







Scrapy Redis的使用
Scrapy Redis
Scrapy Redis是Scrapy框架基于redis分布式的一个组件,用于在分布式环境下使用Redis作为共享的调度器和去重器。它可以让多个Scrapy爬虫共享同一个Redis数据库,从而实现高效的分布式爬取。
GitHub地址:https://github.com/rmax/scrapy-redis
主要特点
基于Redis的去重机制:通过将URL哈希值存储在Redis中,实现对重复URL的过滤
基于Redis的调度器:将爬虫任务队列存储在Redis中,实现多个爬虫的调度
支持多个Spider同时运行:通过为每个Spider分配一个独立的Redis key,实现多个Spider同时运行,互不干扰
支持分布式部署:可以将多个Scrapy爬虫部署在不同的服务器上,通过共享同一个Redis数据库来实现分布式爬取
基本使用
安装Scrapy-Redis库
pip install scrapy-redis
定义DemoItem数据模型
在items.py文件中定义DemoItem数据模型对象
import scrapy
class DemoItem(scrapy.Item):
# 标题
title = scrapy.Field()
# 数量
count = scrapy.Field()
# 创建时间
create = scrapy.Field()
# 爬虫名称
spider = scrapy.Field()
定义分布式爬虫
使用Scrapy Redis提供的RedisSpider类来替代普通的Spider类。RedisSpider会自动从Redis队列中获取待爬取的URL,并将URL哈希值存储在Redis中,实现去重。
这个Spider会从Redis队列
myspider:start_urls中获取待爬取的URL,并使用Scrapy Redis的去重机制去重。在分布式环境中,可以将同一个Redis队列myspider:start_urls共享给多个Scrapy爬虫,从而实现分布式爬取。
from scrapy_redis.spiders import RedisSpider
from scrapy_project.items import DemoItem
class MySpider(RedisSpider):
name = 'my_spider'
# Redis Key,相当于初始请求链接
redis_key = 'my_spider:start_urls'
# 设置__init__
def __init__(self, *args, **kwargs):
domain = kwargs.pop('domain', '')
self.allowed_domains = list(filter(None, domain.split(',')))
super(MySpider, self).__init__(*args, **kwargs)
def parse(self, response):
list = response.xpath('/html/body/div[4]/div/div[2]/div/h2/text()').extract()
print(len(list))
index = 1
for title in list:
div = "div[" + str(index) + "]"
index = index + 1
count = response.xpath('/html/body/div[4]/div/div[2]/' + div + '/a/h4/text()').extract()
item = DemoItem()
item['title'] = title
item['count'] = len(count)
yield item
定义管道
定义一个管道,添加额外的信息
from datetime import datetime
class ExamplePipeline(object):
def process_item(self, item, spider):
print("*" * 20)
now = datetime.now()
formatted_time = now.strftime('%Y-%m-%d %H:%M:%S')
item["create"] = formatted_time
item["spider"] = spider.name
print(dict(item))
return item
Scrapy Redis配置
在settings.py添加Scrapy Redis相关的设置
# 使用Scrapy Redis的去重器
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
# 使用Scrapy Redis的调度器
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
# 调度器持久化设置,如果设置为True,会在爬虫关闭时保存未完成的请求,以便下次启动时继续执行。
SCHEDULER_PERSIST = True
# Redis连接配置
REDIS_URL = 'redis://localhost:6379'
# 或者使用下面的方式
# REDIS_HOST = "127.0.0.1"
# REDIS_PORT = 6379
ITEM_PIPELINES = {
# 自定义管道
'scrapy_project.pipelines.ExamplePipeline': 200,
# 开启管道,管道将会把数据存到Redis数据库中
'scrapy_redis.pipelines.RedisPipeline': 300,
}
# 下载延迟,方便调试
DOWNLOAD_DELAY = 1
指定redis_key
在redis命令行添加redis_key
Redis:0>lpush my_spider:start_urls https://www.runoob.com
"1"
Redis:0>
启动爬虫
可以多开几个窗口执行启动爬虫命令,模拟分布式爬虫效果
scrapy crawl my_spider
scrapy crawl my_spider
爬取结果如下:
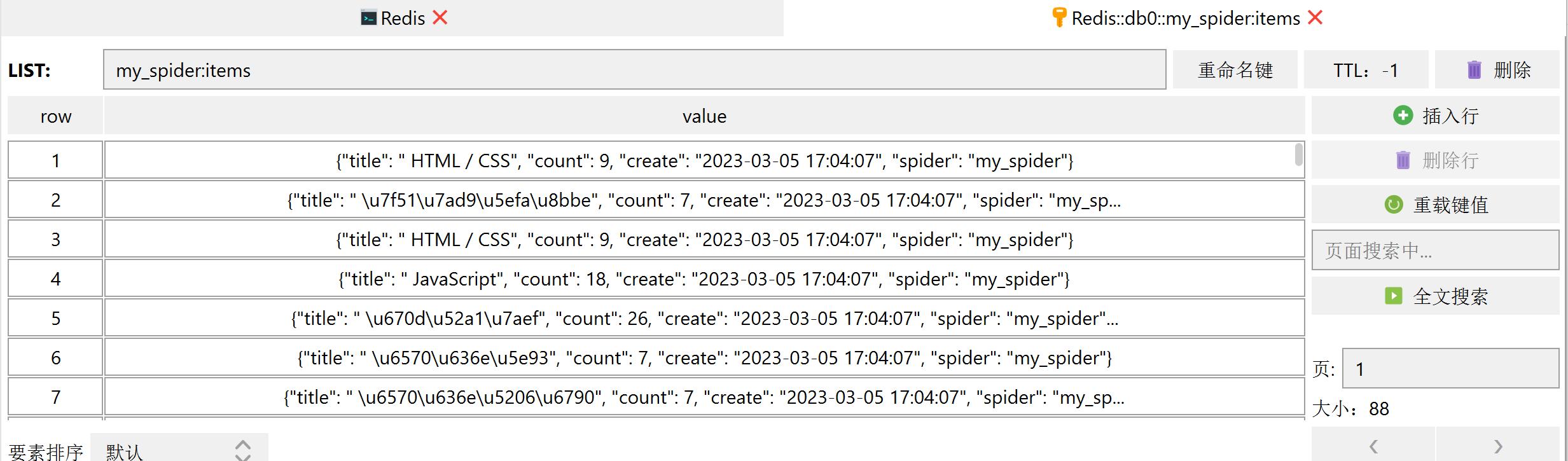
去重原理
通过将URL的哈希值存储在Redis中,Scrapy Redis可以实现高效的去重操作。在处理大规模、高并发的分布式爬取任务时,Scrapy Redis可以显著提升爬取效率和性能
具体去重原理如下:
1.Scrapy Redis会将每个URL的哈希值(MD5值)存储在Redis的Set中,用于记录已经爬取过的URL。同时,它会将URL及其哈希值存储在Redis的Hash中,用于记录URL对应的相关信息,例如爬取时间、爬取状态等。
2.当Scrapy Redis获取一个新的URL时,它会计算该URL的哈希值,并在Redis的Set中查找是否存在该哈希值。如果存在,说明该URL已经被爬取过,直接丢弃;如果不存在,说明该URL是新的待爬取的URL。
3.在处理完一个URL后,Scrapy Redis会将该URL及其哈希值从Redis的Hash和Set中删除,以便后续的URL再次爬取


















 2486
2486

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











