







目录
🍇🍇0.简介
🌷🌷1.研究动机
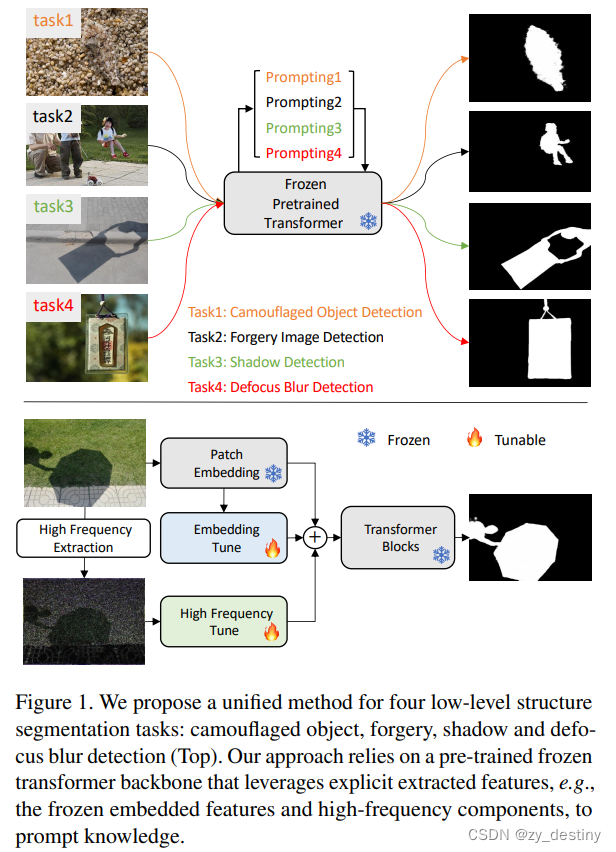
通用的分割任务通常在高分辨率高质量的图像上表现良好,而EVP关注的则是图像中的低级结构问题,比如伪造目标、识别失焦目标、分离阴影和检测隐藏的对象等等,尽管每个任务通常都是通过特定领域的解决方案来解决的,但EVP方法将所有主题任务统一至一个方法中,也就是通常所说的“范式”。由此可见,ECP主要关心的就是图像中不清晰的,结构模糊的对象。
我们从NLP中广泛使用的预训练和提示调优协议中获得灵感,提出了一种新的视觉提示模型,称为显式视觉提示(EVP)。与之前的视觉提示(通常是数据集级别的隐式嵌入)不同,我们的关键见解是强制使用可调参数,重点关注每个单独图像的显式视觉内容,即来自冻结补丁嵌入的特征和输入的高频分量。在相同数量的可调参数(每个任务的5.7%的额外可训练参数)下,所提出的EVP显著优于其他参数有效调节。与特定任务的解决方案相比,EVP在各种低级别结构分割任务上也实现了最先进的性能。
🍋🍋2.主要贡献
- 设计了一种统一的方法,为许多任务提供最先进的性能,包括伪造检测(forgery detection,)、散焦模糊检测(defocus blur detection)、阴影检测(shadow detection)和伪装物体检测(camouflaged object detection)
- 提出了显式视觉提示(EVP),它以冻结补丁嵌入的特征和输入的高频分量作为提示。它被证明在不同的任务中是有效的,并且优于其他参数有效的调整方法。
- EVP方法极大地简化了底层结构分割模型,并与精心设计的SOTA方法实现了相当的性能。
🍓🍓3.网络结构
🍭3.1整体结构
EVP整体结构如下,使用在大规模数据集上预训练的Transformer模型并冻结其参数,为了适应每个任务,再调整embedding的特征并学习每个单独图像的高频成分的额外embedding。可以看到每个任务的可训练参数均在embedding-finetune和high-frequency提取模块中。
EVP使用的Tranformer是SegFormer,是一个分层Transformer,具有更简单的decoder用来进行语义分割。另一篇论文《SAM Fails to Segment Anything? – SAM-Adapter: Adapting SAM in Underperformed Scenes: Camouflage, Shadow, Medical Image Segmentation,and More》中,SAM-Adapter网络用的类似的结构,只是将EVP中的Transformer结构换成了SAM结构,SAM-Adapter主要是使用了SAM的Image Encoder和Masked Decoder,其中Image Encoder冻结了参数,Decoder是参与梯度回传的。
🍭3.2高频分量计算
在EVP论文中的创新点之一的输入的高频分量具体网络结构如下。

对于尺寸为H×W的图像I,我们可以将其分解为低频分量Il(LFC)和高频分量Ih(HFC),即I={Il,Ih}。将fft和ifft分别表示为快速傅立叶变换及其逆变换,我们使用z来表示I的频率分量。因此,我们有z=fft(I)和I=ifft(z)。我们把低频系数移到中心(H/2,W/2)。为了获得高频分量HFC,根据掩码比τ,生成二进制掩码Mh∈{0,1}H×W,并将其应用于傅里叶变换后的影像:

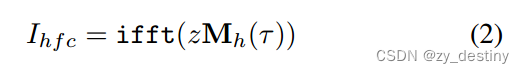
为了获得低频分量LFC,其计算方式与高频分量相似:
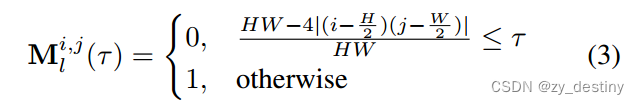

此处的![]() 和
和![]() ,可以将其看做是一个权重矩阵,将其与傅里叶变换后的影像Z进行相乘,再将其结果进行傅里叶逆变换操作,即可实现高低频分量的区分计算和表示。
,可以将其看做是一个权重矩阵,将其与傅里叶变换后的影像Z进行相乘,再将其结果进行傅里叶逆变换操作,即可实现高低频分量的区分计算和表示。
🍭3.3显示视觉提示EVP
显式视觉提示(EVP)的关键是从图像embedding和高频分量中学习明确的提示。
学习图像embedding将分布从预训练数据集转移到目标数据集。学习高频分量的主要动机是通过数据扩充来学习预训练的模型的特征不变性。EVP方法如图3所示,它由三个基本模块组成:embedding 微调、高频分量微调以及Adaptor

Patch embedding tune:在预训练segformer网络中,将patch投影到C维的特征图上,并且冻结该投影,添加一个可微调的线性层L,将原始embedding投影至C维特征中。

此处的尺度参数r即可控制微调参数,
High-frequency components tune:对于高频分量Ihfc,我们学习了类似于SegFormer的重叠补丁嵌入。形式上,Ihfc被划分为与SegFormer具有相同补丁大小的小补丁。我们学习一个线性层Lhfc来将补片投影到c维特征Fhfc中。
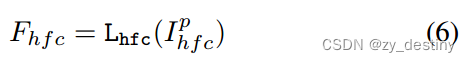
Adaptor: 通过考虑来自图像嵌入和高频分量的特征,在所有层中高效地执行自适应。对于第i个适配器,我们将Fpe和Fhfc作为输入,并获得提示Pi:

🍂🍂4.实验
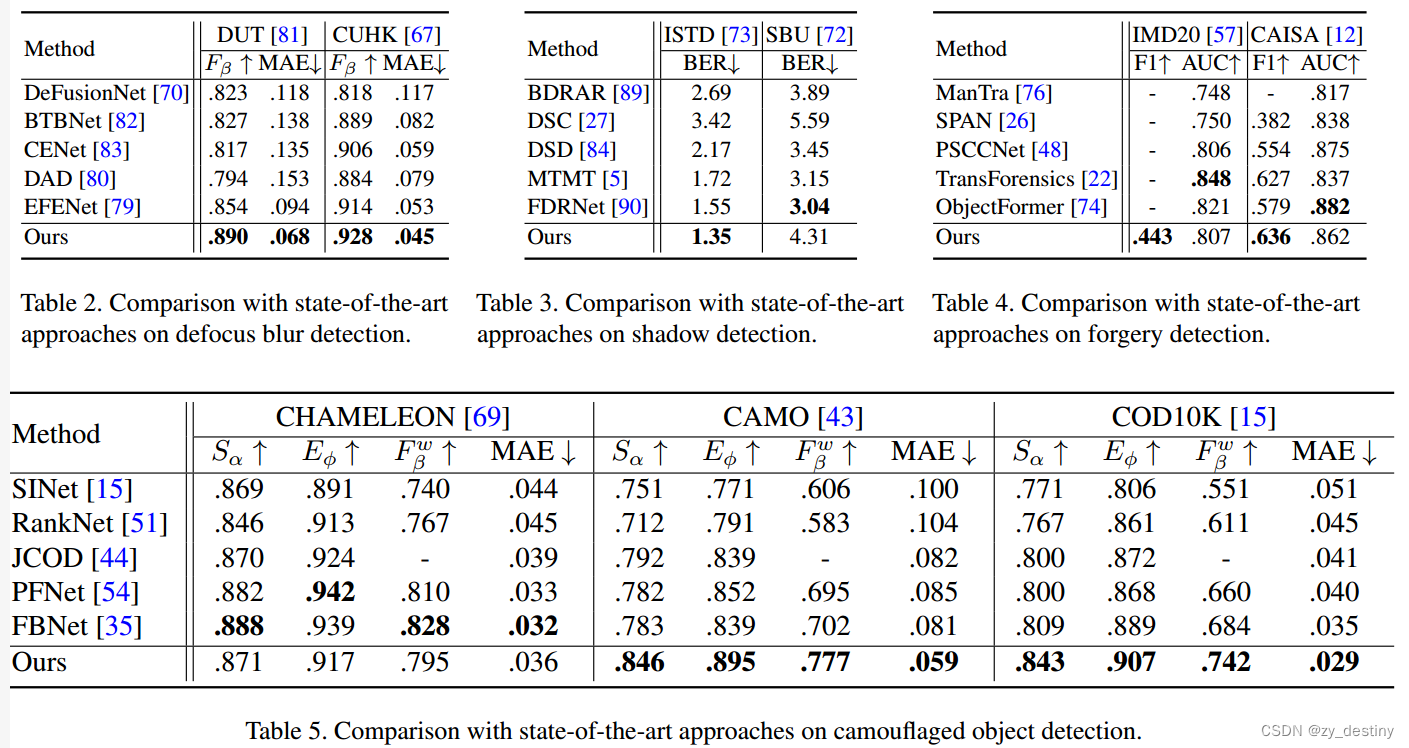
🏆4.1四种任务结果对比
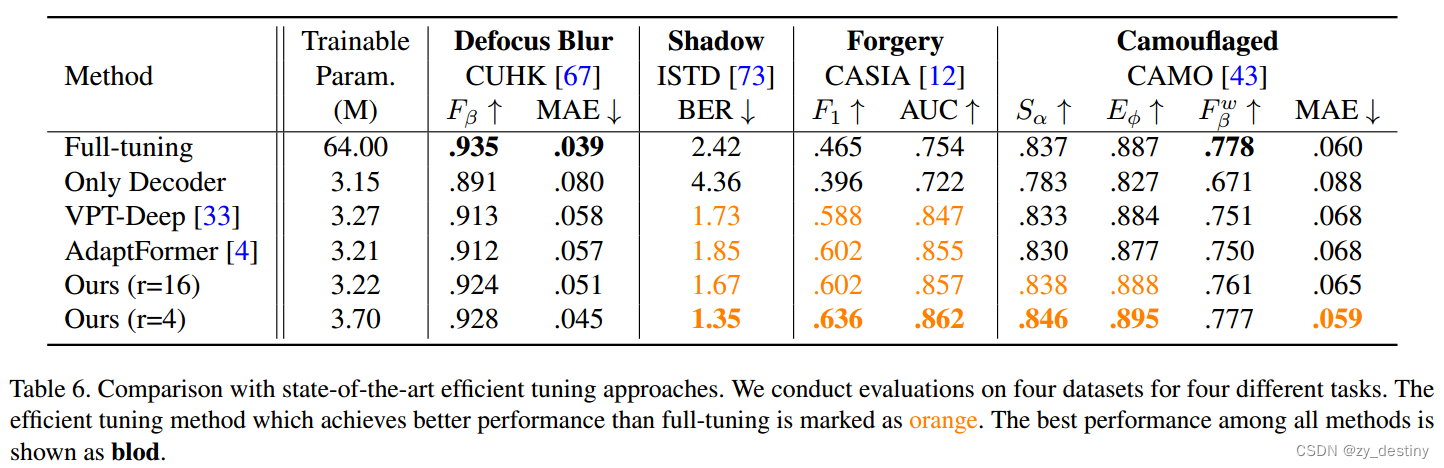
🏆4.2不同可训练参数量结果对比
🏆4.3四种任务可视化结果

🏆4.4消融实验

🏆4.5参数选择对比结果

🏆4.6在四个不同任务上与其他微调方法对比


🍉🍉5.总结
EVP提出了一种明确的视觉提示,以统一低层次结构分割的解决方案。我们主要关注两类特征:来自块嵌入的冻结特征和来自原始图像的高频分量。使用我们的方法,我们发现来自ImageNet的具有有限可调参数的冻结视觉转换器主干可以实现与全微调网络结构相似的性能,与其他特定任务的方法相比,也具有最先进的性能。对于未来的研究,我们将把我们的方法扩展到其他相关问题,并希望它能促进视觉提示的进一步探索。
整理不易,欢迎一键三连!!!
送你们一条美丽的--分割线--
🌷🌷🍀🍀🌾🌾🍓🍓🍂🍂🙋🙋🐸🐸🙋🙋💖💖🍌🍌🔔🔔🍉🍉🍭🍭🍋🍋🍇🍇🏆🏆📸📸⛵⛵⭐⭐🍎🍎👍👍🌷🌷
















 404
404











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











