







简介
布隆过滤器(Bloom Filter)是非常经典的,以空间换时间的算法。布隆过滤器由布隆在 1970 年提出。它实际上是一个很长的二进制向量和一系列随机映射函数。布隆过滤器可以用于检索一个元素是否在一个集合中。它的优点是空间效率和查询时间都远远超过一般的算法,缺点是有一定的误识别率和删除困难。
布隆过滤器的原理
布隆过滤器的实现原理是一个超大的位数组和几个哈希函数。假设位数组的长度为 m,哈希函数的个数为 k。

解析上图,具体的操作流程:假设集合里面有 3 个元素 {x, y, z},哈希函数的个数为 3。首先将位数组进行初始化,初始化状态的维数组的每个位都设置位 0。对于集合里面的每一个元素,将元素依次通过 3 个哈希函数进行映射,每次映射都会产生一个哈希值,这个值对应位数组上面的一个点,然后将位数组对应的位置标记为 1。查询某元素是否存在集合中的时,用同样的方法将 W 通过哈希映射到位数组上的 3 个点。如果 3 个点中任意一个点不为 1,则可以判断该元素一定不存在集合中。反之,如果 3 个点都为 1,则该元素可能存在集合中。注意:此处不能判断该元素是否一定存在集合中,可能存在一定的误判率,这一点从图中就能得知:假设某个元素通过映射对应下标为 4、5、6 这 3 个点。虽然这 3 个点都为 1,但是很明显这 3 个点是不同元素经过哈希得到的位置,因此这种情况说明元素虽然不在集合中,也可能对应的都是 1,这是误判率存在的原因。
布隆过滤器添加和查询元素
添加元素
将要添加的元素分别通过k个哈希函数计算得到k个哈希值,这k个hash值对应位数组上的k个位置,然后将这k个位置设置为1。
查询元素
将要查询的元素分别通过k个哈希函数计算得到k个哈希值,这k个hash值对应位数组上的k个位置,如果这k个位置中有一个位置为0,则此元素一定不存在集合中,如果这k个位置全部为1,则这个元素可能存在。
假阳性率
所谓假阳性率就是本来在集合中不存在的元素,被判定为存在的概率。
假阳性是BF最大的痛点,因此有必要权衡,比如计算一下假阳性的概率。为了简单一点,就假设我们的哈希函数选择位数组中的比特时,都是等概率的。当然在设计哈希函数时,也应该尽量满足均匀分布。
在位数组长度m的BF中插入一个元素,它的其中一个哈希函数会将某个特定的比特置为1。因此,在插入元素后,该比特仍然为0的概率是:
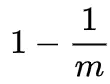
现有k个哈希函数,并插入n个元素,自然就可以得到该比特仍然为0的概率是:
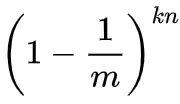
反过来讲,它已经被置为1的概率就是:

也就是说,如果在插入n个元素后,我们用一个不在集合中的元素来检测,那么被误报为存在于集合中的概率(也就是所有哈希函数对应的比特都为1的概率)为:

当n比较大时,根据重要极限公式,可以近似得出假阳性率:
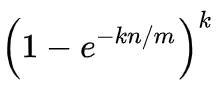
因此,可以得出如下结论,在哈希函数的个数k一定的情况下:
- 位数组长度m越大,假阳性率越低
- 已插入元素的个数n越大,假阳性率越高
如何选择适合业务的 k 和 m 值呢,直接贴一个公式:
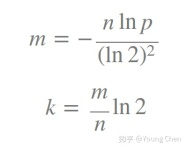
布隆过滤器的优缺点
优点
- 相比于其它的数据结构,布隆过滤器在空间和时间方面都有巨大的优势。布隆过滤器存储空间和插入/查询时间都是常数(即hash函数的个数)
- Hash 函数相互之间没有关系,方便由硬件并行实现
- 布隆过滤器不需要存储元素本身,在某些对保密要求非常严格的场合有优势
- 布隆过滤器可以表示全集,其它任何数据结构都不能。
缺点
但是布隆过滤器的缺点和优点一样明显:
- 误算率(False Positive)是其中之一。随着存入的元素数量增加,误算率随之增加(误判补救方法是:再建立一个小的白名单,存储那些可能被误判的信息)。但是如果元素数量太少,则使用散列表足矣。
- 一般情况下不能从布隆过滤器中删除元素。我们很容易想到把位列阵变成整数数组,每插入一个元素相应的计数器加 1, 这样删除元素时将计数器减掉就可以了。然而要保证安全的删除元素并非如此简单。首先我们必须保证删除的元素的确在布隆过滤器里面. 这一点单凭这个过滤器是无法保证的。另外计数器回绕也会造成问题。
BloomFilter的实现方式
目前市面上有很多实现布隆过滤器的方式,我们这里简单的介绍几种。
使用GUAVA实现布隆过滤器
1.第一步:加入guava依赖
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>29.0-jre</version>
</dependency>
2.编写布隆过滤器
/**
* Guava版布隆过滤器
*
*/
public class BloomFilterTest {
/**
* @param expectedInsertions 预期插入值
* 这个值的设置相当重要,如果设置的过小很容易导致饱和而导致误报率急剧上升,如果设置的过大,也会对内存造成浪费,所以要根据实际情况来定
* @param fpp 误差率,例如:0.001,表示误差率为0.1%
* @return 返回true,表示可能存在,返回false一定不存在
*/
public static boolean isExist(int expectedInsertions, double fpp) {
// 创建布隆过滤器对象
BloomFilter<Integer> filter = BloomFilter.create(Funnels.integerFunnel(), 500, 0.01);
// 判断指定元素是否存在
System.out.println(filter.mightContain(10));
// 将元素添加进布隆过滤器
filter.put(10);
// 再判断指定元素是否存在
System.out.println(filter.mightContain(10));
return filter.mightContain(10);
}
public static void main(String[] args) {
boolean exist = isExist(100000000, 0.001);
}
}
特别注意:Guava 提供的布隆过滤器,有个很大的缺陷就是只能单机使用。为了解决这个问题,后面可以考虑使用 Redis 提供的布隆过滤器。
使用Redis实现布隆过滤器
之前的布隆过滤器可以使用Redis中的位图操作实现,直到Redis4.0版本提供了插件功能,Redis官方提供的布隆过滤器才正式登场。布隆过滤器作为一个插件加载到Redis Server中,就会给Redis提供了强大的布隆去重功能。
使用Redis中的bitmap实现布隆过滤器
有现成的插件不用,谁还会累死累活的自己实现?
当然,这里还是贴出一个通过bitmap实现方式。详见使用Redis的bitmap实现布隆过滤器
使用Redis中的布隆过滤器插件
1.安装插件
通过https://github.com/RedisBloom/RedisBloom下载Redis布隆过滤器插件RedisBloom-master.zip,并上传到linux。
unzip RedisBloom-master.zip
cd RedisBloom-master
make
执行完以上命令 后文件夹内生成一个文件名为:redisbloom.so。
启动redis 时加载该模块:
redis-server redis-6381.conf --loadmodule /zjl/software/RedisBloom-master/redisbloom.so
2.验证
127.0.0.1:6379> bf.add user Tom
(integer) 1
127.0.0.1:6379> bf.add user John
(integer) 1
127.0.0.1:6379> bf.exists user Tom
(integer) 1
127.0.0.1:6379> bf.exists user Linda
(integer) 0
127.0.0.1:6379> bf.madd user Barry Jerry Mars
1) (integer) 1
2) (integer) 1
3) (integer) 1
127.0.0.1:6379> bf.mexists user Barry Linda
1) (integer) 1
2) (integer) 0
需要注意,如果不手动设置redis中的布隆过滤器的参数,就会使用redis默认的配置,但是着很有可能不符合我们的实际需要,所以我们尽量提前初始化布隆过滤器,通过如下命令:
bf.reserve key、error_rate initial_size
参数解释:
- key:此布隆过滤器的key值
- error_rate:表示错误率,此值越低,需要的空间越大
- initial_size:表示预计放入的元素数量,当实际数量超过这个值时,误判率就会提升,所以需要提前设置一个较大的数值避免超出导致误判率升高
3.通过redis的java客户端操作布隆过滤器,代码如下:
public class RedissonBloomFilterDemo {
public static void main(String[] args) {
Config config = new Config();
config.useSingleServer().setAddress("redis://127.0.0.1:6379");
RedissonClient redisson = Redisson.create(config);
RBloomFilter<String> bloomFilter = redisson.getBloomFilter("user");
// 初始化布隆过滤器,预计统计元素数量为55000000,期望误差率为0.03
bloomFilter.tryInit(55000000L, 0.03);
bloomFilter.add("Tom");
bloomFilter.add("Jack");
System.out.println(bloomFilter.count()); //2
System.out.println(bloomFilter.contains("Tom")); //true
System.out.println(bloomFilter.contains("Linda")); //false
}
}
布隆过滤器的使用场景
利用布隆过滤器减少磁盘 IO 或者网络请求,因为一旦一个值必定不存在的话,就可以直接结束查询,比如以下场景:
- 大数据去重;
- 网页爬虫对 URL 的去重,避免爬取相同的 URL 地址;
- 反垃圾邮件,从数十亿个垃圾邮件列表中判断某邮箱是否垃圾邮箱;
- 缓存击穿,将已存在的缓存放到布隆中,当黑客访问不存在的缓存时迅速返回避免缓存及数据库挂掉。















 1408
1408











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









