






文章目录
一、MapReduce
1.1、MapReduce思想
- MapReduce的思想核心是“先分再合,分而治之”。
- 所谓“分而治之”就是把一个复杂的问题,按照一定的分解方法分为等价的规模较小的若干部分,然后逐个解决,分别找出各部分的结果,然后把各部分的结果组成整个问题的最终结果。
- Map表示第一阶段:负责拆分:即把复杂的任务分解为若干个“简单的子任务”来进行并行处理。可以进行拆分的前提是这些小人物可以并行计算,彼此之间几乎没有依赖关系。
- Reduce表示第二阶段,负责合并:即对map阶段的结果进行全局汇总。
1.2、MapReduce实例进程
一个完整的MapReduce程序在分布式运行时有三类:
- MRAppMaster: 负责整个MR程序的过程调度及状态协调。
- MapTask: 负责map阶段的整个数据处理流程。
- Reduce:负责reduce阶段的整个数据处理流程。
1.3、MapReduce阶段组成
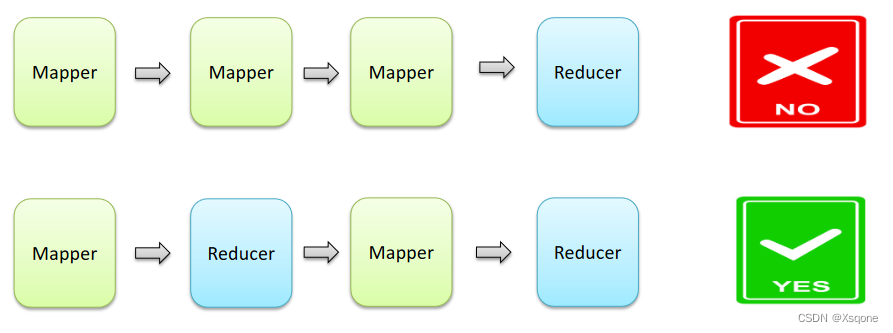
- 一个MapReduce编程模型中只能包含一个Map阶段和一个Reduce阶段,或者只有Map阶段。
- 如果业务逻辑复杂,只能使用多个MapReduce查询串行运行。
1.4、MapReduce数据类型
- 整个MapReduce程序中,数据都是以KV键值对的形式流传的。
1.5、MapReduce关键类
- GenericOptionsParser是为Hadoop框架解析命令行参数的工具类。
- InputFormat接口,实现类包括:Fileinputformat 等,主要作用于文件为输入及切割。
- Mapper将输入的kv对映射成中间数据kv对集合。Maps将输入记录转变为中间记录。
- Reducer根据key将中间数据集合处理合并为更小的数据结果集。
- Partitioner对数据安装key进行分区。
- OutputCllector文件的输出。
- Combiner本地聚合,本地化的reduce。
1.6、MapReduce执行流程

1.6.1、Map阶段执行流程
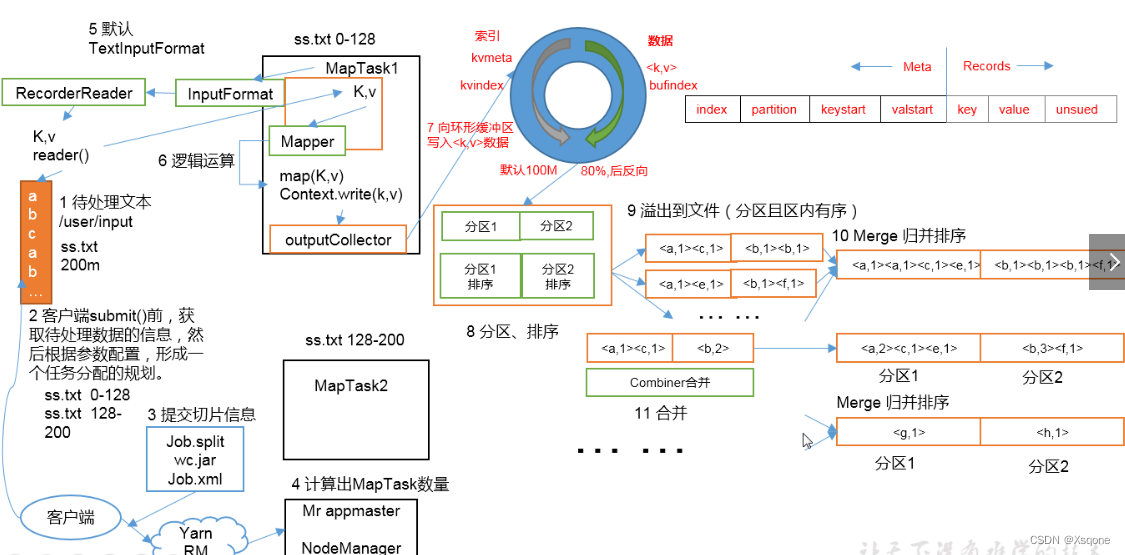
- 在MapReduce程序读取文件的输入目录上存放相应文件。
- 按照一定的标准逐个进行逻辑切片,形成切片规划
默认Split size = Block size(128M),每一个切片由一个MapTask处理。
切片会有1.1的冗余(每次切片时,都要判断切完剩下的部分是否大于块的1.1倍,不大于1.1配就会划分为一块切片) - 提交信息给yarn
包含(切片,jar包,以及job运行相关参数)。 - yarn启动MRAPPmaster根据切片个数计算出需要的MapTask数量。
- 使用客户端指定的InputFormat来读取数据,返回对应的<k,v>键值对
InputFormat默认使用子类TextInputFormat的createRecordReader(规则为LineRecordReader)来逐行读取数据。
返回的<k,v>键值对:k为偏移量,v为偏移量的内容。 - 将<k,v>键值对传给客户端定义的map方法,做逻辑运算。
1.6.2、Map的shuffle阶段执行流程
- map运算完后将结果<k,v>写入环形缓冲区
环形缓冲区默认100M(内存) - 进行分区、排序
- 溢出到文件(分区且区内有序)
到达80%进行溢写到磁盘,在缓冲区中数据进行反向写。 - Merge归并排序。
把所有溢出的临时文件进行一次合并操作,以确保一个MapTask最终只产生一个中间数据文件。 - Combiner合并。
在程序中可以选用,在reduce前进行预先处理数据。
1.6.3、Reduce阶段执行流程
- 在MapTask任务完成后,启动相应数量的ReduceTask,并告知ReduceTask处理数据分区。
- ReduceTask进程启动后,从MapTask拉取数据
- 进行归并排序,按照相同key的KV为一组,调用客户端定义的reduce()方法进行逻辑运算。
- 运算完毕后,使用OutPutFormat将结果输出到文件。
默认为TextOutputFormat的RecordWriter方法
1.7、MapReduce实例WordCount
WordCountDriver
package org.example.workcount;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
/**
* @program: hadoopstu
* @interfaceName WordCountDriver
* @description:
* @author: 太白
* @create: 2023-02-06 12:16
**/
public class WordCountDriver {
public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException {
Configuration configuration = new Configuration();
Job job = Job.getInstance(configuration);
job.setJarByClass(WordCountDriver.class);
job.setMapperClass(WordCountMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
job.setReducerClass(WordCountReduce.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
// 指定map输入的文件路径
FileInputFormat.setInputPaths(job, new Path("E:\\lovejava\\student\\hadoopstu\\in\\workcount.txt"));
// 指定reduce输出的文件路径
Path path = new Path("E:\\lovejava\\student\\hadoopstu\\in\\out1");
FileSystem fileSystem = FileSystem.get(path.toUri(), configuration);
if (fileSystem.exists(path)) {
fileSystem.delete(path, true);
}
FileOutputFormat.setOutputPath(job,path);
job.waitForCompletion(true);
}
}
WordCountMapper
package org.example.workcount;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
/**
* @program: hadoopstu
* @interfaceName WordCountMapper
* @description:
* @author: 太白
* @create: 2023-02-06 12:16
**/
public class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
Text text = new Text();
IntWritable intWritable = new IntWritable();
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, IntWritable>.Context context) throws IOException, InterruptedException {
System.out.println("WordCountMapper stage key:"+key+"value:"+value);
String[] words = value.toString().split(" ");
for (String word : words) {
text.set(word);
intWritable.set(1);
context.write(text,intWritable);
}
}
}
WordCountReduce
package org.example.workcount;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
/**
* @program: hadoopstu
* @interfaceName WordCountReduce
* @description:
* @author: 太白
* @create: 2023-02-06 12:16
**/
public class WordCountReduce extends Reducer<Text, IntWritable, Text, LongWritable> {
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Reducer<Text, IntWritable, Text, LongWritable>.Context context) throws IOException, InterruptedException {
System.out.println("reduce stage key:"+key+"values:"+values.toString());
int count = 0;
for (IntWritable value : values) {
count += value.get();
}
// LongWritable longWritable = new LongWritable();
// longWritable.set(count);
LongWritable longWritable = new LongWritable(count);
System.out.println("key:"+key+"resultValue:"+longWritable.get());
context.write(key,longWritable);
}
}
二、YARN
2.1、YARN简介
- Apache Hadoop YARN (Yet Another Resource Negotiator,另一种资源协调者)是一种新的Hadoop资源管理器。
- 是一个通用资源管理系统,可为上层应用提供统一的资源管理和调度。
- 它的引入为集群在利用率、资源同一管理和数据共享等方面带来巨大好处。
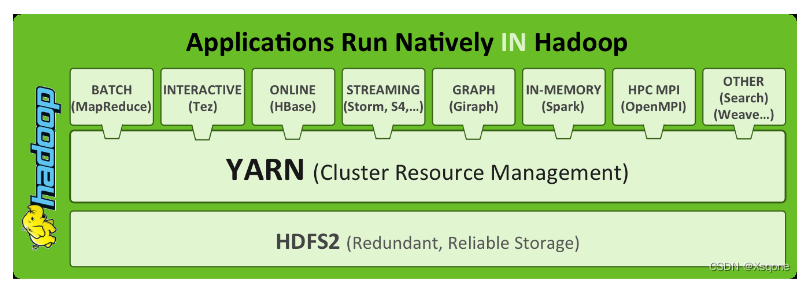
- 可以把Hadoop YARN理解为一个分布式的操作系统平台,而MapReduce等计算程序则相等于云星宇操作系统之上的应用程序,YARN为这些程序提供运算所需的资源。
2.2、功能说明
- 资源管理系统:集群的硬件资源,和程序运行相关。比如内存、CPU等。
- 调度平台:多个程序同时申请计算资源如何分配、调度的规则(算法)。
- 通用:不仅仅支持MapReduce程序,理论上支持各种计算程序。YARN不关心你干什么,只关心你要资源,在有的情况下给你,用完之后还我。
2.3、YARN架构、组件
- ResourceManager(RM)
YARN中的主角色,决定系统中所有应用程序之间资源分配的最终权限,即最终仲裁者。
接收用户的作业提交,并通过NM分配、管理各个机器上的计算资源。- NodeManager(NM)
YARN中的从角色,一台机器上一个,负责管理本机器上的计算资源。
根据RM命令,启动Container容器(资源的抽象)、件事容器的资源使用情况。并且向RM主角色会报资源使用情况。- ApplicationMaster(AM)
用户提交的每个应用程序均包含一个AM。
负责程序内部各阶段的资源申请,监督程序的执行情况。
2.4、YARN执行流程
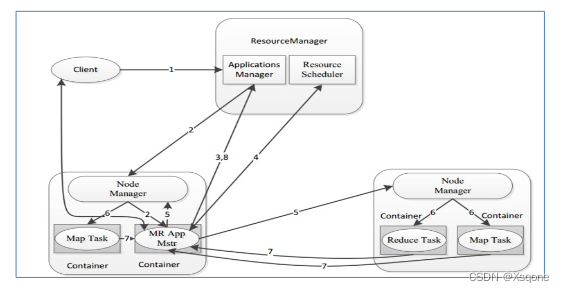
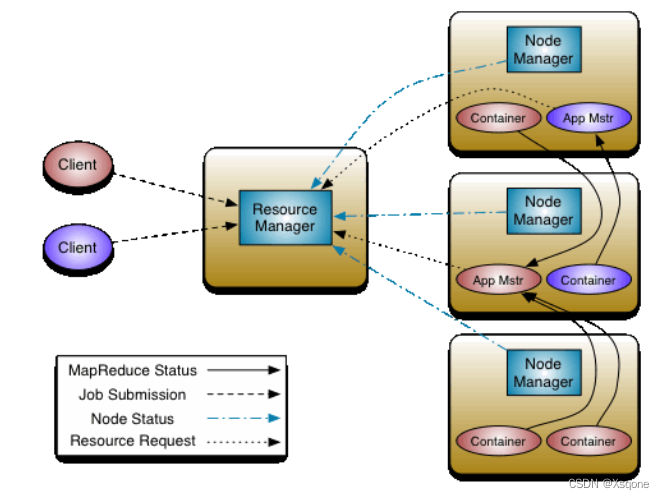
- 用户通过客户端向YARN中ResourceManager提交应用程序。
- ResourceManager为该应用程序分配第一个Container(容器),并与对应的NodeManager通信,要求
它在这个Container中启动这个应用程序的ApplicationMaster。 - ApplicationMaster启动成功之后,首先向ResourceManager注册并保持通信,这样用户可以直接通过ResourceManage查看应用程序的运行状态(处理了百分之几)。
- AM为本次程序内部的各个Task任务向RM申请资源,并监控它的运行状态。
- 一旦 ApplicationMaster 申请到资源后,便与对应的 NodeManager 通信,要求它启动任务。
- NodeManager 为任务设置好运行环境后,将任务启动命令写到一个脚本中,并通过运行该脚本启动任务。
- 各个任务通过某个 RPC 协议向 ApplicationMaster 汇报自己的状态和进度,以让 ApplicationMaster 随时掌握各个任务的运行状态,从而可以在任务失败时重新启动任务。在应用程序运行过程中,用户可随时通过RPC向ApplicationMaster 查询应用程序的当前运行状态。
- 应用程序运行完成后,ApplicationMaster 向 ResourceManager 注销并关闭自己。
2.5、YARN资源调度器Schedule
-
在理想情况下,应用程序提出的请求将立即得到YARN批准。但是实际中,资源是有限的,并且在繁忙的群集上,应用程序通常将需要等待其某些请求得到满足。YARN调度程序的工作是根据一些定义的策略为应用程序分配资源。
-
在YARN中,负责给应用分配资源的就是Scheduler,它是ResourceManager的核心组件之一。Scheduler完全专用于调度作业,它无法跟踪应用程序的状态。
-
一般而言,调度是一个难题,并且没有一个“最佳”策略,为此,YARN提供了多种调度器和可配置的策略供选择。
-
三种调度器
FIFO Scheduler(先进先出调度器)、Capacity Scheduler(容量调度器)、Fair Scheduler(公平调度器)。 -
Apache版本YARN默认使用Capacity Scheduler。
-
如果需要使用其他的调度器,可以在yarn-site.xml中的yarn.resourcemanager.scheduler.class进行配置。















 1281
1281











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









