






摘要:介绍梯度下降算法,以及在 f ( x ) f(x) f(x)的梯度 ▽ f ( x ) \bigtriangledown f(x) ▽f(x)满足L-Lipschitz条件下的梯度下降算法的意义,并由此展开的非光滑约束下的近端梯度下降算法,求解 min x f s ( x ) + f n ( x ) \min_x f^s(x)+f^n(x) minxfs(x)+fn(x)问题.
目录
- 梯度下降算法
- 二阶近似下的梯度下降算法
- 引入非光滑约束后的近端梯度下降
- 三个近端梯度下降计算非光滑约束优化的例子
1. 梯度下降
考虑
min
x
f
(
x
)
\min_x f(x)
minxf(x),其中
f
(
x
)
f(x)
f(x)为可微凸函数,且其梯度
▽
f
(
x
)
\bigtriangledown f(x)
▽f(x)满足L-Lipschitz条件.
最简单的优化方法为梯度下降法(Gradient descent)
x ( k + 1 ) = x ( k ) − η ▽ f ( x ( k ) ) x^{(k+1)}=x^{(k)}-\eta \bigtriangledown f(x^{(k)}) x(k+1)=x(k)−η▽f(x(k))
将 f ( x ) f(x) f(x)在 x = x ( k + 1 ) x=x^{(k+1)} x=x(k+1)的值,在 x ( k ) x^{(k)} x(k)处做Taylor展开,得到
f ( x ( k + 1 ) ) = f ( x ( k ) ) + ▽ f ( x ( k ) ) ( x ( k + 1 ) − x ( k ) ) = f ( x ( k ) ) − η ( ▽ f ( x ( k ) ) ) 2 ≤ f ( x ( k ) ) \begin{aligned} f(x^{(k+1)})&= f(x^{(k)})+\bigtriangledown f(x^{(k)})(x^{(k+1)}-x^{(k)})\\ &=f(x^{(k)})-\eta \left(\bigtriangledown f(x^{(k)})\right)^2\\ &\leq f(x^{(k)}) \end{aligned} f(x(k+1))=f(x(k))+▽f(x(k))(x(k+1)−x(k))=f(x(k))−η(▽f(x(k)))2≤f(x(k))
步长参数 0 < η < 1 0<\eta<1 0<η<1,则每一次迭代总能保证 f ( x ( k + 1 ) ) ≤ f ( x ( k ) ) f(x^{(k+1)})\leq f(x^{(k)}) f(x(k+1))≤f(x(k)).
2. 梯度 ▽ f ( x ) \bigtriangledown f(x) ▽f(x)满足L-Lipschitz条件下的梯度下降
首先给出L-Lipschitz定义:
设函数 f ( x ) f(x) f(x)在有限区间 [ a , b ] [a,b] [a,b]上满足如下条件:
- 当 x ∈ [ a , b ] x\in[a,b] x∈[a,b]时, f ( x ) ∈ [ a , b ] f(x)\in[a,b] f(x)∈[a,b],即 a ≤ f ( x ) ≤ b a\leq f(x)\leq b a≤f(x)≤b;
- 对任意的 x 1 , x 2 ∈ [ a , b ] x_1,x_2\in[a,b] x1,x2∈[a,b], ∣ f ( x 1 ) − f ( x 2 ) ∣ ≤ L ∣ x 1 − x 2 ∣ |f(x_1)-f(x_2)|\leq L|x_1-x_2| ∣f(x1)−f(x2)∣≤L∣x1−x2∣恒成立;
则称 f ( x ) f(x) f(x)在 [ a , b ] [a,b] [a,b]上满足L-Lipschitz条件, L L L称为Lipschitz常数.
可以发现,L-Lipschitz连续比一致连续更强,要求函数值在有限区间的变化幅度受到限制.
进一步的,如果函数 f ( x ) f(x) f(x)的梯度 ▽ f ( x ) \bigtriangledown f(x) ▽f(x)满足L-Lipschitz连续,则其在给定点 x ( k ) x^{(k)} x(k)可以展开成如下二阶近似形式
f ^ ( x ; x ( k ) ) ≐ f ( x ( k ) ) + < ▽ f ( x ( k ) , x − x ( k ) ) > + L 2 ∣ ∣ x − x ( k ) ∣ ∣ 2 \hat{f}(x;x^{(k)})\doteq f(x^{(k)})+<\bigtriangledown f(x^{(k)},x-x^{(k)})>+\frac{L}{2}||x-x^{(k)}||^2 f^(x;x(k))≐f(x(k))+<▽f(x(k),x−x(k))>+2L∣∣x−x(k)∣∣2
展开,并将与 x x x无关的项记为 ϕ ( x ( k ) ) \phi(x^{(k)}) ϕ(x(k)),则可以进一步化简为
f ^ ( x ; x ( k ) ) = L 2 ∣ ∣ x − ( x ( k ) − 1 L ▽ f ( x ( k ) ) ) ∣ ∣ 2 + ϕ ( x ( k ) ) \hat{f}(x;x^{(k)})=\frac{L}{2}\bigg\lvert\bigg\lvert x-\left(x^{(k)}-\frac{1}{L}\bigtriangledown f(x^{(k)})\right)\bigg\rvert\bigg\rvert^2+\phi(x^{(k)}) f^(x;x(k))=2L∣∣∣∣∣∣∣∣x−(x(k)−L1▽f(x(k)))∣∣∣∣∣∣∣∣2+ϕ(x(k))
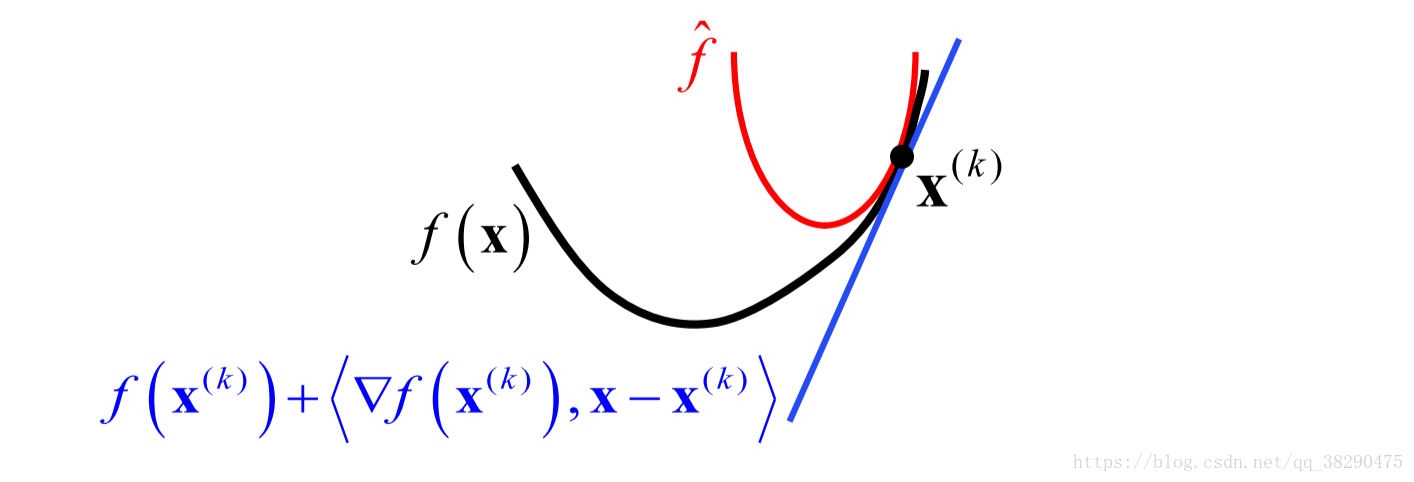
由图可知
f ^ ( x ; x ( k ) ) ≥ f ( x ) \hat{f}(x;x^{(k)})\geq f(x) f^(x;x(k))≥f(x)
当且仅当 x = x ( k ) x=x^{(k)} x=x(k)时,取等号. f ^ ( x ; x ( k ) ) \hat{f}(x;x^{(k)}) f^(x;x(k))实际上为原目标函数的二次上界.
令 x ( k + 1 ) = arg min x f ^ ( x ; x ( k ) ) x^{(k+1)}=\arg\min_x \hat{f}(x;x^{(k)}) x(k+1)=argminxf^(x;x(k)),则可以得到
x ( k + 1 ) = x ( k ) − 1 L ▽ f ( x ( k ) ) x^{(k+1)}=x^{(k)}-\frac{1}{L}\bigtriangledown f(x^{(k)}) x(k+1)=x(k)−L1▽f(x(k))
因此,在二阶近似的条件下,梯度下降可以理解为:
- 每一次迭代都在最小化目标函数在上一次迭代点处的二次上界.
收敛速度为 O ( 1 k ) O(\frac{1}{k}) O(k1).
3. 引入非光滑约束后的近端梯度下降算法
考虑
min
x
f
s
(
x
)
+
f
n
(
x
)
\min_x f^s(x)+f^n(x)
minxfs(x)+fn(x),其中
f
s
(
x
)
f^s(x)
fs(x)为可微凸函数,且其梯度
▽
f
s
(
x
)
\bigtriangledown f^s(x)
▽fs(x)满足L-Lipschitz条件,
f
n
(
x
)
f^n(x)
fn(x)为非光滑函数.
对光滑部分做如上二阶近似,得到
f ^ ( x ; x ( k ) ) = L 2 ∣ ∣ x − ( x ( k ) − 1 L ▽ f s ( x ( k ) ) ) ∣ ∣ 2 + ϕ ( x ( k ) ) + f n ( x ) \hat{f}(x;x^{(k)})=\frac{L}{2}\bigg\lvert\bigg\lvert x-\left(x^{(k)}-\frac{1}{L}\bigtriangledown f^s(x^{(k)})\right)\bigg\rvert\bigg\rvert^2+\phi(x^{(k)})+f^n(x) f^(x;x(k))=2L∣∣∣∣∣∣∣∣x−(x(k)−L1▽fs(x(k)))∣∣∣∣∣∣∣∣2+ϕ(x(k))+fn(x)
令 x ( k + 1 ) = arg min x f ^ ( x ; x ( k ) ) x^{(k+1)}=\arg\min_x \hat{f}(x;x^{(k)}) x(k+1)=argminxf^(x;x(k)),则可以得到近端梯度下降的更新公式
x ( k + 1 ) = arg min x L 2 ∣ ∣ x − ( x ( k ) − 1 L ▽ f s ( x ( k ) ) ) ∣ ∣ 2 + f n ( x ) x^{(k+1)}=\arg\min_x \frac{L}{2}\bigg\lvert\bigg\lvert x-\left(x^{(k)}-\frac{1}{L}\bigtriangledown f^s(x^{(k)})\right)\bigg\rvert\bigg\rvert^2+f^n(x) x(k+1)=argxmin2L∣∣∣∣∣∣∣∣x−(x(k)−L1▽fs(x(k)))∣∣∣∣∣∣∣∣2+fn(x)
而该更新公式可以通过如下近端问题高效求解:
p r o x μ f n ( x ) ( z ) = arg min x 1 2 ∣ ∣ x − z ∣ ∣ 2 + μ f n ( x ) prox_{\mu f^n(x)}(z)=\arg\min_x \frac{1}{2} ||x-z||^2+\mu f^n(x) proxμfn(x)(z)=argxmin21∣∣x−z∣∣2+μfn(x)
即最小化 μ f n ( x ) \mu f^n(x) μfn(x)加上一个独立的二次问题. 此时的收敛速率仍为 O ( 1 k ) O(\frac{1}{k}) O(k1).
4. 三个近端梯度下降计算非光滑约束优化的例子
例1:
凸稀疏罚函数 f n ( x ) = ∣ ∣ x ∣ ∣ 1 f^n(x)=||x||_1 fn(x)=∣∣x∣∣1,此时得到的近端优化问题为
arg min x 1 2 ∣ ∣ x − z ∣ ∣ 2 + μ ∣ ∣ x ∣ ∣ 1 \arg\min_x\frac{1}{2} ||x-z||^2+\mu ||x||_1 argxmin21∣∣x−z∣∣2+μ∣∣x∣∣1
求解得到 z z z的软阈值函数
p r o x μ f n ( x ) ( z ) = S μ ( z ) = s i g n ( z ) max { ∣ z ∣ − μ , 0 } prox_{\mu f^n(x)}(z)=S_\mu(z)=sign(z)\max\left\{|z|-\mu,0\right\} proxμfn(x)(z)=Sμ(z)=sign(z)max{∣z∣−μ,0}
此时的该操作符能够将 z z z的所有元素向 0 0 0压缩,而且计算仅需线性时间.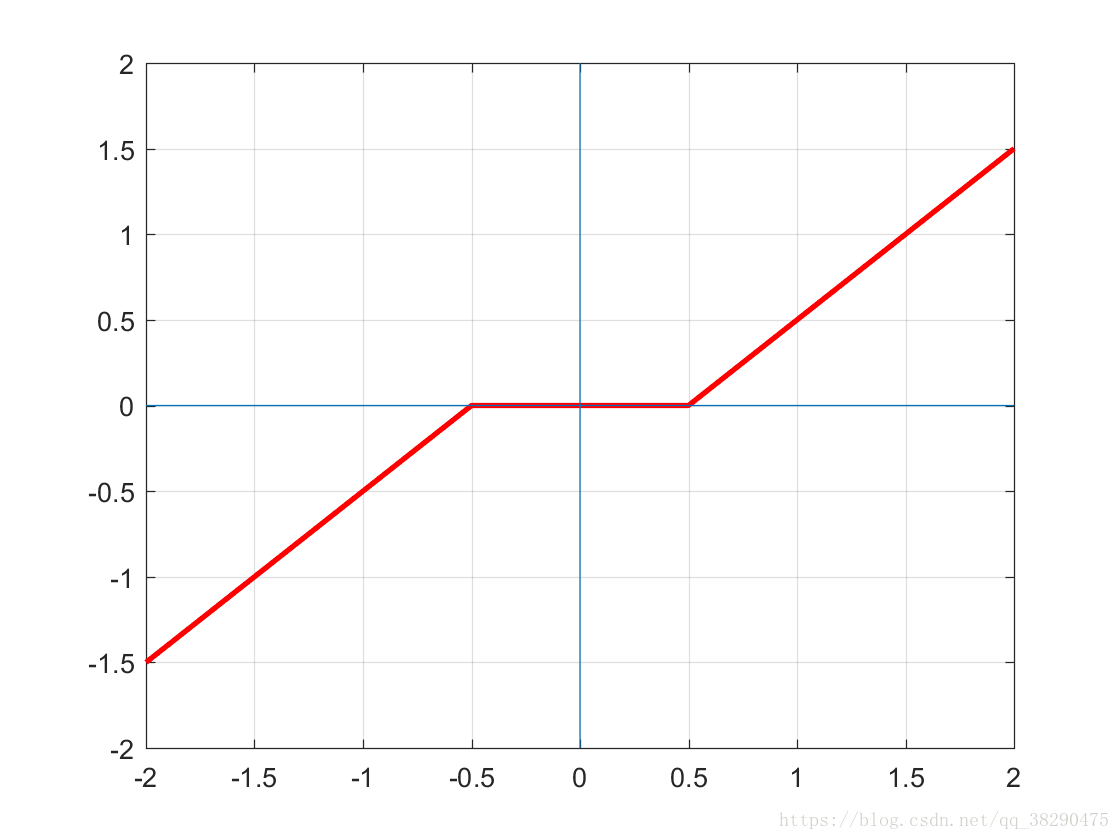
例2:
取 f n ( x ) = ∣ ∣ x ∣ ∣ 0 f^n(x)=||x||_0 fn(x)=∣∣x∣∣0,则得到 z z z的硬阈值函数
p r o x μ f n ( x ) ( z ) = H μ ( z ) = { z ∣ z ∣ ≥ μ 0 o t h e r w i s e prox_{\mu f^n(x)}(z)=H_\mu(z)=\begin{cases} z \quad|z|\geq\mu\\ 0 \quad otherwise \end{cases} proxμfn(x)(z)=Hμ(z)={z∣z∣≥μ0otherwise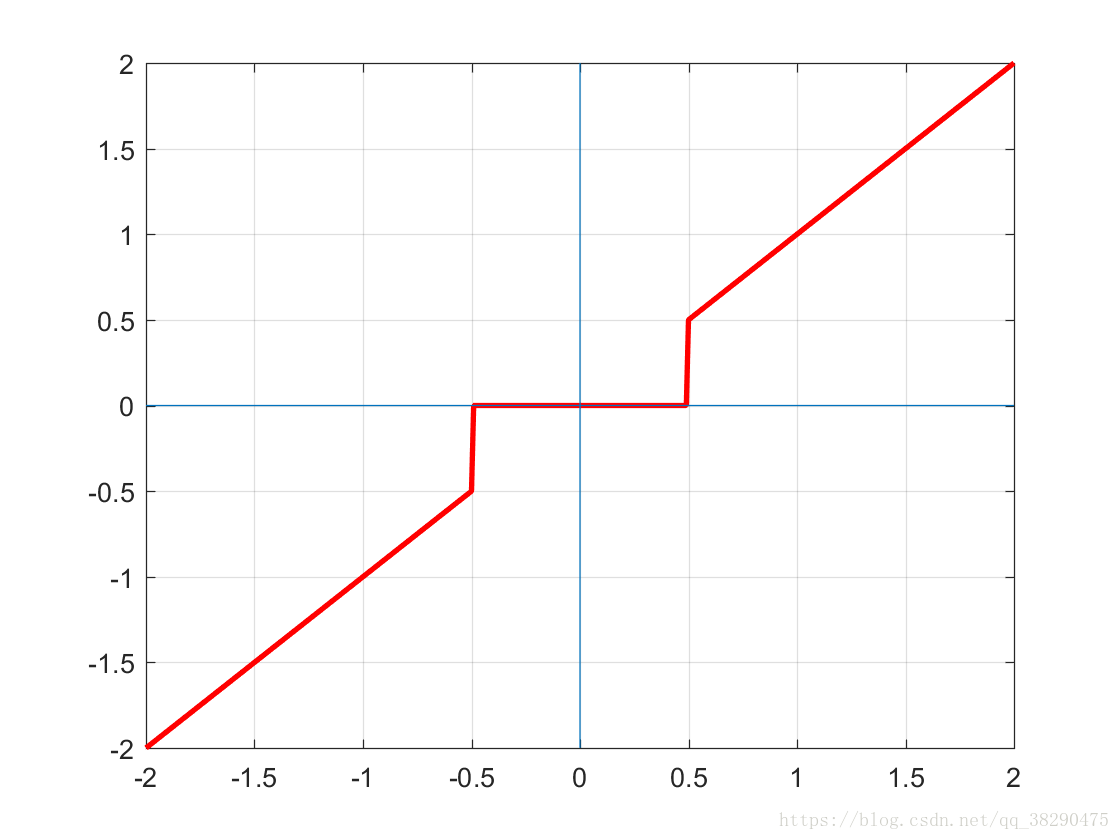
例3:
取 f n ( x ) = ∑ i I ∞ [ x i ≤ 0 ] f^n(x)=\sum_i I_{\infty}[x_i \leq 0] fn(x)=∑iI∞[xi≤0],则得到ReLU网的非线性变换
p r o x μ f n ( x ) ( z ) = R e c ( z ) = max { z , 0 } prox_{\mu f^n(x)}(z)=Rec(z)=\max\left\{z,0\right\} proxμfn(x)(z)=Rec(z)=max{z,0}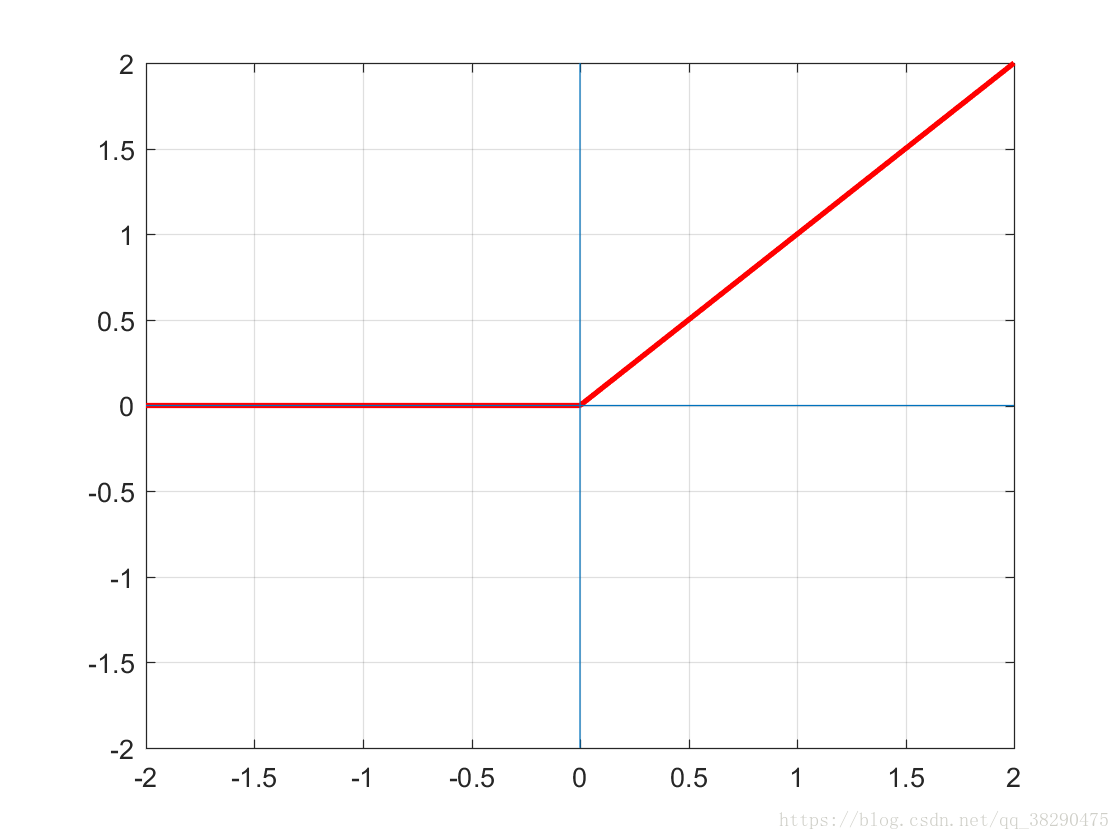

















 6761
6761

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









