







JOIN关联语句
JOIN相关介绍
- Join语法主要是用于根据两张或多张表中列之间的关系,通过这一些列表中的共同组合来查询数据。
- Hive Join语句中主要是有六种join,详情可以参考官方文档介绍。这里我们主要熟悉一下两个最常用的join连接方式一个是内连接一个是左外连接。
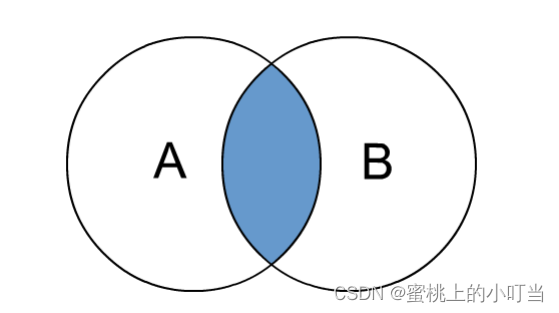
- 内连接:内连接是最常见的一种连接,它也被称为普通连接,其中inner可以省略:inner join == join ;只有进行连接的两个表中都存在与连接条件相匹配的数据才会被留下来。如下图所示:
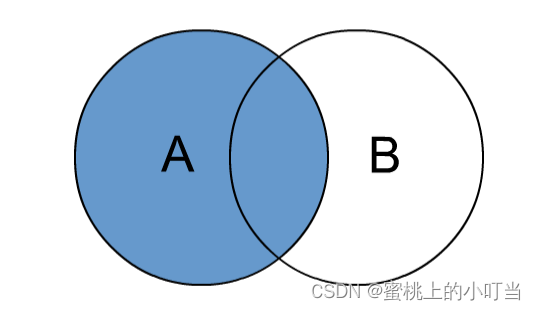
- 左外连接: left join中文叫做是左外连接(Left Outer Join)或者左连接,其中outer可以省略,left outer join是早期的写法。join时以左表的全部数据为准,右边与之关联;左表数据全部返回,右表关联上的显示返回,关联不上的显示null返回。 如下图所示:
- 基本语法

JOIN语句相关操作
- 环境准备
--建表
--table1: 员工表
CREATE TABLE employee(
id int,
name string,
deg string,
salary int,
dept string
) row format delimited
fields terminated by ',';
--table2:员工家庭住址信息表
CREATE TABLE employee_address (
id int,
hno string,
street string,
city string
) row format delimited
fields terminated by ',';
--table3:员工联系方式信息表
CREATE TABLE employee_connection (
id int,
phno string,
email string
) row format delimited
fields terminated by ',';
--加载数据到表中(先把数据放到/root/hivedata/中)
load data local inpath '/root/hivedata/employee.txt' into table employee;
load data local inpath '/root/hivedata/employee_address.txt' into table employee_address;
load data local inpath '/root/hivedata/employee_connection.txt' into table employee_connection;
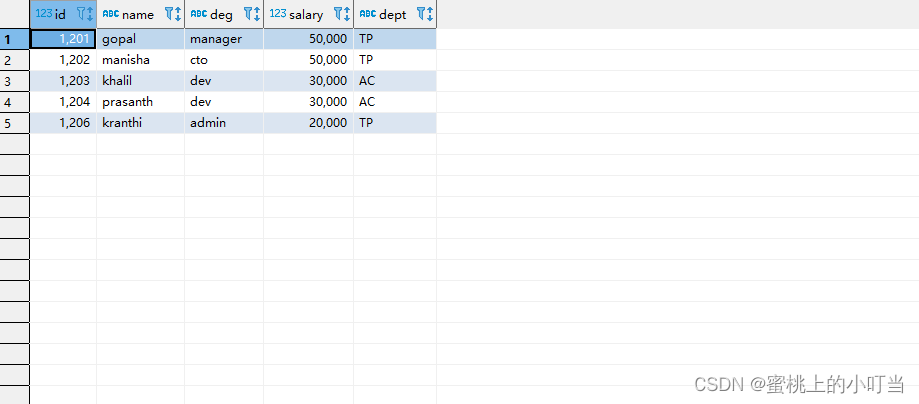
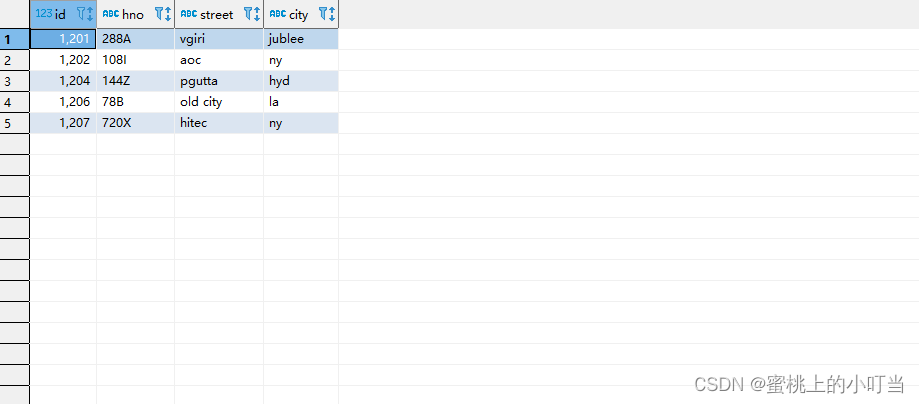
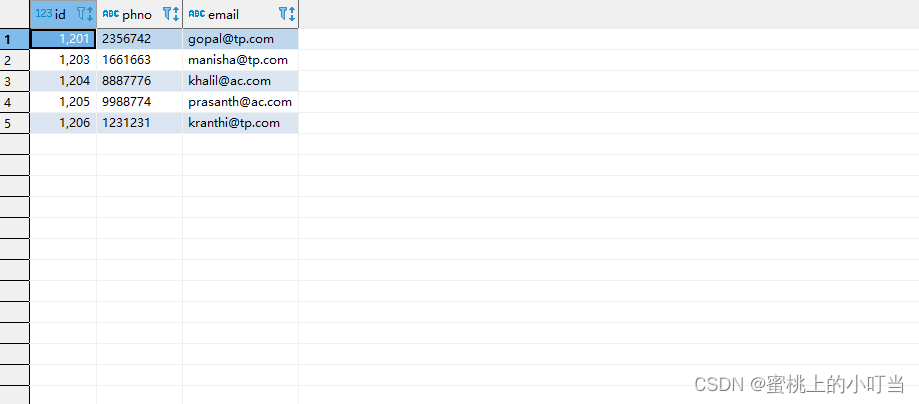
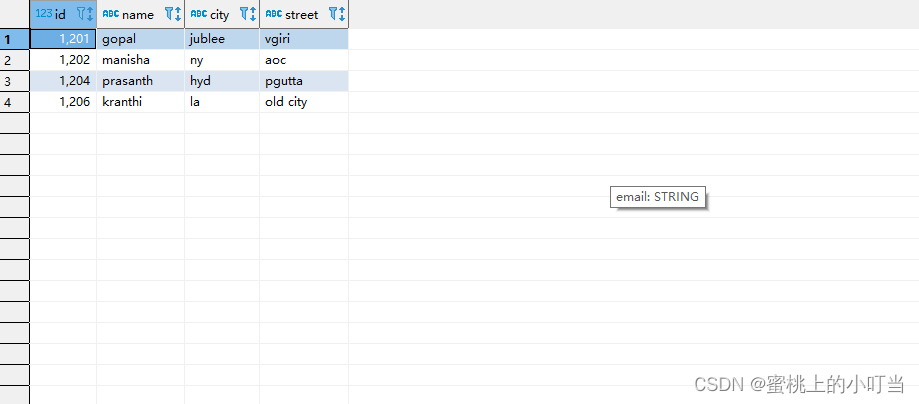
--查看表
select *
from employee;
select *
from employee_address;
select *
from employee_connection;
- inner join
select e.id,e.name,e_a.city,e_a.street
from employee e inner join employee_address e_a
on e.id =e_a.id;
--等价于 inner join=join
select e.id,e.name,e_a.city,e_a.street
from employee e join employee_address e_a
on e.id =e_a.id;
--等价于 隐式连接表示法
select e.id,e.name,e_a.city,e_a.street
from employee e , employee_address e_a
where e.id =e_a.id;`
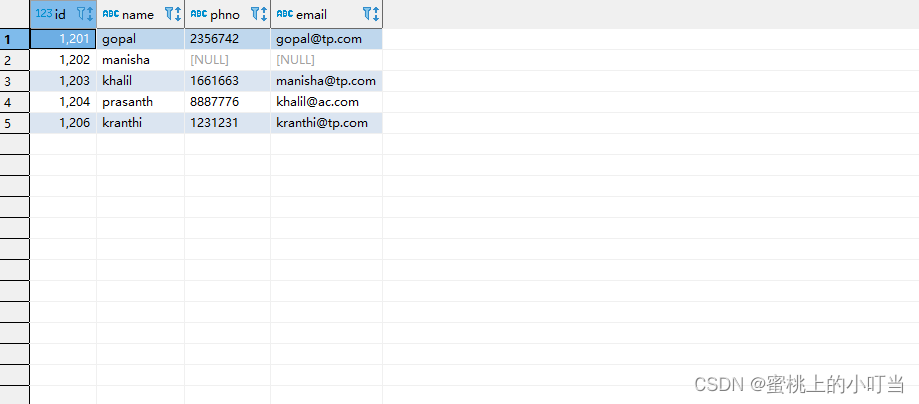
- left join
select e.id,e.name,e_conn.phno,e_conn.email
from employee e left join employee_connection e_conn
on e.id =e_conn.id;
--等价于 left outer join
select e.id,e.name,e_conn.phno,e_conn.email
from employee e left outer join employee_connection e_conn
on e.id =e_conn.id;
Hive函数
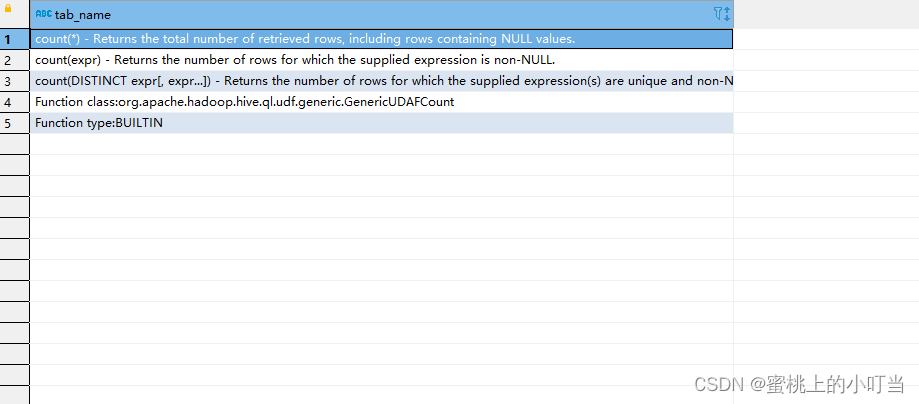
- 为了满足用户不同使用需求,提高SQL编写效率,Hive和Mysql数据库一样都内建了不少函数。使用
show functions查看当下可用的所有函数;也可以通过describe function extended funcname来查看函数的使用方式。
Hive函数分类标准
-
Hive的函数分为两大类:内置函数(Built-in Functions)、用户定义函数UDF(User-Defined Functions)
- 内置函数:数值类型函数、日期类型函数、字符串类型函数、集合函数、条件函数等。
- 用户定义函数根据输入输出的行数可分为3类:UDF、UDAF、UDTF。
-
UDF分类标准
- UDF(User-Defined-Function)普通函数,一进一出。
- UDAF(User-Defined Aggregation Function)聚合函数,多进一出。
- UDTF(User-Defined Table-Generating Functions)表生成函数,一进多出。
-
UDF分类标准本来针对的是用户自己编写开发实现的函数。UDF分类标准可以扩大到Hive的所有函数中:包括内置函数和用户自定义函数。
Hive常见内置函数
字符串函数
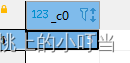
- 字符串长度函数:length
select length("hello");
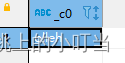
- 字符串反转函数:reverse
select reverse("hello");
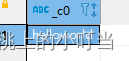
- 字符串连接函数:concat
select concat("hello","world");
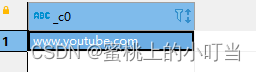
- 带分隔符字符串连接函数:concat_ws(separator, [string | array(string)]+)
select concat_ws('.', 'www', array('youtube', 'com'));
- 字符串截取函数:substr,substring(str, pos[, len]) 或者 substring(str, pos[, len])
select substr("helloworld",-2); --pos是从1开始的索引,如果为负数则是倒过来数
select substr("helloworld",2,2);


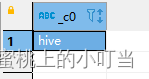
- 分割字符串函数: split(str, regex)
--split针对字符串数据进行切割 返回是数组array 可以通过数组的下标取内部的元素 注意下标从0开始的
select split('apache hive', ' ');
select split('apache hive', ' ')[0];
select split('apache hive', ' ')[1];
日期函数
- 获取当前日期: current_date
select current_date();
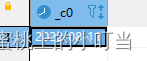
- 获取当前UNIX时间戳函数: unix_timestamp
select unix_timestamp();
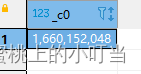
- 日期转UNIX时间戳函数: unix_timestamp
select unix_timestamp("2022-02-22 22:00:22");
-- 指定格式转换
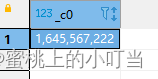
select unix_timestamp('20220222 22:00:02','yyyyMMdd HH:mm:ss');
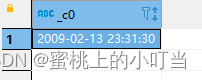
- UNIX时间戳转日期函数: from_unixtime
select from_unixtime(1234567890);
select from_unixtime(0, 'yyyy-MM-dd HH:mm:ss');
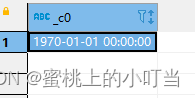
- 日期比较函数: datediff 日期格式要求’yyyy-MM-dd HH:mm:ss’ or ‘yyyy-MM-dd’
select datediff('2022-08-08','2012-12-21');
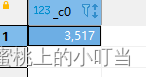
- 日期增加函数: date_add
select date_add('2022-01-30',10);
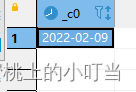
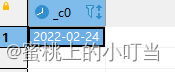
- 日期减少函数: date_sub
select date_sub('2022-03-06',10);
数学函数
- 取整函数: round 返回double类型的整数值部分 (遵循四舍五入)
select round(3.1415926);
#输出
3
- 指定精度取整函数: round(double a, int d) 返回指定精度d的double类型
select round(3.1415926,4);
#输出
3.1416
- 取随机数函数: rand 每次执行都不一样 返回一个0到1范围内的随机数
select rand();
#输出
0.7184552121506158
- 指定种子取随机数函数: rand(int seed) 得到一个稳定的随机数序列
select rand(3);
#输出
0.731057369148862
条件函数
- if条件判断: if(boolean testCondition, T valueTrue, T valueFalseOrNull)
select if(1=2,100,200);
#输出
200
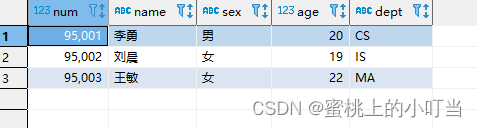
select * from student limit 3;
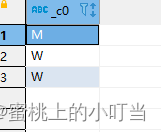
select if(sex ='男','M','W') from student limit 3;
- –空值转换函数: nvl(T value, T default_value)
select nvl("cauchy","win");
#输出cauchy
select nvl(null,"win");
#输出win
- 条件转换函数: CASE a WHEN b THEN c [WHEN d THEN e]* [ELSE f] END
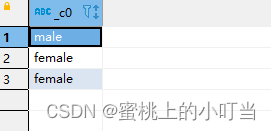
select case sex when '男' then 'male' else 'female' end from student limit 3;















 1626
1626











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









