







PageRank算法
又名佩奇排名,是一种由网页之间相互的超链接计算的技术。以Google公司创办人拉里,佩奇的姓命名。Google的创始人拉里•佩奇和谢尔盖•布林于1998年在斯坦福大学发明了这项技术。

Google不断的重复计算每个页面的PageRank。如果给每个页面一个随机PageRank值(非0),那么经过不断的重复计算,这些页面的PR值会趋向于稳定,也就是收敛的状态。这就是搜索引擎使用它的原因。
协同过滤算法(Collaborative Filtering)
原理是利用某兴趣相投、拥有共同经验之群体的喜好来推荐用户感兴趣的信息,个人通过合作的机制给予信息相当程度的回应(如评分)并记录下来以达到过滤的目的进而帮助别人筛选信息,回应不一定局限于特别感兴趣的,特别不感兴趣信息的纪录也相当重要。
算法细分
以用户为基础(User-based)的协同过滤:
用相似统计的方法得到具有相似爱好或者兴趣的相邻用户,所以称之为以用户为基础(User-based)的协同过滤或基于邻居的协同过滤(Neighbor-based Collaborative Filtering)。 方法步骤:
- 收集用户信息
收集可以代表用户兴趣的信息。一般的网站系统使用评分的方式或是给予评价,这种方式被称为“主动评分”。另外一种是“被动评分”,是根据用户的行为模式由系统代替用户完成评价,不需要用户直接打分或输入评价数据 - 最近邻搜索(Nearest neighbor search, NNS)
以用户为基础(User-based)的协同过滤的出发点是与用户兴趣爱好相同的另一组用户,就是计算两个用户的相似度。例如:查找n个和A有相似兴趣用户,把他们对M的评分作为A对M的评分预测。 - 产生推荐结果
有了最近邻集合,就可以对目标用户的兴趣进行预测,产生推荐结果。依据推荐目的的不同进行不同形式的推荐,较常见的推荐结果有Top-N 推荐和关系推荐。Top-N 推荐是针对个体用户产生,对每个人产生不一样的结果,例如:通过对A用户的最近邻用户进行统计,选择出现频率高且在A用户的评分项目中不存在的,作为推荐结果。关系推荐是对最近邻用户的记录进行关系规则(association rules)挖掘。
以项目为基础(Item-based)的协同过滤
以用户为基础的协同推荐算法随着用户数量的增多,计算的时间就会变长,所以在2001年Sarwar提出了基于项目的协同过滤推荐算法(Item-based Collaborative Filtering Algorithms)。以项目为基础的协同过滤方法有一个基本的假设“能够引起用户兴趣的项目,必定与其之前评分高的项目相似”,通过计算项目之间的相似性来代替用户之间的相似性。 方法步骤:
- 收集用户信息
同以用户为基础(User-based)的协同过滤。 - 针对项目的最近邻搜索
先计算已评价项目和待预测项目的相似度,并以相似度作为权重,加权各已评价项目的分数,得到待预测项目的预测值。例如:要对项目 A 和项目 B 进行相似性计算,要先找出同时对 A 和 B 打过分的组合,对这些组合进行相似度计算,常用的算法同以用户为基础(User-based)的协同过滤。 - 产生推荐结果
以项目为基础的协同过滤不用考虑用户间的差别,所以精度比较差。但是却不需要用户的历史数据,或是进行用户识别。对于项目来讲,它们之间的相似性要稳定很多,因此可以离线完成工作量最大的相似性计算步骤,从而降低了在线计算量,提高推荐效率,尤其是在用户多于项目的情形下尤为显著。
以模型为基础(Model- based)的协同过滤
以用户为基础(User-based)的协同过滤和以项目为基础(Item-based)的协同过滤统称为以记忆为基础(Memory based)的协同过滤技术,他们共有的缺点是数据稀疏,难以处理大数据量影响即时结果,因此发展出以模型为基础的协同过滤技术。 以模型为基础的协同过滤(Model-based Collaborative Filtering)是先用历史数据得到一个模型,再用此模型进行预测。以模型为基础的协同过滤广泛使用的技术包括Latent Semantic Indexing、Bayesian Networks…等,根据对一个样本的分析得到模型。
基于内容的推荐(Content-based Recommendations)
它根据用户过去喜欢的产品(本文统称为 item),为用户推荐和他过去喜欢的产品相似的产品。例如,一个推荐饭店的系统可以依据某个用户之前喜欢很多的烤肉店而为他推荐烤肉店。CB最早主要是应用在信息检索系统当中,所以很多信息检索及信息过滤里的方法都能用于CB中。
CB的过程一般包括以下三步:
- Item Representation:为每个item抽取出一些特征(也就是item的content了)来表示此item;
- Profile Learning:利用一个用户过去喜欢(及不喜欢)的item的特征数据,来学习出此用户的喜好特征(profile);
- Recommendation Generation:通过比较上一步得到的用户profile与候选item的特征,为此用户推荐一组相关性最大的item。
聚类分析(clustering analysis)和多元回归模型(multiple regression model)
聚类与分类的区别:
聚类:无监督学习,类的形成是无人管理的。聚类根据数据来发掘数据对象及其相关信息,并将这些数据分组。每个组内的对象是相似的,各个组间的对象是不相关的。组内相似性越高,组间相异性越高,则聚类越好。
分类:监督学习,类的形成是人为干预的。分类是分析已有数据,寻找共同属性,并根据分类模型划分成不同类别,这些类别是事先定义好的,类别数是已知的。
关联分析算法(association analysis)
基本概念
关联分析(Association Analysis):在大规模数据集中寻找有趣的关系。
频繁项集(Frequent Item Sets):经常出现在一块的物品的集合。
关联规则(Association Rules):暗示两个物品之间可能存在很强的关系。
支持度(Support):数据集中包含该项集的记录所占的比例,是针对项集来说的。

{豆奶} :支持度为3/5.
{橙汁}:支持度为3/5.
{尿布}:支持度为3/5.
{啤酒}:支持度为4/5.
{啤酒,尿布}:支持度为3/5.
置信度(Confidence):出现某些物品时,另外一些物品必定出现的概率,针对规则而言。
规则1:{尿布}–>{啤酒},表示在出现尿布的时候,同时出现啤酒的概率。
该条规则的置信度被定义为:支持度{尿布,啤酒}/支持度{尿布}=(3/5)/(3/5)=3/3=1
规则2:{啤酒}–>{尿布},表示在出现啤酒的时候,同时出现尿布的概率。
该条规则的置信度被定义为:支持度{尿布,啤酒}/支持度{啤酒}=(3/5)/(4/5)=3/4
{橙汁,豆奶,啤酒}:支持度为2/5.
关联分析步骤
发现频繁项集,即计算所有可能组合数的支持度,找出不少于人为设定的最小支持度的集合。
发现关联规则,即计算不小于人为设定的最小支持度的集合的置信度,找到不小于认为设定的最小置信度规则。
朴素贝叶斯方法(Naive Bayes):
贝叶斯公式:
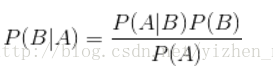
朴素的意思是:各特征之间相互独立















 842
842

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









