







一、批归一化和残差网络
1.批归一化:
- BN是由Google于2015年提出,这是一个深度神经网络训练的技巧,它不仅可以加快了模型的收敛速度,而且更重要的是在一定程度缓解了深层网络中“梯度弥散”的问题,从而使得训练深层网络模型更加容易和稳定。所以目前BN已经成为几乎所有卷积神经网络的标配技巧了。
- 从字面意思看来Batch Normalization是对每一批数据进行归一化,确实如此,对于训练中某一个batch的数据{x1,x2,…,xn},注意这个数据是可以输入也可以是网络中间的某一层输出。在BN出现之前,我们的归一化操作一般都在数据输入层,对输入的数据进行求均值以及求方差做归一化,但是BN的出现打破了这一个规定,我们可以在网络中任意一层进行归一化处理,因为我们现在所用的优化方法大多都是mini-batch SGD,所以我们的归一化操作就成为Batch Normalization。
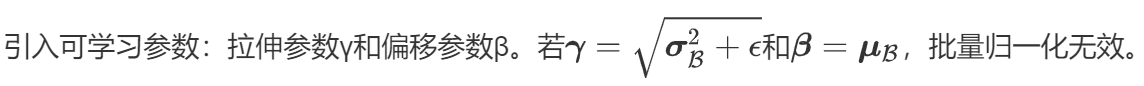
2.预测时的批量归一化
- 训练:以batch为单位,对每个batch计算均值和方差。
- 预测:用移动平均估算整个训练数据集的样本均值和方差。
3.ResNet和DenseNet

- ResNet:加号连接(保证A和B输出形状一样)
- DenseNet:concat(A和B通道数相加)
- 输出通道数=输入通道数+卷积层个数*卷积输出通道数
二、凸优化
1.尽管优化方法可以最小化深度学习中的损失函数值,但本质上优化方法达到
的目标与深度学习的目标并不相同。
- 优化方法目标:训练集损失函数值
- 深度学习目标:测试集损失函数值(泛化性)
2.凸性

- 凸集合:连线两点都在集合内(第一行)
- 凸集合的交集仍然是凸集合(第二行)
- 凸集合的并集不一定是凸集合(第三行)
3.凸函数

- 凸函数:第一个图A点大于B点,同理第三个图也是凸函数,第二个图不是
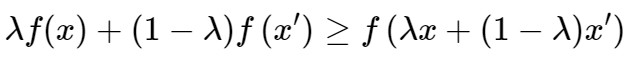
4.Jensen 不等式:函数值的期望大于期望的函数值
5.鞍点是对所有自变量一阶偏导数都为0,且Hessian矩阵特征值有正有负的点















 8749
8749











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









