







说明:CAS是国科大的简称,KG是知识图谱的缩写,这个栏目之下是我整理的国科大学习到的知识图谱的相关笔记。
课程目标
- 了解以知识图谱为代表的大数据知识工程的基本问题和方法
- 掌握基于知识图谱的语义计算关键技术
- 具备建立小型知识图谱并据此进行数据分析应用的能力
教学安排
详情请见博客:CAS-KG——课程安排
文章目录
1. 信息抽取概述
生命周期—知识获取
- 输入:
领域知识本体
海量数据:文本、垂直站点、百科 - 输出:领域实例化知识
实体集合
事件集合
实体关系/属性
事件关系 - 主要技术:
信息抽取
信息抽取的来源:网络文本信息结构


非结构化文本信息抽取:示例

信息抽取:研究方向
从自然语言文本中抽取指定类型的实体、关系、事件等事实信息,并形成结构化数据输出的文本处理技术
信息抽取的主要任务
实体识别
实体消歧
关系抽取(属性抽取)
事件抽取
事件关系判别
信息抽取的历史


2. 信息抽取的基础:分词和词性标注
(1)中文分词
什么是中文分词

分词的重要性

中文分词的难点


中文分词的难点:歧义切分


中文分词的难点:未登录词识别


中文分词的方法

基于字典的分词方法

- 正向最大匹配(Forward Maximum Matching,FMM)

- 最短路径法

基于字典的分析方法优缺点 - 优点
程序简单易行,开发周期短;
仅需要很少的语言资源(词表),不需要任何词法、句法、语义资源; - 缺点
歧义消解的能力差:基于规则的,很容易错误;
切分正确率不高。
基于统计的分词方法:生成式方法
原理:首先建立学习样本的生成模型,再利用模型对预测结果进行间接推理
典型算法:HMM等
马尔可夫模型

马尔可夫模型:假设

马尔可夫模型:状态表示

马尔可夫模型:状态序列的概率

马尔可夫模型:例子

隐马尔可夫模型
创建于20世纪70年代,是美国数学家鲍姆(Leonard E. Baum)等人提出来的。隐马尔可夫模型是关于时序的概率模型,是一个双重随机过程。
描述由一个隐藏的马尔可夫链随机生成不可观察的状态随机序列(state sequence),再由各个状态生成一个观察,从而产生随机观察序列(observation sequence )的过程,序列的每一个位置又可以看作是一个时刻。
隐马尔可夫模型:例子

隐马尔可夫模型:图解
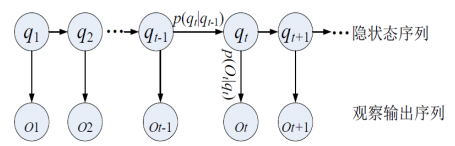
隐马尔可夫模型:三个问题

隐马尔可夫模型:分词+词性标注
以下是一个例子,状态序列是词性,分词的结果由词性这个隐含的序列控制。找一个概率最大的输出。详细见下方第三张图。



优缺点
- 优点
在训练语料规模足够大和覆盖领域足够多的情况下,可以获得较高的切分正确率 - 缺点
训练语料的规模和覆盖领域不好把握。
模型实现复杂、计算量较大。
基于统计的分词方法:判别式方法

判别式分词方法:举例

最大熵模型
最大熵模型:最大熵理论

最大熵模型

最大熵模型:无约束条件

最大熵模型:一个约束条件

最大熵模型:多个约束条件

最大熵模型的参数化形式

最大熵模型

基于最大熵模型的中文分词

基于最大熵模型的中文分词:步骤


基于最大熵模型的中文分词:步骤




神经网络
基于神经网络(BiLSTM+CRF)的中文分词



基于统计的分词方法:判别式方法的优缺点
- 优点
分词精度高
新词识别率较高 - 缺点
训练速度慢
需要设计特征模板
需要人工标注训练语料
性能与特征和语料紧密相关
字典+统计的方法





现有分词方法总结

中文分词的技术水平



当前分词技术存在的主要问题
- 训练语料规模小:分词模型过于依赖训练样本,而标注大规模训练样本费时费力,由此导致分词系统对新词的识别能力差,往往在与训练样本差异较大的测试集上性能大幅
度下降 - 训练语料领域少:现有的训练样本主要在新闻领域,而实际应用千差万别:网络新闻、微博/微信/QQ等对话文本、不同的专业领域(中医药、生物、化学、能源……)。
- 对实体和专有名词的识别性能较低
(2)词性标注
什么是词性标注

词性标注的难点:词性兼类

3. 命名实体识别
以上是我们命名体识别的预备知识。下面开始正式讲NER。
命名实体
命名实体的定义
- 狭义地讲,命名实体指现实世界中具体或抽象的实体,如 人(张三)、机构(中国中文信息学会、阿里巴巴网络技术有限公司)、地点等,通常用唯一的标志符(专有名称)表示,如人名、机构名、地名等。
- 广义地讲,命名实体还可以包含时间(12:00)、日期(2017年10月17日)、数量表达式(100)、金钱(一亿美金)等。至于命名实体的确切含义,只能根据具体应用来确定。比如,在具体应用中,可能需要把住址、电子信箱地址、电话号码、舰船编号、会议名称等作为命名实体。
知识图谱中的命名实体
知识图谱是由数目众多的实体和实体之间的关系所构成的
- DBpedia中共有4,298,433个实体,共有736个类别,例如:/Person/Artist/Actor、/Award/NobelPrize等
- Freebase中共有49,947,799个实体,共有53,092个类别,例如:/location/country、/people/player等
- YAGO中共有5,130,031个实体,共有569,751个类别,例如: / Person/Singer、 / Literal/String/Word等
命名实体识别的任务
一般而言,主要是识别出待处理文本中七类(人名、机构名、地名、时间、日期、货币和百分比)命名实体
两个任务:实体边界识别和实体类别标注(Entity Typing)

命名实体识别的特点

英文人名识别

中文人名识别:难点




中文地名识别:难点


中文机构名识别:难点


中文机构名识别:特点

音译名识别

音译名识别:难点

命名实体识别的方法
- 有词典切分/无词典切分
在分词的过程中使用词典的方法是有词典切分,反之是无词典切分,有字典切分的方法一般是基于规则的,无词典切分的方法一般是基于统计的 - 基于规则的方法/基于统计的方法
基于规则的方法不需要标注训练语料,能直接根据词典和规则进行分词,基于统计的方法需要标注训练语料训练模型。基于统计的方法可以分为生成式统计命名实体识别和判别式命名实体识别
基于词典的命名实体识别方法

基于统计的命名实体识别方法

条件随机场(CRF)

条件随机场:定义

线性链条件随机场:定义

线性链条件随机场的参数化形式

HMM vs ME vs CRF

CRF工具



基于CRF的命名实体识别


LSTM+CRF命名实体识别




汉语分词与实体识别联合模型




基于对抗训练的命名实体识别













融入词典的命名实体识别



英语命名实体识别的技术水平

汉语命名实体识别的技术水平

可选的NER工具

小结
- 受限于训练语料规模,系统的自适应能力不强
网页信息:不规范、存在很多噪音,有些根本就不构成自然语言句子,因此通常的命名实体识别模型所依赖的上下文特征发生了明显变化,使得识别性能剧烈下降 - 类别数限定,不满足实际的应用
摩托罗拉V8088折叠手机、第6届苏迪曼杯羽毛球混合团体赛、胆结石腹腔镜手术等 - 需要开放域实体抽取
实体类型更多、更细,而且有些实体类别是未知、或者是随时间演化的 - 基于深度学习的分词和命名实体识别
4. 细粒度实体分类
传统的命名实体的三大类、七小类远远不能满足需求,在知识图谱构建和很多自然语言处理任务中,细粒度的实体类别包含了更多的知识,有助于相应任务性能的提升。
- 例如,产品名(如:华为Mate10)、疾病名(如:非典型肺炎)、赛事名(如:2018年世界杯),人可以细分为艺人、运动员、教师、工程师等,艺人又可以分为相声演员、影视演员、歌手、主持人等。
典型的细粒度实体类别分类

细粒度实体类别的特点

细粒度实体分类的难点

细粒度实体分类的方法
- 无监督方法:针对没有标注语料的情况
- 有监督方法:针对有人工标注语料
无监督方法

有监督的方法
- 基于特征工程的传统方法
- 基于神经网络的深度学习方法(主流方法)
介绍:Li Dong, A Hybrid Neural Model for Type Classification of Entity Mentions, IJCAI-2015




介绍:Ji Xin, Improving Neural Fine-Grained Entity Typing with Knowledge Attention, AAAI-2018



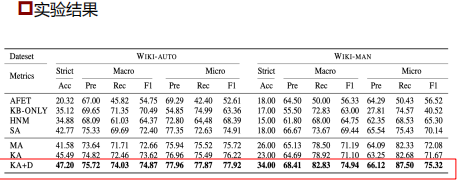
小结
- 类别数较多,和实际的应用比较相符合
- 数据标注困难,训练语料较少
- 以有监督的方法为主
5. 开放域实体识别
开放域实体抽取

开放域实体抽取的主要方法

开放域实体抽取的主要方法: Query Log

开放域实体抽取的主要方法: Web Page


开放域实体抽取的主要方法: 融合多个数据源

评价指标与技术水平


总结
- 自然语言处理技术的历史
- 信息抽取技术概述:四个任务
- 中文分词
任务介绍
难点
典型方法
评测指标
技术水平 - 命名实体识别
任务介绍
难点
典型方法
技术水平 - 细粒度实体分类
任务介绍
细粒度识别类别分类
细粒度实体类别的特点
细粒度实体分类的难点
细粒度实体分类的方法 - 开放域实体识别
任务介绍
难点
典型方法
评测指标
技术水平














 3401
3401











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









