






引入:
-- 建表:t1
create table dma.t1(id int, value int) partitioned by (ds string);
-- 数据装载:t1表
insert overwrite table dma.t1 partition(ds='20220120') select '1','2022';
insert overwrite table dma.t1 partition(ds='20220121') select '2','2022';
insert overwrite table dma.t1 partition(ds='20220122') select '2','2022';
-- 建表:t2
create table dma.t2(idd int, valuee int) partitioned by (ds string);
-- 数据装载:t2表
insert overwrite table dma.t2 partition(ds='20220120') select '1','120';
t1表:
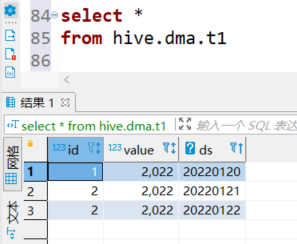
t2表:

思考:
执行以下语句,会返回什么结果呢?
select *
from hive.dma.t1 t1
left join hive.dma.t2 t2
on t1.id = t2.idd
and t1.ds = '20220120'
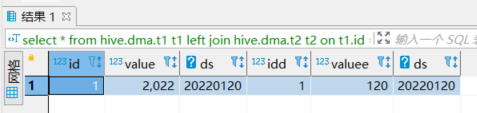
是结果1这样?
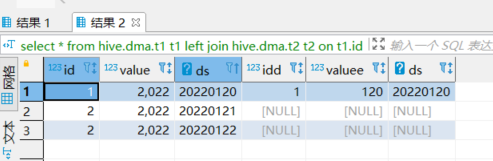
还是结果2这样?
现象:
最终的结果:

如果想获取到结果1的数据,正确应该是:
-- 方式一:
select *
from hive.dma.t1 t1
left join hive.dma.t2 t2
on t1.id = t2.idd
where t1.ds = '20220120'
-- 方式二:
select *
from(
select *
from hive.dma.t1
where ds = '20220120'
)t1
left join hive.dma.t2 t2
on t1.id = t2.idd
小结:按照 left join 的语义,如果没有过滤条件,那么左表的数据应该全部返回,右表匹配不上则补null值
补充:正常的left join,也就是只包含on条件,这种情况没有过滤操作,即左表的数据会全部返回;
另一种方式是有谓词下推,即关联的时候使用了where条件,这个时候会先对数据进行过滤。
引出:谓词下推

-- 以上可知:SQL中的谓词主要有:
like、between、is null、is not null、in、exists
什么是谓词下推
将过滤表达式尽可能移动至靠近数据源的位置,以使真正执行时能直接跳过无关的数据
在文件格式使用Parquet或Orcfile时,甚至可能整块跳过不相关的文件
Hive中谓词下推
Hive中的Predicate Pushdown,简称谓词下推,主要思想是把过滤条件下推到map端,提前执行过滤,以减少map端到reduce端传输的数据量,提升整体性能
-- 具体配置项是:(默认为true)
hive.optimize.ppd
总结:
1、谓词下推:在存储层即过滤了大量大表无效数据,减少扫描无效数据;所谓下推,即谓词过滤在map端执行,所谓不下推,即谓词过滤在reduce端执行
2、inner join时,谓词放任意位置都会下推
3、left join时,左表的谓词应该写在where 后
4、right join时,左表的谓词应该写在join后















 1964
1964











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









