







《OK-VQA: A Visual Question Answering Benchmark Requiring External Knowledge》这篇文章中提出了articlenet网络来编码提取出来的文章,文章中也提出了OK-VQA数据集。回答该数据集的问题是一项有挑战性的任务。
1、介绍
VQA使得我们能够在视觉和语言的联合空间中学习推理,也能够进行场景理解。然而,大部分的VQA都是针对简单的问题,比如计数,视觉属性,目标检测等,并未涉及到图像中的推理或者知识。因此,这篇文章将其标记为基于知识的视觉问答,并且提出OK-VQA,依据外部先验知识做出问答。作者自己新制作的数据集,超过14000个问题,这些问题都涉及到外部知识来回答。结果表明,相较于之前的基于知识的VQA数据集,此任务更多样且困难。
VQA的初衷,不仅是要完成视觉识别,还包括了逻辑推理和整合认知。但是目前的数据集往往只是针对的某些方面。并没有涉及逻辑推理或者整合外部知识。

问题涉及到了泰迪熊和美国总统的关系,仅从图上是无法获得答案的,但是如果用到了外部知识,比如维基百科,就能一下子知道答案:Teddy Roosevelt。
现有的一些模型也做了相关的工作,引入外部知识,然后多添加一步检索知识工作。而这篇文章则又在此基础上向前走了一步,作者对VQA数据集做了改进,数据集中涉及到大量推理过程,并提出了新模型OK-VQA(Outside Knowledge VQA)。模型的设计必须考虑以下内容:
1、了解回答问题所需的知识
2、确定从外部知识库检索必要知识的查询。
3、将知识从其原始表示中结合起来回答问题。
这篇文章的主要贡献在于:
1、设计了新的数据集,该数据集中的问题涉及到外部知识
2、其他VQA模型在新数据集上的表现很差
3、提出了使用非结构化知识的一系列流程
2、OK-VQA数据集
作者介绍了如何收集能够检测VQA模型性能的数据集。现有VQA数据集的大部分问题并不需要太多知识来回答,这些问题都是针对图像内容进行提问的,而不能够对图像外的信息进行推理。
数据集的制作当然是外包了出去,平台是亚马逊的MTurk(Amazon的Mturk是一个平台,用户既可以通过回答别人的调查问卷来挣些小钱,也可以发布调查问卷(当然自己要提供一些资金)获得结果),这里会对标注工人的年龄进行筛选,图像数据集来自COCO,约8万张训练4万张测试。在第一轮标记的过程中,我们会要求工人写出一个问题,这个问题最好能够骗过“聪明的机器人”,当然这个问题也需要和图像相关,同时,不能问图像中是什么,有多少个东西等这类简单直观的问题。第二轮标记的过程中,5个工人,每人都对一个问题给出一个答案。为了确保问题问的有意义,后期又对问题进行了筛选,原本86,700个问题最终筛选到34,921个问题。
另外需要考虑的一个问题是数据集的偏见(bias),在没有筛选的数据集中,有大量问题存在偏见,能够直接指示正确答案。比如大量的图片中都是有雪的,但是提问“这是什么季节?”,尽管数据集中还有其他季节的图像(但是很少),所以答案很自然的就指向了“冬天”。对于这部分的处理,作者将相同答案频率出现超过5次的问题全部删除。最后,还对回答者不统一的答案问题进行了删除。总计留下了14,055个问题,包括9009个训练问题和5046个测试问题。
下图就是数据集的一些例子,可以看到回答这些问题都是需要一些背景知识的:

为了更好地理解我们的数据集所需要的知识种类 ,我们让5名MTurk工人将每个问题注释为属于我们指定的十种知识中的一种。如果没有一个类别有多个工人,它就被归类为“其他”,这也确保了最后一个类别的标签是相互排斥的。
#问题
{"image_id": 408272, "question": "What are the most popular countries for this sport?", "question_id": 4082725}
#每个问题的标注
{"image_id": 408272, "answer_type": "other", "question_type": "four", "question_id": 4082725, "answers":
[{"answer_id": 1, "raw_answer": "brazil", "answer_confidence": "yes", "answer": "brazil"},
{"answer_id": 2, "raw_answer": "brazil", "answer_confidence": "yes", "answer": "brazil"},
{"answer_id": 3, "raw_answer": "brazil", "answer_confidence": "yes", "answer": "brazil"},
{"answer_id": 4, "raw_answer": "brazil", "answer_confidence": "yes", "answer": "brazil"},
{"answer_id": 5, "raw_answer": "france", "answer_confidence": "yes", "answer": "franc"}, {"answer_id": 6, "raw_answer": "france", "answer_confidence": "yes", "answer": "franc"}, {"answer_id": 7, "raw_answer": "england australia", "answer_confidence": "yes", "answer": "england australia"},
{"answer_id": 8, "raw_answer": "england australia", "answer_confidence": "yes", "answer": "england australia"},
{"answer_id": 9, "raw_answer": "european union", "answer_confidence": "yes", "answer": "european union"},
{"answer_id": 10, "raw_answer": "european union", "answer_confidence": "yes", "answer": "european union"}]}每张图片对应一个问题,每个问题对应十个答案,每张图片对应的每个问题及答案用"{ }"括起来,每个问题对应的十个答案用"[]"括起来 。
3. 数据集统计
知识类别Knowledge category:作者明确了10类知识,并要求标注者的问题必须在这10类之中,这些类别包括:车辆交通(Vehicles and Transportation)、商标公司产品(Brands,Companies and Products)、材料衣服(Objects, Materials and Clothing)、运动娱乐(Sports and Recreation)、烹饪(Cooking and Food)、人文地理(Geography, History, Language and Culture)、日常生活(People and Everyday Life, Plants and Animals)、科学技术(Science and Technology)、气候环境(Weather andClimate),其他(Other)。这10个类别的分布情况如下所示:
VQA数据集的比较Comparison with other VQA datasets:作者与一些常见的数据集做了比较:

问题统计Question statistics:OK-VQA数据集总计有14055个问题,其中唯一的问题有12591个,单词涉及7178个,图像来自于COCO,是COCO的一个子集。与所有这些数据集不同的是,该数据集关注的是关联图像中的信息无法回答的问题,这些问题需要外部知识来回答。之后作者对10类问题进行了统计,对唯一的单词进行了记录:
可以从中看到,问题中的一些单词可以明确的指明问题类别,而且与每一类的答案也是极其相关。
4. 基准(Benchmarking)
作者选择了一些VQA的模型进行比较。包括:
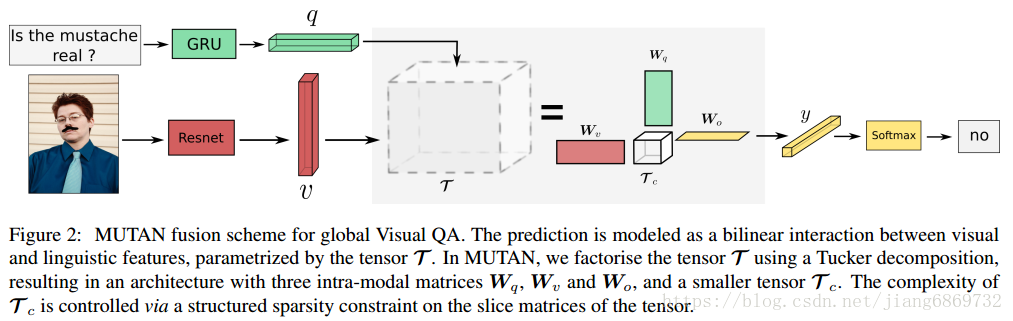
MUTAN(Multimodal Tucker Fusion):基于张量的模型
BAN(Bilinear Attention Networks):使用了协同注意力
MLP:3个隐含层
Q-Only:和MLP类似
ArticleNet (AN):基于知识的模型,从维基百科中检索文章的方式来寻找答案,检索分三步:①对问题中的单词识别②用维基百科API查找排序③对查找到的文章进行提取,对提取出的子集进行频率统计,找到词频最高的作为检索答案。检索完成之后则对检索出的句子进行编码送入网络,最后根据得分输出问题答案。网络结构如下所示:

网络的输入是问题q,从ImageNet获取的视觉特征V,维基百科文章的标题和文章中的T个句子。
简单的编码,比如一般的word2vec编码,或者使用skip思想,都不适合对长文章进行编码。 因此,作者训练一种特定于我们的数据的编码。我们在代理任务上对检索到的文章进行网络培训,以获得良好的表示。具体来说,我们训练ArticleNet,用来预测文章和每个句子中是否以及在何处出现正确答案。
作为补充,作者还使用了:
MUTAN + AN
BAN + AN
MUTAN/AN oracle
BAN/AN oracle
结果(Benchmark results):结果如下图所示:
 可以看到没有任何方法能够接近在标准VQA数据集上的得分(指2018年VQA开放式问答冠军得分72.41)。领完尽管AN的得分很低,但是它与其他模型结合却能提高得分。
可以看到没有任何方法能够接近在标准VQA数据集上的得分(指2018年VQA开放式问答冠军得分72.41)。领完尽管AN的得分很低,但是它与其他模型结合却能提高得分。
视觉特征简化(Visual feature ablation):前面实验的时候MUTAN用的是Res152来提取图像特征,那么不同深度的残差网络是否会对结果有影响,作者做了一个简化研究,结论看起来是越深越好:

尺度简化(Scale ablation):作者统计了数据集中训练集数量多少对得分的影响:

定性实例(Qualitative examples):下图的例子展示了外部知识是如何帮助VQA的:

BAN+AN
我们将Articlenet隐藏状态纳入BAN中,并将其与另一个存储网络集成到VQA管道中。在最终分类网络之前,我们将内存网络的输出与BAN隐藏状态连接。
def forward(self, v, b, q, labels):
"""Forward
v: [batch, num_objs, obj_dim]
b: [batch, num_objs, b_dim]
q: [batch_size, seq_length]
return: logits, not probs
"""
w_emb = self.w_emb(q)
q_emb = self.q_emb.forward_all(w_emb) # [batch, q_len, q_dim]
boxes = b[:,:,:4].transpose(1,2)
b_emb = [0] * self.glimpse
att, logits = self.v_att.forward_all(v, q_emb) # b x g x v x q
for g in range(self.glimpse):
b_emb[g] = self.b_net[g].forward_with_weights(v, q_emb, att[:,g,:,:]) # b x l x h
atten, _ = logits[:,g,:,:].max(2)
embed = self.counter(boxes, atten)
q_emb = self.q_prj[g](b_emb[g].unsqueeze(1)) + q_emb
#应把句子的隐藏层特征添加到q_emb中
q_emb = q_emb + self.c_prj[g](embed).unsqueeze(1)
logits = self.classifier(q_emb.sum(1))
return logits, attMUTAN+AN
我们使用句子的隐藏状态对MUTAN进行增强,这些语句隐藏状态来自于articlnet 。我们使用预测得分最高的句子(忽略重复语句),并将其输入端对端内存网络的内存中。存储网络的输出与第一个MUTAN融合层的输出连接。














 125
125











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









