







JobContainer 是什么?
jobContainer 是许多job的组合体,比如我有个任务是同时读取mysql和oracle的表然后写导hdfs的。此时mysqlreader+oraclereader打包起来就是一个container。但是实际来说我们都是只有一种reader的。
job是什么?
简单的理解就是我要 mysql->hdfs这这任务就是一个job
task是什么?
task是job的更细层次划分,比如mysql id 1->100w 共计100w条数据
我把 mysql->hdfs 这个job划分为10个task
mysql 1-10w ->hdfs
mysql 10-20w->hdfs
。。。。
mysql 90w-100->hdfs
这十个任务每个任务就是一个task。
taskgroup 是什么?
顾名思义就是将几个task划分为一个小组进行管理。几个呢?5个。可以在datax_home/conf/core.json调整。


channel是什么?
channel可以理解为在部分的job 种可以控制 taskgroup的数量。可以控制并发数
例如mysql postgresql oracle 这种 task的数量=channel数*5+1,

但是hdfsreader这种 设置channel数多少也不起作用。
下面是源码的学习和分析。
JobContainer.java
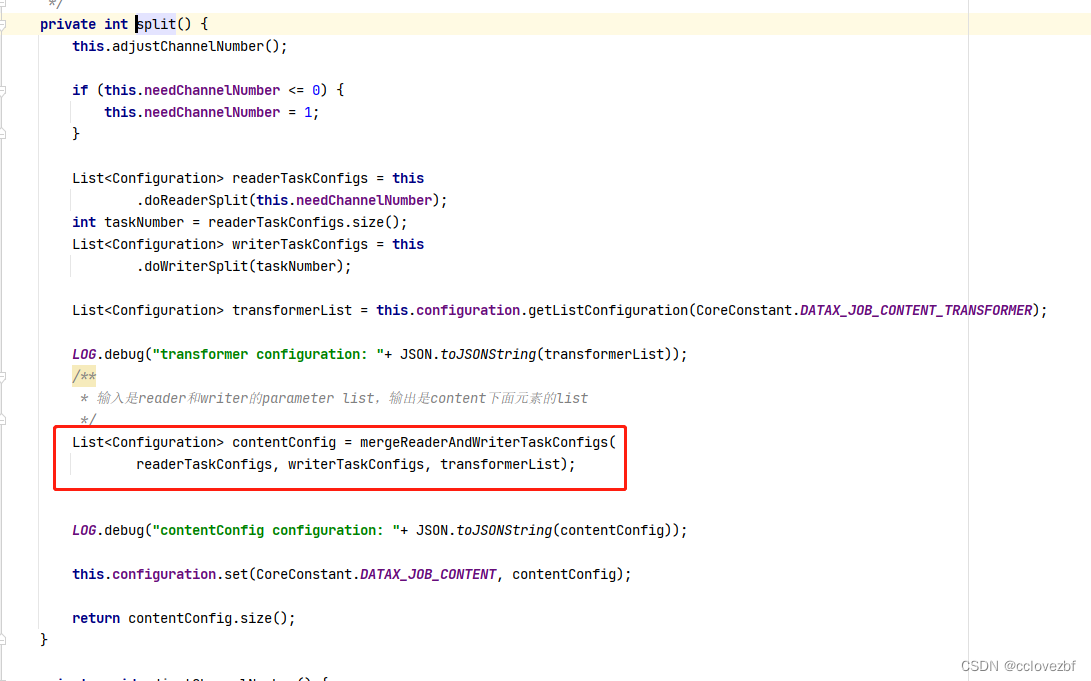
这里是将一个job切分为多个任务,这里我还是举例,oraclereader->oraclewriter channel=10
注意我们之前配置的json只是job的config。
doReaderSplit的返回值就是task的config,taskconfig和jobconfig的不同有,里面加个标记 类似reader=oracle,然后job的sql是 select * from t ,taskconfig是 select * from t where xx<id<xx
sliceConfig.set(CommonConstant.LOAD_BALANCE_RESOURCE_MARK, DataBaseType.parseIpFromJdbcUrl(jdbcUrl));dowriterSplit的返回值就是writerTaskConfig,其实就是jobconfig。
备注:我这里全都是简化的比喻,有的人写多个oraclewriter和多个oraclereader,然后table里有多个表,由于情况比较多我就不举例了,只说最常用的情况。
List<Configuration> contentConfig = mergeReaderAndWriterTaskConfigs(
readerTaskConfigs, writerTaskConfigs, transformerList);这里还有个transformerList 怎么说?我查了参数没有 暂且看作0
那么此时readerTaskConfigs.size=51, writerTaskConfigs.size=51
这个merge方法的作用就是把readerTaskConfig和writerTaskConfigs 组装起来,成为了一个完整的taskconfig,同时还给task编号1 ,2,3,4....51.
举个简单例子
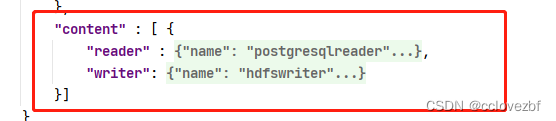
就是将这个job复制了51份,每一份reader的查询内容不一样,将where切分为了51份。
this.configuration.set(CoreConstant.DATAX_JOB_CONTENT, contentConfig);最后this.configuration是jobConfguration,将contentConfig(51个taskConfig)set到jobContent里, 至此 JobContainer的start方法中的 split就完了。
然后重点是schedule方法,怎么分配这51个任务好好工作?
private void schedule() {
/**
* 这里的全局speed和每个channel的速度设置为B/s
*/
//按照说明 这里=5
int channelsPerTaskGroup = this.configuration.getInt(
CoreConstant.DATAX_CORE_CONTAINER_TASKGROUP_CHANNEL, 5);
//这个获取的json里的job.content 的个数,由于split里已经set了51个task 这里=51
int taskNumber = this.configuration.getList(
CoreConstant.DATAX_JOB_CONTENT).size();
//needChannelNumber=10 taskNumber=51 所以这里=10
this.needChannelNumber = Math.min(this.needChannelNumber, taskNumber);
PerfTrace.getInstance().setChannelNumber(needChannelNumber);
/**
* 通过获取配置信息得到每个taskGroup需要运行哪些tasks任务
*/
//这里就是计算taskGroup有多少个task 其实就是(int) Math.ceil(1.0 * 10/ 5)=2;
//其实这里面真鸡儿的复杂,写这个方法的人考虑到不同的reader,比如mysql的task1和oracle的task1总不能放到一个group里把。所以简单的来看就是 channels/ 5 向上取整。
//然后将task组装放到了taskGroup里,此时就是2个group 一个有25个task 一个有26个task
//同时还将channel数也拆分了 每个group 有5个channel
List<Configuration> taskGroupConfigs = JobAssignUtil.assignFairly(this.configuration,
this.needChannelNumber, channelsPerTaskGroup);
LOG.info("Scheduler starts [{}] taskGroups.", taskGroupConfigs.size());
ExecuteMode executeMode = null;
AbstractScheduler scheduler;
try {
executeMode = ExecuteMode.STANDALONE;
scheduler = initStandaloneScheduler(this.configuration);
//设置 executeMode
for (Configuration taskGroupConfig : taskGroupConfigs) {
taskGroupConfig.set(CoreConstant.DATAX_CORE_CONTAINER_JOB_MODE, executeMode.getValue());
}
if (executeMode == ExecuteMode.LOCAL || executeMode == ExecuteMode.DISTRIBUTE) {
if (this.jobId <= 0) {
throw DataXException.asDataXException(FrameworkErrorCode.RUNTIME_ERROR,
"在[ local | distribute ]模式下必须设置jobId,并且其值 > 0 .");
}
}
LOG.info("Running by {} Mode.", executeMode);
this.startTransferTimeStamp = System.currentTimeMillis();
scheduler.schedule(taskGroupConfigs);
this.endTransferTimeStamp = System.currentTimeMillis();
} catch (Exception e) {
LOG.error("运行scheduler 模式[{}]出错.", executeMode);
this.endTransferTimeStamp = System.currentTimeMillis();
throw DataXException.asDataXException(
FrameworkErrorCode.RUNTIME_ERROR, e);
}
/**
* 检查任务执行情况
*/
this.checkLimit();
}
可以看到打印的日志和我的备注一样。
此时这一步schedule就完了,然后就是执行。
继续查看

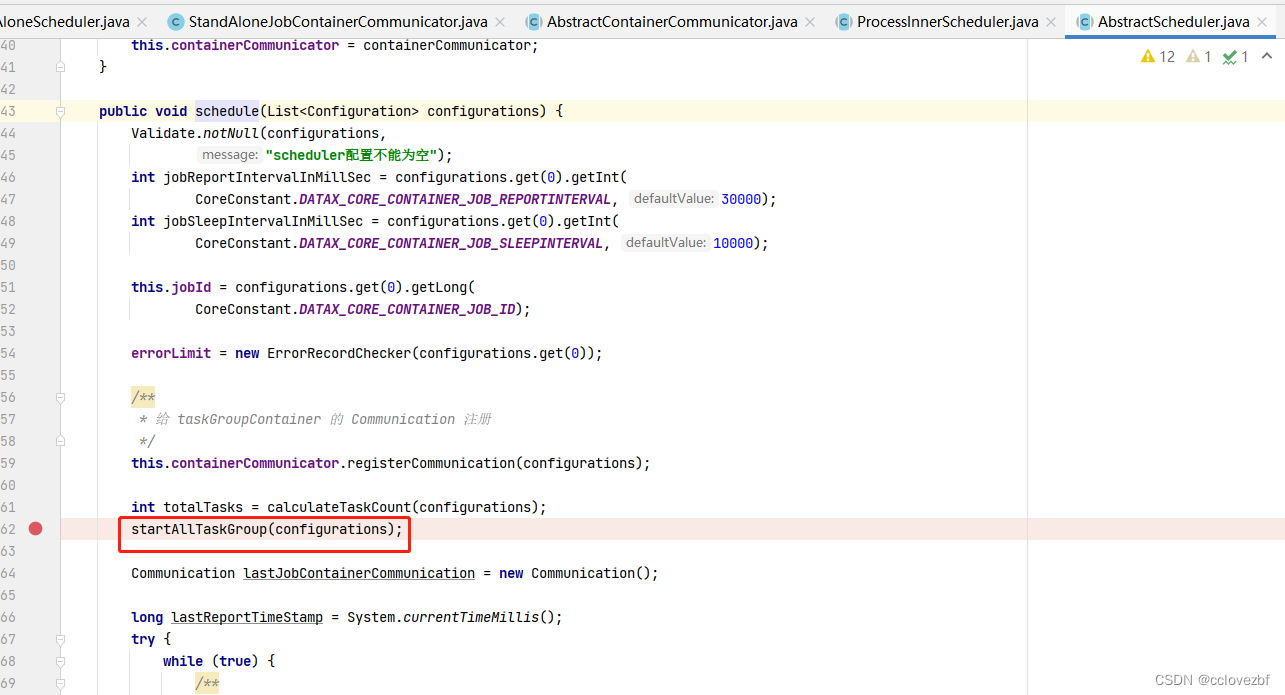
注意看此时是根据taskgroup为单位开始任务的
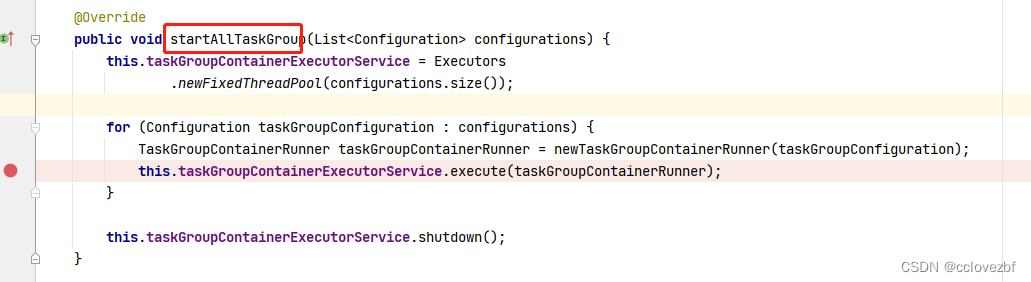
后面就很清楚了。就是开启线程池提交任务,然后就是监控任务。
那么我们任务实际的速度肯定和线程的个数有关,此时就开启了两个线程。
但是转眼一想不对啊 原先1个线程->2个线程,那任务不会提升那么明显。
接着看TaskGroupContainer的start 方法由于较长。截取关键的

判断正在运行的任务是否是小与channel数的,如果小于channel数,则让任务运行。这里的channel数因为在划分到taskgroup那个阶段也拆分了。所以每个taskGroup为5个channel。
那么我们从头梳理一下
1个job 2个taskGroup 10个channel 51个task。
实际上是将task划分到两个group管理,group1里可以同行运行5个task,group2里可以同时运行5个task,那么并发数量就是channel。
怎么验证的这个并发数?很简单继续看日志
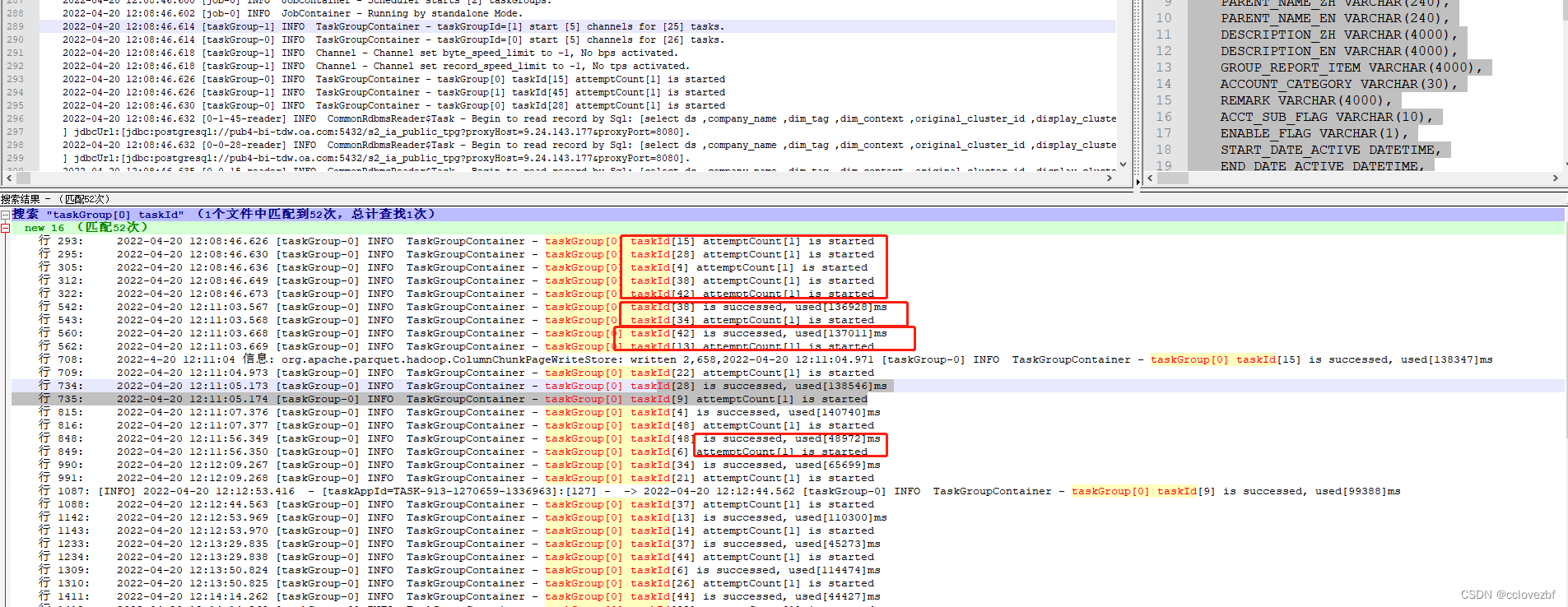
可以看到最开始就是5个start,然后就是1个end,紧接着一个又开始start。
只要有一个end 立马就有start,那么taskGroup[0]就是5个并发,和我们拆想的一样。
看datax的githu的介绍
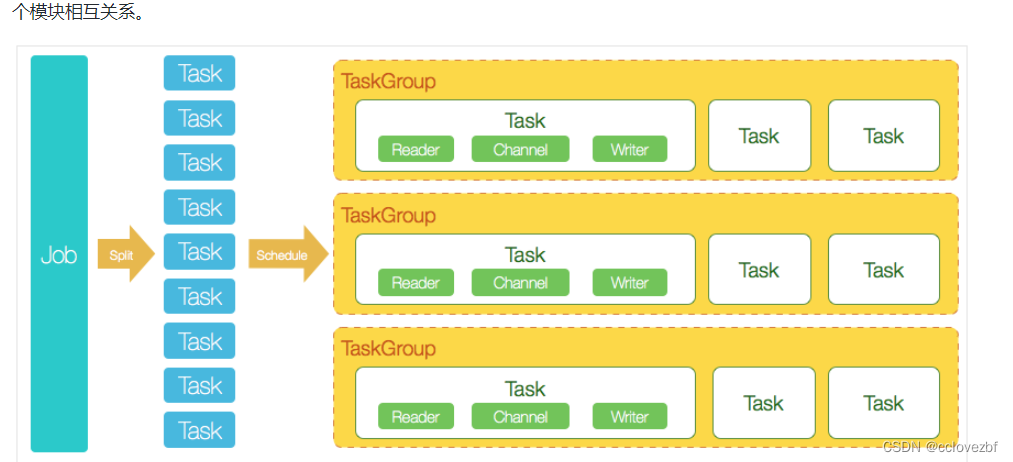
核心模块介绍:
- DataX完成单个数据同步的作业,我们称之为Job,DataX接受到一个Job之后,将启动一个进程来完成整个作业同步过程。DataX Job模块是单个作业的中枢管理节点,承担了数据清理、子任务切分(将单一作业计算转化为多个子Task)、TaskGroup管理等功能。
- DataXJob启动后,会根据不同的源端切分策略,将Job切分成多个小的Task(子任务),以便于并发执行。Task便是DataX作业的最小单元,每一个Task都会负责一部分数据的同步工作。
- 切分多个Task之后,DataX Job会调用Scheduler模块,根据配置的并发数据量,将拆分成的Task重新组合,组装成TaskGroup(任务组)。每一个TaskGroup负责以一定的并发运行完毕分配好的所有Task,默认单个任务组的并发数量为5。
- 每一个Task都由TaskGroup负责启动,Task启动后,会固定启动Reader—>Channel—>Writer的线程来完成任务同步工作。
- DataX作业运行起来之后, Job监控并等待多个TaskGroup模块任务完成,等待所有TaskGroup任务完成后Job成功退出。否则,异常退出,进程退出值非0
DataX调度流程:
举例来说,用户提交了一个DataX作业,并且配置了20个并发,目的是将一个100张分表的mysql数据同步到odps里面。 DataX的调度决策思路是:
- DataXJob根据分库分表切分成了100个Task。
- 根据20个并发,DataX计算共需要分配4个TaskGroup。
- 4个TaskGroup平分切分好的100个Task,每一个TaskGroup负责以5个并发共计运行25个Task。
根据上面的例子就是我说的 100个task 20个并发就是20个channel 20/5=4个taskgroup
每个taskgroup内的task 100/4=25
但是能够同时运行的任务是 20个channel =20个并发。
由此 我们得到什么结论?

这个参数就是代表了taskGroup的并发度。
那么此时我有一个疑问了?
1个taskGroup 管理50个任务 10个并发度
和切分后 2个taskGroup 分别管理25个任务和5个并发度,这两种有什么区别嘛?
说实话我是没有看出区别,但是datax这么设计应该还是有它的原因的。
未完待续。。后面使用过程中如果想到了再补充















 1660
1660











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









