










一、文章概况
文章题目:《OK-VQA: A Visual Question Answering Benchmark Requiring External Knowledge》
一作(也是通讯作者)是CMU的,在Allen Institute for AI实习期间的工作。一作的个人主页为[1],四作的个人主页为[2].
[1] Kenneth Marino的个人主页 (作者的个人主页似乎没有更新,看了下作者主要在做视觉推理)
[2] Roozbeh Mottaghi的个人主页 (原本是斯坦福的学者,后来去了Allen)
文章引用格式:K. Marino, M. Rastegari, A. Farhadi, R. Mottaghi. "OK-VQA: A Visual Question Answering Benchmark Requiring External Knowledge." In The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2019
项目地址:数据集作者公布在https://okvqa.allenai.org/
二、文章导读
文章较新,网上没有看到类似解读。先放上文章的摘要部分:
Visual Question Answering (VQA) in its ideal form lets us study reasoning in the joint space of vision and language and serves as a proxy for the AI task of scene understanding. However, most VQA benchmarks to date are focused on questions such as simple counting, visual attributes, and object detection that do not require reasoning or knowledge beyond what is in the image. In this paper, we address the task of knowledge-based visual question answering and provide a benchmark, called OK-VQA, where the image content is not sufficient to answer the questions, encouraging methods that rely on external knowledge resources. Our new dataset includes more than 14,000 questions that require external knowledge to answer. We show that the performance of the state-of-the-art VQA models degrades drastically in this new setting. Our analysis shows that our knowledge-based VQA task is diverse, difficult, and large compared to previous knowledge-based VQA datasets. We hope that this dataset enables researchers to open up new avenues for research in this domain.
VQA使得我们能够在视觉和语言的联合空间中学习推理,也能够进行场景理解。然而,大部分的VQA都是针对简单的问题,比如计数,视觉属性,目标检测等,并未涉及到图像中的推理或者知识。因此,这篇文章将其标记为基于知识的视觉问答,并且提出OK-VQA,依据外部先验知识做出问答。作者自己新制作的数据集,超过14000个问题,这些问题都涉及到外部知识来回答。结果表明该,相较于之前的基于知识的VQA数据集,此任务更多样且困难。
三、文章详细介绍
VQA的初衷,不仅是要完成视觉识别,还包括了逻辑推理和整合认知。但是目前的数据集往往只是针对的某些方面。并没有涉及逻辑推理或者整合外部知识。
比如下面这张图:

问题涉及到了泰迪熊和美国总统的关系,仅从图上是无法获得答案的,但是如果用到了外部知识,比如维基百科,就能一下子知道答案:Teddy Roosevelt。
现有的一些模型也做了相关的工作,引入外部知识,然后多添加一步检索知识工作。而这篇文章则又在此基础上向前走了一步,作者对VQA数据集做了改进,数据集中涉及到大量推理过程,并提出了新模型OK-VQA(Outside Knowledge VQA)。模型的设计必须考虑以下内容:(1)学习相关知识来回答问题(2)判断问题想要什么,然后从外部知识库检索相关知识(3)整合相关知识来回答问题。
这篇文章的主要贡献在于:
(a) we introduce the OK-VQA dataset, which includes only questions that require external resources to answer; (设计了新的数据集,该数据集中的问题设计到外部知识)
(b) we benchmark some state-of-theart VQA models on our new dataset and show the performance of these models degrades drastically; (其他VQA模型在新数据集上的表现很差)
(c) we propose a set of baselines that exploit unstructured knowledge。(提出了使用非结构化知识的一系列流程。)
1. 相关工作
视觉问答Visual Question Answering (VQA):早期的VQA模型是用循环网络和CNN来提取问题特征和图像特征;之后基于注意力的VQA模型能够定位到图像和问题中的关键区域;再有提出模块化的方法。近期对于VQA则是放在交互环境(interactive environment)中进行处理。然而这些方法都没有用到外部知识。目前关于基于知识的VQA,大部分用的都是监督方法来检索知识,采用subject-relation-object或visual concept-relationattribute元组来表示特征,而本文的方法则是处理非结构化数据。
数据集VQA datasets:目前已经发布了很多数据集,包括DAQUAR、FM-IQA、Visual Madlibs、COCO-QA、Visual 7W、Visual Genome、MovieQA、CLEVR、FVQA、
知识库和知识推理Building knowledge bases & Knowledge-based reasoning:目前已有一些成果,作者也给出了相关参考文献。
2. OK-VQA数据集
作者介绍了如何收集能够检测VQA模型性能的数据集。现有VQA数据集的大部分问题并不需要太多知识来回答,这些问题都是针对图像内容进行提问的,而不能够对图像外的信息进行推理。
数据集的制作当然是外包了出去,平台是亚马逊的MTurk,这里会对标注工人的年龄进行筛选,图像数据集来自COCO,约8万张训练4万张测试。在第一轮标记的过程中,我们会要求工人写出一个问题,这个问题最好能够骗过“聪明的机器人”,当然这个问题也需要和图像相关,同时,不能问图像中是什么,有多少个东西等这类简单直观的问题。第二轮标记的过程中,5个工人,没人都对一个问题给出一个答案。为了确保问题问的有意义,后期又对问题进行了筛选,原本86,700个问题最终筛选到34,921个问题。
另外需要考虑的一个问题是数据集的偏见(bias),在没有筛选的数据集中,有大量问题存在偏见,能够直接指示正确答案。比如大量的图片中都是有雪的,但是提问“这是什么季节?”,尽管数据集中还有其他季节的图像,但是很少,所以答案很自然的就指向了“冬天”。对于这部分的处理,作者将相同答案频率出现超过5次的问题全部删除。最后,还对回答者不统一的答案问题进行了删除。总计留下了14,055个问题,包括9009个训练问题和5046个测试问题。
下图就是数据集的一些例子,可以看到回答这些问题都是需要一些背景知识的:

3. 数据集统计
知识类别Knowledge category:作者明确了10类知识,并要求标注者的问题必须在这10类之中,这些类别包括:车辆交通(Vehicles and Transportation)、商标公司产品(Brands,Companies and Products)、材料衣服(Objects, Materials and Clothing)、运动娱乐(Sports and Recreation)、烹饪(Cooking and Food)、人文地理(Geography, History, Language and Culture)、日常生活(People and Everyday Life, Plants and Animals)、科学技术(Science and Technology)、气候环境(Weather andClimate),其他(Other)。这10个类别的分布情况如下所示:
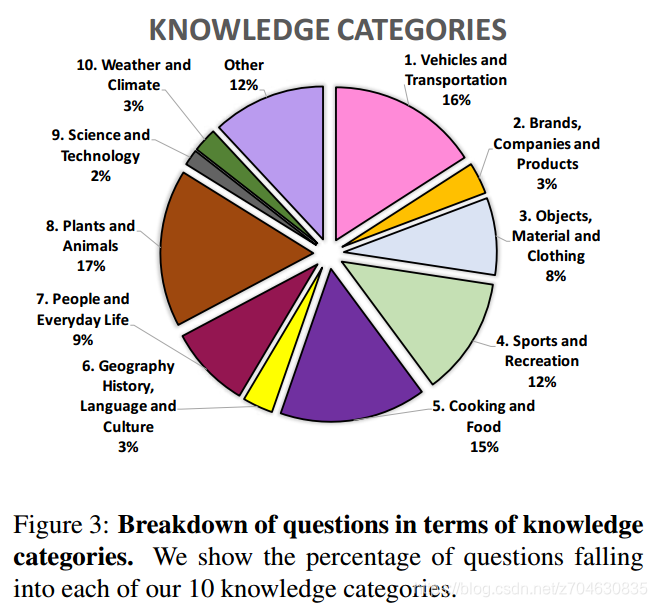
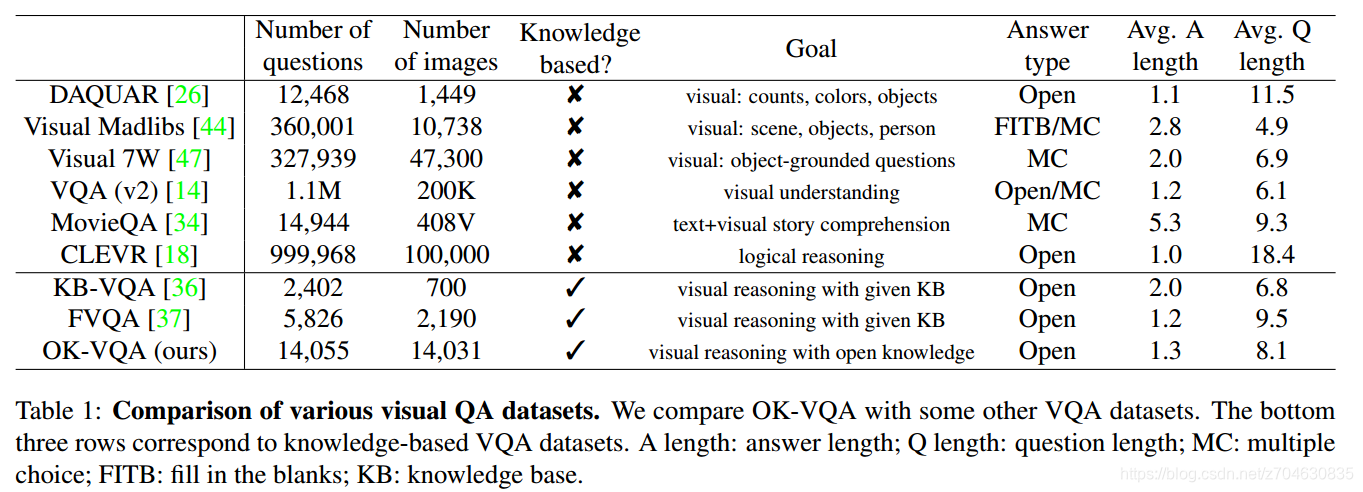
VQA数据集的比较Comparison with other VQA datasets:作者比较了一些常见的数据集:
问题统计Question statistics:OK-VQA数据集总计有14055个问题,其中唯一的问题有12591个,单词涉及7178个,图像来自于COCO,是COCO的一个子集。用Places2来分析场景类别,大概有超过365景,包含5个类别:猎人小屋(hunting lodge),大厦(mansion),电影院(movie theater),下雨(ruin)和火山(volcano)。之后作者对10类问题进行了统计,对唯一的单词进行了记录:

可以从中看到,问题中的一些单词可以明确的指明问题类别,而且与每一类的答案也是极其相关。
4. 基准(Benchmarking)
作者选择了一些VQA的模型进行比较。包括:
MUTAN(Multimodal Tucker Fusion):基于张量的模型
BAN(Bilinear Attention Networks):使用了协同注意力
MLP:3个隐含层
Q-Only:和MLP类似
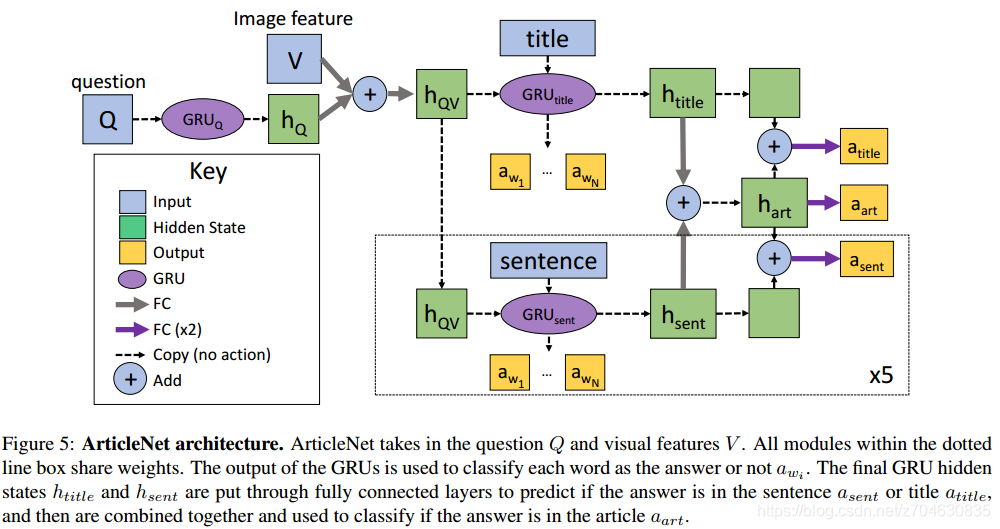
ArticleNet (AN):基于知识的模型,从维基百科中检索文章的方式来寻找答案,检索分三步:①对问题中的单词识别②用维基百科API查找排序③对查找到的文章进行提取,对提取出的子集进行频率统计,找到词频最高的作为检索答案。检索完成之后则对检索出的句子进行编码送入网络,最后根据得分输出问题答案。网络结构如下所示:
作为补充,作者还使用了:
MUTAN + AN
BAN + AN
MUTAN/AN oracle
BAN/AN oracle
结果(Benchmark results):结果如下图所示:
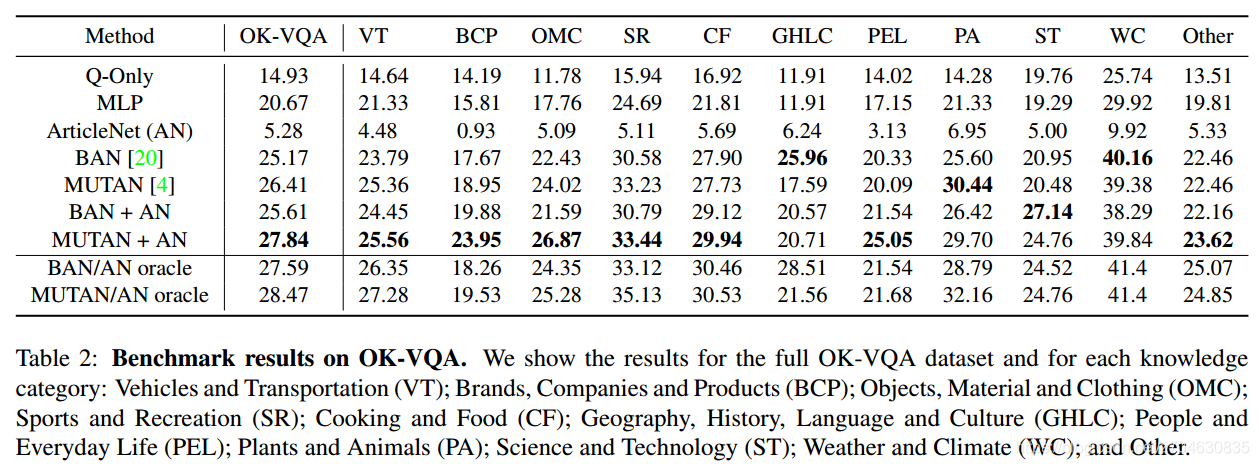
可以看到没有任何方法能够接近在标准VQA数据集上的得分(指2018年VQA开放式问答冠军得分72.41)。领完尽管AN的得分很低,但是它与其他模型结合却能提高得分
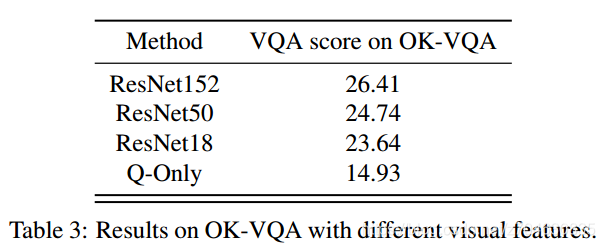
视觉特征简化(Visual feature ablation):前面实验的时候MUTAN用的是Res152来提取图像特征,那么不同深度的残差网络是否会对结果有影响,作者做了一个简化研究,结论看起来是越深越好:
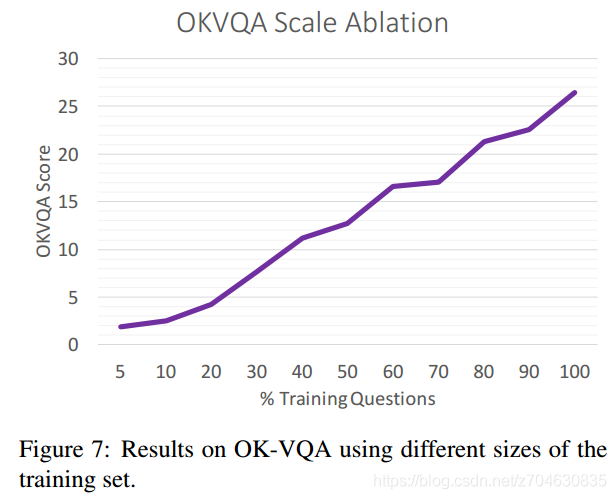
尺度简化(Scale ablation):作者统计了数据集中训练集数量多少对得分的影响:
定性实例(Qualitative examples):下图的例子展示了外部知识是如何帮助VQA的:



















 5693
5693

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











