
排名第三的队伍用的就是用到了这篇论文的方法。基于GoogLeNet-22,对最后的8层feature map,首先使用最大池化对这些不同尺度的特征图分别进行子采样转换成相同尺寸的特征图,再使用卷积对这些采样结果进一步处理。然后对这些特征图做线性加权,最后使用sum pooling得到最终的图像特征。
(2) MAC pooling 最大池化
说到MAC pooling就要说一下Mop pooling, 分成L=1,2,3。当L为1的时候输入整张图片256*256,输出的是4096的向量。当L为2的时候,输入为截取的128*128,输出还是4096,使用k-means聚类100个质心,然后将4096的维度降维成500维度,那么现在L=2 就有了50000个维度,然后在降维到4096即可。
与MOP pooling相似,但是MAC pooling滑窗是在feature map上进行滑动,而不像MOP一样是在原图上滑动。
如果L=3, 那么会有三种滑窗滑动feature map,与Mop使用VLAD不同的是,使用向量加和进行向量化。
(3)GeM pooling
介于最大pooling,平均pooling,之间的一个pooling形式
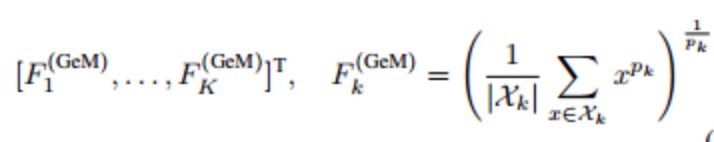
将每个channel的所有做Fk相关操作,然后范湖一个向量即可。
附录二 降维检索PCA白化
白化是一种重要的预处理过程,其目的就是降低输入数据的冗余性,使得经过白化处理的输入数据具有如下性质:(i)特征之间相关性较低;(ii)所有特征具有相同的方差。
经过PCA降低维度之后,然后再进行特征相同方差处理,既每一个维度需要除以方差,然后每一维度的方差都为1
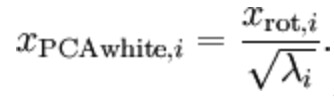
附录三 Loss function
(1)N-pair Loss
这个Loss 是对triplet loss的改进,不再像triplet loss一样,而是使用N-1个负样本,一个正样本,一个anchor。来进行计算,其计算公式如下
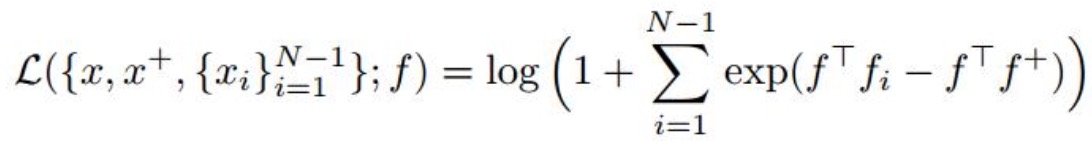
(2) Angular Loss
角度loss。
附录四 数据扩展方法
数据扩展分成了DBA/QA两种,其中DBA表示从训练集合中根据KNN选择出前k个近似的向量进行加权求和。而QE表示从query集合中根据KNN选择出前K个相似的向量进行加权求和。
附录五 Re-ranking方法

















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









