







以《我的微信连三界》这本小说为例,进行字符统计
- 对中文、英文、标点符号、数字等分别统计, 统计结果暂时储存在字典 countchr 中
- 用jieba库的分词功能将文本中所有可能的词(和字符)分离出来,统计每个词(和字符)出现频率,降序排列并保存
- “词频”保存在 “jieba lcut.txt” 中, "字符频率"保存在 “jieba lcut1.txt” 中
- 将高频字词和countchr一起保存在 “countchar.txt” 中
运行结果如下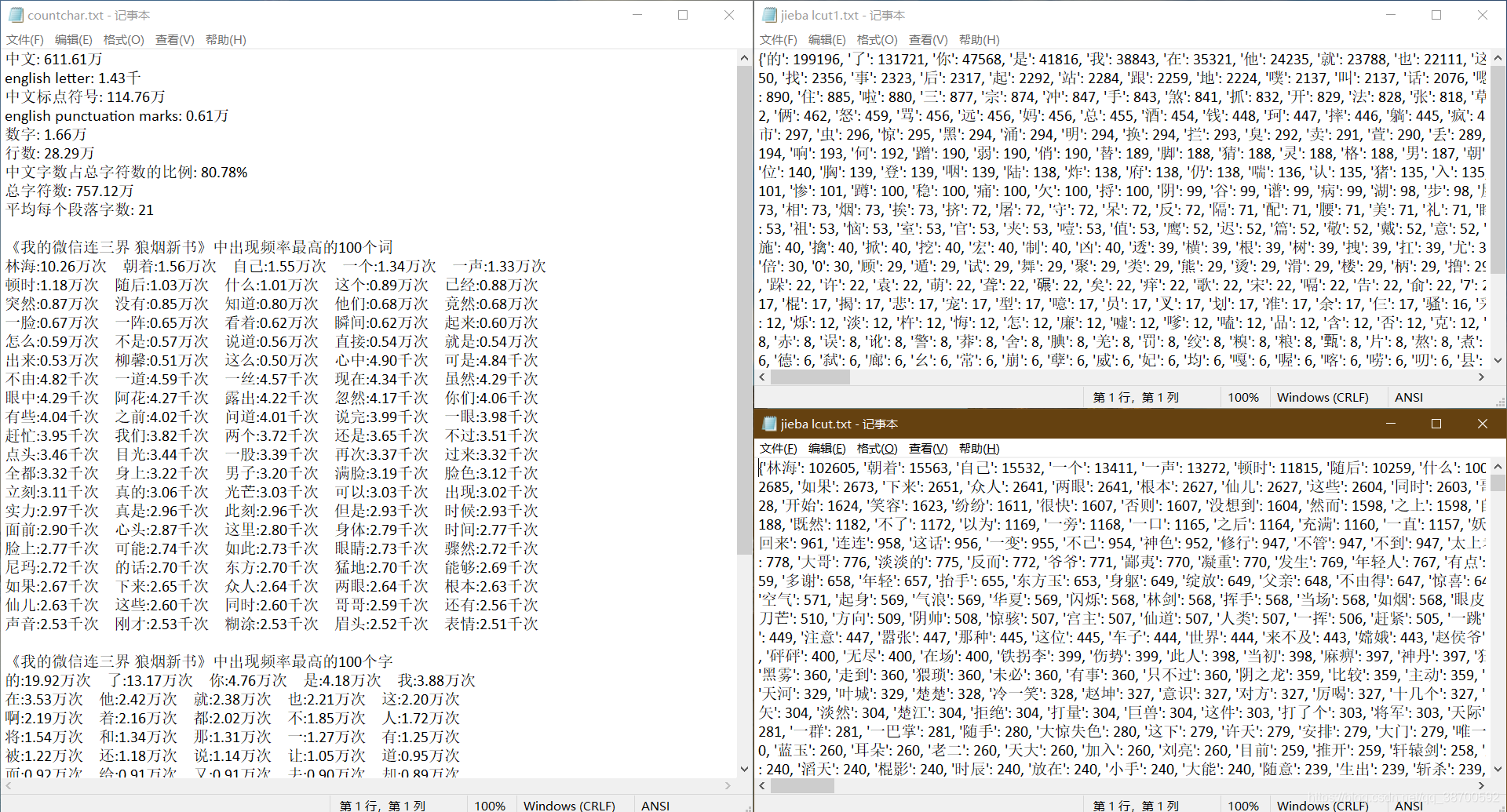
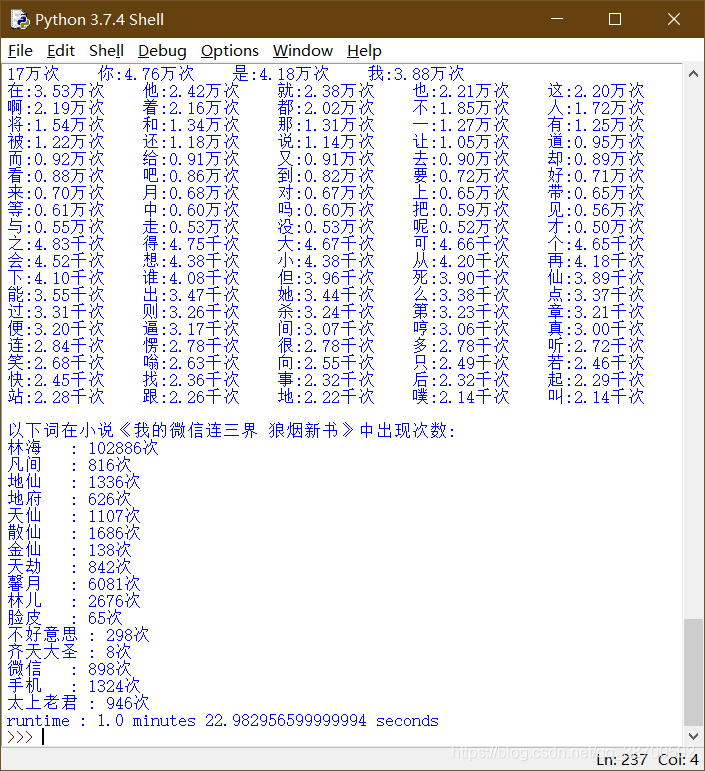
这样看着不是很舒服, 用excel处理了下
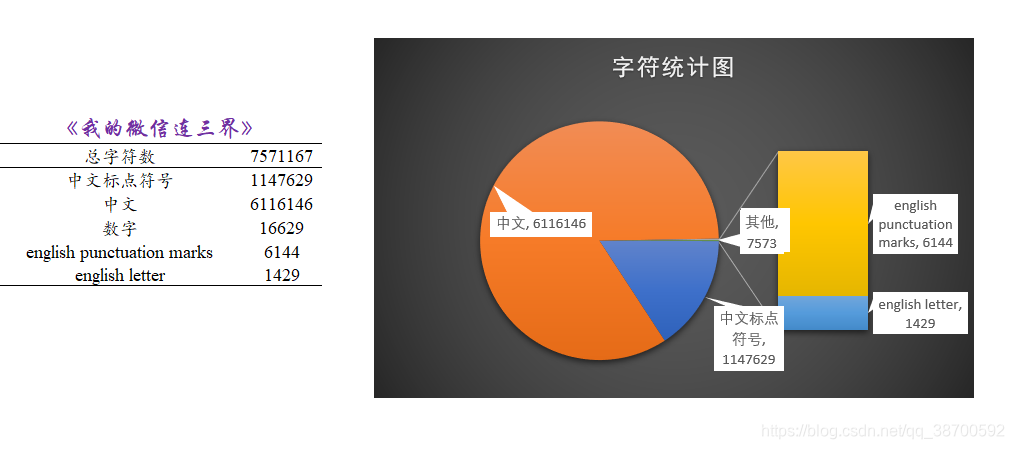
因为小说里有很多微信聊天的情景, 平均每个段落才21字, 比较短
主角名字占了20万字的篇幅, 有点小惊讶, "的"字出现频率最高, 这个在预料之中
在网上随机找了十几本小说试了下, 有如下规律
- 标点符号约占五分之一
- 主角名出现次数一般是最多的
- “的”、“了”、“是”、“他”这四个字使用频率都很高
- 平均每章2000~3000字, 按掌阅一章1毛多一点计算, 平摊下来5分/千字. 假设作者每分钟可以码60字, 每天稳定更两章, 每天需要码字2小时.
完整代码如下
import os
import time
import jieba
import asyncio
# hs中不储存标点符号,标点符号只统计总数,不分别统计?
pcd = {
3: '·、【】!¥—~……();‘’:“”《》,。?、',
4: ''' `~!@#$%^&*()_+-={}|:%<>?[]\;',./×''',
} # uncuaion
hs0 = {
1: 0, # 中文
2: 0, # english letter
3: 0, # 中文标点符号
4: 0, # english punctuation marks
5: 0, # 数字
6: 0, # 行数
7: 0, # 中文字数占总字符数的比例?
} # 效仿word的字符统计,因中文文章中空格较少,故不统计空格?
path = input('please input the path of your file: ')
print(os.path.isfile(path))
if not os.path.isfile(path):
path = r'C:\Users\QQ\Desktop\ls\py\我的微信连三界 狼烟新书\我的微信连三界 狼烟新书.txt' # 设置默认词?
rootpath = r'C:\Users\QQ\Desktop\ls\py\我的微信连三界 狼烟新书'
print(rootpath)
else:
rootpath = os.path.dirname(path)
print(rootpath)
def wdwxlsj():
#path = rootpath + r'\我的微信连三界 狼烟新书.txt'
sl = ['林海', '凡间', '地仙', '地府', '天仙', '散仙', '金仙', '天劫', '馨月', '林儿',
'脸皮', '不好意思', '齐天大圣', '微信', '手机' 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 552
552

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









