







名称空间级资源
名称空间在kubernetes中主要的作用是做资源隔离,因此名称空间级别的资源只在当前名称空间下有效。
工作负载型资源
工作负载(workload)是在Kubernetes上运行的应用程序,无论负载是单一组件还是由多个一同工作的组件构成,工作负载都可以在一组Pods中运行。
Pod
Pod是Kubernetes中可以创建和管理的最小可部署计算单元。Pod中包含了一组(一个或多个)容器,这些容器不仅指Docker,实现了CRI的容器都可以作为kubernetes的运行时,如containerd等。从Docker出发来说,Pod类似于共享名称空间(Namespace)和文件系统卷(Volume)的一组Docker容器。
说明:Pod天生地为其成员容器提供了两种共享资源:网络和存储
- 网络
Pod中的每个容器共享网络资源,包括IP地址和网络端口,每个Pod在每个地址族中拥有唯一的IP地址,没有特殊配置就不能使用IPC进行通信。Pod内的容器可以使用localhost互相通信,当Pod中的容器与Pod之外的实体通信时,可以通过IP联网的方式实现,但是需要协调如何使用共享的网络资源(例如端口),Pod中的容器所看到的系统主机名与为Pod配置的name属性值相同。
- 存储
一个Pod可以设置一组共享的存储卷(Volume)。Pod中的所有容器都可以访问该共享卷,从而允许这些容器共享数据。卷还允许Pod中的持久数据保留下来,即使其中的容器需要重新启动。
如何使用
在kubernetes中通常不会直接创建Pod,一般使用诸如Deployment或Job这类工作负载资源来创建Pod,这些Pod都是无状态的。如果Pod需要跟踪状态,可以使用StatefulSet资源来创建。Kubernetes集群中的Pod主要有两种用法:
- 运行单个容器的Pod:"每个Pod一个容器"模型是最常见的Kubernetes用例,这种情况下,可以将Pod看作单个容器的包装器,并且Kubernetes直接管理Pod,而不是容器。
- 运行多个协同工作的容器的Pod:Pod可能封装由多个紧密耦合且需要共享资源的共处容器组成的应用程序。这些位于同一位置的容器形成单个内聚的服务单元,Pod将这些容器和存储资源打包为一个可管理的实体。
说明:将多个并置、同管的容器组织到一个Pod中是一种相对高级的使用场景,只有在一些场景中,容器之间紧密关联时你才应该使用这种模式。
Pod被设计成支持形成内聚服务单元的多个协作过程(形式为容器)。Pod中的容器被自动安排到集群中的同一物理机或虚拟机上,并可以一起进行调度。容器之间可以共享资源和依赖、彼此通信、协调何时以及何种方式终止自身。
例如,在一个Pod中包含两个容器,一个容器,为共享卷中的文件提供Web服务器支持,另一个单独的容器负责从远端更新这些文件,如下图所示:
生命周期
Pod遵循预定义的生命周期,起始于Pending阶段,如果至少其中有一个主要容器正常启动,则进入Running,之后取决于Pod中是否有容器以失败状态结束而进入Succeeded或者Failed阶段。
- 概述
Pod生命周期中只会被调度一次,和容器一样,Pod也被认为是相对临时性(而不是长期存在)的实体,Pod会被创建、赋予一个唯一的ID(UID),一旦Pod被调度(分派)到某个节点,Pod会一直在该节点运行,直到Pod停止或者被终止。任何给定的Pod(由UID定义)从不会被重新调度(rescheduled)到不同的节点,如有必要,这一Pod可以被一个新的、几乎完全相同的Pod替换掉,新Pod的名字可以不变,但是其UID会不同。如果存储卷生命期与某Pod相同,这就意味着该对象在此Pod(UID亦相同)存在期间也一直存在。如果Pod因为任何原因被删除,甚至某完全相同的替代Pod被创建时,这个相关的对象(例如这里的卷)也会被删除并重建。
Pod自身不具有自愈能力,如果Pod被调度到某节点(Node)而该节点之后失效,调度到该节点的Pod也会在给定的超时期限结束后删除。同时,Pod无法在因节点资源耗尽或者节点维护而被驱逐期间继续存活。kubernetes使用一种高级抽象(控制器)来管理这些相对而言可随时丢弃的Pod实例。
- Pod阶段
Pod的status字段是一个PodStatus对象,其中包含一个phase字段。Pod的阶段(Phase)是Pod在其生命周期中所处位置的简单宏观概述,该阶段并不是对容器或Pod状态的综合汇总。Pod阶段的数量和含义是严格定义的,下面是phase可能的值:
| 取值 | 描述 |
|---|---|
| Pending | Pod已被Kubernetes系统接受,但有一个或者多个容器尚未创建亦未运行。此阶段包括等待Pod被调度的时间和通过网络下载镜像的时间。 |
| Running | Pod已经绑定到了某个节点,Pod中所有的容器都已被创建。至少有一个容器仍在运行,或者正处于启动或重启状态。 |
| Succeeded | Pod中的所有容器都已成功终止,并且不会再重启。 |
| Failed | Pod中的所有容器都已终止,并且至少有一个容器是因为失败终止。也就是说,容器以非0状态退出或者被系统终止。 |
| Unknown | 因为某些原因无法取得Pod的状态。这种情况通常是因为与Pod所在主机通信失败。 |
- Pod内容器状态
kubernetes还会跟踪Pod中每个容器的状态,就像它跟踪Pod总体上的阶段一样,可以使用容器生命周期回调在容器生命周期中的特定时间点触发事件。一旦调度器将Pod分派给某个节点,kubelet就通过容器运行时开始为Pod创建容器。容器状态有三种:Waiting(等待)、Running(运行中)、Terminated(终止)。可以使用命令检查Pod中容器的状态。
[root@master ~]# kubectl describe pod docker-learn-server-7597c4ddf6-jnfpr
# 输出结果
Name: docker-learn-server-7597c4ddf6-jnfpr
Namespace: default
Priority: 0
Node: node1/10.0.4.5
Start Time: Fri, 01 Apr 2022 01:14:07 +0800
Labels: k8s.kuboard.cn/layer=svc
k8s.kuboard.cn/name=docker-learn-server
pod-template-hash=7597c4ddf6
Annotations: cni.projectcalico.org/containerID: 332efea7ce7d4d93d9dd5b1b265a921197c2f66a09dfe30ce8526aaf2111430e
cni.projectcalico.org/podIP: 10.234.168.26/32
cni.projectcalico.org/podIPs: 10.234.168.26/32
Status: Running
IP: 10.234.168.26
IPs:
IP: 10.234.168.26
Controlled By: ReplicaSet/docker-learn-server-7597c4ddf6
Containers:
docker-learn-server:
Container ID: containerd://ff4d17115f8b2c02db6a485ecda67c74fc91cb3fc73cc62c1e7ab92dc288a500
Image: ccr.ccs.tencentyun.com/dockerpracticesig/docker_practice:vuepress
Image ID: ccr.ccs.tencentyun.com/dockerpracticesig/docker_practice@sha256:2d74d38991a79c96c14782502e3b7aeb2dacab1a2c2f61ab6974160178466472
Port: 80/TCP
Host Port: 0/TCP
State: Running
Started: Fri, 01 Apr 2022 01:14:08 +0800
Ready: True
Restart Count: 0
Environment: <none>
Mounts:
/var/run/secrets/kubernetes.io/serviceaccount from kube-api-access-mzmw5 (ro)
Conditions:
Type Status
Initialized True
Ready True
ContainersReady True
PodScheduled True
Volumes:
kube-api-access-mzmw5:
Type: Projected (a volume that contains injected data from multiple sources)
TokenExpirationSeconds: 3607
ConfigMapName: kube-root-ca.crt
ConfigMapOptional: <nil>
DownwardAPI: true
QoS Class: BestEffort
Node-Selectors: <none>
Tolerations: node.kubernetes.io/not-ready:NoExecute op=Exists for 300s
node.kubernetes.io/unreachable:NoExecute op=Exists for 300s
Events: <none>输出了Pod的详细声明式信息,其输出中包含Pod中每个容器的状态。每种状态都有特定的含义:
- Waiting
如果容器不处在Running或Terminated状态之一,它就处在Waiting状态,处于Waiting状态的容器仍在运行它完成启动所需要的操作。例如,从某个容器镜像仓库拉取容器镜像,或者向容器应用Secret数据等。使用kubectl来查询包含Waiting状态的容器的Pod时,会看到一个Reason字段,其中给出了容器处于等待状态的原因。
- Running
Running状态表明容器正在执行状态并且没有问题发生。如果配置了postStart回调,那么该回调已经执行且已完成。如果使用kubectl来查询包含Running状态的容器的Pod时,会看到关于容器进入Running状态的信息。
- Terminated
处于Terminated状态的容器已经开始执行并且或者正常结束或者因为某些原因失败。如果使用kubectl来查询包含Terminated状态的容器的Pod时,会看到容器进入此状态的原因、退出代码以及容器执行期间的起止时间。如果容器配置了preStop回调,则该回调会在容器进入Terminated状态之前执行。
- Pod重启策略
Pod的spec中包含一个restartPolicy字段,其可能取值包括Always、OnFailure和Never。默认值是Always。该策略适用于Pod中的所有容器。restartPolicy仅针对同一节点上kubelet的容器重启动作。当Pod中的容器退出时,kubelet会按指数回退方式计算重启的延迟(10s、20s、40s、...),其最长延迟为5分钟。一旦某容器执行了10分钟并且没有出现问题,kubelet对该容器的重启回退计时器执行重置操作。
- Pod状况
Pod有一个PodStatus对象,其中包含一个PodConditions数组。Pod可能通过也可能未通过其中的一些状况测试。主要包含以下几种状态
- PodScheduled:Pod已经被调度到某节点
- ContainersReady:Pod中所有容器都已就绪
- Initialized:所有的Init容器都已成功完成
- Ready:Pod可以为请求提供服务,并且应该被添加到对应服务的负载均衡池中
对象中包含的属性信息如下表所示:
| 字段名称 | 描述 |
|---|---|
| type | Pod状况的名称 |
| status | 表明该状况是否适用,可能的取值有"True","False"或"Unknown" |
| lastProbeTime | 上次探测Pod状况时的时间戳 |
| lastTransitionTime | Pod上次从一种状态转换到另一种状态时的时间戳 |
| reason | 机器可读的、驼峰编码(UpperCamelCase)的文字,表述上次状况变化的原因 |
| message | 人类可读的消息,给出上次状态转换的详细信息 |
kubernetes在v1.14 stable后引入就绪态概念。应用可以向PodStatus中注入额外的反馈信号:PodReadiness(Pod就绪态)。要使用这一特性,可以设置Pod规约中的readinessGates列表,为kubelet提供一组额外的状况供其评估Pod就绪态时使用。
就绪态基于Pod的status.conditions字段的当前值来做决定。如果Kubernetes无法在status.conditions字段中找到某状况,则该状况的状态值默认为"False"。
kind: Pod
...
spec:
readinessGates:
- conditionType: "www.example.com/feature-1"
status:
conditions:
- type: Ready # 内置的 Pod 状况
status: "False"
lastProbeTime: null
lastTransitionTime: 2018-01-01T00:00:00Z
- type: "www.example.com/feature-1" # 额外的 Pod 状况
status: "False"
lastProbeTime: null
lastTransitionTime: 2018-01-01T00:00:00Z
containerStatuses:
- containerID: docker://abcd...
ready: true
...命令kubectl patch不支持修改对象的状态。如果需要设置Pod的status.conditions,应用或者Operators需要使用PATCH操作。可以使用Kubernetes客户端库之一来编写代码,针对Pod就绪态设置定制的Pod状况。对于使用定制状况的Pod而言,只有当下面的陈述都适用时,该Pod才会被评估为就绪:
- Pod中所有容器都已就绪;
- readinessGates中的所有状况都为True值。
当Pod容器已就绪,但至少一个定制状况没有取值或值为False,kubelet将Pod的状况设置为ContainersReady。
Pause容器
Pause容器,也被称为infra容器,用作Pod中所有容器的父容器,Pod是Kubernetes设计的精髓,而pause容器则是Pod网络模型的精髓。
在Pod的生命周期中,创建Pod时Kubelet先调用CRI接口RuntimeService.RunPodSandbox来创建一个沙箱环境,为Pod设置网络(例如:分配 IP)等基础运行环境。当Pod沙箱(Pod Sandbox,Pod 这种在统一隔离环境里资源受限的一组容器)建立起来后,Kubelet 就可以在里面创建用户容器。当到删除 Pod 时,Kubelet 会先移除 Pod Sandbox 然后再停止里面的所有容器。
Kubernetes的Pod抽象基于Linux的namespace和cgroups,为一组容器共同提供了隔离的运行环境。从网络的角度看,同一个Pod 中的不同容器犹如在运行在同一个专有主机上,可以通过 localhost 进行通信。原则上,任何人都可以配置Docker来控制容器组之间的共享级别,只需创建一个父容器,并创建与父容器共享资源的新容器,然后管理这些容器的生命周期。在Kubernetes中,pause容器被当作Pod中所有容器的父容器并为每个业务容器提供以下功能:
- 在Pod中它作为共享Linux Namespace(Network、UTS 等)的基础
- 启用PID Namespace共享,它为每个Pod提供1号进程,并收集Pod内的僵尸进程

Init容器
有些Pod中具有Init容器,Init容器是一种特殊容器,Init容器会在启动应用容器之前运行并完成。Init容器可以包括一些应用镜像中不存在的实用工具和安装脚本。Init容器与普通的容器非常相似,与应用容器相比有两点不同:
- Init容器总是运行到完成为止。
- 每个Init容器都必须在下一个Init容器启动之前成功完成(串行)。
Pod规约中添加initContainers字段设置Init容器,该字段为Container类型对象数组形式,和应用的containers数组同级。Init容器的状态在status.initContainerStatuses字段中为容器状态数组(类似status.containerStatuses字段)。因为Init容器具有与应用容器分离的单独镜像,其启动相关代码具有如下优势:
- Init容器可以包含一些安装过程中应用容器中不存在的实用工具或个性化代码。例:没有必要仅为了在安装过程中使用类似sed、awk、python或dig这样的工具而去FROM一个镜像来生成一个新的镜像
- Init容器可以安全地运行这些工具,避免这些工具导致应用镜像的安全性降低
- 应用镜像的创建者和部署者可以各自独立工作,而没有必要联合构建一个单独的应用镜像
- Init容器能以不同于Pod内应用容器的文件系统视图运行。因此,Init容器可以访问应用容器不能访问的Secret的权限
- 由于Init容器必须在应用容器启动之前运行完成,因此Init容器提供了一种机制来阻塞或延迟应用容器的启动,直到满足了一组先决条件。一旦前置条件满足,Pod内的所有的应用容器会并行启动
Pod重启会导致Init容器重新执行,主要有如下几个原因:
- Pod的基础设施容器(如pause容器)被重启。这种情况不多见,必须由具备root权限访问节点的人员来完成。
- 当restartPolicy设置为"Always",Pod中所有容器会终止而强制重启。由于垃圾收集机制的原因,Init容器的完成记录将会丢失。
如果Pod的Init容器启动失败,kubelet会不断地重启该Init容器直到该容器成功为止。如果Pod对应的restartPolicy值为"Never",并且Pod的Init容器失败,则Kubernetes会将整个Pod状态设置为失败。
当Init容器的镜像发生改变或者Init容器的完成记录因为垃圾收集等原因被丢失时,Pod不会被重启。这一行为适用于Kubernetesv1.20及更新版本。
Pod的终止
Pod所代表的是集群在节点上运行的进程,当不再需要这些进程时,一般不应武断地使用KILL信号终止,会导致这些进程没有机会完成清理操作。
当请求删除某个Pod时,设计的目标是不仅能够删除进程,并且知道进程何时被终止,同时也能够确保删除操作终将完成。集群会记录并跟踪Pod的终止周期,而不是直接强制杀死Pod,在存在强制关闭设施前提下, kubelet会尝试体面地终止Pod。
- 正常终止流程
通常情况下,容器运行时会发送一个TERM信号到每个容器中的主进程,很多容器运行时都能够注意到容器镜像中STOPSIGNAL的值,并发送该信号而不是TERM,一旦超出了体面终止限期,容器运行时会向所有剩余进程发送KILL信号,之后 Pod 就会被从apiserver上移除。如果kubelet或者容器运行时的管理服务在等待进程终止期间被重启, 集群会从头开始重试,赋予Pod完整的体面终止限期。
下面是一个终止流程的例子:
- 使用kubectl工具手动删除某个特定的Pod,而该Pod的体面终止限期是默认值(30 秒)。
- apiserver中的Pod对象被更新,记录涵盖体面终止限期在内Pod的最终死期,超出所计算时间点则认为Pod 已死(dead)。 如果你使用kubectl describe来查验你正在删除的Pod,该Pod会显示为"Terminating"(正在终止)。 在Pod运行所在的节点上,kubelet一旦看到Pod被标记为正在终止(已经设置了体面终止限期),kubelet即开始本地的Pod关闭过程。
- 如果Pod中的容器之一定义了preStop回调, kubelet开始在容器内运行回调逻辑。如果超出体面终止限期时,preStop回调逻辑仍在运行,kubelet会请求给予该Pod的宽限期一次性增加2秒钟。如果 preStop回调所需要的时间长于默认的体面终止限期,你必须修改terminationGracePeriodSeconds属性值来使其正常工作。
- kubelet接下来触发容器运行时发送TERM信号给每个容器中的进程 。Pod中的容器会在不同时刻收到 TERM信号,接收顺序也是不确定的, 如果关闭的顺序很重要,可以考虑使用preStop回调逻辑来协调。
- 与此同时,kubelet启动体面关闭逻辑,控制面会将Pod从对应的端点列表(以及端点切片列表, 如果启用了的话)中移除,过滤条件是Pod被对应的服务以某选择算符选定。 ReplicaSets和其他工作负载资源不再将关闭进程中的Pod视为合法的、能够提供服务的副本。关闭动作很慢的Pod也无法继续处理请求数据,因为负载均衡器(例如服务代理)已经在终止宽限期开始的时候将其从端点列表中移除。
- 超出终止宽限期限时,kubelet会触发强制关闭过程。容器运行时会向Pod中所有容器内仍在运行的进程发送 SIGKILL信号,如果容器运行时使用了pause容器,kubelet也会清理隐藏的pause容器。
- kubelet触发强制从API服务器上删除Pod对象的逻辑,并将体面终止限期设置为0(这意味着马上删除)。
- apiserver删除Pod的API对象,从任何客户端都无法再看到该对象。
- **强制终止Pod **
对于某些工作负载及其Pod而言,强制删除很可能会带来某种破坏。默认情况下,所有的删除操作都会附有30秒钟的宽限期限。 kubectl delete命令支持--grace-period=
选项,允许你重载默认值, 设定自己希望的期限值。将宽限期限强制设置为0意味着立即从apiserver删除Pod。 如果Pod 仍然运行于某节点上,强制删除操作会触发kubelet立即执行清理操作。必须在设置 --grace-period=0 的同时额外设置 --force 参数才能发起强制删除请求。
执行强制删除操作时,apiserver不再等待来自kubelet的关于Pod已经在原来运行的节点上终止执行的确认消息。 apiserver直接删除Pod对象,这样新的与之同名的Pod即可以被创建。 在节点侧,被设置为立即终止的 Pod仍然会在被强行杀死之前获得一点点的宽限时间。
- **失效Pod的垃圾收集 **
对于已失败的Pod而言,对应的API对象仍然会保留在集群的apiserver上,直到用户或者控制器进程显式地将其删除。
控制面组件会在 Pod 个数超出所配置的阈值 (根据 kube-controller-manager 的 terminated-pod-gc-threshold 设置)时 删除已终止的 Pod(阶段值为 Succeeded 或 Failed)。 这一行为会避免随着时间演进不断创建和终止 Pod 而引起的资源泄露问题。
容器探针
探针(probe)是由kubelet对容器执行的定期诊断。要执行诊断,kubelet既可以在容器内执行代码,也可以发出一个网络请求,下面从几个方面来说明容器探针。
- 检查机制
使用探针来检查容器有四种不同的方法。每个探针都必须准确定义为这四种机制中的一种:
- exec
在容器内执行指定命令。如果命令退出时返回码为0则认为诊断成功。
- grpc
使用gRPC执行一个远程过程调用,目标应该实现gRPC健康检查。如果响应的状态是"SERVING",则认为诊断成功。gRPC探针是一个alpha特性,只有在你启用了"GRPCContainerProbe"特性门控时才能使用。
- httpGet
对容器的IP地址上指定端口和路径执行HTTPGET请求。如果响应的状态码大于等于200且小于400,则诊断被认为是成功的。
- tcpSocket
对容器的IP地址上的指定端口执行TCP检查。如果端口打开,则诊断被认为是成功的。如果远程系统(容器)在打开连接后立即将其关闭,这算作是健康的。
- 探测结果
每次探测都将获得以下三种结果之一:
- Success(成功)容器通过了诊断。
- Failure(失败)容器未通过诊断。
- Unknown(未知)诊断失败,因此不会采取任何行动。
- 探测类型
针对运行中的容器,kubelet可以选择是否执行以下三种探针,以及如何针对探测结果作出反应:
- livenessProbe
指示容器是否正在运行。如果存活态探测失败,则kubelet会杀死容器,并且容器将根据其重启策略决定未来。如果容器不提供存活探针,则默认状态为Success。
- readinessProbe
指示容器是否准备好为请求提供服务。如果就绪态探测失败,端点控制器将从与Pod匹配的所有服务的端点列表中删除该Pod的IP地址。初始延迟之前的就绪态的状态值默认为Failure。如果容器不提供就绪态探针,则默认状态为Success。
- startupProbe
指示容器中的应用是否已经启动。如果提供了启动探针,则所有其他探针都会被禁用,直到此探针成功为止。如果启动探测失败,kubelet将杀死容器,而容器依其重启策略进行重启。如果容器没有提供启动探测,则默认状态为Success。
- 探针类型
容器探针按照不同探测维度可以划分为存活态、就绪态、启动探针几种,每种有各自的使用场景,下面进行简单介绍:
- 何时该使用存活态探针,特性状态:Kubernetesv1.0[stable]
如果容器中的进程能够在遇到问题或不健康的情况下自行崩溃,则不一定需要存活态探针,kubelet将根据Pod的restartPolicy自动执行修复操作。如果希望容器在探测失败时被杀死并重新启动,那么需要指定一个存活态探针,并指定restartPolicy为"Always"或"OnFailure"。
- 何时该使用就绪态探针,特性状态:Kubernetesv1.0[stable]
如果要仅在探测成功时才开始向Pod发送请求流量,需要指定就绪态探针。在这种情况下,就绪态探针可能与存活态探针相同,但是规约中的就绪态探针的存在意味着Pod将在启动阶段不接收任何数据,并且只有在探针探测成功后才开始接收数据。如果希望容器能够自行进入维护状态,也可以指定一个就绪态探针,检查某个特定于就绪态的且不同于存活态探测的端点。
如果应用程序对后端服务有严格的依赖性,可以同时实现存活态和就绪态探针。当应用程序本身是健康的,存活态探针检测通过后,就绪态探针会额外检查每个所需的后端服务是否可用。可以避免将流量导向只能返回错误信息的Pod。
如果容器需要在启动期间加载大型数据、配置文件或执行迁移,你可以使用启动探针。然而,如果想区分已经失败的应用和仍在处理其启动数据的应用,可能更倾向于使用就绪探针。
说明:如果只是想在Pod被删除时能够排空请求,则不一定需要使用就绪态探针;在删除Pod时,Pod会自动将自身置于未就绪状态,无论就绪态探针是否存在。等待Pod中的容器停止期间,Pod会一直处于未就绪状态。
- 何时该使用启动探针,特性状态:Kubernetesv1.18[beta]
对于包含的容器需要较长时间才能启动就绪的Pod而言,启动探针是有用的。不再需要配置一个较长的存活态探测时间间隔,只需要设置另一个独立的配置选定,对启动期间的容器执行探测,从而允许使用远远超出存活态时间间隔所允许的时长。
如果容器启动时间通常超出initialDelaySeconds+failureThreshold×periodSeconds总值,应该设置一个启动探测,对存活态探针所使用的同一端点执行检查。periodSeconds的默认值是10秒,应该将其failureThreshold设置得足够高,以便容器有充足的时间完成启动,并且避免更改存活态探针所使用的默认值。并且这一设置有助于减少死锁状况的发生。
ReplicaSet
ReplicaSet(RS)的目的是维护一组在任何时候都处于运行状态的 Pod 副本的稳定集合。 因此,它通常用来保证给定数量的、完全相同的Pod的可用性。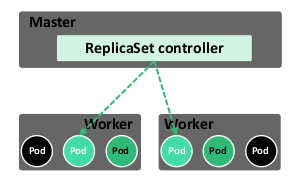
在新版本的Kubernetes中建议使用RS来取代ReplicationController(RC)。ReplicaSet跟RC没有本质的不同,只是名字不一样,但ReplicaSet支持集合式selector。其工作原理如下图所示:
说明:在初始阶段定了一个RS需要维护保证集群中存在12个Pod副本,这三个副本分布在集群的三个节点中,由于某种不可控(如网络中断或者断电)因素,节点(Node)不可用,为了保障维持12个副本,RS会在其余可用节点中创建新的Pod,保障其可用性。
虽然ReplicaSets可以独立使用,但如今它主要被Deployments用作协调Pod的创建、删除和更新的机制。当使用 Deployment时,不必担心还要管理它们创建的ReplicaSet,Deployment会拥有并管理ReplicaSet。
ReplicaSet通过一组字段来定义的,包括一个用来识别可获得的Pod的集合的选择算符、一个用来标明应该维护的副本个数的数值、一个用来指定应该创建新Pod以满足副本个数条件时要使用的Pod模板等。 每个ReplicaSet都通过根据需要创建和删除Pod以使得副本个数达到期望值, 进而实现其存在价值。当ReplicaSet需要创建新的 Pod时,会使用所提供的Pod模板。
Deployment
Deployment是最常用工作负载,是ReplicaSet的更上一层的抽象概念。Deployment提供了Pod和ReplicaSet声明式创建和更新的能力,不要管理Deployment所拥有的ReplicaSet。
- 工作原理示意
Deployment控制器以受控速率更改实际状态,使其变为期望状态。可以定义Deployment以创建新的RS,或删除现有Deployment,并通过新的Deployment收养其资源。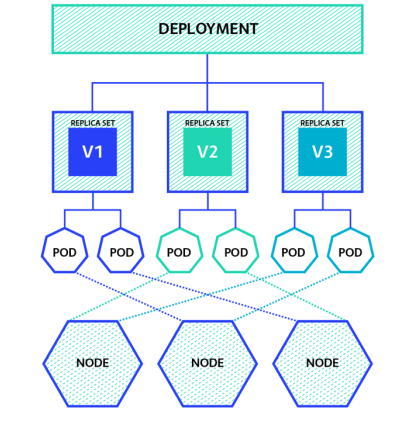
以下是 Deployments 的典型用例:
- 创建 Deployment以将ReplicaSet上线,ReplicaSet在后台创建Pods。检查ReplicaSet的上线状态,查看其是否成功。
- 通过更新Deployment的PodTemplateSpec,声明Pod的新状态。新的ReplicaSet会被创建,Deployment以受控速率将Pod从旧ReplicaSet迁移到新ReplicaSet。每个新的ReplicaSet都会更新Deployment的修订版本。
- 如果Deployment的当前状态不稳定,回滚到较早的Deployment版本。每次回滚都会更新Deployment的修订版本。
- 扩大Deployment规模以承担更多负载。
- 暂停Deployment以应用对PodTemplateSpec所作的多项修改,然后恢复其执行以启动新的上线版本。
- 使用Deployment状态来判定上线过程是否出现停滞。
- 清理较旧的不再需要的ReplicaSet。
使用Deployment进行滚动更新示意:
图片说明:一个节点中定义了四个Pod副本,假定按照预定策略每次进行50%的变更进行滚动更新,升级前版本为V1,升级后版本为v2。
- 第一阶段:创建两个新的Pod,当这两个副本变为Running状态后替换原来副本中的两个;
- 第二阶段:进行剩余副本的创建、替换过程,到此整个Devolopment更新过程完成,实现滚动更新。
在这个过程中不会让用户出现明显的服务中断感知,进行版本的回退,原理同样类似,只不过是创建历史v1版本资源定义的Pod来替换v2版本的Pod。
- 如何使用
下面是一个Deployment示例。其中创建了一个ReplicaSet,负责启动三个nginx Pods:
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
labels:
app: nginx
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.14.2
ports:
- containerPort: 80在该例中:
- 创建名为nginx-deployment(由 .metadata.name 字段标明)的Deployment。
- 该 Deployment 创建三个(由 replicas 字段标明)Pod 副本。
- selector 字段定义 Deployment 如何查找要管理的 Pods。 在这里,你选择在 Pod 模板中定义的标签(app: nginx)。 不过,更复杂的选择规则是也可能的,只要 Pod 模板本身满足所给规则即可。
操作过程中可能用到的命令:
- 创建Development
kubectl apply -f <定义Development资源的yaml文件>- 查看运行情况
kubectl get deployments
# 输出结果
NAME READY UP-TO-DATE AVAILABLE AGE
nginx-deployment 0/3 0 0 1s说明:在检查集群中的Deployment时,所显示的字段有
- NAME列出了集群中Deployment的名称
- READY显示应用程序的可用的“副本”数,显示的模式是“就绪个数/期望个数”
- UP-TO-DATE显示为了达到期望状态已经更新的副本数
- AVAILABLE显示应用可供用户使用的副本数
- AGE显示应用程序运行的时间
请注意期望副本数是根据.spec.replicas字段设置3。
- 查看Deployment创建的RS
kubectl get rs
# 输出结果
NAME DESIRED CURRENT READY AGE
nginx-deployment-75675f5897 3 3 3 18s说明:ReplicaSet输出中包含以下字段,注意ReplicaSet的名称始终被格式化为[Deployment名称]-[随机字符串]。 其中的随机字符串是使用pod-template-hash作为种子随机生成的。
- NAME列出名字空间中ReplicaSet的名称
- DESIRED显示应用的期望副本个数,即在创建 Deployment 时所定义的值,此为期望状态
- CURRENT显示当前运行状态中的副本个数
- READY显示应用中有多少副本可以为用户提供服务
- AGE显示应用已经运行的时间长度
- 查看每个Pod自动生成的标签
kubectl get pods --show-labels
# 输出结果
NAME READY STATUS RESTARTS AGE LABELS
nginx-deployment-75675f5897-7ci7o 1/1 Running 0 18s app=nginx,pod-template-hash=3123191453
nginx-deployment-75675f5897-kzszj 1/1 Running 0 18s app=nginx,pod-template-hash=3123191453
nginx-deployment-75675f5897-qqcnn 1/1 Running 0 18s app=nginx,pod-template-hash=3123191453StatefulSet
StatefulSet是用来管理有状态应用的工作负载 API 对象。StatefulSet用来管理某Pod集合的部署和扩缩, 并为这些Pod提供持久存储和持久标识符。
与Deployment类似,StatefulSet管理基于相同容器规约的一组Pod。但和Deployment不同的是,StatefulSet为它们的每个Pod维护了一个有粘性的ID,这些Pod是基于相同的规约来创建的,但是不能相互替换,无论怎么调度,每个Pod都有一个永久不变的ID。
如果希望使用存储卷为工作负载提供持久存储,可以使用StatefulSet作为解决方案的一部分。 尽管StatefulSet中的单个Pod仍可能出现故障,但持久的Pod标识符使得将现有卷与替换已失败Pod的新Pod相匹配变得更加容易。
StatefulSets 对于需要满足以下一个或多个需求的应用程序很有价值:
- 稳定的、唯一的网络标识符。
- 稳定的、持久的存储。
- 有序的、优雅的部署和缩放。
- 有序的、自动的滚动更新。
在上面描述中,“稳定的”意味着Pod调度或重调度的整个过程是有持久性的。 如果应用程序不需要任何稳定的标识符或有序的部署、删除或伸缩,则应该使用 由一组无状态的副本控制器提供的工作负载来部署应用程序,比如 Deployment或者ReplicaSet可能更适用于无状态应用部署需要。下面是一个创建例子:
apiVersion: v1
kind: Service
metadata:
name: nginx
labels:
app: nginx
spec:
ports:
- port: 80
name: web
clusterIP: None
selector:
app: nginx
---
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: web
spec:
selector:
matchLabels:
app: nginx # has to match .spec.template.metadata.labels
serviceName: "nginx"
replicas: 3 # by default is 1
template:
metadata:
labels:
app: nginx # has to match .spec.selector.matchLabels
spec:
terminationGracePeriodSeconds: 10
containers:
- name: nginx
image: k8s.gcr.io/nginx-slim:0.8
ports:
- containerPort: 80
name: web
volumeMounts:
- name: www
mountPath: /usr/share/nginx/html
volumeClaimTemplates:
- metadata:
name: www
spec:
accessModes: [ "ReadWriteOnce" ]
storageClassName: "my-storage-class"
resources:
requests:
storage: 1Gi上述例子中:
- 名为nginx的Headless Service用来控制网络域名。
- 名为 web 的 StatefulSet 有一个 Spec,它表明将在独立的 3 个 Pod 副本中启动 nginx 容器。
- volumeClaimTemplates 将通过 PersistentVolumes 驱动提供的PersistentVolumes来提供稳定的存储。
StatefulSet 的命名需要遵循DNS 子域名规范。
DaemonSet
DaemonSet确保全部(或者某些)节点上运行一个Pod的副本。当有节点加入集群时,也会为新增一个Pod。当有节点从集群移除时,这些Pod也会被回收。删除DaemonSet将会删除它创建的所有Pod。
DaemonSet 的一些典型用法:
- 在每个节点上运行集群守护进程
- 在每个节点上运行日志收集守护进程
- 在每个节点上运行监控守护进程
一种简单的用法是为每种类型的守护进程在所有的节点上都启动一个DaemonSet。一个稍微复杂的用法是为同一种守护进程部署多个DaemonSet,每个具有不同的标志,并且对不同硬件类型具有不同的内存、CPU 要求。
DaemonSet与Deployments非常类似,它们都能创建Pod,并且Pod中的进程都不希望被终止(例如,Web 服务器、存储服务器)。
建议为无状态的服务使用Deployments,比如前端服务。对这些服务而言,对副本的数量进行扩缩容、平滑升级,比精确控制Pod运行在某个主机上要重要得多。当需要Pod副本总是运行在全部或特定主机上,并且当该 DaemonSet提供了节点级别的功能(允许其他 Pod 在该特定节点上正确运行)时, 应该使用DaemonSet。
例如,网络插件通常包含一个以DaemonSet运行的组件。 这个DaemonSet组件确保它所在的节点的集群网络正常工作。
Job
Job会创建一个或者多个Pods,并将继续重试Pods的执行,直到指定数量的Pods成功终止。随着Pods成功结束,Job跟踪记录成功完成的Pods个数。当数量达到指定的成功个数阈值时,任务(即Job)结束。删除Job的操作会清除所创建的全部Pods。挂起Job的操作会删除Job的所有活跃Pod,直到Job被再次恢复执行。
适合以 Job 形式来运行的任务主要有三种:
- 非并行 Job:
- 通常只启动一个 Pod,除非该 Pod 失败。
- 当 Pod 成功终止时,立即视 Job 为完成状态。
- 具有 确定完成计数 的并行 Job:
- .spec.completions 字段设置为非 0 的正数值。
- Job 用来代表整个任务,当成功的 Pod 个数达到 .spec.completions 时,Job 被视为完成。
- 当使用 .spec.completionMode="Indexed" 时,每个 Pod 都会获得一个不同的 索引值,介于 0 和 .spec.completions-1 之间。
- 带 工作队列 的并行 Job:
- 不设置 spec.completions,默认值为 .spec.parallelism。
- 多个 Pod 之间必须相互协调,或者借助外部服务确定每个 Pod 要处理哪个工作条目。 例如,任一 Pod 都可以从工作队列中取走最多 N 个工作条目。
- 每个 Pod 都可以独立确定是否其它 Pod 都已完成,进而确定 Job 是否完成。
- 当 Job 中 任何 Pod 成功终止,不再创建新 Pod。
- 一旦至少 1 个 Pod 成功完成,并且所有 Pod 都已终止,即可宣告 Job 成功完成。
- 一旦任何 Pod 成功退出,任何其它 Pod 都不应再对此任务执行任何操作或生成任何输出。 所有 Pod 都应启动退出过程。
创建示例
apiVersion: batch/v1
kind: Job
metadata:
name: pi
spec:
template:
spec:
containers:
- name: pi
image: perl
command: ["perl", "-Mbignum=bpi", "-wle", "print bpi(2000)"]
restartPolicy: Never
backoffLimit: 4CronJob
CronJob创建基于时隔重复调度的Jobs,Kubernetes v1.21 [stable]引入特性。一个CronJob对象就像crontab (cron table) 文件中的一行,它用Cron格式进行编写,并周期性地在给定的调度时间执行Job。
CronJob用于执行周期性的动作,例如备份、报告生成等。这些任务中的每一个都应该配置为周期性重复的(例如:每天/每周/每月一次); 你可以定义任务开始执行的时间间隔。创建一个CronJob示例:
apiVersion: batch/v1
kind: CronJob
metadata:
name: hello
spec:
schedule: "* * * * *"
jobTemplate:
spec:
template:
spec:
containers:
- name: hello
image: busybox:1.28
imagePullPolicy: IfNotPresent
command:
- /bin/sh
- -c
- date; echo Hello from the Kubernetes cluster
restartPolicy: OnFailureReplicationController
Replication Controller(RC)保证了在所有时间内,都有特定数量的Pod副本正在运行,如果太多了,RC就杀死几个,如果太少了,RC会新建几个,和直接创建的pod不同的是,RC会替换掉那些删除的或者被终止的pod,不管删除的原因是什么(维护、更新RC都不关心)。基于这个理由,建议即使是只创建一个Pod,也要使用RC。RC就像一个进程管理器,监管着不同node上的多个pod,而不是单单监控一个Node上的Pod,RC会委派本地容器来启动一些节点上服务(Kubelet 、Docker)。
说明:在v1.11版本废弃,由RS来替代。
服务发现及负载均衡型资源
Kubernetes除了容器编排、弹性伸缩资源之外,另一强大之处在于提供了一套自己的网络模型,很好的解决了服务间网络通信和负载问题。
Kubernetes中每一个Pod都有它自己的IP地址。从端口分配、命名、服务发现、 负载均衡、应用配置和迁移的角度来看, Pod可以被视作虚拟机或者物理主机,这将形成一个干净的、向后兼容的模型,这个模型里,不需要显式地在Pod之间创建连接,不需要处理容器端口到主机端口之间的映射。这个模型不仅不复杂,还与Kubernetes实现从虚拟机向容器平滑迁移的初衷相符, 如果从虚拟机单一IP和其他虚拟机通信的角度来说,Pod和虚拟机的模型是基本相同的。
Kubernetes强制要求所有网络设施都满足以下基本要求(从而排除了有意隔离网络的策略):
- 节点上的Pod可以不通过NAT和其他任何节点上的Pod通信
- 节点上的代理(比如:系统守护进程、kubelet)可以和节点上的所有Pod通信
Kubernetes中通过Service提供在Node本身请求端口,并用这类端口转发到对应的Pod(称之为主机端口), 这是一个很特殊的操作,转发方式如何实现也是容器运行时的细节,Pod自己并不知道这些主机端口的存在。Kubernetes网络解决四方面的问题:
- 一个Pod中的容器之间通过本地回路(loopback)通信
- 集群网络在不同Pod之间提供通信
- Service资源允许对外暴露Pod中运行的应用程序, 以支持来自于集群外部的访问
- 可以使用Services来发布仅供集群内部使用的服务
Service
Kubernetes中工作负载运行在Pod之内,并且提供了将运行在一组Pods上的应用程序公开为网络服务,这种抽象称之为Service。也可以简称为svc。
Pod是非永久性资源,如果使用Deployment来运行应用程序,可以动态创建和销毁Pod。每个Pod都有自己的IP地址,但是在Deployment中,在同一时刻运行的Pod集合可能与稍后运行该应用程序的Pod集合不同。这导致了一个问题: 如果一组Pod(如"后端")为集群内的其他Pod(如"前端")提供功能, 那么前端如何找出并跟踪要连接的IP地址,以便前端可以使用提供工作负载的后端部分?
Service就提供了这样一种能力,无需调用着关注IP地址的变化,通过服务名称的映射就可以调用到真实服务,并且当被调用的Pod存在多个副本时,Service还提供了一种负载的能力。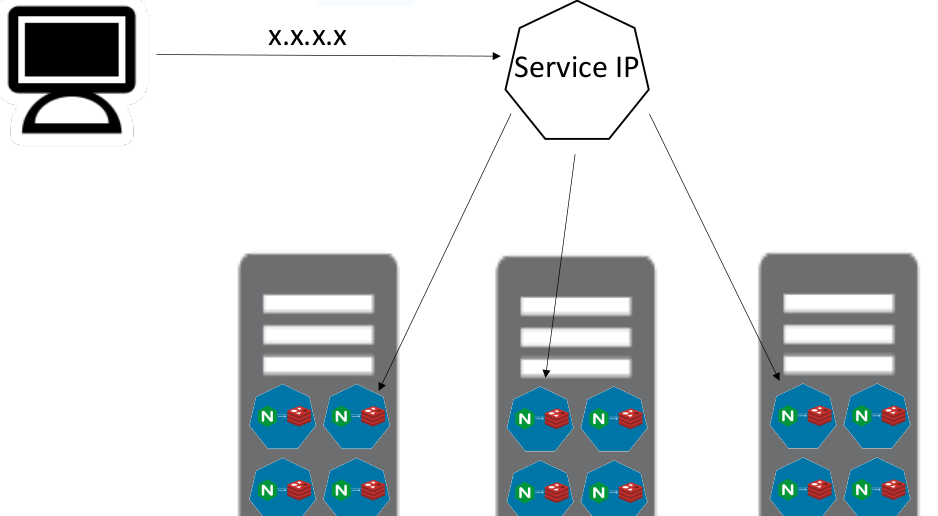
如何定义
Service是一个REST对象,基于POST方式,向apiserver发送REST请求创建服务对象。在Kubernetes中提供了几种常用的服务发布类型,通过ServiceTypes来指定服务类型:
- ClusterIP:通过集群的内部IP暴露服务,只能够在集群内部访问,默认的ServiceType类型。
- NodePort:通过每个节点上的IP和静态端口(NodePort)暴露服务,NodePort服务会路由到自动创建的 ClusterIP服务,通过请求 <节点IP>:<节点端口>,可以从集群的外部(例如公网)访问一个NodePort服务。
- LoadBalancer:使用云提供商的负载均衡器向外部暴露服务,外部负载均衡器可以将流量路由到自动创建的 NodePort服务和ClusterIP服务上。
- ExternalName:通过返回CNAME和对应值,将服务映射到externalName字段的内容(例fexample.com),无需创建任何类型代理。
说明:也可以使用Ingress来暴露自己的服务,Ingress不是一种服务类型,但它充当集群的入口点,它可以将路由规则整合到一个资源中,因此可以在同一IP地址下公开多个服务。
查看如下创建Service(服务)的yaml文件
---
apiVersion: v1
kind: Service
metadata:
annotations: {}
labels:
k8s.kuboard.cn/layer: svc
k8s.kuboard.cn/name: docker-learn-server
name: docker-learn-server
namespace: default
resourceVersion: '189188'
spec:
clusterIP: 10.233.154.14
clusterIPs:
- 10.233.154.14
externalTrafficPolicy: Cluster
internalTrafficPolicy: Cluster
ipFamilies:
- IPv4
ipFamilyPolicy: SingleStack
ports:
- name: ibsday
nodePort: 32601
port: 80
protocol: TCP
targetPort: 80
selector:
k8s.kuboard.cn/layer: svc
k8s.kuboard.cn/name: docker-learn-server
sessionAffinity: None
type: NodePort
status:
loadBalancer: {}Kubernetes为该服务分配一个IP地址(有时称为 "集群IP"),该IP地址由服务代理使用,会将请求代理到端口为80的并且便签为docker-learn-server的容器服务,该NodePort类型的服务对外公开的端口为32601。
说明:Service能够将一个接收port映射到任意的targetPort,默认情况下,targetPort将被设置为与port字段相同的值。
多端口
对于某些服务,需要公开多个端口,Kubernetes允许在Service对象上配置多个端口定义。 当服务使用多个端口时,必须提供所有端口名称,以使它们无歧义。 例如:
apiVersion: v1
kind: Service
metadata:
name: my-service
spec:
selector:
app: MyApp
ports:
- name: http
protocol: TCP
port: 80
targetPort: 9376
- name: https
protocol: TCP
port: 443
targetPort: 9377说明:与一般的Kubernetes名称一样,端口名称只能包含小写字母数字字符和-。 端口名称还必须以字母数字字符开头和结尾。例如,名称123-abc和web有效,但是123_abc和-web无效。
自定义IP
在Service创建的请求中,可以通过设置spec.clusterIP字段来指定集群IP地址。 比如,希望替换一个已经已存在的DNS条目,或者遗留系统已经配置了一个固定的IP且很难重新配置。
用户选择的IP地址必须合法,并且这个IP地址在service-cluster-ip-range CIDR范围内, 这对apiserver来说是通过一个标识来指定的。 如果IP地址不合法,apiserver会返回HTTP状态码 422,表示值不合法。
流量策略
- **外部流量策略 **
通过设置spec.externalTrafficPolicy字段来控制来自于外部的流量如何路由,可选值有Cluster和Local。字段设为 Cluster会将外部流量路由到所有就绪的端点,设为Local会只路由到当前节点上就绪的端点;如果流量策略设置为Local,而且当前节点上没有就绪的端点,kube-proxy不会转发请求相关服务的任何流量。
说明:如果启用了kube-proxy的ProxyTerminatingEndpoints特性,kube-proxy会检查节点是否有本地的端点,以及是否所有的本地端点都被标记为终止中。
如果本地有端点,而且所有端点处于终止中的状态,那么kube-proxy会忽略任何设为Local的外部流量策略。在所有本地端点处于终止中的状态的同时,kube-proxy将请求指定服务的流量转发到位于其它节点的 状态健康的端点,如同外部流量策略设为 Cluster。
针对处于正被终止状态的端点这一转发行为使得外部负载均衡器可以优雅地排出由NodePort服务支持的连接,就算是健康检查节点端口开始失败也是如此。否则,当节点还在负载均衡器的节点池内,在Pod终止过程中的流量会被丢掉,并且可能会丢失。
- **内部流量策略 **
Kubernetes在v1.22 [beta]引入的特性,设置spec.internalTrafficPolicy字段来控制内部来源的流量如何转发,可设置的值有Cluster和Local。将字段设置为Cluster会将内部流量路由到所有就绪端点,设置为Local只会路由到当前节点上就绪的端点。如果流量策略是Local,而且当前节点上没有就绪的端点,那么kube-proxy会丢弃流量。
服务发现
Kubernetes支持两种基本的服务发现模式,环境变量和DNS。
- 环境变量
当Pod运行在Node上,kubelet会为每个活跃的Service添加一组环境变量。它同时支持Docker links兼容变量,简单的{SVCNAME}_SERVICE_HOST和{SVCNAME}_SERVICE_PORT变量。这里Service的名称需大写,横线被转换成下划线。
例如:一个名称为redis-master的Service暴露了TCP端口6379,同时给它分配了Cluster IP地址10.0.0.11,这个 Service生成了如下环境变量:
REDIS_MASTER_SERVICE_HOST=10.0.0.11
REDIS_MASTER_SERVICE_PORT=6379
REDIS_MASTER_PORT=tcp://10.0.0.11:6379
REDIS_MASTER_PORT_6379_TCP=tcp://10.0.0.11:6379
REDIS_MASTER_PORT_6379_TCP_PROTO=tcp
REDIS_MASTER_PORT_6379_TCP_PORT=6379
REDIS_MASTER_PORT_6379_TCP_ADDR=10.0.0.11说明:当具有需要访问服务的Pod时,并且正在使用环境变量方法将端口和集群IP发布到客户端Pod时,必须在客户端Pod出现之前创建服务。 否则,这些客户端Pod将不会设定其环境变量。如果仅使用DNS查找服务的集群IP,则无需担心此设定问题。
- DNS
Kubernetes集群范围内使用DNS服务来完成服务名到ClusterIP的解析,一般应该使用附加组件为Kubernetes集群设置DNS服务,从Kubernetes v1.12开始,CoreDNS是推荐的DNS服务器,取代了kube-dns。支持集群的DNS服务器(例如CoreDNS)监视Kubernetes API中的新服务,并为每个服务创建一组DNS记录,如果在整个集群中都启用了DNS,则所有Pod都应该能够通过其DNS名称自动解析服务。
由于Pod的地址可变性,通过创建Service资源,绑定Service IP,将其代理到后端Pod,通过暴露Service资源的固定地址(集群IP),来解决以上Pod资源变化产生的IP变动问题,简单概括Service解决了Pod的服务发现问题。需要注意的是Service资源也会被创建和销毁,并且也绑定了唯一IP,同样存在类似于Pod服务发现的问题,如果将Service资源名称和Service暴露的网络IP通过类似域名与IP的关系进行绑定,那么只需要根据服务名就能自动匹配服务IP,解决了Service服务发现问题。
CoreDNS就是为了解决以上问题,在集群内部做了ServiceName和ServiceIP之间的自动映射,使得不需要记录Service的IP地址,只需要通过ServiceName就能访问Pod。
无头服务
如果不需要进行负载均衡,以及提供单独的Service IP,可以通过指定Cluster IP(spec.clusterIP)的值为 "None" 来创建无头服务(Headless Service)。对于Headless Service并不会分配Cluster IP,kube-proxy不会处理它们, 而且平台也不会为它们进行负载均衡和路由。
DNS如何实现自动配置,依赖于 Service 是否定义了选择算符:
- 带选择算符的服务
对定义了选择算符的无头服务,Endpoint控制器在API中创建了Endpoints记录,并且修改DNS配置返回A记录,通过这个地址直接到达Service的后端Pod上。
- 无选择算符的服务
对没有定义选择算符的无头服务,Endpoint控制器不会创建Endpoints记录。 然而DNS系统会查找和配置,无论是:
- 对于ExternalName类型的服务,查找其CNAME记录
- 对所有其他类型的服务,查找与Service名称相同的任何Endpoints的记录
代理模式
在Kubernetes集群中,每个Node运行一个kube-proxy进程。kube-proxy负责为Service实现了一种VIP(虚拟 IP)的形式,而不是ExternalName的形式。
Kubernetes依赖代理将入站流量转发到后端,为什么不使用DNS轮询? 例如:是否可以配置具有多个A值(或 IPv6为AAAA)的DNS记录,并依靠轮询名称解析?
使用服务代理有以下几个原因:
- DNS实现的历史由来已久,它不遵守记录TTL,并且在名称查找结果到期后对其进行缓存。
- 有些应用程序仅执行一次DNS查找,并无限期地缓存结果。
- 即使应用和库进行了适当的重新解析,DNS记录上的TTL值低或为零也可能会给DNS带来高负载,从而使管理变得困难。
- userspace
kube-proxy会监视Kubernetes控制平面对Service对象和Endpoints对象的添加和移除操作。对每个Service,它会在本地Node上打开一个随机端口。任何连接到"代理端口"的请求,都会被代理到Service后端Pods中的某个上面。使用哪个后端Pod,是kube-proxy基于SessionAffinity来确定的,默认情况下,用户空间模式下的kube-proxy通过轮转算法选择后端。
- iptables
kube-proxy会监视Kubernetes控制节点对Service对象和Endpoints对象的添加和移除。使用iptables处理流量具有较低的系统开销,因为流量由Linux netfilter处理,无需在用户空间和内核空间之间切换,这种方法也更可靠:
- 对每个Service,kube-proxy会配置iptables规则,从而捕获到达该Service的clusterIP和端口的请求,进而将请求重定向到Service的一组后端中的某个Pod上面。
- 对于每个Endpoints对象,kube-proxy也会配置iptables规则,这个规则会选择一个后端组合。默认的策略是,kube-proxy在iptables模式下随机选择一个后端。
如果kube-proxy在iptables模式下运行,且所选的第一个Pod没有响应,则连接失败。与userspace模式不同。这种情况下,kube-proxy将检测到与第一个Pod的连接已失败,并会自动使用其他后端Pod重试。可以使用Pod就绪探测器验证后端Pod可以正常工作,以便iptables模式下的kube-proxy仅看到测试正常的后端。这样做可以避免将流量通过kube-proxy发送到已知失败的Pod。
- ipvs
在ipvs模式下,kube-proxy监视Kubernetes服务和端点,调用netlink接口相应地创建IPVS规则,并定期将IPVS规则与Kubernetes服务和端点同步。该控制循环可确保IPVS状态与所需状态匹配。访问服务时,IPVS将流量定向到后端Pod之一。
IPVS代理模式基于类似于iptables模式的netfilter挂钩函数,但是使用哈希表作为基础数据结构,并且在内核空间中工作。这意味着,与iptables模式下的kube-proxy相比,IPVS模式下的kube-proxy重定向通信的延迟要短,并且在同步代理规则时具有更好的性能。与其他代理模式相比,IPVS模式还支持更高的网络流量吞吐量。IPVS提供了更多选项来平衡后端Pod的流量:
- rr:轮替(Round-Robin)
- lc:最少链接(Least Connection),即打开链接数量最少者优先
- dh:目标地址哈希(Destination Hashing)
- sh:源地址哈希(Source Hashing)
- sed:最短预期延迟(Shortest Expected Delay)
- nq:从不排队(Never Queue)
服务类型
- NodePort类型
如果将type字段设置为NodePort,Kubernetes会在--service-node-port-range标志指定的范围内分配端口(默认值:30000-32767),通过.spec.ports[].nodePort字段指定端口,每个节点将那个端口(每个节点上的相同端口号)代理到服务中。
使用NodePort可以自由设置自己的负载均衡解决方案,配置Kubernetes不完全支持的环境,甚至直接暴露一个或多个节点的IP。Service能够通过
:spec.ports[
].nodePort和spec.clusterIp:spec.ports[*].port对外可见。 如果设置了kube-proxy的--nodeport-addresses参数或kube-proxy配置文件中的等效字段,
将被过滤NodeIP。
如果要指定特定的IP代理端口,可以设置kube-proxy中的--nodeport-addresses参数或者将kube-proxy配置文件 中的等效nodePortAddresses字段设置为特定的IP块。标志采用逗号分隔的IP块列表(10.0.0.0/8,192.0.2.0/25)来指定kube-proxy认为是此节点的IP地址范围。
如果使用--nodeport-addresses=127.0.0.0/8标志启动kube-proxy,则kube-proxy仅选择NodePort Services的本地回路接口。--nodeport-addresses的默认值是一个空列表,这意味着kube-proxy应该考虑NodePort的所有可用网络接口。(这也与早期的 Kubernetes 版本兼容)。
如果需要特定的端口号,可以在nodePort字段中指定一个值。控制平面将分配该端口或报告API事务失败。这意味着需要注意可能发生的端口冲突。必须使用有效的端口号,该端口号在配置用于NodePort的范围内。下面是一个创建NodeType类型Service的实例:
apiVersion: v1
kind: Service
metadata:
name: my-service
spec:
type: NodePort
selector:
app: MyApp
ports:
# 默认情况下,为了方便起见,`targetPort` 被设置为与 `port` 字段相同的值。
- port: 80
targetPort: 80
# 可选字段
# 默认情况下,为了方便起见,Kubernetes 控制平面会从某个范围内分配一个端口号(默认:30000-32767)
nodePort: 30007- LoadBalancer类型
如果需要使用支持外部负载均衡器的云提供商服务,设置type的值为"LoadBalancer", 将为Service提供负载均衡器。负载均衡器是异步创建的,关于被提供的负载均衡器的信息将会通过Service的status.loadBalancer字段发布出去。如下是创建LoadBalancer类型的Service示例:
apiVersion: v1
kind: Service
metadata:
name: my-service
spec:
selector:
app: MyApp
ports:
- protocol: TCP
port: 80
targetPort: 9376
clusterIP: 10.0.171.239
type: LoadBalancer
status:
loadBalancer:
ingress:
- ip: 192.0.2.127来自外部负载均衡器的流量将直接重定向到后端Pod上,不过实际它们是如何工作的,这要依赖于云提供商。某些云提供商允许设置loadBalancerIP,在这些情况下,将根据用户设置的loadBalancerIP来创建负载均衡器。如果没有设置loadBalancerIP字段,将会给负载均衡器指派一个临时IP;如果设置了loadBalancerIP,但云提供商并不支持这种特性,那么设置的loadBalancerIP值将会被忽略掉。
Ingress
Ingress是在kubernetes v1.19[stable]版本引入,Ingress是对集群中服务的外部访问进行管理的API对象,典型的访问方式是HTTP。
什么是Ingress
Ingress公开了从集群外部到内部服务的HTTP和HTTPS路由,为Service提供外部可访问的URL、负载均衡流量,流量路由由Ingress资源上定义的规则控制,也可以配置边缘路由或其他前端帮助处理流量。Ingress不会公开任意端口或协议,将HTTP或HTTPS以外的服务公开到Internet时,通常使用NodePort或LoadBalancer类型的Service。其工作过程如下图所示: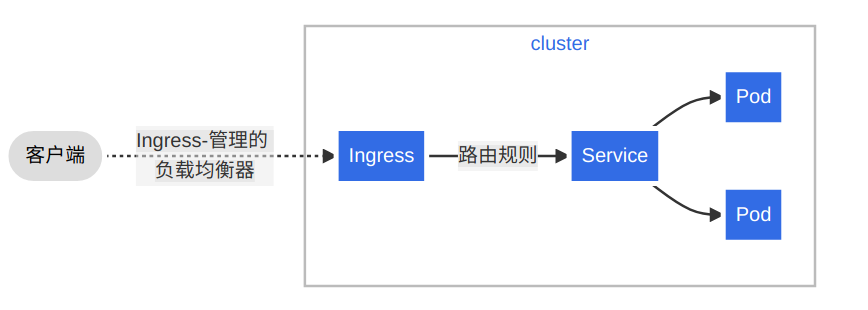
如何使用
为了让Ingress资源工作,集群必须有一个运行状态的Ingress控制器。与作为kube-controller-manager可执行文件的一部分运行的其他类型的控制器不同,Ingress控制器不是随集群自动启动的。
使用Ingress类可以在集群中部署任意数量的Ingress控制器。使用.metadata.name字段的值来设置Ingress对象的ingressClassName字段,ingressClassName是之前的注解做法的替代。
如果没有指定一个IngressClass,并且集群中只有一个IngressClass被标记为了默认,Kubernetes会应用此默认IngressClass。 也可以将ingressclass.kubernetes.io/is-default-class注解的值设置为"true"把一个IngressClass标记为集群默认。如下所示为一个最小的Ingress资源示例:
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: minimal-ingress
annotations:
nginx.ingress.kubernetes.io/rewrite-target: /
spec:
rules:
- http:
paths:
- path: /testpath
pathType: Prefix
backend:
service:
name: test
port:
number: 80作用域
Ingress的作用域取决于Ingress控制器,作用域范围可以是集群也可以是名称空间,IngressClass的参数默认是集群范围的。
- 集群范围
如果设置了.spec.parameters字段且未设置.spec.parameters.scope字段,或是将.spec.parameters.scope字段设为了Cluster,那么该IngressClass所指代的即是一个集群作用域的资源。 参数的kind(和apiGroup一起)指向一个集群作用域的API(可能是一个定制资源Custom Resource),而它的name则为此API确定了一个具体的集群作用域的资源。
---
apiVersion: networking.k8s.io/v1
kind: IngressClass
metadata:
name: external-lb-1
spec:
controller: example.com/ingress-controller
parameters:
# 此 IngressClass 的配置定义在一个名为 “external-config-1” 的
# ClusterIngressParameter(API 组为 k8s.example.net)资源中。
# 这项定义告诉 Kubernetes 去寻找一个集群作用域的参数资源。
scope: Cluster
apiGroup: k8s.example.net
kind: ClusterIngressParameter
name: external-config-1- 名称空间范围
Kubernetes v1.23[stable]版本引入该特性,如果设置了.spec.parameters字段且将.spec.parameters.scope字段设为了Namespace,那么该IngressClass将会引用一个名称空间作用域的资源。.spec.parameters.namespace必须和此资源所处的名称空间相同。
参数的kind(和apiGroup一起)指向一个名称空间作用域的API(例如:ConfigMap),而它的name则确定了一个位于指定的名称空间中的具体的资源。
名称空间作用域的参数帮助集群操作者将控制细分到用于工作负载的各种配置中(比如:负载均衡设置、API 网关定义)。如果使用集群作用域的参数,那么必须从以下两项中选择一项执行:
- 每次修改配置,集群操作团队需要批准其他团队的修改。
- 集群操作团队定义具体的准入控制,比如RBAC角色与角色绑定,以使得应用程序团队可以修改集群作用域的配置参数资源。
IngressClass API本身是集群作用域的。下面是一个引用名称空间作用域的配置参数的IngressClass的示例:
---
apiVersion: networking.k8s.io/v1
kind: IngressClass
metadata:
name: external-lb-2
spec:
controller: example.com/ingress-controller
parameters:
# 此 IngressClass 的配置定义在一个名为 “external-config” 的
# IngressParameter(API 组为 k8s.example.com)资源中,
# 该资源位于 “external-configuration” 命名空间中。
scope: Namespace
apiGroup: k8s.example.com
kind: IngressParameter
namespace: external-configuration
name: external-config扇出
过多的Ingress类资源会难以管理,因此Ingress提供了一种方案,Ingress允许降低负载均衡器的数量,Ingress可以HTTP URI将来自同一IP地址的流量路由到多个Service,这种方式称为扇出(fanout)可以简单理解为对所有的客户端请求提供一个入口点,并根据URI分发至各自请求的后端。如图所示: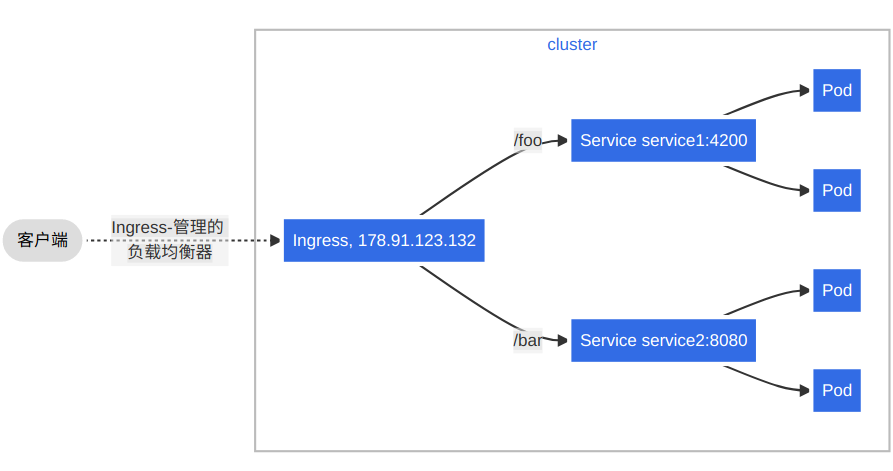
下面是一个配置示例:
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: simple-fanout-example
spec:
rules:
- host: foo.bar.com
http:
paths:
- path: /foo
pathType: Prefix
backend:
service:
name: service1
port:
number: 4200
- path: /bar
pathType: Prefix
backend:
service:
name: service2
port:
number: 8080虚拟托管
基于名称的虚拟主机支持将针对多个主机名的HTTP流量路由到同一IP地址上。
以下Ingress让后台负载均衡器基于host 头部字段来路由请求。
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: name-virtual-host-ingress
spec:
rules:
- host: foo.bar.com
http:
paths:
- pathType: Prefix
path: "/"
backend:
service:
name: service1
port:
number: 80
- host: bar.foo.com
http:
paths:
- pathType: Prefix
path: "/"
backend:
service:
name: service2
port:
number: 80如果创建的Ingress资源没有在rules中定义的任何hosts,则可以匹配指向Ingress控制器IP地址的任何网络流量,而无需基于名称的虚拟主机。
以下Ingress会将请求first.bar.com的流量路由到service1,将请求second.bar.com的流量路由到 service2,而所有其他流量都会被路由到service3。
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: name-virtual-host-ingress-no-third-host
spec:
rules:
- host: first.bar.com
http:
paths:
- pathType: Prefix
path: "/"
backend:
service:
name: service1
port:
number: 80
- host: second.bar.com
http:
paths:
- pathType: Prefix
path: "/"
backend:
service:
name: service2
port:
number: 80
- http:
paths:
- pathType: Prefix
path: "/"
backend:
service:
name: service3
port:
number: 80Ingress-Nginx
Kubernetes作为一个项目,目前支持和维护AWS、 GCE和Nginx Ingress控制器。其中常用的是基于Nginx的Ingress-Nginx,这里的Nginx是经过改造适配于Ingress的。
这里不做过多介绍,详细内容可以查看官网或者Github地址,官方网站:
Github地址:
配置与存储型资源
卷(Volume)
无论是Docker还是Kubernetes中其他CRI,都存在着一个问题,容器中的文件是临时存在的,会随着容器重启、销毁、或者故障等造成数据丢失,此外在Pod中如果存在多个容器共享文件,也需要提供共享空间。Docker也有卷(Volume)的概念,但对它只有少量且松散的管理。Docker卷是磁盘上或者另外一个容器内的一个目录,提供卷驱动程序,但是其功能非常有限。Kubernetes Volume(数据卷)主要解决了如下两方面问题:
- 数据持久性:通常情况下,容器运行起来之后,写入到其文件系统的文件暂时性的。当容器崩溃后,kubelet 将会重启该容器,此时原容器运行后写入的文件将丢失,因为容器将重新从镜像创建
- 数据共享:同一个 Pod(容器组)中运行的容器之间,经常会存在共享文件/文件夹的需求
卷的核心是一个目录,其中可能存有数据,Pod中的容器可以访问该目录中的数据。 所采用的特定的卷类型将决定该目录如何形成的、使用何种介质保存数据以及目录中存放的内容。使用卷时,在.spec.volumes字段中设置为Pod提供的卷,并在.spec.containers[*].volumeMounts字段中声明卷在容器中的挂载位置。容器中的进程看到的文件系统视图是由它们的容器镜像的初始内容以及挂载在容器中的卷(如果定义了的话)所组成的。 其中根文件系统同容器镜像的内容相吻合, 任何在该文件系统下的写入操作,如果被允许的话,都会影响接下来容器中进程访问文件系统时所看到的内容。
Kubernetes支持很多类型的卷,Pod可以同时使用任意数目的卷类型。临时卷类型的生命周期与Pod相同,但持久卷可以比Pod的存活期长;当Pod不再存在时,Kubernetes也会销毁临时卷;不过Kubernetes不会销毁持久卷。对于给定Pod中任何类型的卷,在容器重启期间数据都不会丢失。卷挂载在镜像中的指定路径下,Pod配置中的每个容器必须独立指定各个卷的挂载位置,卷不能挂载到其他卷之上(不过存在一种使用 subPath 的相关机制),也不能与其他卷有硬链接。
持久卷
存储的管理是一个与计算实例的管理完全不同的问题。Kubernetes中为用户和管理员提供了一组API,将存储如何供应的细节从其如何被使用中抽象出来,为了实现这点,引入了两个新的API资源:
- 持久卷(PersistentVolume,PV)
PV是集群中的一块存储,可由管理员事先供应,或使用存储类(Storage Class)动态供应。持久卷是集群资源,就像节点也是集群资源一样。PV和普通的Volume一样,也是使用卷插件来实现的,只是它们拥有独立于任何使用PV的Pod的生命周期,此API对象中记述了存储的实现细节,无论其背后是NFS、iSCSI还是特定于云平台的存储系统。
- 持久卷申领(PersistentVolumeClaim,PVC)
PVC表达的是用户对存储的需求,概念上与Pod类似。Pod会耗用节点资源,而PVC会耗用PV资源。Pod可以请求特定数量的资源(CPU 和内存);同样PVC也可以请求特定的大小和访问模式 (例如,可以要求PV卷能够以ReadWriteOnce、ReadOnlyMany或ReadWriteMany模式之一来挂载)。
PVC允许用户消耗抽象的存储资源,常见的情况是针对不同场景用户需要具有不同属性(如:性能)的PV卷。集群管理员需要能够提供不同性质的PV,并且这些PV卷之间的差别不仅限于卷大小和访问模式,同时又不能将卷是如何实现的这些细节暴露给用户,为了满足这类需求,就有了存储类(StorageClass) 资源。
PV卷的供应有两种方式:静态供应、动态供应。
- 静态供应
集群管理员创建若干PV卷。这些卷对象带有真实存储的细节信息,并且对集群用户可用(可见)。PV卷对象存在于Kubernetes API中,可供用户使用。
- 动态供应
如果管理员所创建的所有静态PV卷都无法与用户的PVC匹配,集群可以尝试为该PVC动态供应一个存储卷。这一供应操作是基于StorageClass来实现的。
说明:PVC必须请求某个存储类,同时集群管理员必须已经创建并配置了该类,这样动态供应卷的动作才会发生。如果PVC指定存储类为 "",则相当于为自身禁止使用动态供应的卷。
为了基于存储类完成动态的存储供应,集群管理员需要在apiserver上启用DefaultStorageClass准入控制器。例:通过保证DefaultStorageClass出现在apiserver组件的--enable-admission-plugins标志值中实现这点,该标志的值可以是逗号分隔的有序列表。
关于PV、PVC以及StorageClass之间关系示意图如下所示:
Pod将PVC当做存储卷来使用,集群会检视PVC,找到所绑定的卷,并为Pod挂载该卷。对于支持多种访问模式的卷,用户要在Pod中以卷的形式使用PVC时需指定期望的访问模式。一旦用户有了PVC对象并且该对象已被绑定,则所绑定的PV卷在用户需要期间一直属于该用户。用户通过在Pod的volumes块中包含PVC节区来调度Pod,访问所申领的PV卷。
说明:用户创建一个带有特定存储容量和特定访问模式的PVC对象,在动态供应场景下,这个PVC对象可能已经创建完毕。主控节点中的控制回路监测新的PVC对象,寻找与之匹配的PV卷,并将二者绑定到一起。如果为了新的PVC动态供应了PV卷,则控制回路总是将该PV卷绑定到这一PVC。否则,用户总是能够获得他们所请求的资源,只是所获得的PV卷可能会超出所请求的配置。无论该PVC是如何与PV卷建立的绑定关系,一旦绑定关系建立,则PVC绑定就是排他性的。PVC与PV卷之间的绑定是一种一对一的映射,实现上使用ClaimRef来记述PV卷与PVC申领间的双向绑定关系。
如果找不到匹配的PV卷,PVC会无限期地处于未绑定状态。当匹配的PV卷可用时,PVC会被绑定。例:即使某集群上供应了很多50 Gi大小的PV卷,也无法与请求100 Gi大小的存储的PVC匹配。当新的 100 Gi PV卷被加入到集群时,该PVC才有可能被绑定。
投射卷
投射卷(Projected Volumes),一个Projected Volumes可以将若干现有的卷源映射到同一个目录之上。所有的卷源都要求处于Pod所在的同一个名称空间内。目前以下类型的卷源可以被投射:
- secret
- downwardAPI
- configMap
- serviceAccountToken
- 带有Secret、DownwardAPI和ConfigMap的配置示例
apiVersion: v1
kind: Pod
metadata:
name: volume-test
spec:
containers:
- name: container-test
image: busybox:1.28
volumeMounts:
- name: all-in-one
mountPath: "/projected-volume"
readOnly: true
volumes:
- name: all-in-one
projected:
sources:
- secret:
name: mysecret
items:
- key: username
path: my-group/my-username
- downwardAPI:
items:
- path: "labels"
fieldRef:
fieldPath: metadata.labels
- path: "cpu_limit"
resourceFieldRef:
containerName: container-test
resource: limits.cpu
- configMap:
name: myconfigmap
items:
- key: config
path: my-group/my-config- 带有非默认权限模式设置的Secret的配置示例
apiVersion: v1
kind: Pod
metadata:
name: volume-test
spec:
containers:
- name: container-test
image: busybox:1.28
volumeMounts:
- name: all-in-one
mountPath: "/projected-volume"
readOnly: true
volumes:
- name: all-in-one
projected:
sources:
- secret:
name: mysecret
items:
- key: username
path: my-group/my-username
- secret:
name: mysecret2
items:
- key: password
path: my-group/my-password
mode: 511每个被投射的卷源都列举在规约中的sources下面。参数几乎相同,只有两个例外:
- 对于Secret,secretName字段被改为name以便于ConfigMap的命名一致;
- defaultMode只能在投射层级设置,不能在卷源层级设置,也可以显式地为每个投射单独设置mode属性。
临时卷
临时卷(Ephemeral Volume)区别于持久卷,有的应用程序需要额外存储,但并不关心数据在重启后是否存在。例如,缓存服务经常受限于内存大小,将不常用的数据转移到比内存慢、但对总体性能的影响很小的存储中。另外,有的应用程序需要以文件形式注入的只读数据,比如配置数据或密钥。
临时卷就是为上述类似用例设计的,遵从Pod的生命周期,与Pod一起创建和删除,停止和重新启动Pod时,不会受持久卷在何处可用的限制。临时卷在Pod规范中以内联方式定义,简化了应用程序的部署和管理。Kubernetes为不同的场景,支持几种不同类型的临时卷:
- emptyDir: Pod 启动时为空,存储空间来自本地的kubelet根目录(通常是根磁盘)或内存
- configMap、downwardAPI、secret: 将不同类型的Kubernetes数据注入到Pod中
- CSI临时卷: 类似于前面的卷类型,但由专门支持此特性的指定CSI驱动程序提供
- 通用临时卷: 它可以由所有支持持久卷的存储驱动程序提供
emptyDir、configMap、downwardAPI、secret是作为本地临时存储提供的,它们由各个节点上的kubelet管理。
CSI临时卷必须由第三方CSI存储驱动程序提供。通用临时卷可以由第三方CSI存储驱动程序提供,也可以由支持动态配置的任何其他存储驱动程序提供。一些专门为CSI临时卷编写的CSI驱动程序,不支持动态供应,因此这些驱动程序不能用于通用临时卷。使用第三方驱动程序的优势在于,它们可以提供Kubernetes本身不支持的功能,例如,与kubelet管理的磁盘具有不同运行特征的存储,或者用来注入不同的数据。
存储类
StorageClass资源为管理员提供了描述存储"类"的方法。不同的类型可能会映射到不同的服务质量等级或备份策略,或是由集群管理员制定的任意策略。Kubernetes本身并不清楚各种类代表的什么,这个类的概念在其他存储系统中有时被称为 "配置文件"。
每个StorageClass都包含provisioner、parameters和reclaimPolicy字段,这些字段会在StorageClass需要动态分配PV时会使用到。
StorageClass对象的命名很重要,用户使用这个命名来请求生成一个特定的类。当创建StorageClass对象时,管理员设置StorageClass对象的命名和其他参数,一旦创建了对象就不能再对其更新。
创建StorageClass示例:
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: standard
provisioner: kubernetes.io/aws-ebs
parameters:
type: gp3
reclaimPolicy: Retain
allowVolumeExpansion: true
mountOptions:
- debug
volumeBindingMode: Immediate健康监测
CSI卷健康监测支持CSI驱动从底层存储系统着手,探测异常卷状态,并以事件形式上报到PVC或Pod。Kubernetes卷健康监测是Kubernetes容器存储接口(CSI)实现的一部分。卷健康监测特性由外部健康监测控制器kubelet两个组件实现。如果CSI驱动器通过控制器的方式支持卷健康监测特性,那么只要在CSI卷上监测到异常卷状态,就会在 PVC中上报一个事件。
外部健康监测控制器也会监测节点失效事件。如果要启动节点失效监测功能,可以设置标志enable-node-watcher为true。当外部健康监测器检测到节点失效事件,控制器会报送一个事件,该事件会在 PVC 上继续上报,以表明使用此PVC的Pod正位于一个失效的节点上。如果CSI驱动程序支持节点测的卷健康检测,那当在CSI卷上检测到异常卷时,会在使用该PVC的每个Pod上触发一个事件。
CSI
CSI卷克隆功能增加了通过在dataSource字段中指定存在的PVC,来表示用户想要克隆的卷。克隆(Clone),意思是为已有的Kubernetes卷创建副本,它可以像任何其它标准卷一样被使用。唯一的区别就是配置后,后端设备将创建指定完全相同的副本,而不是创建一个"新的"空卷。
从Kubernetes API的角度看,克隆的实现只是在创建新的PVC时,增加了指定一个现有PVC作为数据源的能力。源PVC必须是bound状态且可用的(不在使用中)。用户在使用该功能时,需要注意以下事项:
- 克隆支持(VolumePVCDataSource)仅适用于CSI驱动
- 克隆支持仅适用于动态供应器
- CSI驱动可能实现,也可能未实现卷克隆功能
- 仅当PVC与目标PVC存在于同一命名空间(源和目标PVC必须在相同的命名空间)时,才可以克隆PVC
- 仅在同一存储类中支持克隆。
- 目标卷必须和源卷具有相同的存储类
- 可以使用默认的存储类并且storageClassName字段在规格中忽略了
- 克隆只能在两个使用相同VolumeMode设置的卷中进行(如果请求克隆一个块存储模式的卷,源卷必须也是块存储模式)。
克隆卷与其他任何PVC一样配置,除了需要增加dataSource来引用同一命名空间中现有的PVC。创建示例:
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: clone-of-pvc-1
namespace: myns
spec:
accessModes:
- ReadWriteOnce
storageClassName: cloning
resources:
requests:
storage: 5Gi
dataSource:
kind: PersistentVolumeClaim
name: pvc-1说明:必须为spec.resources.requests.storage指定一个值,并且指定的值必须大于或等于源卷的值。
创建结果是一个名称为clone-of-pvc-1的新PVC与指定的源pvc-1拥有相同的内容。一旦新的PVC可用,被克隆的PVC像其他PVC一样被使用。可以预期的是,新创建的PVC是一个独立的对象。 可以独立使用、克隆、快照或删除它,而不需要考虑它的原始数据源PVC。这也意味着,源没有以任何方式链接到新创建的PVC,它也可以被修改或删除,而不会影响到新创建的克隆。
DownwardAPI
有两种方式可以将Pod和Container字段呈现给运行中的容器:
- 环境变量:用于单个变量,可以将Pod信息和容器信息直接注入容器内部
- 卷文件:将Pod信息生成为文件,直接挂载到容器内部中去
这两种呈现Pod和Container字段的方式都称为Downward API。
更多内容查看:Downward API
ConfigMap
ConfigMap是一种配置类资源,用来将非机密性的数据保存到键值对中。Pods可以将其用作环境变量、命令行参数或者存储卷中的配置文件。ConfigMap主要作用把环境配置信息和容器镜像解耦,便于应用配置的修改。在设计上ConfigMap不是用来保存大量数据的,其保存的数据不可超过1M。如果需要保存超出此尺寸限制的数据,可以考虑挂载存储卷或者使用独立的数据库或者文件服务。
说明:ConfigMap并不提供保密或加密功能。如果存储的数据是机密的,使用Secret或者使用第三方工具来保证数据的私密性。
ConfigMap也可以看作一个API对象,可以存储其他对象所需要使用的配置。和其他Kubernetes对象都有一个spec不同的是,ConfigMap使用data和binaryData字段,能够接收"键-值"对作为其取值。data和binaryData字段都是可选的。data字段设计用来保存UTF8字符串,binaryData则被设计用来保存二进制数据作为base64编码的字串。
ConfigMap 的名字必须是一个合法的DNS子域名。data或binaryData字段下面的每个键的名称都必须由字母数字字符或者-、_或.组成。在data下保存的键名不可以与在binaryData下出现的键名有重叠。
如何使用
ConfigMap可以作为数据卷挂载,也可被系统的其他组件使用, 而不一定直接暴露给Pod。最常见的用法是为同一命名空间里某Pod中运行的容器执行配置,也可单独使用,比如基于ConfigMap调整其行为插件或Operator。在一个Pod的存储卷中使用ConfigMap,一般流程如下:
- 创建一个ConfigMap对象或者使用现有的ConfigMap对象,多个Pod可以引用同一个ConfigMap
- 修改Pod定义,在spec.volumes[]下添加一个卷,为该卷设置任意名称,将spec.volumes[].configMap.name字段设置为对ConfigMap对象的引用
- 为每个需要该ConfigMap的容器添加一个.spec.containers[].volumeMounts[]字段,设置字段的值如下:
- 将.spec.containers[].volumeMounts[].readOnly值设置为true
- 将.spec.containers[].volumeMounts[].mountPath设置为一个未使用的目录名,ConfigMap的内容将出现在该目录中。
- 更改镜像或者命令行,以便程序能够从该目录中查找文件,ConfigMap中的每个data键会变成mountPath下面的一个文件名。
下面是一个将ConfigMap以卷的形式进行挂载的Pod示例:
apiVersion: v1
kind: Pod
metadata:
name: mypod
spec:
containers:
- name: mypod
image: redis
volumeMounts:
- name: foo
mountPath: "/etc/foo"
readOnly: true
volumes:
- name: foo
configMap:
name: myconfigmap说明:如果Pod中有多个容器,每个容器都需要自己的volumeMounts块,每个ConfigMap,只需设置一个spec.volumes块,被挂载的ConfigMap内容会被自动更新。当卷中使用的ConfigMap被更新时,所投射的键最终也会被更新。kubelet组件会在每次周期性同步时检查所挂载的ConfigMap是否为最新。kubelet使用的是本地的高速缓存来获得ConfigMap当前值,缓存类型通过KubeletConfiguration结构ConfigMapAndSecretChangeDetectionStrategy字段来配置。
ConfigMap既可通过watch实现内容传播(默认形式),也可实现基于TTL的缓存,还可直接经过所有请求重定向到apiserver。从ConfigMap被更新的那一刻算起,到新的主键被投射到Pod中去,这一时间跨度可能与kubelet的同步周期加上高速缓存的传播延迟相等。这里的传播延迟取决于所选的高速缓存类型 (分别对应watch操作的传播延迟、高速缓存的TTL时长或者0)。以环境变量方式使用的ConfigMap数据不会被自动更新。更新这些数据需要重新启动 Pod。使用ConfigMap作为subPath卷挂载的容器将不会收到ConfigMap的更新。
某些情况下,可以写一个引用ConfigMap的Pod的spec,并根据ConfigMap中的数据在该Pod中配置容器,这个Pod和ConfigMap必须要在同一个名称空间中。静态Pod中的spec字段不能引用ConfigMap或任何其他API对象。
这是一个ConfigMap的示例,它的一些键只有一个值,其他键的值看起来像是配置的片段格式。
apiVersion: v1
kind: ConfigMap
metadata:
name: game-demo
data:
# 类属性键;每一个键都映射到一个简单的值
player_initial_lives: "3"
ui_properties_file_name: "user-interface.properties"
# 类文件键
game.properties: |
enemy.types=aliens,monsters
player.maximum-lives=5
user-interface.properties: |
color.good=purple
color.bad=yellow
allow.textmode=true可以使用四种方式来使用ConfigMap配置Pod中的容器:
- 在容器命令和参数内
- 容器的环境变量
- 在只读卷里面添加一个文件,让应用来读取
- 编写代码在Pod中运行,使用Kubernetes API来读取ConfigMap
不同的方法适用于不同的数据使用方式。前三种方法,kubelet使用ConfigMap中的数据在Pod中启动容器。第四种方法必须编写代码才能读取ConfigMap数据,由于直接使用Kubernetes API,只要ConfigMap发生更改, 应用就能够通过订阅来获取更新,并且在这样的情况发生的时候做出反应。通过直接进入Kubernetes API,也可以获取到不同的名称空间里的ConfigMap。下面是一个Pod示例,通过使用game-demo中的值来配置一个Pod:
apiVersion: v1
kind: Pod
metadata:
name: configmap-demo-pod
spec:
containers:
- name: demo
image: alpine
command: ["sleep", "3600"]
env:
# 定义环境变量
- name: PLAYER_INITIAL_LIVES # 请注意这里和 ConfigMap 中的键名是不一样的
valueFrom:
configMapKeyRef:
name: game-demo # 这个值来自 ConfigMap
key: player_initial_lives # 需要取值的键
- name: UI_PROPERTIES_FILE_NAME
valueFrom:
configMapKeyRef:
name: game-demo
key: ui_properties_file_name
volumeMounts:
- name: config
mountPath: "/config"
readOnly: true
volumes:
# 你可以在 Pod 级别设置卷,然后将其挂载到 Pod 内的容器中
- name: config
configMap:
# 提供你想要挂载的 ConfigMap 的名字
name: game-demo
# 来自 ConfigMap 的一组键,将被创建为文件
items:
- key: "game.properties"
path: "game.properties"
- key: "user-interface.properties"
path: "user-interface.properties"ConfigMap不会区分单行属性值和多行类似文件的值,重要的是Pods和其他对象如何使用这些值。示例定义了一个卷并将它作为/config文件夹挂载到demo容器内,创建两个文件,/config/game.properties和 /config/user-interface.properties,尽管ConfigMap中包含了四个键。这是因为Pod定义中在volumes节指定了一个items数组。如果完全忽略items数组,则ConfigMap中的每个键都会变成一个与该键同名的文件,会得到四个文件。
不可变更选项
从v1.19开始,可以添加一个immutable字段到ConfigMap定义中,创建不可变更的ConfigMap。Kubernetes特性 Immutable Secret和ConfigMaps提供了一种将各个Secret和ConfigMap设置为不可变更的选项。对于大量使用 ConfigMap的集群 (至少有数万个各不相同的ConfigMap给Pod挂载)而言,禁止更改ConfigMap的数据有以下好处:
- 保护应用,使之免受意外(不想要的)更新所带来的负面影响。
- 大幅降低对kube-apiserver的压力提升集群性能,系统会关闭对已标记为不可变更的ConfigMap的监视操作。
此功能特性由ImmutableEphemeralVolumes控制,将immutable字段设置为true创建不可变更的 ConfigMap。 例如:
apiVersion: v1
kind: ConfigMap
metadata:
...
data:
...
immutable: true一旦某ConfigMap被标记为不可变更,则无法逆转这一变化,也无法更改data或binaryData字段的内容,只能删除并重建ConfigMap,现有的Pod会维护一个已被删除的ConfigMap的挂载点,建议重新创建这些Pods。
Secret
Secret是一种包含少量敏感信息例如密码、令牌或密钥的对象,这些信息可能会放在Pod规约中或镜像中,这样不需要在应用程序代码中包含机密数据。Secret类似于ConfigMap但专门用于保存机密数据。由于创建Secret可以独立于使用它的Pod,因此在创建、查看和编辑Pod的工作流程中暴露Secret的风险较小。在集群中运行的应用程序也可以对Secret采取额外的预防措施,例如避免将机密数据写入非易失性存储。
说明:默认情况下Secret未加密地存储在apiserver的底层数据存储etcd中,任何拥有API或etcd访问权限的人都可以检索或修改Secret。此外,任何有权限在命名空间中创建Pod的人都可以使用该访问权限读取该命名空间中的任何Secret,包括间接访问。例:创建Deployment的能力,为了安全地使用Secret,需至少执行以下步骤:
- 为Secret启用静态加密
- 启用或配置RBAC规则来限制读取和写入Secret的数据,被准许创建Pod的人也隐式地被授权获取Secret内容
- 在适当的情况下,也可以使用RBAC等机制来限制允许哪些主体创建新Secret或替换现有Secret
类型
创建Secret时,可以使用Secret资源的type字段,或者与其等价的kubectl命令行参数为其设置类型,类型有助于对Secret数据进行编程处理。Kubernetes提供若干内置类型,用于一些常见的使用场景,不同类型Kubernetes执行的合法性检查操作以及对其所实施的限制各不相同。
| 内置类型 | 用法 |
|---|---|
| Opaque | 用户定义的任意数据 |
| kubernetes.io/service-account-token | 服务账号令牌 |
| kubernetes.io/dockercfg | ~/.dockercfg 文件的序列化形式 |
| kubernetes.io/dockerconfigjson | ~/.docker/config.json 文件的序列化形式 |
| kubernetes.io/basic-auth | 用于基本身份认证的凭据 |
| kubernetes.io/ssh-auth | 用于 SSH 身份认证的凭据 |
| kubernetes.io/tls | 用于 TLS 客户端或者服务器端的数据 |
| bootstrap.kubernetes.io/token | 启动引导令牌数据 |
通过为Secret对象的type字段设置一个非空的字符串值,也可以定义并使用自己的Secret类型。如果type值为空字符串,则被视为Opaque类型。Kubernetes并不对类型的名称作任何限制。如果使用内置类型, 必须满足为该类型定义的所有要求。
如果要定义一种公开使用的Secret类型,需要遵守Secret类型的约定和结构,在类型名签名添加域名,并用 / 隔开。 例如:cloud-hosting.example.net/cloud-api-credentials。
更多内容参考:https://kubernetes.io/zh/docs/concepts/configuration/secret/#secret-types
创建
Secret的创建可以使用以下几种形式:
- 使用kubectl命令来创建
- 基于配置文件来创建
- 使用kustomize来创建
下面主要介绍前两种创建Secret的方式,第三种可以参考官方文档。
- 基于Kubectl创建
一个Secret可以包含Pod访问数据库所需的用户凭证。例如由用户名和密码组成的数据库连接字符串,可以在本地计算机上,将用户名存储在文件 ./username.txt 中,将密码存储在文件 ./password.txt 中。
echo -n 'admin' > ./username.txt
echo -n '1f2d1e2e67df' > ./password.txt命令中,-n标志确保生成的文件在文本末尾不包含额外的换行符。当kubectl读取文件并将内容编码为base64字符串时,多余的换行符也会被编码。
使用命令将这些文件打包成一个Secret并在apiserver上创建对象。
# 执行命令
kubectl create secret generic db-user-pass \
--from-file=./username.txt \
--from-file=./password.txt
# 输出
secret/db-user-pass created默认密钥名称是文件名,可以选择使用--from-file=[key=]source设置密钥名称
kubectl create secret generic db-user-pass \
--from-file=username=./username.txt \
--from-file=password=./password.txt不需要对文件中包含的密码字符串中的特殊字符进行转义。使用--from-literal= = 标签提供Secret数据,可以多次使用此标签,提供多个键值对。特殊字符(例如: \(,\,*,= 和 !)由所使用shell解释执行,而且需要转义。 大多数shell中,转义密码最简便的方法是用单引号括起来。如果密码是S!B\*d\)zDsb=,可以如下执行命令:
kubectl create secret generic db-user-pass \
--from-literal=username=devuser \
--from-literal=password='S!B\*d$zDsb='查看secret是否已创建:
kubectl get secrets
# 输出
NAME TYPE DATA AGE
db-user-pass Opaque 2 51s查看Secret的描述:
kubectl describe secrets/db-user-pass
# 输出
Name: db-user-pass
Namespace: default
Labels: <none>
Annotations: <none>
Type: Opaque
Data
====
password: 12 bytes
username: 5 byteskubectl get和kubectl describe命令默认不显示Secret的内容,防止Secret被意外暴露或存储在终端日志中。要查看创建的Secret的内容,运行以下命令:
kubectl get secret db-user-pass -o jsonpath='{.data}'
# 输出结果
{"password":"MWYyZDFlMmU2N2Rm","username":"YWRtaW4="}使用base64解码password的数据:
echo 'MWYyZDFlMmU2N2Rm' | base64 --decode
# 输出结果
1f2d1e2e67df删除创建的Secret:
kubectl delete secret db-user-pass- 基于配置文件创建
使用配置文件,可以先用JSON或YAML格式在文件中创建Secret,然后创建该对象。Secret资源包含2个键值对,data和stringData。data字段用来存储base64编码的任意数据,提供stringData字段是为了方便,它允许Secret使用未编码的字符串。data和stringData的键必须由字母、数字、-,_ 或 . 组成。例如,要使用Secret的data字段存储两个字符串,需先将字符串转换为base64 ,如下所示:
echo -n 'admin' | base64
YWRtaW4=
echo -n '1f2d1e2e67df' | base64
MWYyZDFlMmU2N2Rm编写一个Secret配置文件,如下所示:
apiVersion: v1
kind: Secret
metadata:
name: mysecret
type: Opaque
data:
username: YWRtaW4=
password: MWYyZDFlMmU2N2Rm说明:Secret对象的名称必须是有效的DNS子域名。Secret数据的JSON和YAML序列化结果是以base64编码的。换行符在这些字符串中无效,必须省略。在Darwin/macOS上使用base64工具时,用户不应该使用-b选项分割长行。Linux用户应该在base64地命令中添加-w 0选项,或者在-w选项不可用的情况下,输入base64 | tr -d '\n'。
对于某些场景,可能希望使用stringData字段,可以将一个非base64编码的字符串直接放入Secret中,当创建或更新该Secret时,此字段将被编码。
上述用例的实际场景可能为:当部署应用时,使用Secret存储配置文件,希望在部署过程中,填入部分内容到该配置文件。例如,应用程序使用以下配置文件:
apiUrl: "https://my.api.com/api/v1"
username: "<user>"
password: "<password>"可以使用以下定义将其存储在Secret中:
apiVersion: v1
kind: Secret
metadata:
name: mysecret
type: Opaque
stringData:
config.yaml: |
apiUrl: "https://my.api.com/api/v1"
username: <user>
password: <password>然后使用kubectl apply命令创建Secret:
kubectl apply -f ./secret.yaml
# 输出结果
secret/mysecret createdstringData字段是只写的,获取Secret时,此字段永远不会输出。 例如,运行以下命令:
kubectl get secret mysecret -o yaml
# 输出结果 yaml格式
apiVersion: v1
data:
config.yaml: YXBpVXJsOiAiaHR0cHM6Ly9teS5hcGkuY29tL2FwaS92MSIKdXNlcm5hbWU6IHt7dXNlcm5hbWV9fQpwYXNzd29yZDoge3twYXNzd29yZH19
kind: Secret
metadata:
creationTimestamp: 2018-11-15T20:40:59Z
name: mysecret
namespace: default
resourceVersion: "7225"
uid: c280ad2e-e916-11e8-98f2-025000000001
type: Opaque命令kubectl get和kubectl describe默认不显示Secret的内容。防止Secret意外地暴露给旁观者或者保存在终端日志中。如果在data和stringData中都指定了一个字段,例如username,字段值为stringData,如下Secret定义:
apiVersion: v1
kind: Secret
metadata:
name: mysecret
type: Opaque
data:
username: YWRtaW4=
stringData:
username: administrator输出结果生成以下Secret:
apiVersion: v1
data:
username: YWRtaW5pc3RyYXRvcg== # 其中 YWRtaW5pc3RyYXRvcg== 解码成administrator。
kind: Secret
metadata:
creationTimestamp: 2018-11-15T20:46:46Z
name: mysecret
namespace: default
resourceVersion: "7579"
uid: 91460ecb-e917-11e8-98f2-025000000001
type: Opaque使用
Secret可以以数据卷的形式挂载,也可以作为环境变量暴露给Pod中的容器使用。Secret也可用于系统中的其他部分,而不是一定要直接暴露给Pod,比如包含系统中其他部分在与外部系统交互时需要的凭证数据。Kubernetes控制平面也使用Secret,例如引导令牌Secret是一种帮助自动化节点注册的机制:
- 在Pod中以文件形式使用
- 以环境变量形式使用
- 在静态Pod使用
- 容器镜像拉取使用
说明:Kubernetes会检查Secret的卷数据源,确保所指定的对象引用确实指向类型为Secret的对象。如果Pod依赖于某Secret,该Secret必须先于Pod被创建。
如果Secret内容无法取回(可能因为Secret尚不存在或者临时性地出现apiserver网络连接问题),kubelet会周期性地重试Pod运行操作。kubelet也会为该Pod报告Event事件,给出读取Secret时遇到的问题细节。
详细内容:https://kubernetes.io/zh/docs/concepts/configuration/secret/#working-with-secrets
参考资料:















 2480
2480











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











