







一、动机
不完美的检索器、现实中的数据噪声很大,检索到的信息于查询无关,从而导致模型生成错误的 结果。近期的一些解决方案:采用过滤模块,但是这些方法有一些问题:
(1) 无法确保注释后的过滤结果能够有效支持生成模型准确回答问题;
(2) 在面对无法支持问题解答的检索证据时,过滤器难以判断是否应放弃作答;
(3) 缺乏对过滤结果压缩程度的适应性,从而难以在成本与性能之间达到最优平衡。
过滤器相关的论文(本文提到的):
改进检索器:
- FLARE(Jiang 等,2023c)和Self-RAG(Asai 等,2023)致力于训练模型,使其能够主动地检索和过滤检索内容。
- REPLUG(Shi 等,2023b)通过计算检索器和大型语言模型之间的KL散度,改进了检索器。
提出过滤模块:
- 噪声过滤,可以帮助缓解这些问题。Bai 等(2023)集中于对检索到的文章进行重新排序,以过滤噪声。
- 一些方法,如 Selective Context(Li,2023)和 LLMLINGUA(Jiang 等,2023a),利用小型语言模型来衡量提示的互信息或困惑度,找出得分最高的元素。
采用摘要技术:
- 一些方法采用摘要技术来设计压缩器(Xu 等,2023;Wang 等,2023)。TCRA-LLM(Liu 等,2023)和 LONGLLMLINGUA(Jiang 等,2023b)结合了摘要和语义压缩技术
- PRCA(Yang 等,2023b)也在模型训练中引入了强化学习算法
- 然而,这些压缩方法并未对压缩结果进行统一评估。RECOMP(Xu 等,2023)实现了6%的压缩率,但以牺牲性能为代价。
二、解决方法
✅ 背景
-
在RAG系统中,模型先从知识库中检索一些段落(X),然后基于这些段落来生成答案(Y)。
-
但问题来了:检索到的内容里往往夹杂着很多没用的、甚至是错误的内容(也就是“噪声”)。
-
所以我们需要一个“噪声过滤器”,从X中提取出对Y有用的信息(记作压缩后的 X~)。
❌ 当前做法的问题
-
目前的过滤器是通过一个叫“最大似然估计”的目标来训练的,简单说就是:“我训练过滤器,目的是为了让生成模型更容易生成出Y。”
-
这种做法虽然能提取出一些对Y有用的信息,但没法准确界定哪些信息是有用的,哪些是噪声。
-
换句话说:现在的过滤器可能会“保留一些无用信息”或者“漏掉一些有用信息”。
✅ 新的提议:信息瓶颈理论(Information Bottleneck)
-
利用信息瓶颈理论从整体角度优化噪声过滤器,通过最大化有用信息的同时最小化噪声信息
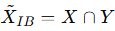
-
如果检索对于内容生成并非必要或效果有限,信息瓶颈目标还能使噪声过滤器将检索段落压缩为空
具体做法:
首先,我们从理论上推导出适用于结合大型语言模型的检索增强生成的信息瓶颈公式。
随后,我们将信息瓶颈引入为一种新的综合评估指标,用于评估噪声过滤的效果,衡量压缩内容的简洁性与正确性。
接着,我们还推导出基于信息瓶颈的有监督微调目标和强化学习目标,用于训练噪声过滤器。
三、方法细节
1.噪声过滤
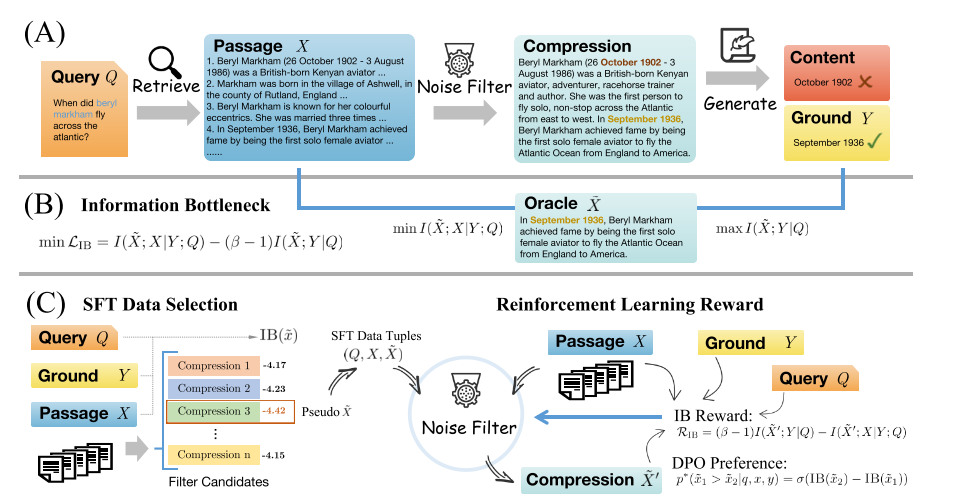
RAG:根据查询检索到一些段落,然后推进LLM进行生成答案,目前的过滤噪音的做法:从检索到的大段落X中,选出一部分压缩后的内容,然后让,LLM在这些内容的基础上尽可能好的生成答案,训练目标通常是最大化:
![]()
这个目标的本质就是:![]() 它衡量的是在给定问题的条件下,压缩后的内容和正确答案之间的信息量。问题就在这里: 这种方法虽然让生成模型更倾向于输出正确答案,但并不能保证这些压缩内容中没有无关的信息(噪声)。也就是说,压缩过程本身可能还不够“干净”或“精准”。
它衡量的是在给定问题的条件下,压缩后的内容和正确答案之间的信息量。问题就在这里: 这种方法虽然让生成模型更倾向于输出正确答案,但并不能保证这些压缩内容中没有无关的信息(噪声)。也就是说,压缩过程本身可能还不够“干净”或“精准”。
提出:在查询 Q 条件下,检索段落 X 与目标输出 Y 之间的信息瓶颈。
所以,现在的过滤器的目标:
-
最大化其压缩结果与目标输出之间的互信息
-
最小化其压缩结果与原始检索内容之间的互信息
目标的表达式:


简而言之:
-
简洁性是:压缩得越狠,越无法从中恢复出原始文段(信息越少越好)。
-
正确性是:保留足够多的信息,能让模型生成正确答案(信息越多越好)。
-
整个信息瓶颈的目标就是在这两者之间取得最优平衡。
信息瓶颈不仅仅是一种方法论,更是一项可以应用于检索增强生成(Retrieval-Augmented Generation, RAG)中的基本原则。在本节中,我们将阐述信息瓶颈的三种具体应用方式,包括:
-
构建用于噪声过滤效果评估的指标,
-
用于生成监督微调(SFT)训练数据集,
-
设计强化学习中的奖励函数。
2.评估指标
信息瓶颈(Information Bottleneck, IB)被用作一个重要的评估指标。
![]()
公式的第一项:模型在知道了问题、压缩内容和答案后,是否还能“还原”出原始内容 x。
👉 越低,说明压缩掉了很多无用内容,达到了“去噪”目的。
公式的第二项:模型在看到问题和压缩内容时,是否还能生成正确答案 y。
👉 越高越好,说明压缩内容中保留了有用信息。
| 分数低 | ✅ 好的压缩 | 表示:去掉了无关内容(噪声),还能正确回答问题 |
|---|
| 分数高 | ❌ 差的压缩 | 要么没压缩干净、要么压掉了关键信息,生成效果差 |
3.SFT
我们想训练一个「噪声过滤器」,它的任务是从检索到的大段文本里,筛选出对回答问题真正有用的内容,去掉多余的废话(也就是噪声)。
但有个问题: 👉 没有人手动标注“什么是最精简、最有用的内容”,也就是没有所谓的「标准答案」可以让我们用来训练过滤器。
🤔 怎么办?
那就要靠算法自己去“猜”哪些内容保留效果最好。但问题是:
-
一段文本里可能有成千上万种组合(比如保留哪些句子、去掉哪些),
-
我们不可能把所有组合都试一遍。
🧠 解决思路:用「蒙特卡洛采样」
我们不试完所有组合,而是:
-
利用已有的一些压缩方法(比如别人提出的算法)来生成几个候选压缩版本。
-
用我们之前说的「IB 分数(信息瓶颈评分)」来评估每一个候选版本的效果。
-
挑出效果最好的那个版本,把它当成“伪标准答案”(pseudo ˜x)。
📦 然后做什么?
拿这些伪标准答案,组成训练数据 {(q, x, ˜x)},来训练我们自己的过滤器模型。
这个模型学会了:“如果输入是 x 和 q,应该压缩出 ˜x 这样的内容”。
4.强化学习
🏋️♀️ 为什么用强化学习?
我们想训练一个“过滤器”,但:
-
没有人类标注告诉我们“保留哪几句话最合适”;
-
虽然理论上可以用“信息瓶颈评分”来找最佳压缩,但那太难算了(涉及全空间搜索和积分)。
于是我们换个策略 —— 和 RLHF(强化学习对齐 LLM)一样,用强化学习来**“学会选择最好的压缩”**。
🎯 核心思想
我们提出了一个评分机制,叫做:
💡 IB Score(信息瓶颈分数):衡量压缩内容(x~\tilde{x}x~)的质量,得分越低表示压缩得越好(少但有用的信息)。
然后我们用这个 IB Score 来当作偏好标签,让噪声过滤器自己去“试错 + 学习”。
🎁 一句话总结
我们用强化学习 + 信息瓶颈打分,让噪声过滤器学会:
-
保留有用信息;
-
去除无关内容;
-
让 RAG 的上下文输入变得更短更准更强。
四、实验

















 875
875

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









