






Docker 系列文章
第四章 kubernetes
文章目录
前言
提示。
一、Kubernetes入门
1.1.kubernetes 是什么
Kubernetes,简称 k8s, 首先它是一个全新的基于容器技术的分布式架构领先方案,是 Google 基于 Borg(基于容器的大规模集群管理系统) 的一个开源的,用于管理云平台中多个主机上的容器化的应用。它支持自动化部署、大规模可伸缩、应用容器化管理。
Kubernetes是一个开放的开发平台。它不局限语言,没有限定编程接口,任何语言编写的服务都可以被映射为 k8s 的 Service 并通过标准的TCP通信协议进行交互。此外它对现有的编程语言、 编程框架、 中间件没有任何侵入性, 因此现有的系统也很容易改造升级并迁移到Kubernetes平台上。
Kubernetes是一个完备的分布式系统支撑平台。具有完备的集群管理能力,包括多层次的安全防护和准入机制、多租户应用支撑能力、透明的服务注册和发现机制、內建智能负载均衡器、强大的故障发现和自我修复能力、服务滚动升级和在线扩容能力、可扩展的资源自动调度机制以及多粒度的资源配额管理能力。同时提供了完善的管理工具,涵盖了包括开发、部署测试、运维监控在内的各个环节。
1.2.为什么要用 kubernetes
目前云原生生态是一种趋势。市面上越来越多公司都将 k8s 作为底层平台,未来会有更多系统选择 k8s。
降低运维难度和成本。k8s 自身提供的一系列解决方案能使我们节省不少于 30% 的开发成本,让我们将经历更加集中于业务本身。其强大的自动化机制使得系统的运维难度和成本大幅度降低。
无缝迁移。越来越多公有云和私有云先后宣布支持 k8s 集群,同时 k8s 架构中完全屏蔽了底层网络细节,我们无需改变运行期的配置文件,就可以将系统从物理机环境迁移到公有云上。
弹性扩容机制轻松应对突发流量。在服务高峰期可以扩容服务实例副本来提升系统的吞吐量。此外利用 k8s 提供的工具可以不用修改代码在线完成集群扩容,配合合理的微服务架构设计能再云环境中进行弹性伸缩。
1.3.kubernetes 的基本概念
1.3.1.Master
Kubernetes 里的 Master 指的是集群控制节点,在每个 Kubernetes 集群里都需要有一个Master来负责整个集群的管理和控制,基本上 Kubernetes 的所有控制命令都发给它,它负责具体的执行过程,我们后面执行的所有命令基本都是在 Master 上运行的。
1.3.2. Node
集群节点除了 Master 外, 其他机器被称为 Node。职责是运行容器应用,Node 由 Master 管理,负责监控并汇报容器的状态,同时根据 Master 的要求管理容器的生命周期。
1.3.3. Pod
K8s 的最小工作单元。每个 Pod 包含一个或多个容器。有些容器天生就是需要紧密联系,一起工作。Pod提供了比容器更高层次的抽象,K8s 以 Pod 为最小单位进行调度、扩展、共享资源、管理生命周期。
Pod中的所有容器使用同一个网络的 namespace,即相同的 IP 地址和 Port 空间。它们可以直接用 localhost 通信。同样的,这些容器可以共享存储,当 K8s 挂载 Volume 到Pod上,本质上是将 volume 挂载到Pod中的每一个容器。

1.3.4. Label
一个Label是一个key=value的键值对,其中key与value由用户自己指定。给某个资源对象定义一个Label,就相当于给它打了一个标签, 随后可以通过Label Selector(标签选择器) 查询和筛选拥有某些Label的资源对象, K8s 通过这种方式实现了类似SQL的简单又通用的对象查询机制。
1.3.5. Replication Controller
Replication Controller(简称RC)。用来定义一个期望的场景,即声明某种 Pod 的副本数量在任意时刻都符合某个预期值。
在我们定义了一个 RC 并将其提交到Kubernetes集群中后, Master 上的 Controller Manager 组件就得到通知, 定期巡检系统中当前存活的目标 Pod, 并确保目标Pod实例的数量刚好等于此 RC 的期望值, 如果有过多的Pod副本在运行, 系统就会停掉一些 Pod, 否则系统会再自动创建一些 Pod。
ReplicaSet 是加强版的 Replication Controller,其功能只是扩展了 Replication Controller 的 selector,支持基于集合的selector(version in (v1.0, v2.0) 或 env notin (dev, qa)),K8s中一般我们不再使用 Replication Controller。
1.3.6. Deployment
Deployment 是 K8s 在1.2版本中引入的新概念, 用于更好地解决 Pod 的编排问题。Deployment 为 Pod 和 Replica Set(下一代Replication Controller)提供声明式更新。Replica Set 是在 Deployment 里使用的。你只需要在 Deployment 中描述你想要的目标状态是什么,Deployment controller 就会帮你将 Pod 和 Replica Set 的实际状态改变到你的目标状态。你可以定义一个全新的 Deployment,也可以创建一个新的替换旧的 Deployment。
1.3.7. DaemonSet
DaemonSet 保证在每个Node上都运行一个容器副本,常用来部署一些集群的日志、监控或者其他系统管理应用。k8s内部就启用了这个,一般运维监控才用到它。日志收集,系统监控等系统程序,比如kube-proxy, kube-dns, glusterd, ceph 等都是 DaemonSet。
1.3.8. StatefulSet
StatefulSet 是为了解决有状态服务的问题(对应Deployments和ReplicaSets是为无状态服务而设计)。
1.3.9. Job
批处理任务。Job 所控制的 Pod 副本是短暂运行的, 可以将其视为一组Docker容器, 其中的每个Docker容器都仅仅运行一次。 当Job控制的所有Pod副本都运行结束时, 对应的Job也就结束了。Cronjob 周期性作业,是K8s 在1.5版本之后又提供了类似 crontab 的定时任务,为了解决某些批处理任务需要定时反复执行的问题。
1.3.10. Service
Service服务也是Kubernetes里的核心资源对象之一, K8s 里的每个Service 就如同微服务架构中的一个微服务。
1.3.11. Namespace
Namespace(命名空间) 将物理的 Cluster 逻辑上划分成多个虚拟 Cluster,每个 Cluster 就是一个 Namespace。不同的 Namespace 里的资源是完全隔离的。default 是默认的 namespace,kube-system 是K8s自己创建的系统资源放到这个 namespace。
1.3.12. ConfigMap
集中管理系统的配置。以键值对形式存在,比如配置项 password=123456、 user=root 配置参数。 这些配置项可以作为 Map 表中的一个项, 整个 Map 的数据可以被持久化存储在 K8s 的 Etcd 数据库中, 然后提供 API 以方便 K8s 相关组件或客户应用CRUD操作这些数据, 上述专门用来保存配置参数的 Map 就是 Kubernetes ConfigMap 资源对象。
K8s 提供了一种内建机制, 将存储在 etcd 中的 ConfigMap 通过 Volume 映射的方式变成目标 Pod 内的配置文件, 不管目标 Pod 被调度到哪台服务器上, 都会完成自动映射。 进一步地, 如果 ConfigMap 中的 key-value 数据被修改, 则映射到 Pod 中的 “配置文件” 也会随之自动更新。

二、Kubernetes 基本命令
| 资源名称 | 简写 |
|---|---|
| pods | po |
| namespaces | ns |
| services | svc |
| nodes | no |
| events | ev |
| ingress | ing |
| deployments | deploy |
2.1.基础命令
create,delete,get,run,expose,set,explain,edit
- kubectl create(根据文件或输入创建资源)
# 创建Deployment或Service资源
kubectl create -f filename.yaml
- kubectl delete(删除命令)
# 根据yaml文件删除对应的资源,yaml文件并不会被删除
kubectl delete -f filename.yaml
# 也可通过具体的资源名称来进行删除,使用这个删除资源,需要同时删除pod和service资源才行
kubectl delete <具体的资源名称>
- kubectl get(获取资源信息可以使用简写)
# 查看所有的资源信息
kubectl get all
# 查看pod列表
kubectl get pod
# 显示pod节点的标签信息
kubectl get pod --show-labels
# 根据指定标签匹配到具体的pod
kubectl get pods -l app=example
# 查看node节点列表
kubectl get node
# 显示node节点的标签信息
kubectl get node --show-labels
# 查看pod详细信息,节点信息和ip
kubectl get pod -o wide
# 查看服务的详细信息,显示了服务名称,类型,集群ip,端口,时间等信息
kubectl get svc
# 查看命名空间
kubectl get ns
# 查看所有pod所属的命名空间
kubectl get pod --all-namespaces
# 查看所有pod所属的命名空间并且查看都在哪些节点上运行
kubectl get pod --all-namespaces -o wide
# 查看目前所有的replica set,显示了所有的pod的副本数,以及可用数量及状态等信息
kubectl get rs
# 查看目前所有的deployment
kubectl get deployment
# 查看已经部署了的所有应用,可以看到容器以及容器所用的镜像,标签等信息
kubectl get deploy -o wide
- kubectl run(集群中创建并运行一个或多个容器镜像)
# 基本语法
run NAME --image=image [--env="key=value"] [--port=port] [--replicas=replicas] [--dry-run=bool] [--overrides=inline-json] [--command] -- [COMMAND] [args...]
# 示例,运行一个名称为nginx,副本数为3,标签为app=example,镜像为nginx:1.10,端口为80的容器实例
kubectl run nginx --replicas=3 --labels="app=example" --image=nginx:1.10 --port=80
- kubectl expose(创建service并暴露端口到外部可以访问)
# 创建一个nginx服务并且暴露端口让外界可以访问
kubectl expose deployment nginx --port=88 --type=NodePort --target-port=80 --name=nginx-service
- kubectl set(配置应用的特定资源,可以修改应用已有的资源)
# 将deployment的nginx容器cpu限制为“200m”,将内存设置为“512Mi”
kubectl set resources deployment nginx -c=nginx --limits=cpu=200m,memory=512Mi
# 为nginx中的所有容器设置 Requests和Limits
kubectl set resources deployment nginx --limits=cpu=200m,memory=512Mi --requests=cpu=100m,memory=256Mi
# 删除nginx中容器的计算资源值
kubectl set resources deployment nginx --limits=cpu=0,memory=0 --requests=cpu=0,memory=0
# 将deployment中的nginx容器镜像设置为“nginx:1.9.1”。
kubectl set image deployment/nginx busybox=busybox nginx=nginx:1.9.1
# 所有deployment和rc的nginx容器镜像更新为“nginx:1.9.1”
kubectl set image deployments,rc nginx=nginx:1.9.1 --all
# 将daemonset abc的所有容器镜像更新为“nginx:1.9.1”
kubectl set image daemonset abc *=nginx:1.9.1
# 从本地文件中更新nginx容器镜像
kubectl set image -f path/to/file.yaml nginx=nginx:1.9.1 --local -o yaml
- kubectl explain(显示资源文档信息)
kubectl explain rs
- kubectl edit(编辑资源信息)
# 编辑Deployment nginx的一些信息
kubectl edit deployment nginx
# 编辑service类型的nginx的一些信息
kubectl edit service/nginx
2.2.设置命令
label,annotate,completion
- kubectl label(增删改资源上的标签)
# 给名为foo的Pod添加label unhealthy=true
kubectl label pods foo unhealthy=true
# 给名为foo的Pod修改label 为 'status' / value 'unhealthy',且覆盖现有的value
kubectl label --overwrite pods foo status=unhealthy
# 给 namespace 中的所有 pod 添加 label
kubectl label pods --all status=unhealthy
# 仅当resource-version=1时才更新 名为foo的Pod上的label
kubectl label pods foo status=unhealthy --resource-version=1
# 删除名为“bar”的label 。(使用“ - ”减号相连)
kubectl label pods foo bar-
- kubectl annotate(更新一个或多个资源的 annotations 信息,即注解信息)
# 更新Pod“foo”,设置annotation “description”的value “my frontend”,如果同一个annotation多次设置,则只使用最后设置的value值
kubectl annotate pods foo description='my frontend'
# 根据“pod.json”中的type和name更新pod的annotation
kubectl annotate -f pod.json description='my frontend'
# 更新Pod"foo",设置annotation“description”的value“my frontend running nginx”,覆盖现有的值
kubectl annotate --overwrite pods foo description='my frontend running nginx'
# 更新 namespace中的所有pod
kubectl annotate pods --all description='my frontend running nginx'
# 只有当resource-version为1时,才更新pod ' foo '
kubectl annotate pods foo description='my frontend running nginx' --resource-version=1
# 通过删除名为“description”的annotations来更新pod ' foo '。#不需要- overwrite flag。
kubectl annotate pods foo description-
- kubectl completion(设置 kubectl命令自动补全)
$ source <(kubectl completion bash) # setup autocomplete in bash, bash-completion package should be installed first.
$ source <(kubectl completion zsh) # setup autocomplete in zsh
2.3.部署命令
rollout,rolling-update,scale,autoscale
- kubectl rollout
# 语法
kubectl rollout SUBCOMMAND
# 回滚到之前的deployment
kubectl rollout undo deployment/abc
# 查看daemonet的状态
kubectl rollout status daemonset/foo
- kubectl rolling-update(指定RC滚动更新)
# 使用frontend-v2.json中的新RC数据更新frontend-v1的pod
kubectl rolling-update frontend-v1 -f frontend-v2.json
# 使用JSON数据更新frontend-v1的pod
cat frontend-v2.json | kubectl rolling-update frontend-v1 -f -
# 其他的一些滚动更新
kubectl rolling-update frontend-v1 frontend-v2 --image=image:v2
kubectl rolling-update frontend --image=image:v2
kubectl rolling-update frontend-v1 frontend-v2 --rollback
- kubectl scale(扩容缩容)
# 将名为foo中的pod副本数设置为3。
kubectl scale --replicas=3 rs/foo
kubectl scale deploy/nginx --replicas=30
# 将由“foo.yaml”配置文件中指定的资源对象和名称标识的Pod资源副本设为3
kubectl scale --replicas=3 -f foo.yaml
# 如果当前副本数为2,则将其扩展至3。
kubectl scale --current-replicas=2 --replicas=3 deployment/mysql
# 设置多个RC中Pod副本数量
kubectl scale --replicas=5 rc/foo rc/bar rc/baz
- kubectl autoscale(扩容缩容,与scale不同,它根据流量多少来自动扩容缩容)
# 语法
kubectl autoscale (-f FILENAME | TYPE NAME | TYPE/NAME) [--min=MINPODS] --max=MAXPODS [--cpu-percent=CPU] [flags]
# 使用 Deployment “foo”设定,使用默认的自动伸缩策略,指定目标CPU使用率,使其Pod数量在2到10之间
kubectl autoscale deployment foo --min=2 --max=10
# 使用RC“foo”设定,使其Pod的数量介于1和5之间,CPU使用率维持在80%
kubectl autoscale rc foo --max=5 --cpu-percent=80
2.4.集群管理命令
certificate,cluster-info,top,cordon,uncordon,drain,taint
# 用于证书资源管理授权
kubectl certificate
# 查看集群信息
kubectl cluster-info
# 查看资源cpu,内存磁盘等资源的使用率
kubectl top
kubectl top pod --all-namespaces
#用于标记某个节点不可调度
kubectl cordon
#用于标记节点可以调度
kubectl uncordon
#用于在维护期间排除节点
kubectl drain
# 设置污点
kubectl taint
2.5.集群故障排除与调试命令
describe,logs,exec,attach,port-foward,proxy,cp,auth
- kubectl describe(显示特定资源详细信息)
# 语法
kubectl describe TYPE NAME_PREFIX
(首先检查是否有精确匹配TYPE和NAME_PREFIX的资源,如果没有,将会输出所有名称以NAME_PREFIX开头的资源详细信息)
支持的资源包括但不限于(大小写不限):pods (po)、services (svc)、 replicationcontrollers (rc)、nodes (no)、events (ev)、componentstatuses (cs)、 limitranges (limits)、persistentvolumes (pv)、persistentvolumeclaims (pvc)、 resourcequotas (quota)和secrets。
#查看my-nginx pod的详细状态
kubectl describe po my-nginx
- kubectl logs(查看日志)
# 语法
kubectl logs [-f] [-p] POD [-c CONTAINER]
# 返回仅包含一个容器的pod nginx的日志快照
kubectl logs nginx
# 返回pod ruby中已经停止的容器web-1的日志快照
kubectl logs -p -c ruby web-1
# 持续输出pod ruby中的容器web-1的日志
kubectl logs -f -c ruby web-1
# 仅输出pod nginx中最近的20条日志
kubectl logs --tail=20 nginx
# 输出pod nginx中最近一小时内产生的所有日志
kubectl logs --since=1h nginx
# 参数选项
-c, --container="": 容器名。
-f, --follow[=false]: 指定是否持续输出日志(实时日志)。
--interactive[=true]: 如果为true,当需要时提示用户进行输入。默认为true。
--limit-bytes=0: 输出日志的最大字节数。默认无限制。
-p, --previous[=false]: 如果为true,输出pod中曾经运行过,但目前已终止的容器的日志。
--since=0: 仅返回相对时间范围,如5s、2m或3h,之内的日志。默认返回所有日志。只能同时使用since和since-time中的一种。
--since-time="": 仅返回指定时间(RFC3339格式)之后的日志。默认返回所有日志。只能同时使用since和since-time中的一种。
--tail=-1: 要显示的最新的日志条数。默认为-1,显示所有的日志。
--timestamps[=false]: 在日志中包含时间戳。
- kubectl exec(进入容器交互)
# 语法
kubectl exec POD [-c CONTAINER] -- COMMAND [args...]
#命令选项
-c, --container="": 容器名。如果未指定,使用pod中的一个容器。
-p, --pod="": Pod名。
-i, --stdin[=false]: 将控制台输入发送到容器。
-t, --tty[=false]: 将标准输入控制台作为容器的控制台输入。
# 进入nginx容器,执行一些命令操作
kubectl exec -it nginx-deployment-58d6d6ccb8-lc5fp bash
- kubectl attach(连接到一个正在运行的容器)
#语法
kubectl attach POD -c CONTAINER
# 参数选项
-c, --container="": 容器名。如果省略,则默认选择第一个 pod
-i, --stdin[=false]: 将控制台输入发送到容器。
-t, --tty[=false]: 将标准输入控制台作为容器的控制台输入。
# 获取正在运行中的pod 123456-7890的输出,默认连接到第一个容器
kubectl attach 123456-7890
# 获取pod 123456-7890中ruby-container的输出
kubectl attach 123456-7890 -c ruby-container
# 切换到终端模式,将控制台输入发送到pod 123456-7890的ruby-container的“bash”命令,并将其输出到控制台/
# 错误控制台的信息发送回客户端。
kubectl attach 123456-7890 -c ruby-container -i -t
- kubectl cp(拷贝文件或目录到 pod 容器中)
2.6.其它命令
api-servions,config,help,plugin,version
# 打印受支持的api版本信息
kubectl api-servions
# 显示全部的命令帮助提示
kubectl --help
# 具体的子命令帮助,例如
kubectl create --help
# 修改 config 配置文件
kubectl config
# 运行一个命令插件
kubectl plugin
2.7.高级命令
apply,patch,replace,convert
- kubectl apply(通过文件名或者标准输入对资源应用配置)
# 语法
kubectl apply -f FILENAME
# 将pod.json中的配置应用到pod
kubectl apply -f ./pod.json
# 将控制台输入的JSON配置应用到Pod
cat pod.json | kubectl apply -f -
选项
-f, --filename=[]: 包含配置信息的文件名,目录名或者URL。
--include-extended-apis[=true]: If true, include definitions of new APIs via calls to the API server. [default true]
-o, --output="": 输出模式。"-o name"为快捷输出(资源/name).
--record[=false]: 在资源注释中记录当前 kubectl 命令。
-R, --recursive[=false]: Process the directory used in -f, --filename recursively. Useful when you want to manage related manifests organized within the same directory.
--schema-cache-dir="~/.kube/schema": 非空则将API schema缓存为指定文件,默认缓存到'$HOME/.kube/schema'
--validate[=true]: 如果为true,在发送到服务端前先使用schema来验证输入。
- kubectl patch(使用补丁修改,更新资源字段)
# 语法
kubectl patch (-f FILENAME | TYPE NAME) -p PATCH
# Partially update a node using strategic merge patch
kubectl patch node k8s-node-1 -p '{"spec":{"unschedulable":true}}'
# Update a container's image; spec.containers[*].name is required because it's a merge key
kubectl patch pod valid-pod -p '{"spec":{"containers":[{"name":"kubernetes-serve-hostname","image":"new image"}]}}'
- kubectl replace(通过文件或者标准输入替换原有资源)
# 语法
kubectl replace -f FILENAME
# Replace a pod using the data in pod.json.
kubectl replace -f ./pod.json
# Replace a pod based on the JSON passed into stdin.
cat pod.json | kubectl replace -f -
# Update a single-container pod's image version (tag) to v4
kubectl get pod mypod -o yaml | sed 's/\(image: myimage\):.*$/\1:v4/' | kubectl replace -f -
# Force replace, delete and then re-create the resource
kubectl replace --force -f ./pod.json
- kubectl convert(不同的版本之间转换配置文件)
# 语法
kubectl convert -f FILENAME
# Convert 'pod.yaml' to latest version and print to stdout.
kubectl convert -f pod.yaml
# Convert the live state of the resource specified by 'pod.yaml' to the latest version
# and print to stdout in json format.
kubectl convert -f pod.yaml --local -o json
# Convert all files under current directory to latest version and create them all.
kubectl convert -f . | kubectl create -f -
三、安装配置
3.1.系统配置要求
| 软硬件 | 最低配置 | 最低配置 |
|---|---|---|
| CPU & 内存 | Master:2核4GB Node:4核16GB | Master:4核16GB Node:根据实际容器数量配置 |
| Linux 操作系统 | 基于x86_64架构的各种Linux发型版本,Red Hat Linux、CentOS、Fedora、Ubuntu等,Kernel 版本3.10 及 + | Red Hat Linux 7 CentOS 7 |
| etcd | 版本 3.0 及 + | 版本 3.3 |
| Docker | 版本 18.03 及 + | 版本 18.09 |
3.2.环境安装准备
| 主机名 | IP | 系统 | Docker | 配置 | 角色 | 安装组件 |
|---|---|---|---|---|---|---|
| k8s-node1 | 192.168.61.129 | CentOS7 | 18.09 | 2C4G | master | kubectl, kubelet, kube-proxy, flannel, kubeadm,etcd, kube-apiserver, kube-controller-manager |
| k8s-node2 | 192.168.61.132 | CentOS7 | 18.09 | 2C4G | slave | kubectl, kubelet, kube-proxy, flannel |
| k8s-node3 | 192.168.61.133 | CentOS7 | 18.09 | 2C4G | slave | kubectl, kubelet, kube-proxy, flannel |
| 组件 | 版本 | 说明 |
|---|---|---|
| CentOS | 7.6.1810 | |
| Kernel | Linux 3.10.0-957.el7.x86_64 | |
| etcd | 3.3.15 | |
| coredns | 1.6.2 | |
| kubeadm | v1.16.2 | |
| kubectl | v1.16.2 | |
| kubelet | v1.16.2 | |
| kube-proxy | v1.16.2 | |
| flannel | v0.15.0 |
系统信息查看:hostnamectl
3.2.1.设置 hosts 解析
设置主机名(node1/2/3)
# master(node1) 节点上执行,设置 master 节点的hostname
hostnamectl set-hostname k8s-node1
slave(node2) 节点上执行
hostnamectl set-hostname k8s-node2
# slave(node3) 节点上执行
hostnamectl set-hostname k8s-node3
添加 hosts 解析(node1/2/3)
cat >>/etc/hosts<<EOF
192.168.61.129 k8s-node1
192.168.61.132 k8s-node2
192.168.61.133 k8s-node3
EOF
3.2.2.关闭 swap 分区
kubeadm 推荐关闭交换空间的使用,集群搭建时每个节点(node1/2/3)都操作一次
# 1.临时禁用
swapoff -a
# 2.永久禁用,注释掉 “/dev/mapper/centos-swap swap” 一行,确保重启后禁用
sed -i.bak '/swap/s/^/#/' /etc/fstab
# 3.查看是否关闭 Swap: 0 0 0 即表示关闭
free -m
3.2.3.开放指定端口
CentOS Linux 7 默认启动了防火墙服务,而Kubernetes的Master与工作Node之间会有大量的网络通信, 安全的做法是在防火墙上配置各组件需要相互通信的端口号,或者在安全的内部网络环境中可以关闭防火墙服务。
- 关闭防火墙
# 1.关闭防火墙 (node1/2/3)
systemctl stop firewalld && systemctl disable firewalld
# 2.关闭selinux(内核级防火墙),让容器可以读取主机文件系统 (node1/2/3)
setenforce 0
# 3.修改SELINUX=disabled (node1/2/3)
vi /etc/sysconfig/selinux
- 不关闭防火墙,开放指定端口 官方文档
Master (node1)节点
| 协议 | 方向 | 端口 | 目的 | 使用人 |
|---|---|---|---|---|
| TCP | 入站 | 6443 | Kubernetes API server | All |
| TCP | 入站 | 2379-2380 | etcd server client API | kube-apiserver, etcd |
| TCP | 入站 | 10250 | Kubelet API | Self, Control plane |
| TCP | 入站 | 10259 | kube-scheduler | Self |
| TCP | 入站 | 10257 | kube-controller-manager | Self |
Node (node2/3)节点
| 协议 | 方向 | 端口 | 目的 | 使用人 |
|---|---|---|---|---|
| TCP | 入站 | 10250 | Kubelet API | Self, Control plane |
| TCP | 入站 | 30000-32767 | NodePort Services† | All |
3.2.4.配置 ip_forward 转发
# 默认为1,可以不用设置,为确保可以之前查看下 cat /proc/sys/net/ipv4/ip_forward 是否为1(node1/2/3)
echo "1" > /proc/sys/net/ipv4/ip_forward
3.2.5.验证每个节点的 MAC 地址和 product_uuid 是唯一的
尽管某些虚拟机可能具有相同的值,但硬件设备很可能具有唯一的地址。Kubernetes 使用这些值来唯一标识集群中的节点。如果这些值不是每个节点唯一的,安装过程可能会失败。
# 1.在每个节点上执行对比,确保唯一(node1/2/3)
cat /sys/class/dmi/id/product_uuid
3.2.6.让 iptables 看到桥接流量
确保br_netfilter模块已加载
# 1.查看是否已加载 (node1/2/3)
lsmod |grep br_netfilter
# 2.没有则执行以下命令进行加载(node1/2/3)
modprobe br_netfilter
作为 Linux 节点的 iptables 正确查看桥接流量的要求,应该确保 net.bridge.bridge-nf-call-iptables 在 sysctl 配置中设置为 1(node1/2/3)
cat <<EOF | sudo tee /etc/modules-load.d/k8s.conf
br_netfilter
EOF
cat <<EOF | sudo tee /etc/sysctl.d/k8s.conf
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
EOF
sudo sysctl --system
3.2.7.设置 yum 源
# (node1/2/3)
cat <<EOF > /etc/yum.repos.d/kubernetes.repo
[kubernetes]
name=Kubernetes
baseurl=http://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64
enabled=1
gpgcheck=1
repo_gpgcheck=1
gpgkey=http://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg
http://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg
EOF
3.2.8.安装 docker
# (node1/2/3)
# 1.安装系统工具
yum install -y yum-utils device-mapper-persistent-data lvm2
# 2.配置源地址(可选择国内的源地址,我这里配置阿里云)
yum-config-manager --add-repo http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
# 3.更新缓存
yum makecache fast
# 4.安装:
# 4.1方式一:最新版本安装
yum install -y docker-ce docker-ce-cli containerd.io
# 4.2.方式二:指定版本安装
# 列出可用版本
yum list docker-ce --showduplicates | sort -r
# 选择安装指定版本(其中<version>替换为需要安装的版本号如:18.09.9),这里我安装18.09.9
yum install docker-ce-<version> docker-ce-cli-<version> containerd.io
# 5.配置docker加速
mkdir -p /etc/docker
cat <<EOF > /etc/docker/daemon.json
{
"registry-mirrors" : [
"https://registry.docker-cn.com"
],
"exec-opts": ["native.cgroupdriver=systemd"]
}
EOF
# 6.设置开机启动,启动docker
systemctl enable docker && systemctl start docker
注意:如果文件已存在并配置了加速,且 docker 已经安装,需要增加以上的 exec-opts 否则后续初始化会报错。添加成功后执行命令 systemctl daemon-reload && systemctl restart docker 重新加载配置并重启 docker
3.3.使用 kubeadm 工具快速安装 kubernetes 集群
3.3.1.安装 kubeadm 和相关工具
# 1.安装指定版本 kubeadm 和相关工具# (node1/2/3)
yum install -y kubelet-1.16.2 kubeadm-1.16.2 kubectl-1.16.2 --disableexcludes=kubernetes
# 2.查看 kubeadm 版本# (node1/2/3)
kubeadm version
# 3.设置 kubelet 开机启动并启动 kubelet (node1/2/3)
systemctl enable kubelet && systemctl start kubelet
3.3.2.kubeadm config
注意:kubeadm config 初始化文件这一步其实可以跳过,因为正常大部分都是默认参数,如果不做特别修改可以跳过当前介绍内容直接前往 3.3.4 去执行初始化安装。
# 1.取得默认的初始化参数文件保存为 init.default.yaml (只在 node1 master节点执行)
kubeadm config print init-defaults > init.default.yaml
# 2.拷贝文件重命名
cp init.default.yaml init-config.yaml
# 3.修改 init-config.yaml
vi init-config.yaml
init-config.yaml
apiVersion: kubeadm.k8s.io/v1beta2
bootstrapTokens:
- groups:
- system:bootstrappers:kubeadm:default-node-token
token: abcdef.0123456789abcdef
ttl: 24h0m0s
usages:
- signing
- authentication
kind: InitConfiguration
localAPIEndpoint:
advertiseAddress: 192.168.61.129 # 1.修改apiserver地址,由于单master,配置master的节点内网IP
bindPort: 6443
nodeRegistration:
criSocket: /var/run/dockershim.sock
name: k8s-node1
taints:
- effect: NoSchedule
key: node-role.kubernetes.io/master
---
apiServer:
timeoutForControlPlane: 4m0s
apiVersion: kubeadm.k8s.io/v1beta2
certificatesDir: /etc/kubernetes/pki
clusterName: kubernetes
controllerManager: {}
dns:
type: CoreDNS
etcd:
local:
dataDir: /var/lib/etcd
imageRepository: registry.aliyuncs.com/google_containers # 2.修改成阿里镜像源
kind: ClusterConfiguration
kubernetesVersion: v1.16.2 # 3.修改版本为 v1.16.2
networking:
dnsDomain: cluster.local
serviceSubnet: 10.96.0.0/12
podSubnet: 10.244.0.0/16 # 4.增加配置 Pod 网段,flannel 插件需要使用这个网段
scheduler: {}
注意:以上如果没有增加 “podSubnet” 配置项或者说配置的值与下文安装的 flannel 配置中使用的地址不一致会报以下错误:
Error registering network: failed to acquire lease: node “k8s-master” pod cidr not assigned
3.3.3.下载 kubernetes 相关镜像
# 1.查看需要使用的镜像列表(只在 node1 master节点执行)
kubeadm config images list --config init-config.yaml
# 2.下载镜像列表(只在 node1 master节点执行)
kubeadm config images pull --config init-config.yaml

3.3.4.运行 kubeadm init 命令安装Master
- 进行了 3.3.2 步骤选择以下方式
# 只在 node1 master节点执行
kubeadm init --config init-config.yaml
- 没有进行 3.3.2 步骤选择以下方式
# 只在 node1 master节点执行
kubeadm init --kubernetes-version v1.16.2 \
--image-repository registry.aliyuncs.com/google_containers \
--pod-network-cidr=10.244.0.0/16 \
--apiserver-advertise-address=192.168.61.129
参数说明:
- - kubernetes-version :安装指定版本 k8s。
- - image-repository :设置 kubeadm 拉取 k8s 各组件镜像的地址,默认拉取的地址是:k8s.gcr.io,改地址国内无法访问,所以设置为阿里云镜像仓库。
- - pod-network-cidr :设置 pod ip 的网段。这里设置的 10.244.0.0/16 是因为与后续安装的 flannel 网络插件网段一致,如果不一致会导致 Node 见 Cluster IP 不通。如果不指定后续安装启动 flannel 插件会失败,报以下错:
Error registering network: failed to acquire lease: node “k8s-master” pod cidr not assigned
出现以下提示标识初始化成功

# 根据成功结果提示,执行提示操作,配置 kubectl 客户端的认证(只在 node1 master节点执行)
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
注意:初始化过程中出错,调整后执行 kubeadm reset 后再次执行 kubeadm init 操作
3.3.5.添加 slave 节点到集群中
# 在各 slave 节点(node2/3)上分别执行命令(该命令在初始化成功后可以拷贝)
kubeadm join 192.168.61.129:6443 --token abcdef.0123456789abcdef \
--discovery-token-ca-cert-hash sha256:51150865e50a8d39ede1a4a2733f64954f092e56db92d50b4ef710c501a8dd67
出现以下提示表示 slave 加入集群成功

3.3.6.安装 flannel 网络插件
执行kubectl get nodes命令, 会发现 Kubernetes 提示节点为 NotReady 状态, 这是因为还没有安装网络插件。
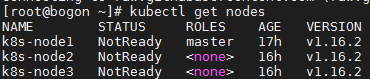
浏览器打开 flannel git 项目 https://github.com/flannel-io/flannel/blob/master/Documentation/kube-flannel.yml 拷贝配置文件 kube-flannel.yml 内容并在服务器上创建该文件。
---
apiVersion: policy/v1beta1
kind: PodSecurityPolicy
metadata:
name: psp.flannel.unprivileged
annotations:
seccomp.security.alpha.kubernetes.io/allowedProfileNames: docker/default
seccomp.security.alpha.kubernetes.io/defaultProfileName: docker/default
apparmor.security.beta.kubernetes.io/allowedProfileNames: runtime/default
apparmor.security.beta.kubernetes.io/defaultProfileName: runtime/default
spec:
privileged: false
volumes:
- configMap
- secret
- emptyDir
- hostPath
allowedHostPaths:
- pathPrefix: "/etc/cni/net.d"
- pathPrefix: "/etc/kube-flannel"
- pathPrefix: "/run/flannel"
readOnlyRootFilesystem: false
# Users and groups
runAsUser:
rule: RunAsAny
supplementalGroups:
rule: RunAsAny
fsGroup:
rule: RunAsAny
# Privilege Escalation
allowPrivilegeEscalation: false
defaultAllowPrivilegeEscalation: false
# Capabilities
allowedCapabilities: ['NET_ADMIN', 'NET_RAW']
defaultAddCapabilities: []
requiredDropCapabilities: []
# Host namespaces
hostPID: false
hostIPC: false
hostNetwork: true
hostPorts:
- min: 0
max: 65535
# SELinux
seLinux:
# SELinux is unused in CaaSP
rule: 'RunAsAny'
---
kind: ClusterRole
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: flannel
rules:
- apiGroups: ['extensions']
resources: ['podsecuritypolicies']
verbs: ['use']
resourceNames: ['psp.flannel.unprivileged']
- apiGroups:
- ""
resources:
- pods
verbs:
- get
- apiGroups:
- ""
resources:
- nodes
verbs:
- list
- watch
- apiGroups:
- ""
resources:
- nodes/status
verbs:
- patch
---
kind: ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: flannel
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: flannel
subjects:
- kind: ServiceAccount
name: flannel
namespace: kube-system
---
apiVersion: v1
kind: ServiceAccount
metadata:
name: flannel
namespace: kube-system
---
kind: ConfigMap
apiVersion: v1
metadata:
name: kube-flannel-cfg
namespace: kube-system
labels:
tier: node
app: flannel
data:
cni-conf.json: |
{
"name": "cbr0",
"cniVersion": "0.3.1",
"plugins": [
{
"type": "flannel",
"delegate": {
"hairpinMode": true,
"isDefaultGateway": true
}
},
{
"type": "portmap",
"capabilities": {
"portMappings": true
}
}
]
}
net-conf.json: |
{
"Network": "10.244.0.0/16",
"Backend": {
"Type": "vxlan"
}
}
---
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: kube-flannel-ds
namespace: kube-system
labels:
tier: node
app: flannel
spec:
selector:
matchLabels:
app: flannel
template:
metadata:
labels:
tier: node
app: flannel
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: kubernetes.io/os
operator: In
values:
- linux
hostNetwork: true
priorityClassName: system-node-critical
tolerations:
- operator: Exists
effect: NoSchedule
serviceAccountName: flannel
initContainers:
- name: install-cni-plugin
image: rancher/mirrored-flannelcni-flannel-cni-plugin:v1.2
command:
- cp
args:
- -f
- /flannel
- /opt/cni/bin/flannel
volumeMounts:
- name: cni-plugin
mountPath: /opt/cni/bin
- name: install-cni
image: quay.io/coreos/flannel:v0.15.0
command:
- cp
args:
- -f
- /etc/kube-flannel/cni-conf.json
- /etc/cni/net.d/10-flannel.conflist
volumeMounts:
- name: cni
mountPath: /etc/cni/net.d
- name: flannel-cfg
mountPath: /etc/kube-flannel/
containers:
- name: kube-flannel
image: quay.io/coreos/flannel:v0.15.0
command:
- /opt/bin/flanneld
args:
- --ip-masq
- --kube-subnet-mgr
resources:
requests:
cpu: "100m"
memory: "50Mi"
limits:
cpu: "100m"
memory: "50Mi"
securityContext:
privileged: false
capabilities:
add: ["NET_ADMIN", "NET_RAW"]
env:
- name: POD_NAME
valueFrom:
fieldRef:
fieldPath: metadata.name
- name: POD_NAMESPACE
valueFrom:
fieldRef:
fieldPath: metadata.namespace
volumeMounts:
- name: run
mountPath: /run/flannel
- name: flannel-cfg
mountPath: /etc/kube-flannel/
volumes:
- name: run
hostPath:
path: /run/flannel
- name: cni-plugin
hostPath:
path: /opt/cni/bin
- name: cni
hostPath:
path: /etc/cni/net.d
- name: flannel-cfg
configMap:
name: kube-flannel-cfg
# 1.先拉取配置文件中所需镜像(node1/2/3)
docker pull quay.io/coreos/flannel:v0.15.0
docker pull rancher/mirrored-flannelcni-flannel-cni-plugin:v1.2
# 2.执行安装(node1)
kubectl apply -f kube-flannel.yml
注意:以上网络插件所需镜像要确保能成功拉取,否则安装时会失败。如果拉取镜像超时需要自行配置相应的 docker 镜像加速器并重新加载重启 docker。
3.3.7.验证 kubernetes 集群安装是否完成
# 1.查看节点信息,可以观察到节点状态为 Ready 状态(node1)
kubectl get nodes
# 2.验证Kubernetes集群的相关Pod是否都正常创建并运行 (node1)
kubectl get pods --all-namespaces
kubectl get pods --all-namespaces -o wide
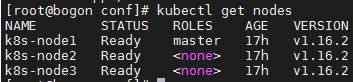

注意:如果 coredns 非 Running 状态可以尝试重启节点。如果发现有状态错误的 Pod 则可以执行以下命令查看错误日志
# 查看 pod 错误原因 (node1)
kubectl --namespace=kube-system describe pod <pod_name>
# 查看 pod 错误日志 (node1)
kubectl logs -f -n kube-system <pod_name>
注意:常见的错误原因是镜像没有下载完成。
3.3.8.安装失败如何重置集群
# 1.执行重置命令 (node1/2/3) 主从节点都要执行,根据提示输入 y
kubeadm reset
# 2.在 master 节点执行
rm -rf $HOME/.kube
# 3.重新从 3.3.4 步骤开始一系列初始化
不执行第2步 在执行 kubectl get nodes 等命令时会报错:
Unable to connect to the server: x509: certificate signed by unknown authority (possibly because of “crypto/rsa: verification error” while trying to verify candidate authority certificate “kubernetes”)
四、Pod 理解与实践
4.1.Pod 定义详解
apiVersion: v1 #必选,组名/版本号,kubectl api-version
kind: Pod #必选 资源类型比如 Deployment、Service
metadata: #必选,具有唯一标识对象的元数据,包括 name、UID、namespace
name: string #必选,Pod名称
namespace: string #必选,Pod所属的命名空间
labels: #自定义标签
- name: string #自定义标签名字
annotations: #自定义资源注释列表
- name: string
spec: #必选,Pod中容器的详细定义;期望的状态disired state
containers: #必选,Pod中容器列表
- name: string #必选,容器名称
image: string #必选,容器的镜像名称
imagePullPolicy: [Always | Never | IfNotPresent] #获取镜像的策略 Alawys表示下载镜像 IfnotPresent表示优先使用本地镜像,否则下载镜像,Nerver表示仅使用本地镜像
command: [string] #容器的启动命令列表,如不指定,使用打包时使用的启动命令
args: [string] #容器的启动命令参数列表
workingDir: string #容器的工作目录
volumeMounts: #挂载到容器内部的存储卷配置
- name: string #引用pod定义的共享存储卷的名称,需用volumes[]部分定义的的卷名
mountPath: string #存储卷在容器内mount的绝对路径,应少于512字符
readOnly: boolean #是否为只读模式
ports: #需要暴露的端口库号列表
- name: string #端口号名称
containerPort: int #容器需要监听的端口号
hostPort: int #容器所在主机需要监听的端口号,默认与 Container 相同
protocol: string #端口协议,支持TCP和UDP,默认TCP
env: #容器运行前需设置的环境变量列表
- name: string #环境变量名称
value: string #环境变量的值
resources: #资源限制和请求的设置
limits: #资源限制的设置
cpu: string #Cpu的限制,单位为core数,将用于docker run --cpu-shares参数
memory: string #内存限制,单位可以为Mib/Gib,将用于docker run --memory参数
requests: #资源请求的设置
cpu: string #Cpu请求,容器启动的初始可用数量
memory: string #内存清楚,容器启动的初始可用数量
livenessProbe: #对Pod内个容器健康检查的设置,当探测无响应几次后将自动重启该容器,检查方法有exec、httpGet和tcpSocket,对一个容器只需设置其中一种方法即可
exec: #对Pod容器内检查方式设置为exec方式
command: [string] #exec方式需要制定的命令或脚本
httpGet: #对Pod内个容器健康检查方法设置为HttpGet,需要制定Path、port
path: string
port: number
host: string
scheme: string
HttpHeaders:
- name: string
value: string
tcpSocket: #对Pod内个容器健康检查方式设置为tcpSocket方式
port: number
initialDelaySeconds: 0 #容器启动完成后首次探测的时间,单位为秒
timeoutSeconds: 0 #对容器健康检查探测等待响应的超时时间,单位秒,默认1秒
periodSeconds: 0 #对容器监控检查的定期探测时间设置,单位秒,默认10秒一次
successThreshold: 0
failureThreshold: 0
securityContext:
privileged:false
restartPolicy: [Always | Never | OnFailure] #Pod的重启策略,Always表示一旦不管以何种方式终止运行,kubelet都将重启,OnFailure表示只有Pod以非0退出码退出才重启,Nerver表示不再重启该Pod
nodeSelector: obeject #设置NodeSelector表示将该Pod调度到包含这个label的node上,以key:value的格式指定
imagePullSecrets: #Pull镜像时使用的secret名称,以key:secretkey格式指定
- name: string
hostNetwork:false #是否使用主机网络模式,默认为false,如果设置为true,表示使用宿主机网络
volumes: #在该pod上定义共享存储卷列表
- name: string #共享存储卷名称 (volumes类型有很多种)
emptyDir: {} #类型为emtyDir的存储卷,与Pod同生命周期的一个临时目录。为空值
hostPath: string #类型为hostPath的存储卷,表示挂载Pod所在宿主机的目录
path: string #Pod所在宿主机的目录,将被用于同期中mount的目录
secret: #类型为secret的存储卷,挂载集群与定义的secre对象到容器内部
scretname: string
items:
- key: string
path: string
configMap: #类型为configMap的存储卷,挂载预定义的configMap对象到容器内部
name: string
items:
- key: string
path: string
4.2.Pod 基本用法
# 1.根据以下配置文件创建一个单节点 redis
vi single-redis-pod.yaml
# 2.创建 pod
kubectl create -f single-redis-pod.yaml
# 3.查看创建的 pod
kubectl get pods
# 4.进入容器操作 redis
kubectl exec -it redis redis-cli
single-redis-pod.yaml
apiVersion: v1
kind: Pod
metadata:
name: redis
spec:
containers:
- name: redis
image: redis
ports:
- containerPort: 6379
执行以上操作后将创建一个 pod,该 pod 中运行着一个 redis 容器如下图所示:

同时我们也可以创建多个容器的 pod,如当两个容器应用为紧耦合关系时可以将其打包为一个 Pod 组合成一个整体对外提供服务。属于同一个 Pod 的多个容器应用直接相互访问仅需通过 localhost 就可以通信。

redis-nginx-pod.yaml
apiVersion: v1
kind: Pod
metadata:
name: redis-nginx
labels:
name: redis-nginx
spec:
containers:
- name: redis
image: redis
ports:
- containerPort: 6379
- name: nginx
image: nginx
ports:
- containerPort: 80
4.3.Pod 容器共享 Volume
同一个 Pod 中的多个容器可以共享 Pod 级别的存储卷 Volume。Volume 可以被定义为各种类型,多个容器各自进行挂载操作。以下例子为同一个 Pod 中的 tomcat 容器与 redis 容器共享 Volume 类型为 emptyDir(也可设置为其它类型)写入日志文件。

# 1.创建以下配置文件
vi shared-volume-pod.yaml
# 2.创建 pod
kubectl apply -f shared-volume-pod.yaml
# 3.执行以上操作后可以通过以下命令查看日志
kubectl logs shared-volume-pod -c redis
kubectl logs shared-volume-pod -c tomcat
shared-volume-pod.yaml
apiVersion: v1
kind: Pod
metadata:
name: shared-volume-pod
spec:
containers:
- name: tomcat
image: tomcat
ports:
- containerPort: 8080
volumeMounts:
- name: app-logs
mountPath: /usr/local/tomcat/logs
- name: redis
image: redis
ports:
- containerPort: 6379
volumeMounts:
- name: app-logs
mountPath: /data
volumes:
- name: app-logs
emptyDir: {}
4.4.Pod 的配置管理 ConfigMap
为了让镜像和配置文件解耦,以便实现镜像的可以执行和复用性 K8s 1.2 开始提供了一种统一的应用配置管理方案 ConfigMap。ConfigMap 以一个或多个 key:value 形式保存在 K8s 系统中供应用使用,实际就是一系列配置信息的集合,通常用来配置一些非敏感数据,如果涉及到密码秘钥等数据时需使用 Secret 类型。ConfigMap value 的长度是没有限制的,所以它可以是一整个配置文件信息。
Secret 和 ConfigMap可以理解为特殊的存储卷,但是它们不是给Pod提供存储功能的,而是提供了从集群外部向集群内部的应用注入配置信息的功能。ConfigMap扮演了K8S集群中配置中心的角色。
4.4.1.创建 ConfigMap 资源对象
创建 ConfigMap 资源对象有两种方式,一是直接使用 kubectl create configmap 命令方式,二是直接通过 YAML 配置文件方式。
4.4.1.1.通过命令行创建 configmap
命令行方式创建可以有三种方式,一是通过键值对创建,二是通过文件创建,三是通过文件夹创建。
(1)使用 --from–literal 参数 从文本中的键值对创建 configmap
# 每个 --from-literal 对应一个信息条目
kubectl create configmap literal-config --from-literal=key1=hello --from-literal=key2=world
(2)使用 --from-file 参数从文件中创建 configmap
# 1.创建配置文件
echo hello > test1.txt
ehco world > test2.txt
# 2.创建 configmap 每个文件内容对应一个信息条目
kubectl create configmap my-config --from-file=key1=test1.txt --from-file=key2=test2.txt
# 3.查看创建信息
kubectl describe configmap my-config
(3)使用 --from-file 参数从目录中创建 configmap
# 1.创建文件夹
mkdir config
# 2.创建配置文件
echo hello > config/test1
echo world > config/test2
# 3.创建 configmap 每个文件内容对应一个信息条目
kubectl create configmap dir-config --from-file=config/
# 4.查看创建信息
kubectl describe configmap dir-config
(4)使用 --from-env-file 参数从文件中的每行信息创建 configmap
# 1.创建配置文件
cat << EOF > env.txt
key1=hello
key2=world
EOF
# 2.创建 configmap 文件 env.txt 中每行 Key=Value 对应一个信息条目
kubectl create configmap my-env-config --from-env-file=env.txt
# 3.查看创建信息
kubectl describe configmap my-env-config

4.4.1.2.通过 yaml 文件创建 configmap
# 1.创建配置文件(使用以下配置文件内容)
vi config.yaml
# 2.创建 configmap
kubectl apply -f config.yaml
# 3.查看配置信息
kubectl describe configmap my-config
config.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: my-config
data:
key1: hello
key2: world
4.4.2.ConfigMap 的使用
ConfigMap 供容器使用有三种使用方式(注意创建 configmap 要在创建 pod 之前)。一是将 ConfigMap 中的数据设置为容器内的环境变量,二是将 ConfigMap 中的数据设置为容器启动命令的启动参数,三是以 Volume 形式挂载为容器内部的文件或目录。
4.4.2.1.配置到容器的环境变量
apiVersion: v1
kind: Pod
metadata:
name: redis
spec:
containers:
- name: redis
image: redis
ports:
- containerPort: 6379
env:
- name: KEY1 # 自行定义环境变量名称
valueFrom:
configMapKeyRef:
name: my-config # configmap 名称
key: key1 # 所使用的的key名称
- name: KEY2 # 自行定义环境变量名称
valueFrom:
configMapKeyRef:
name: my-config # configmap 名称
key: key2 # 所使用的的key名称
4.4.2.2.设置为容器启动命令的启动参数
apiVersion: v1
kind: Pod
metadata:
name: cm-test-pod
spec:
containers:
- name: cm-test
image: busybox
imagePullPolicy: IfNotPresent
command: [ "/bin/sh","-c","echo $(KEY1) $(KEY2)"] # 设置命令参数(需要有以下env定义)
env:
- name: KEY1
valueFrom:
configMapKeyRef:
name: my-config
key: key1
- name: KEY2
valueFrom:
configMapKeyRef:
name: my-config
key: key2
restartPolicy: Never # 由于是测试,设置 pod 执行完启动命令后退出,且不会被系统自动重启
4.4.2.3.挂载为容器内部的文件或目录
这里使用 nginx 配置为例,新建 nginx 首页 index.html 并挂载
# 1.创建 configmap yaml 配置文件(内容下附)
vi nginx-config.yaml
# 2.创建 configmap
kubectl apply -f nginx-config.yaml
# 3.创建 nginx pod 配置文件(内容下附)
vi nginx-config-pod.yaml
# 4.创建 pod 并使用 configmap 配置
kubectl apply -f nginx-config-pod.yaml
# 5.查看 pod 信息,获取 pod ip
kubectl describe pod test-nginx-config
# 6.访问 pod 校验结果
curl <IP>
nginx-config.yaml(注意别漏写了 nginx-index 后面的 | 符号)
apiVersion: v1
kind: ConfigMap
metadata:
name: nginx-config
data:
nginx-index: |
<html>
<head><title>Hello Nginx</title></head>
<body>
<p>Hello Nginx! This is a configmap page.</p>
</body>
</html>
nginx-config-pod.yaml
apiVersion: v1
kind: Pod
metadata:
name: test-nginx-config # 定义pod 名称
spec:
containers:
- name: nginx-config
image: nginx
ports:
- containerPort: 80
volumeMounts:
- name: nginxhtml # 所引用的 volume 的名称
mountPath: /usr/share/nginx/html # 挂载到容器内目录
volumes:
- name: nginxhtml # 定义volume 名称(注意格式不能是驼峰的,单词间可以使用 - 分割)
configMap:
name: nginx-config # 使用的 ConfigMap 的名称
items: # items下可以配置多个 key(即多个文件)
- key: nginx-index # 使用的配置文件中的配置 key
path: index.html # value 将 index.html 文件名进行挂载
volumes 中的 name 格式需如 ‘my-name’ 或 ‘123-abc’ 格式或不带 - 符号的数字与字符组合不能有大写字母否则创建 pod 会报以下错误:
The Pod “xxx” is invalid:* spec.volumes[0].name: Invalid value: “xxx”: a DNS-1123 label must consist of lower case alphanumeric characters or ‘-’, and must start and end with an alphanumeric character (e.g. ‘my-name’, or ‘123-abc’, regex used for validation is ‘a-z0-9?’)

4.4.3.ConfigMap 的约束
使用 ConfigMap 必须在 Pod 之前创建。ConfigMap 受 Namespace 限制,只有处于同一个 Namespace 中的 Pod 才能引用。在 Pod 对 ConfigMap 进行挂载操作时,在容器内部职能挂在为“目录”,无法挂在为 “文件”,ConfigMap 定义的 item 下可以指定为某个文件名挂载到容器指定目录下,该目录下有相同文件名则会被覆盖。
4.5.Pod 中的控制器
kube-controller-manager(控制器) 是K8s 的大脑, 它通过 apiserver 监控整个集群的状态, 并确保集群处于预期的工作状态。在 K8s 平台中我们很少会去直接创建一个 Pod,在大多数情况下会通过 RC、Deployment、DaemonSet、Job 等控制器来完成一组 Pod 副本的创建、调度以及全生命周期的自动控制任务。
4.5.1.ReplicationController (RC) 控制器
Replication Controller 简称 RC, 为 K8s 的一个核心内容。它就像一个进程管理器,监管者不同 node 上的多个 pod 同时会委派本地容器来启动一些节点上的服务(Kubectl,Dcker)。它会确保 K8s 中有指定数量的 Pod 在运行。如果少于指定数量的 pod,Replication Controller会创建新的,反之则会删除掉多余的以保证 Pod 数量不变。当pod不健康,运行出错或者无法提供服务时,Replication Controller 也会杀死不健康的 pod,重新创建新的。它还支持弹性伸缩,在业务高峰或者低峰期的时候,可以通过Replication Controller动态的调整pod的数量来提高资源的利用率。同时,配置相应的监控功能(Hroizontal Pod Autoscaler),会定时自动从监控平台获取Replication Controller关联pod的整体资源使用情况,做到自动伸缩。同时它也支持滚动升级。简单配置文件格式如下:
apiVersion: v1
kind: ReplicationController
metadata:
name: nginx
spec:
containers:
- name: nginx
image: nginx
ports:
- containerPort: 80
4.5.2.ReplicaSet 控制器
ReplicaSet(RS)是Replication Controller(RC)的升级版本。ReplicaSet 和 Replication Controller 之间的唯一区别是对选择器的支持。ReplicaSet支持 labels user guide 中描述的 set-based 选择器要求 Replication Controller 仅支持 equality-based 的选择器要求。K8s中一般我们不再使用 Replication Controller。简单配置文件格式如下:
apiVersion: v1
kind: ReplicaSet
metadata:
name: myapp
spec:
replicas: 2
selector:
matchLabels:
app: myapp
template: # pod模板
metadata:
name: myapp-pod
labels:
app: myapp
spec:
containers:
- name: myapp-container
image: docker.io/busybox:latest
command: ["sh","-c","sleep 3600"]
4.5.3.Deployment 控制器(推荐)
Deployment 为 Pod 和 Replica Set(下一代 Replication Controller)提供声明式更新。更加方便的管理 Pod 和 Replica Set。Deployment 具备上面描述的 RC 的全部功能,它又具备了 RC 之外的新特性。Deployment 支持事件和状态查看,可以查看 Deployment 的升级详细进度和状态。 Deployment 拥有更加灵活强大的升级、回滚功能,当升级 pod 镜像或者相关参数的时候发现问题,可以使用回滚操作回滚到上一个稳定的版本或者指定的版本。版本的指定来源于其版本记录的功能, 每一次对 Deployment 的操作,都能保存下来,给予后续可能的回滚使用。它还支持暂停和启动,对于每一次升级,都能够随时暂停和启动。具备 Recreate(删除所有已存在的pod,重新创建新的) 、RollingUpdate(滚动升级,逐步替换的策略,同时滚动升级时,支持更多的附加参数,例如设置最大不可用pod数量,最小升级间隔时间等等) 多种升级方案。
k8s 创建资源有两种方式:一是使用 kubectl 命令方式直接创建 。二是通过 yaml 配置文件和 kubectl apply 命令创建。正式的使用一般采用第二种方式。
4.5.3.1.kubectl 命令方式直接创建 Deployment
4.5.3.1.1.创建应用程序
# 1.创建并启动 名为 nginx-dep 的 nginx 服务,指定副本数为 2
kubectl run nginx-dep --image=nginx:1.7.9 --port=80 --replicas=2
# 2.查看服务信息
kubectl get pods -o wide
# 3.查看 deployment 信息
kubectl get deployment
# 4.测试 nginx服务,服务ip地址在第二步中可以获取到
curl 10.244.1.4

4.5.3.1.2.查看 pod 详情
# 查看 pod 详情
kubectl describe pod <POD_NAME>

4.5.3.1.3.使用 service 提供外部访问
pod 创建成功后,只能在集群内部通过 pod 的 ip 地址去访问该服务。当 pod 出现故障后 pod 的控制器会重新创建一个该服务的 pod 此时 ip 地址也会发生改变,为了保持 pod 访问 ip 地址不变做到对调用者无影响就需要我们创建一个 service(下文会对其展开阐述) 来统一 ip 不至于被改变,当 pod 重新创建后 service 会通过 pod 的 label 连接到该服务,我们只需通过 service 的 ip 访问该服务即可。此外虽然此时能通过 service 访问到 pod 服务。但在集群外部(如本地 windows)是无法访问到 nginx 服务的,还需要通过修改 service 的类型为 NodePort 才可访问。
# 1.创建 ngxin 的 service 把目标服务绑定到 service 的8080端口上
kubectl expose deployment nginx-dep --name=nginx-svc --port=8080 --target-port=80
# 2.查看 service 的配置
kubectl describe svc nginx-svc
# 3.修改 service 类型 ClusterIP -> NodePort
kubectl edit svc nginx-svc
# 4.查看绑定端口
kubectl get svc


4.5.4.1.5.服务在线升级与回滚
4.5.3.2.YAML 配置文件方式创建 Deployment
4.5.3.2.1.资源清单格式
apiVersion: group/apiversion # 不指定定group,默认为 croe
kind: #资源类别
metadata: #资源元数据
name
namespace #k8s自身的namespace
lables
annotations #主要目的是方便用户阅读查找
spec:#期望的状态(disired state)
status:#当前状态,本字段有kubernetes自身维护,用户不能去定义
注意:层级采用缩进方式,不支持制表符 “tab” 缩进,使用空格缩进,通常开头缩进 2 个空格,字符后缩进 1 个空格,如冒号,逗号等。“- - -” 表示 YAML格式一个文件的开始。注释使用 “#”
4.5.3.2.2.创建 deployment
以下定义文件内容与上文命令方式创建相同。但配置的方式会更易读,更为详尽。
vi nginx-deployment.yaml
apiVersion: apps/v1 # 配置格式的版本
kind: Deployment # 创建的资源类型,这里是deployment
metadata: # 元数据
name: nginx-deployment
namespace: default
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.7.9
ports:
- containerPort: 80
# 使用create 子命令以yaml文件的方式启动
kubectl create -f nginx-deployment.yaml

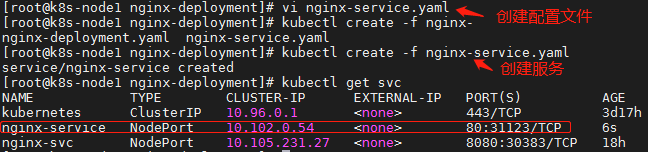
4.5.3.2.4.使用 service 提供外部访问
# 1.创建 service 资源配置文件
vim nginx-service.yaml
# 2.创建service
kubectl create -f nginx-service.yaml
# 3.查看 service
kubectl get svc
apiVersion: v1
kind: Service
metadata:
name: nginx-service
labels:
app: nginx
spec:
type: NodePort
ports:
- port: 80
targetPort: 80
nodePotr: 31123 #这里默认端口范围 30000-32767 如果想不在这个范围内可以修改 kube-apiserver.yaml 中的 service-node-port-range 范围。如果不配置会被随机指定一个端口
selector:
app: nginx

4.6.Pod 的扩缩容
在实际生产系统中,我们经常会遇到某个服务需要扩容的场景,也可能会遇到由于资源紧张或者工作负载降低而需要减少服务实例数量的场景。此时可以利用 Deployment/RC 的 Scale 机制来完成。
K8s 对 Pod 的扩缩容提供了手动和自动两种模式。手动模式可以通过 kubectl scale 命令或者通过 RESTful API 对一个 Deployment/RC进行 Pod 副本数量的设置即可。自动模式则需要用户根据某个性能指标或者自定义业务表,并指定 Pod 副本数量的范围,系统将自动在这个范围内根据性能指标的变化进行调整。
4.6.1.手动扩容机制
4.6.1.1.kubectl scale 命令方式
以上文 4.5.3.1 命令创建的 Deployment nginx-dep 为例
# 扩展与缩减命令一致,通过 指定 replicas 数量
kubectl scale --replicas=3 deployment nginx-dep

4.6.1.2.kubectl edit 命令方式
# 执行以下命令 i 进入编辑模式修改 replicas 数量
kubectl edit deploy nginx-dep

4.6.1.3.修改 yaml 配置文件方式
以上文 4.5.3.2 yaml 创建的 Deployment nginx-deployment 为例
# 1.编辑 nginx-deployment.yaml 修改 replicas 副本数为指定数量
vi nginx-deployment.yaml
# 2.执行命令,生效
kubectl apply -f nginx-deployment.yaml

4.6.2.自动扩容机制
4.6.2.1.K8s 自动扩容机制背景
早期 K8s 1.1版本开始提供了 Horizontal Pod Autoscaling(HPA)控制器用于实现基于 CPU 使用率(也仅仅只能基于此)进行 Pod 自动扩缩容的功能。K8s 1.6 版本开始引入了基于自定义性能指标的 HPA 机制,并在 1.9 版本之后逐步成熟。
4.6.2.2.自动扩容存在的意义
当业务量较大,涉及服务较多时手动扩缩容就不现实了。因为根据负载变化而做扩缩容这一过程本身就是不固定的,频繁的。K8s 为我们提供了一个资源对象: Horizontal Pod Autoscaling (Pod 水平自动伸缩)简称 HPA 。HPA通过监控分析 RC 或者 Deployment 控制的所有 Pod 的负载变化情况来确定是否需要调整 Pod 的副本数量。
4.6.2.1.Metrics Server(前置知识)
Metrics Server 是集群核心监控数据的聚合器。Metrics Server 通过 K8s 聚合器( kube- aggregator) 注册 到 主 API Server 之上,并定时通过 kubelet 的 Summary API 收集的资源指标信息,这些聚合过的数据将存储在内存中,同时以 Metrics API 形式暴露出去供查询(1.8 版本开始)。
在 Metrics Server 组件之前的实现是 heapster,heapster 从 1.11 版本开始逐渐被弃用。Metrics Server 与 heapster 一致监控数据是没有存放在内存中。因此是没有持久化的,重启后数据将全部丢失,且它只能保存最近收集的指标数据,所以如果需要获取访问历史数据,那就要借助于第三方监控系统如 Prometheus。
Metrics Server 提供:
- 适用于大多数集群的单一部署。
- 快速自动缩放,每15秒收集一次指标。
- 资源效率,为集群中的每个及诶单使用1毫厘 cpu 和 2MB 内存
- 可扩展支持多大 5000 个节点集群。
Metrics Server
4.6.2.2.HPA 工作原理
K8s 中的某个 Metrics Server(Heapster 或自定义 Metrics Server)持续采集所有 Pod 副本的指标数据。HPA 控制器通过 Metrics Server 的 API 获取监控数据,基于用户自定义扩缩容规则计算,得到目标 Pod 副本数量。当目标 Pod 副本数量与当前副本数量不一致时,HPA 控制器就会向 Pod 的副本控制器(Deployment / RC / ReplicaSet)发起 scale 操作来调整 Pod 的副本数量从而完成扩缩容动作。

这里引申下 Metrics Server(容器监控)
4.7.Pod 的升级和回滚
通过 Deployment 创建的 Pod 可以在运行时修改 Deployment 的 Pod 定义或者镜像名称并应用到 Deployment 对象上,系统即可完成对其自动更新操作。如果更新过程中发生错误还可通过回滚操作恢复 Pod 的版本。
4.7.1.Deployment 的升级
更新的过程可以概括为:当初始创建 Deployment 时,系统就创建了一个 ReplicaSet(简称 RS),并按照用户需求创建了 3个 Pod 副本。而当更新(升级)Deployment 时,系统会创建一个新的 ReplicaSet,并将副本数量扩大到1,随后将旧的 ReplicaSet 的 Pod 副本缩减为 2,之后系统按照相同更新策略对新旧两个 ReplicaSet 进行逐个调整,最后新的 ReplicaSet 运行了 3 个新版本 Pod 副本,旧的 ReplicaSet 副本数量则缩减为 0。如下图所示。

# 1.nginx 服务升级 1.7.9 -> 1.9.1
kubectl set image deployment nginx-dep nginx-dep=nginx:1.9.1
# 2.查看滚动更新的过程
kubectl get pod -w
# 3.更新完成后,查看确认版本
kubectl describe pod <POD_NAME>


4.7.2.Deployment 的回滚
有时我们需要将 Deployment 回滚到旧版本,默认情况下所有 Deployment 的发布历史记录都会被保留在系统中,以便于我们随时进行回滚。
4.7.2.1.探究发布历史记录
# 查看具体 Deployment 发布历史记录(以下四种格式任意一条均可查看)
kubectl rollout history deployment <DEPLOY_NAME>
kubectl rollout history deploy <DEPLOY_NAME>
kubectl rollout history deployment/<DEPLOY_NAME>
kubectl rollout history deploy/<DEPLOY_NAME>

注意:我们发现通 CHANGE-CAUSE 列中记录为 none 。那是由于在创建 Deployment 时没有使用参数 --record,使用该参数后 CHANGE-CAUSE 列中便可查看到使用命令的记录。否则查看记录时候该列为空的
所以在这之前我们先把之前创建的 deployment 删除,重新创建并加上参数 --record。
# 1.删除具体的 Deployment
kubectl delete deploy nginx-deployment
# 2.创建 Deployment 并加上参数 --record
kubectl apply -f nginx-deployment.yaml --record
# 3.起始配置文件中 nginx 版本为 1.7.9 间断性执行三次升级操作,中间需要间隔一定时间再执行下一条,给服务升级空出时间
kubectl set image deployment nginx-deployment nginx=nginx:1.8.1
kubectl set image deployment nginx-deployment nginx=nginx:1.9.1
kubectl set image deployment nginx-deployment nginx=nginx:1.9.7
# 4.查看发布历史记录
kubectl rollout history deployment nginx-deployment

通过以上操作,可以观察第一次 nginx 1.7.9 版本初始创建 + 后续三次升级版本 操作后能查询到一共 4条(个版本) 历史发布记录(1.7.9 -> 1.8.1 -> 1.9.1 -> 1.9.7)。如果我们在进行一次相同版本比如 1.8.1 版本的更新的话,那发布历史记录会产生怎样的变化?
# 5.执行更新版本为 1.8.1
kubectl set image deployment nginx-deployment nginx=nginx:1.8.1
# 6.再次查看发布历史记录
kubectl rollout history deployment nginx-deployment

我们发现第 2 条(个版本)记录(即升级版本为 1.8.1)的已经不见了,而新增加了一条版本为 5 的数据。为此我们可以总结出发布历史记录会根据更新操作相同(重复的)的原版本删除,而增加一条最新的版本变更记录,可以理解为版本变更记录是一个类似 “Set” 一样的集合,不存储相同操作,相同的(或者最新)的操作总在最后。
那以上记录都一致,我们如何查看具体版本记录下的详细信息?可以通过以下命令查看,如果做具体指定回滚版本时不确定版本信息可以先行查看。
# 查看指定版本详细信息,这里示例查看第 3个 发布历史记录
kubectl rollout history deployment nginx-deployment --revision=3

4.7.2.2.回滚操作
回滚操作可以回滚上一个版本,也可以执行版本回滚。
(1)回滚上一个版本
# 回滚上一个版本,这里以之前创建的 deployment nginx-dep 为例
kubectl rollout undo deployment nginx-dep

(2)回滚到指定版本
# 1.以上文创建的 deployment nginx-deployment 为例,回滚到版本3(即1.9.1版本)
kubectl rollout undo deployment nginx-deployment --to-revision=3
# 2.查看详细信息
kubectl describe deploy/nginx-deployment

4.7.3.Deployment 回滚操作的暂停与恢复
在 k8s 权威指南第四版中的标题为“暂停和恢复 Deployment 的部署操作,以完成复杂修改”,实际是有误的(当前部署版本中),与其说是暂定更新操作,不如更准确说是暂停回滚操作。通过实际操作可以发现当执行 Deployment 的暂停命令后,是无法做回滚操作,但是可以做更新操作如 kubectl set image 指定更新版本,以下是实际操作步骤。
# 1.暂定 Deployment 回滚操作
kubectl rollout history deploy/nginx-deployment
# 2.恢复 Deployment 回滚操作
kubectl rollout resume deploy/nginx-deployment

五、Service 理解与实践
Service 是 K8s 的核心概念, 通过创建 Service 可以为一组具有相同功能的容器应用提供一个统一的入口地址, 并且将请求负载分发到后端的各个容器应用上。Service 是一种抽象,是一种可以访问 Pod逻辑分组的策略。Service通常是通过 Label Selector访问 Pod组。
pod 在重新部署之后 ip 会改变,所以一般会通过 service 来访问 pod。core-dns 会给 service 分配一个内部的虚拟 ip(节点上根本查询不到这个ip,ping是不通的,具体是怎么访问到的继续往下看),因此内部服务可以通过这个ip或者是serviceName来访问到pod的服务。
5.1.Service 类型
在配置文件中的 spec.type
-
ClusterIP:虚拟的服务 IP 地址,默认方式。该地址用于 k8s 集群内部的 Pod 的访问,在 Node 上 kube-proxy 通过设置的 iptables 规则进行转发。
-
NodePort:使用宿主机的端口,使得能够访问各 Node 的外部客户端通过 Node 的 IP 地址和端口号就能访问服务。
-
LoadBalancer:使用外接负载均衡器完成到服务的负载分发,需要在 spec.status/loadBalancer 字段指定外部负载均衡的 IP 地址,并同时定义 nodePort 和 clusterIP,用于公有云环境。
-
ExternalName:将服务映射到 DNS 名称。是Service的一种特例,此模式主要面对运行在集群外部的服务。把集群外部的服务映射到集群内部来,在集群内部直接使用,为集群内部提供服务。没有任何类型代理被创建,这只有 K8s 1.7或更高版本的 kube-dns 才支持
5.2.Service 定义详解
apiVersion: v1 // Required 版本
kind: Service // Required
matadata:
name: string // Required service 名称需符合 RFC 1035 规范
namespace: string // Required 命名空间,不指定系统将使用名为 default
labels: // 自定义标签属性列表
- name: string
annotations: // 自定义注解属性列表
- name: string
spec: // Required 详细描述
selector: [] // Required Lable Selector 配置,将选择具有指定 Label 标签的 Pod作为管理范围
type: string // Required service 类型,指定 Service 的访问方式,默认值为 ClusterIP。
clusterIP: string // 虚拟服务 IP 地址,当 type=ClusterIP 时,如果不指定,则系统进行自动分配,也可以配置手动指定。当type=LoadBalancer 时,则需要指定。
sessionAffinity: string //是否支持 Session,可选值为 ClientIP,默认值为空。ClientIP:表示将同一个客户端(根据客户端的 IP 地址决定)的访问请求都转发到同一个后端 Pod
ports: list // 需要暴露的端口列表
- name: string // 端口名称
protocol: string // 端口协议,支持 TCP(默认)和 UDP
port: int // 端口号
targetPort: int // 需要转发到后端 Pod 的端口号
nodePort: int // 当 sepc.type=NodePort 时,指定映射到物理机的端口号
status: // 当 spec.type=LoadBalancer 时,设置外部负载均衡器地址,用于公有云环境
loadBalancer: // 外部负载均衡器
ingress: // 外部负载均衡器
ip: string //外部负载均衡器的 IP 地址
hostname: string // 外部负载均衡器的主机名
5.3.Service 基本用法
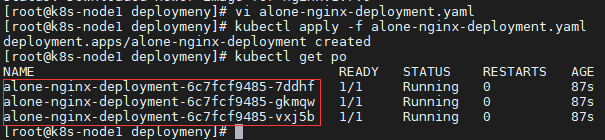
5.3.1.创建 deployment
# 1.创建 deployment.yaml 配置文件,内容下附
vi alone-nginx-deployment.yaml
# 1.创建 deployment
kubectl apply -f alone-nginx-deployment.yaml
alone-nginx-deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: alone-nginx-deployment
labels:
app: alone-nginx-deployment
spec:
replicas: 3
selector:
matchLabels:
app: alone-nginx-deployment
template:
metadata:
labels:
app: alone-nginx-deployment
spec:
containers:
- name: alone-nginx-deployment
image: nginx:1.7.9
ports:
- containerPort: 80
5.3.2.创建 service
创建 service 有两种方式,一种是 k8s 提供的 kubectl expose 命令快速创建,一种是定义 service.yaml 文件创建。
(1)方式一:
# 命令快速创建,默认 type 为 ClusterIP
kubectl expose deployment alone-nginx-deployment
(2)方式二:
# 1.创建 service.yaml 配置文件,内容下附
vi alone-nginx-service.yaml
# 2.创建 service
kubectl apply -f alone-nginx-service.yaml
alone-nginx-service.yaml
apiVersion: v1
kind: Service
metadata:
name: alonea-nginx-service
labels:
app: alonea-nginx-service
spec:
type: NodePort
ports:
- port: 80
targetPort: 80
selector:
app: alone-nginx-deployment

通过以上创建 service 前后通过命令 kubectl get endpoints 查询 endpoints(k8s中的资源)可以发现,我们在创建 service 的同时设置了 selector 关联的 pod,那就会同时创建一个与 service 同名的 endpoints 。它是用来记录 service 对应 pod 的访问地址的。由于我们启动的 nginx 副本数是 3 所以endpoints 中会存有 3 个 ip 地址。endpints 是通过 endpoint controller 维护的。
endpoint controller是k8s集群控制器的其中一个组件。负责生成和维护所有endpoint对象的控制器,负责监听service和对应pod的变化,监听到service被删除,则删除和该service同名的endpoint对象,监听到新的service被创建,则根据新建service信息获取相关pod列表,然后创建对应endpoint对象,监听到service被更新,则根据更新后service信息获取相关pod列表,然后更新对应endpoint对象,监听到pod事件,则更新对应的service的endpoint对象,将podIp记录到endpoint中。
持续更新中…忙完这阶段再继续更新。
















 850
850











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









