







一、解决的问题
解决两个问题:
1.现有的RAG是通过把检索到的结果和查询直接放到llm中进行生成结果,具有不可解释性和预测性。传统 RAG 方法不专门处理噪音,而是通过让模型在带噪音的数据上进行训练,使其具备在噪音中生成正确答案的能力。
2.在训练模型的时候,提供明确、准确的标注数据是很困难的。
3.缺乏完美的检索解决方案,检索到的内柔通常由不相关的、噪声。
4.语料库中存在噪声数据。
二、提出的解决方法
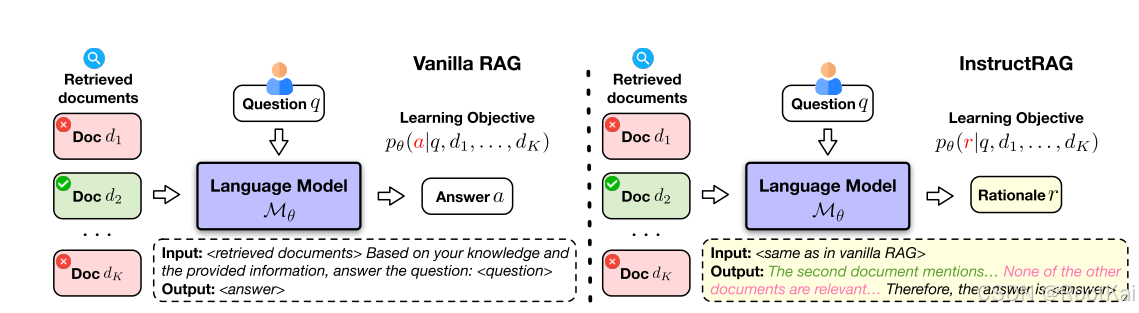
提出:通过LLM通过自合成原理明确的学习去噪过程,能够显式的对检索到的信息去噪,并通过生成去噪相应来证明预测的最终答案:
首先:语言模型在生成答案时,还需要生成一段解释性文本,说明它如何使用检索到的文档来得出这个答案。称为理由也是推理过程(rationales)
然后:生成的推理(理由)
- 将这些推理过程作为示范样例,用于上下文学习,上下文学习指的是在提示中加入示例,引导模型在生成时模仿这种示范,从而学会显式地去噪(即在生成答案时主动识别并剔除噪音信息)。
- 通过将模型自生成的推理过程与真实答案进行对比,使用监督学习对模型进行微调,从而让模型在未来能够更好地解释和去噪。
这个方法的有效性:归因于lm较强的指令跟随能力,这是在RAG背景下仍未充分探索的一个重要特征。
三、方法详解
先导:
方法由两个步骤构成:
1.向一个经过指令微调的语言模型(即推理生成器Mϕ)提供提示,让它生成用于去噪监督的推理过程
Please identify documents that are useful to answer the given question: {qi}, and explain how the contents lead to the answer: {ai}
2.引导LM(即基本原理学习者Mθ)通过利用这些基本原理作为上下文学习演示或监督微调数据(§2.3)来学习显式去噪。
注意:默认情况下:推理生成器和基本原理学习器是同一个指令微调模型
采用标准的 RAG 设置,在这种设置中,语言模型 Mθ 可以访问下游任务的标注数据集(例如,问答任务 T={⟨q,a⟩}),以及一个带有现成检索器 RRR 的外部知识库,用于检索信息。本文假设模型在训练和推理时只能访问下游任务数据和外部知识库,而不会使用 GPT-3/GPT-4 等强大的外部生成监督。
使用现成的检索器,不进行任何过滤或重新排序。
1.基本原理生成器
出发点就是LLM的指令跟随能力很强。所以,我们给定问题答案对和一组检索到的文档,利用去噪指令,提示基本原理生成器,生成相应的原理,将有用的文档和嘈杂的文档区分开,并解释这些文档如何产生真实答案。
使用字符串匹配来评估生成的基本原理和真实答案的一致性。如果检索到的文档中至少有一篇包含真实答案可以将这些推理过程用作一致性检查(sanity check),验证模型推理的合理性。
然后,增强数据集:T=(q,a)----->T`=(q,r)
2.学习去噪的基本原理
开发一个基本的原理学习器,通过有效的学习策略直接学习RAG任务的显示去噪。
两种学习策略:
INSTRUCTRAG-ICL:
不用训练,模型通过上下文学习去噪过程
INSTRUCTRAG-FT:
它通过具有标准语言建模目标的监督微调(FT)来学习去噪原理。
四、实验
1.数据集:
PopQA 、TriviaQA 、Natural Questions 、ASQA 和2WikiMultiHopQA 。
分别在这5个数据集上验证提出的方法
2.评估指标:
Recall@K测量检索质量,表明检索的K个文档是否包含正确答案。
- 对ASQA (Gao等人,2023a)采用了正确性(str-em)、引用精度(pre)和召回率(rec)的官方度量
- 其他数据集使用准确率(accuracy):衡量模型生成的答案中是否包含真实答案。
此外还是用LLM进行评估语义
3.基线:
无检索的LLM
RAG 基线方法:
- RALM(上下文检索增强语言建模):通过检索外部文档来增强模型生成的能力。
- 带指令的少量示范(ICL 方法):通过提供少量真实的问答对示范,帮助模型理解任务。
这些方法在没有额外训练的情况下,都能依靠预训练的知识或检索到的信息进行推理。
标准的 RAG 基线上进行微调:
- Vanilla SFT 是最基础的微调方法,侧重于通过监督学习最大化正确答案的概率。
- RetRobust 专注于增强模型对无关上下文的鲁棒性。
- Self-RAG 利用特殊的反射标记来控制自适应检索过程,以提高模型的表现。
采用指令调优的Llama-3作为主干模型,使用Llama-3- instruct8b训练RetRobust和Self-RAG,并通过广泛的超参数搜索优化它们的性能。
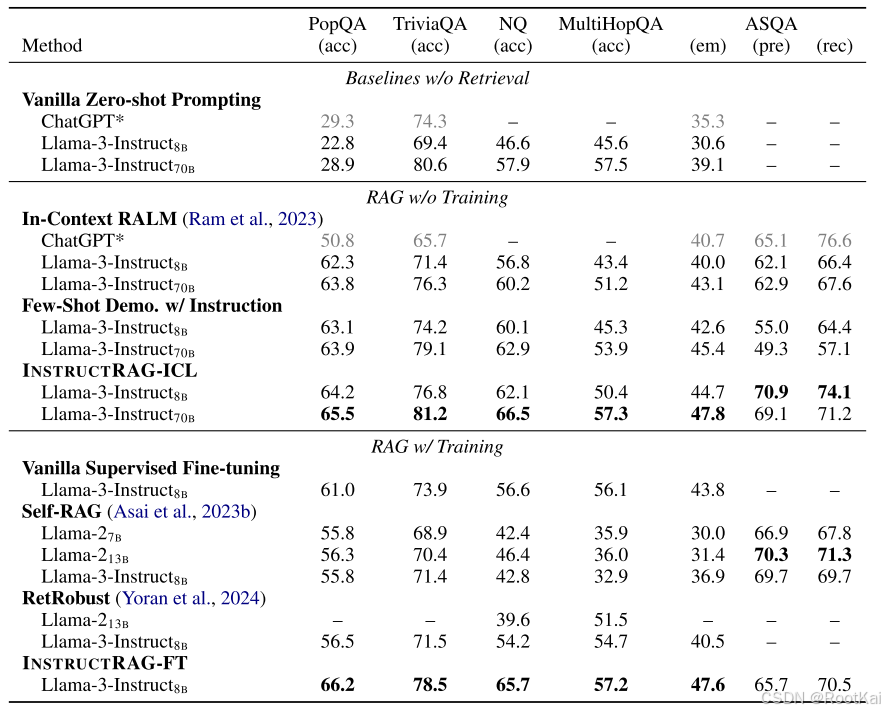
4.实验结果
5.实现细节
检索设置:
使用来自维基百科转储作为本工作中研究的所有五个基准的外部检索语料库,其中每个文档是从维基百科文章中提取的最多100个单词的不相交文本块。
比较了不同检索环境下的所有RAG方法,包括各种稀疏和密集检索器以及检索文档的数量。
具体来说,我们使用Contriever-MS MARCO作为PopQA和TriviaQA的检索器,DPR用于自然问题,GTR用于ASQA, BM25用于2WikiMultiHopQA。
我们从除2WikiMultiHopQA之外的所有任务中的每个查询的检索语料库中检索前5个文档,在2WikiMultiHopQA中检索前10个文档。
我们对所有密集检索器使用官方权重,并对稀疏检索器BM25使用Pyserini (Lin et al., 2021)的实现。
训练细节:
默认情况下,所有模型都使用Adam优化器(Kingma & Ba, 2014)进行2个epoch的训练,批大小为128,学习率为2.5e-5,余弦学习率计划为3%的预热步骤。
对于可训练基线香草SFT,我们基于超参数搜索结果使用稍微不同的学习率25 -5。
为了公平地与Self-RAG和RetRobust进行比较,我们使用llama -3- directive - 8b重新实现它们。
我们还通过在[8e-6, 1e-5, 2e-5]和[1,2,3]的训练时期进行广泛的超参数搜索来优化它们的性能。
对于Self-RAG,我们使用单个训练历元的学习率为1e-5。
对于RetRobust,我们使用25 -5的学习率和两个训练时期。
唯一的例外是RetRobust在2WikiMultiHopQA上的训练,我们在原作者发布的增强训练集上训练了5个epoch的模型。所有模型的最大令牌长度固定为4096。
推理细节:
默认情况下,在INSTRUCTRAG-ICL和基线方法少量样本学习演示中使用的演示次数设置为2。
我们使用vLLM (Kwon et al., 2023)加载模型进行内存高效推理,并采用贪婪解码策略进行模型生成。
术语解释:
1.域内任务:指的是模型在训练数据所属领域或主题上进行推理或生成任务。
2.域外泛化:指的是模型在未见过的新领域或新任务上的表现。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









