










相信大家对于ELK并不陌生吧,大家在工作中一定都接触过Elasticsearch这个搜索引擎,ELK技术栈就是Elasticsearch和Logstash以及Kibana三个组件共同组成的,但是随着后来又有新组件Beats的加入,于是就形成了Elastic Stack。因此作为一个优秀的程序开发者,我们现在在和别人聊技术的时候不应该再说ELK了(过时了),而是称之为Elastic Stack。关于两者的区别,如下图所示:

好了,今天就给大家介绍一下第一个组件Elasticsearch的环境搭建以及他的基础的语法。首先我们准备好一台干净的虚拟机。
由于Elasticsearch是基于Java语言开发的一个搜索引擎,因此再运行的时候需要依赖Java的环境,因此我们首先需要安装Java的环境再来搭建Elasticsearch的环境。接下来我们开始实操。
首先准备好安装包,如下图所示:

同时我们创建一个目录es,作为es的安装目录。这里说明一下我的操作系统版本信息如下所示:

首先解压jdk的安装包,可以根据自己的习惯选择解压路径,这里我习惯放在/usr/local/java/下。接着需要修改一下etc目录下的profile文件,再文件的最下面加上以下内容:
#####JAVA_HOMR
export JAVA_HOME=/usr/local/java/jdk1.8.0_144
export PATH=$PATH:$JAVA_HOME/bin
这里说明以下哈,JAVA_HOME的值就是自己jdk解压的路径。下面我们再继续使用source 命令重新加载profile文件,是我们刚才修改的配置生效。然后我们在终端输入java -version命令。查看Java环境是否安装成功。
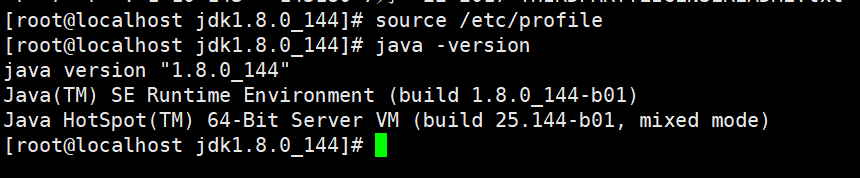
出现了上图的信息 就说明Java环境已经OK了。接下来我们来安装es, 首先解压安装包到es目录下,
解压之后我们来到config目录下,修改elasticsearch.yml文件 
这里给大家说明一下这个文件中的配置信息的含义:

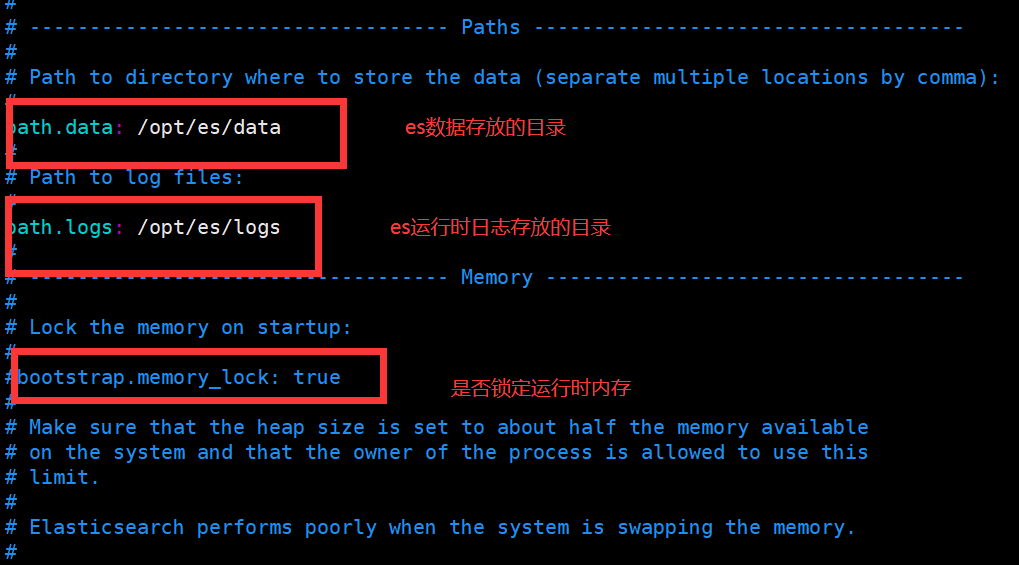

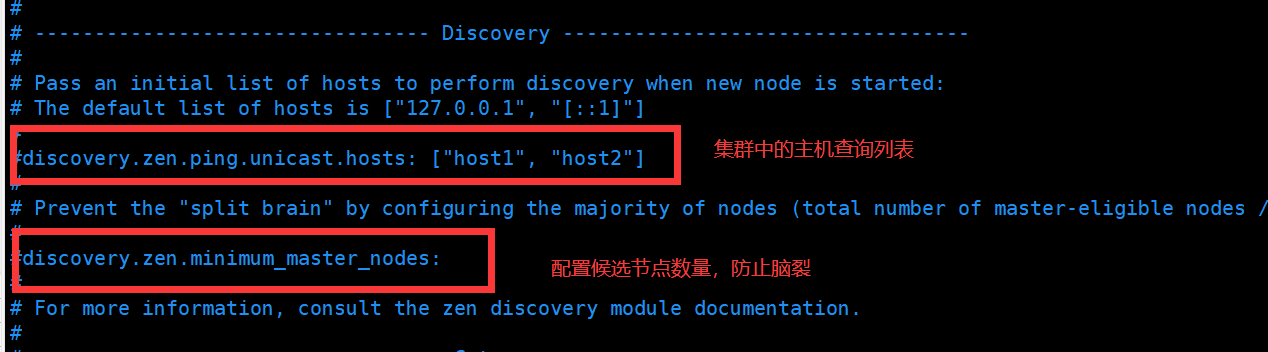
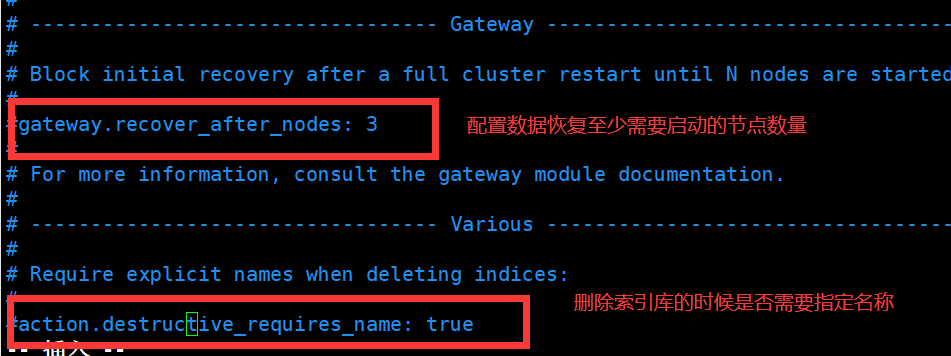
好了,关于每个配信的属性具体的用法后续将会给大家详细的解释,这里我们只需要配置es的日志路径和存放数据的路径,同时我们为了后续的测试方便,因此将network.host设置成0.0.0.0,含义是任何ip都可以访问。后续会为大家介绍这个配置的具体用法。配置完成之后我们还需要修改jvm.options这个配置文件,将默认的内存设置成256M,这里不修改也可以,主要是我自己的虚拟机只配了2G的内存,如果是生产使用的话可以根据服务器的配置来决定。这里给大家一个建议,我们在修改配置文件的时候,一般最好先备份文件,即复制一份,文件名加上日期后缀,再进行修改。好了,修该完成之后我们再es路径下新建logs和data目录,用来存放日志和数据。
接下来就可以启动服务了,我们直接执行bin目录下的elasticsearch脚本就可以了
启动之后我们会发现,程序报错了,错误信息如下所示:

再控制台上打印出来一句 java.lang.RuntimeException: can not run elasticsearch as root。意思是es不允许使用root用户来启动,好吧,接下来我们来创建一个普通用户es,并将es目录权限分配给es用户
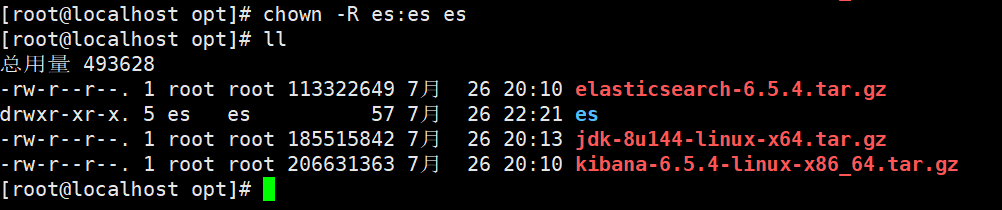
好了,接着我们使用es用户来启动服务。 好吧,我们有发现新的问题了,如下图所示:

我们可以发现有两个错误,max file descriptors [4096] for elasticsearch process is too low, increase to at least [65536]和 max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144] 。也就是说elasticsearch进程的最大文件描述符太低,请至少增加到设置成65536第二个错误是最大虚拟内存区域vm.max_map_计数最少要设置成262144。emmmm...,说白了就是说es嫌弃我的服务器环境太low了,他拒绝启动。好吧,我们接下来使用root用户修改上述的配置。首先在etc下的sysctl.conf文件中新增一行,设置vm.max_map_count。然后
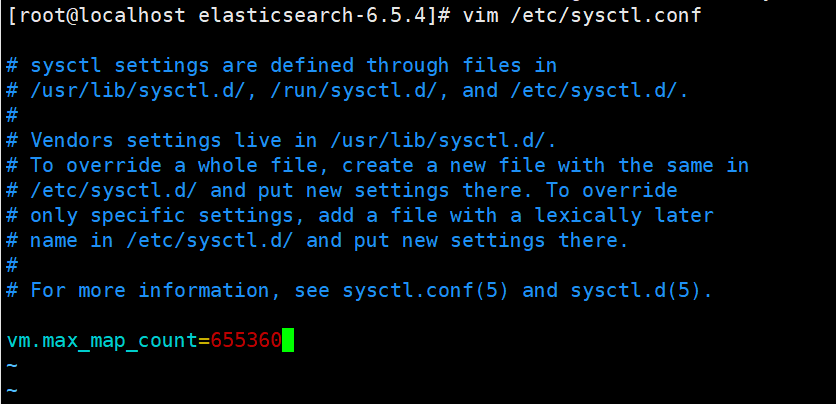
修改完成之后我们需要使用sysctl.conf文件生效

好了,我们再次登录es用户,启动服务就是正常的了,

好了,这种启动方式会占用一个终端,我们接下加上一个-d的参数,可以进行后台启动。启动之后我们使用jps命令来查看es的进程号,

接着我们在logs目录中查看日志来判断服务是否启动的过程是否有报错。 
好了,接下来我们打开浏览器,访问http://192.168.137.93:9200/

这个时候,我们的单机版的es环境搭建完毕!接下来我们来安装kibana。我们将kibana解压,
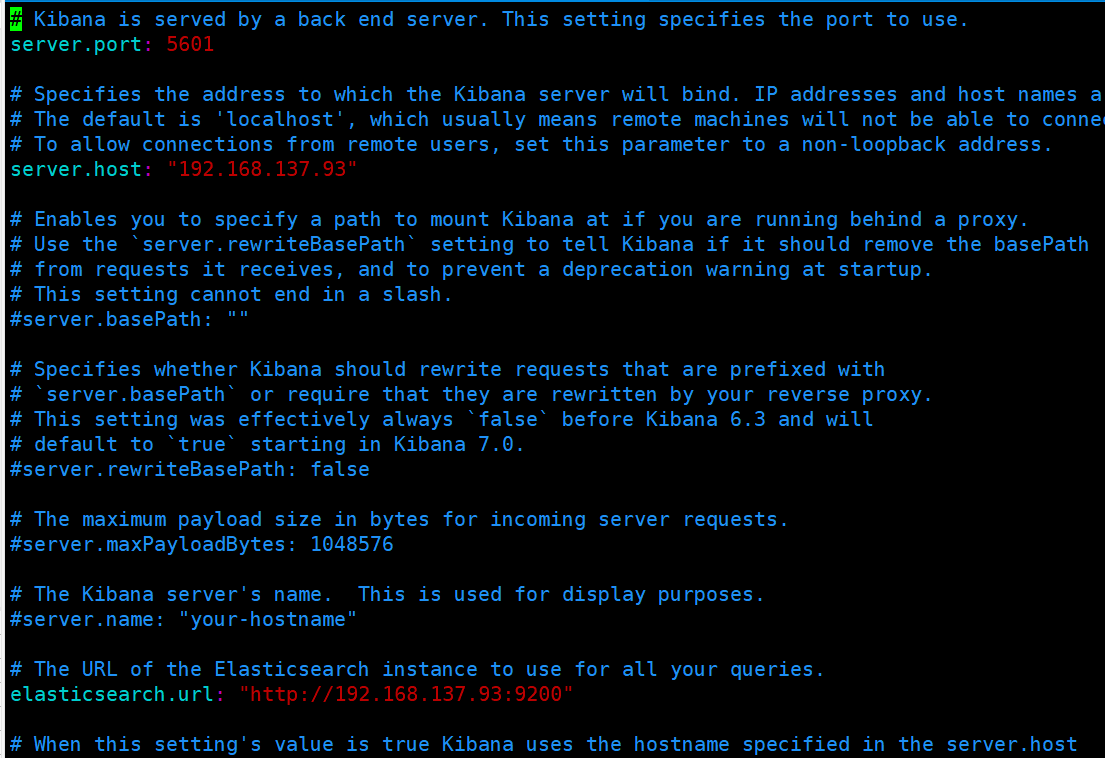
我们需要修改config目录下的配置文件,指定kibana的端口和es的服务url,如下图所示:
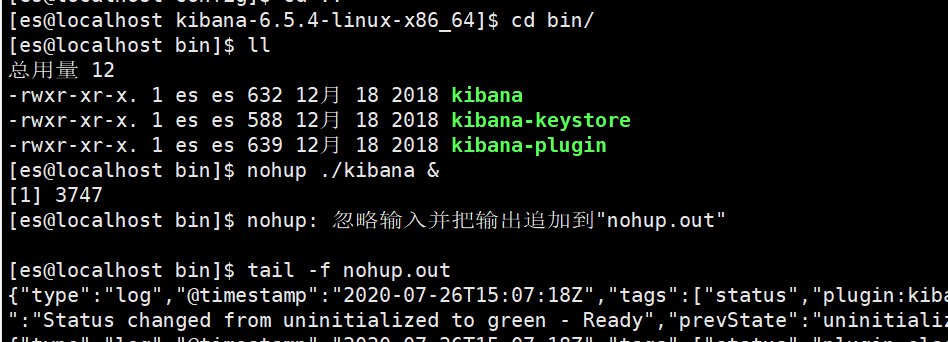
配置完成之后我们就可以启动kibana服务了。我们使用nohup来进程后台启动
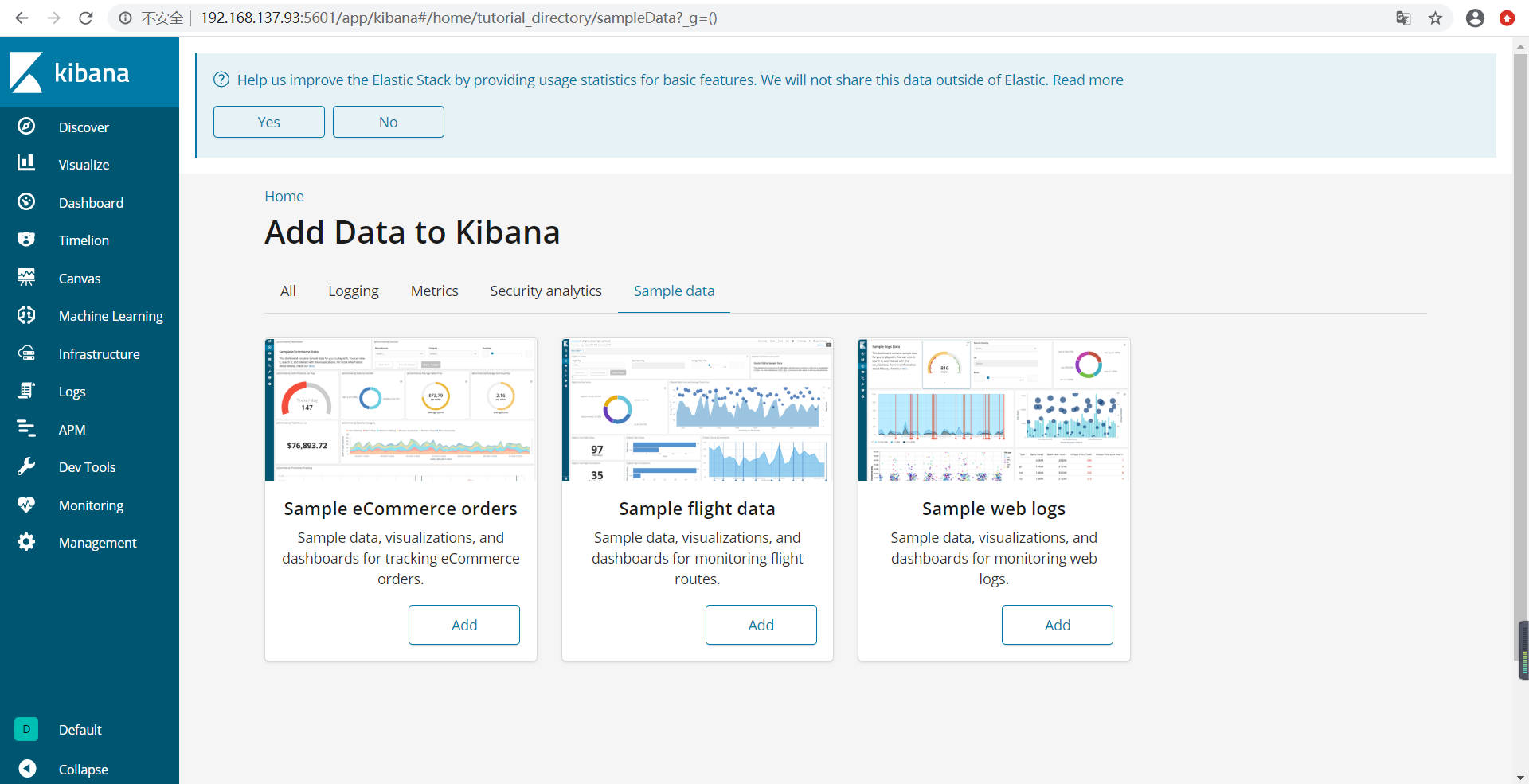
启动成功之后我们打开浏览器,访问http://192.168.137.93:5601/即可。
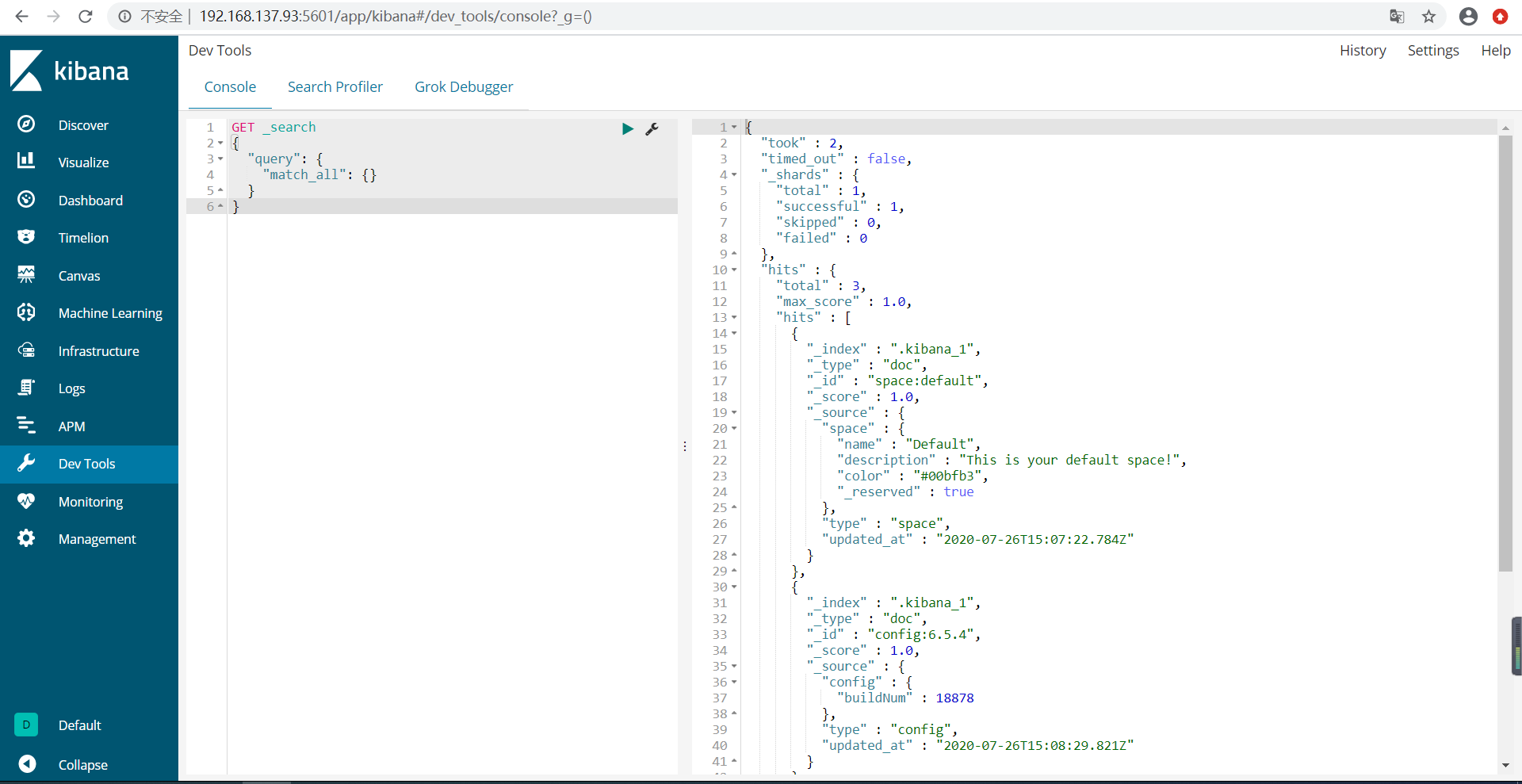
这里我们选择Dev-tools,进入控制台:
好了,我们操作es的客户端也安装好了,下面我们就来准备学习es的基础知识了。
首先,我们来聊一下es的一些基本的概念,首先是索引(index)。所谓的索引库我的理解就是存放一些数据的集合,相当于关系型数据库的一个实例,例如mysql中的一个数据库。接着是type,在es中,type就是索引库中的具有一些具有共同特征的文档的集合,而文档就是es中的一条记录,存放json格式的数据,也可以理解成es中存储的一个对象,文档是es里最小的数据单元。需要注意的是在6.0的版本之每个索引中只能还有一个type,因此可以使用_doc来代替。最后,还有一个比较重要的概念就是映射,数据如何存放到索引对象上,需要有一个映射配置,包括:数据类型、是否存储、是否分词等。而Mapping就是用来定义文档中每个字段的类型。好了,这里先给大家简单的介绍一下,后续会和结合案例和大家深入的探讨相关的概念。接下来我们在kibana 中使用PUT创建一个index

接着使用GET命令来查看索引
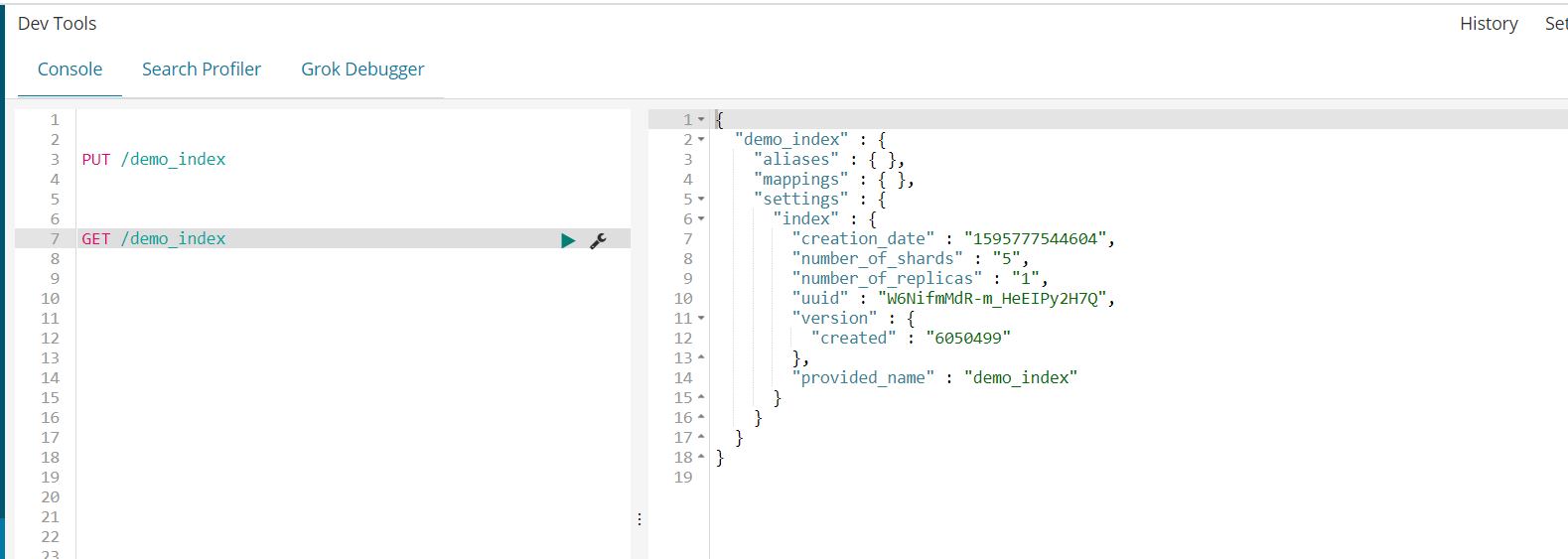 解释一下左侧的内容,其中 index里面的number_of_shards表示的是分片数量number_of_replicas表示每个分片的副本数量,然后就是这个索引的uuid以及版本标识。
解释一下左侧的内容,其中 index里面的number_of_shards表示的是分片数量number_of_replicas表示每个分片的副本数量,然后就是这个索引的uuid以及版本标识。
接着我们可以使用DELETE来删除这个索引。
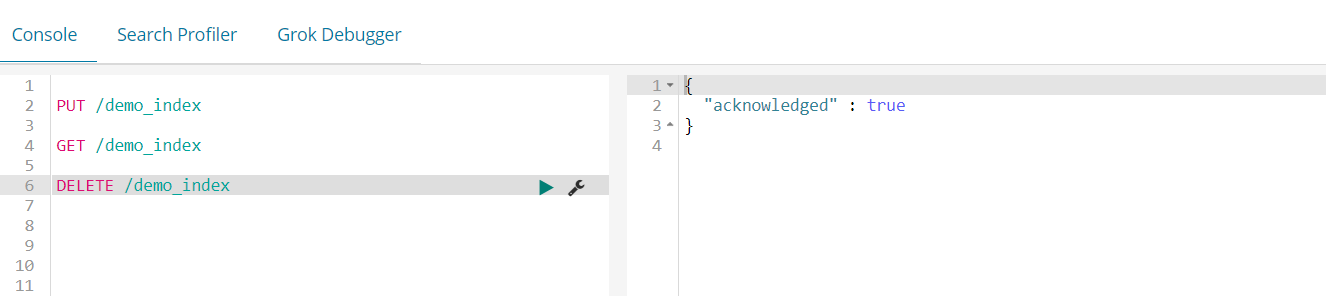
好了,接下来,我们再来创建索引,这次我们需要初始化一些信息,例如设置分片数量和每个分片的副本数量

我们创建索引的时候还可以设置一些参数信息。接着我们在user_index中添加文档信息。
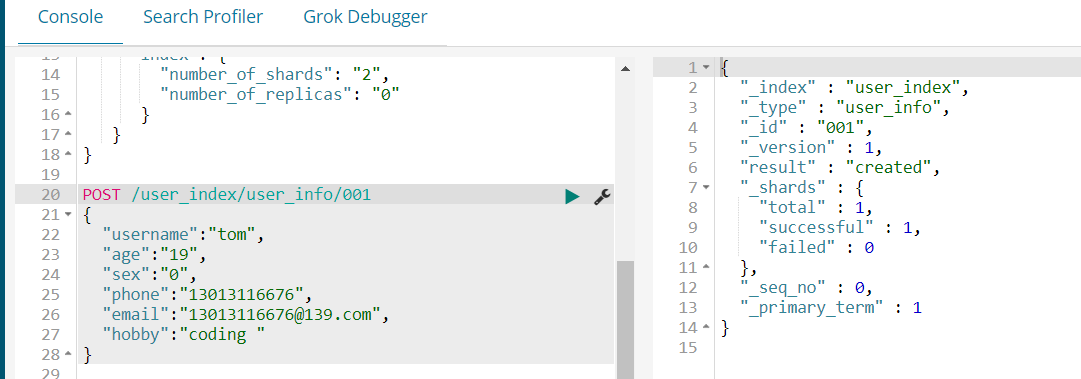
这里我们向索引库中添加了一条数据。我们使用GET 可以查询 :
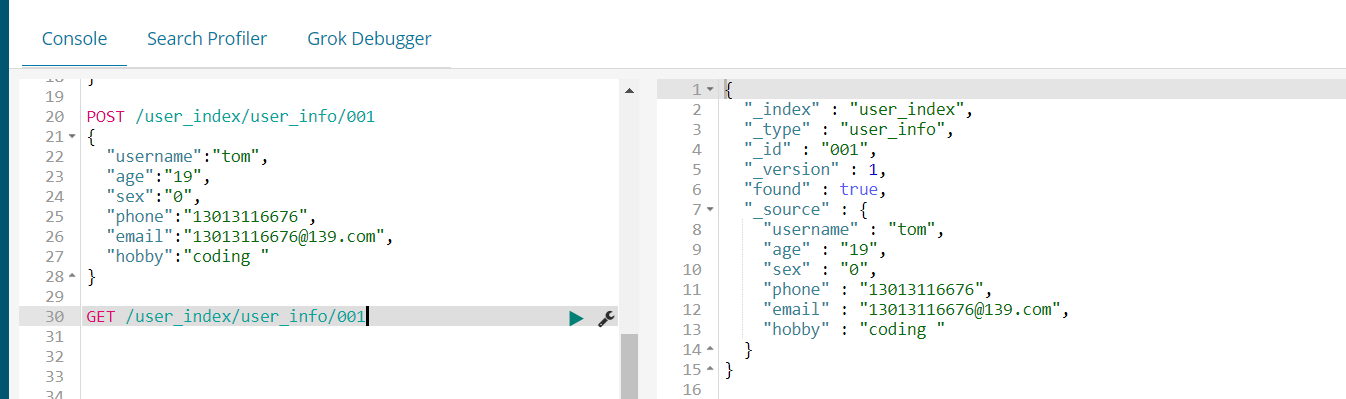
如果我们想要修改其中的属性可以将修改后的再次塞进去,例如,我们将年龄改成20后再次的插入result的值是updated,如下图所示:
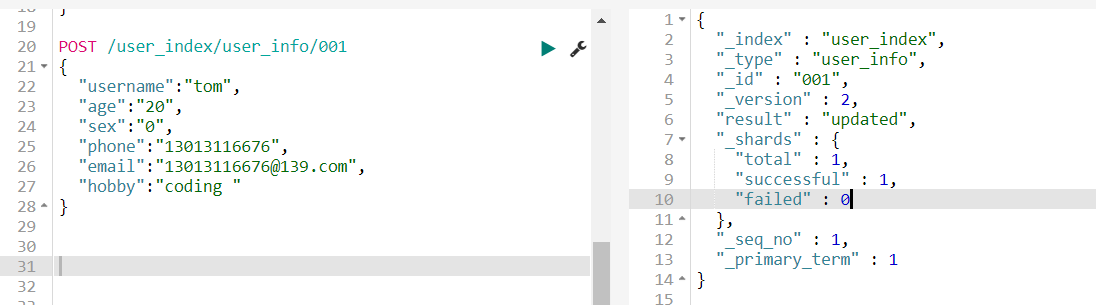
或者我们使用第二种方式进行修改,如下图所示:

我们继续查询,发现也可以修改:

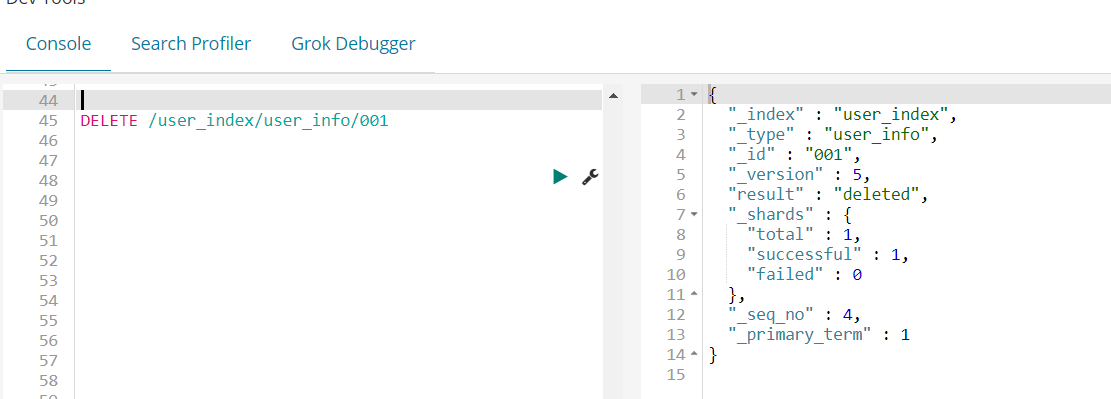
好了,最后我们可以使用DELETE指令将这条数据删除,
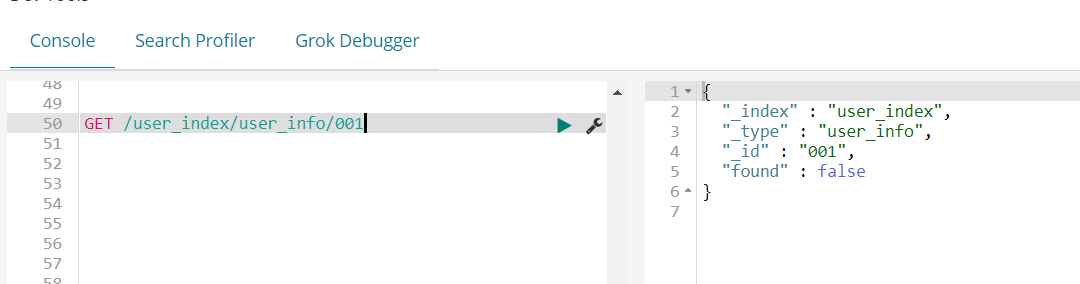
好了,以上就是es中简单的增删查改。今天就先给大家介绍这么多了。















 1175
1175











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









