







为什么要进行内存对其?
(1) 性能原因:数据结构(尤其是栈)应该尽可能地在自然边界上对齐。原因在于,为了访问未对齐的内存,处理器需要作两次内存访问;而对齐的内存访问仅需要一次访问。
(2) 平台原因:不是所有的硬件平台都能访问任意地址上的任意数据的;某些硬件平台只能在某些地址处取某些特定类型的数据,否则抛出硬件异常。
(3) 空间原因:没有进行内存对齐的结构体或类会浪费一定的空间,当创建对象越多时,消耗的空间越多。
在 C/C++ 中,结构体/类是一种复合数据类型,其构成元素既可以是基本数据类型(如int、long、float等)的变量,也可以是一些复合数据类型(如数组、结构、联合等)的数据单元。编译器为每个成员按其自然边界(alignment)分配空间。各个成员按照它们被声明的顺序在内存中顺序存储,第一个成员的地址和整个结构的地址相同。
如果一个变量的内存地址正好位于它长度的整数倍,他就被称做自然对齐。如果在 32 位的机器下,一个int类型的地址为0x00000004,那么它就是自然对齐的。同理,short 类型的地址为0x00000002,那么它就是自然对齐的。char 类型就比较 "随意" 了,因为它本身长度就是 1 个字节。自然对其的前提下:
char 偏移量为sizeof(char) 即 1 的倍数
short 偏移量为sizeof(short) 即 2 的倍数
int 偏移量为sizeof(int) 即 4 的倍数
float 偏移量为sizeof(float) 即 4 的倍数
double 偏移量为sizeof(double) 即 8 的倍数 在设置结构体或类时,不考虑内存对齐问题,会浪费一些空间,例如实验一:
struct asd1{
char a;
int b;
short c;
};//12字节
struct asd2{
char a;
short b;
int c;
};//8字节上面两个结构体拥有相同的数据成员 char、short 和 int,但由于各个成员按照它们被声明的顺序在内存中顺序存储,所以不同的声明顺序导致了结构体所占空间的不同。具体如下图:


看到上面的第二张图,有的人可能会有疑问,为什么 short 不是紧挨着 char 呢?其实这个原因在上面已经给出了答案——自然对齐。为此,我们可以创建结构体验证自然对齐的规则。实验很简单,在原本 short 类型变量前后添加 char 类型,看结果是怎样的。实验二:
struct asd3{
char a;
char b;
short c;
int d;
};//8字节
struct asd4{
char a;
short b;
char c
int d;
};//12字节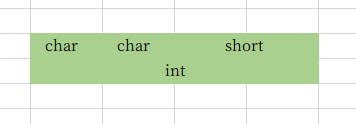
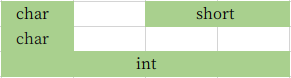
需要注意的一点
当数据成员中有 double 和 long 时,情况又会有一点变化。还是以上面的结构体 asd1 和 asd2 为基础,都添加 double 型数据成员。来看看结果是什么,实验三:
struct asd1{
char a;
int b;
short c;
double d;
};//24个字节
struct asd2{
char a;
short b;
int c;
double d;
};//16个字节只添加了一个 double,但 struct asd1 的大小从 12 变到了 24。而 struct asd2 的大小从 8 变到了 16。不需要迷惑,因为这和 double 的自然对其有关(需要注意)。原本的 asd1 占 12 个字节大小,但是 double 对齐需要是 8 的倍数,所以在 short 后面又填充了 4 个字节。此时,asd1 的占 16 个字节,再加上 double 的 8 个字节就成了 24 个字节。而 asd2 没有这个问题,它原本占 8 个字节。因为正好能对齐,所以添加 double 后占 16 个字节。具体情况如下图所示:


指定对齐值
在缺省情况下,C 编译器为每一个变量或是数据单元按其自然对界条件分配空间。一般地,可以通过下面的方法来改变缺省的对界条件:
使用伪指令 #pragma pack (n),C 编译器将按照 n 个字节对齐。
使用伪指令 #pragma pack (),取消自定义字节对齐方式。
实验四:
#pragma pack(4)
struct asd5{
char a;
int b;
short c;
float d;
char e;
};//20
#pragma pack()
#pragma pack(1)
struct asd6{
char a;
int b;
short c;
float d;
char e;
};//12
#pragma pack()使用 #pragma pack (value) 指令将结构体按相应的值进行对齐。两个结构体包含同样的成员,但是却相差 8 个字节。难道我们只需要通过简单的指令就能完成内存对齐的工作吗?其实不是的。上面的对齐结果如下:

以 32 位机器为例,CPU 取的字长是 32 位。所以上面的对齐结果会这样带来的问题是:访问未对齐的内存,处理器需要作两次内存访问。如果我要获取 int 和 float 的数据,处理器需要访问两次内存,一次获取 "前一部分" 的值,一次获取 "后一部分" 的值。这样做虽然减少了空间,但是增加访问时间的消耗。其实最理想的对齐结果应该是:

ps.使用 #pragma pack(4) 可以让前面的实验三中的 asd1 少占用 4 字节。
对齐原则
1. 数据类型自身的对齐值:对于 char 型数据,其自身对齐值为1,对于 short 型为2,对于 int,float,double 类型,其自身对齐值为 4,单位字节。(上面实验二已经验证过了)
2. 结构体或者类的自身对齐值:其成员中自身对齐值最大的那个值。
3. 指定对齐值:#pragma pack (value) 时的指定对齐值 value。
4. 数据成员、结构体和类的有效对齐值:自身对齐值和指定对齐值中小的那个值。



















 4302
4302

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











