







转载于https://blog.csdn.net/qq_32641659/article/details/87912452
1、hdfs的web界面介绍
1.1、访问地址:http://ip:50070,默认是50070端口

1.2tab页功能介绍
overview:显示概要信息,关注度较高,主要关注如红色圈信息

datanodes:显示所有datanode节点信息,关注度一般
Datanode Volume Failures:失败的数据节点卷,关注度低
snapshot: 快照,关注度低
startup progress:启动的过程,关注度低
Utilities Browse the file system : 显示hdfs文件目录结构以及文件的详细信息,关注度高

Utilities logs :hadoop进程日志信息,出现问题时,需要查询日志,关注度一般
2、yarn的web界面介绍
2.1、访问地址:http://ip:8088,默认是8088端口
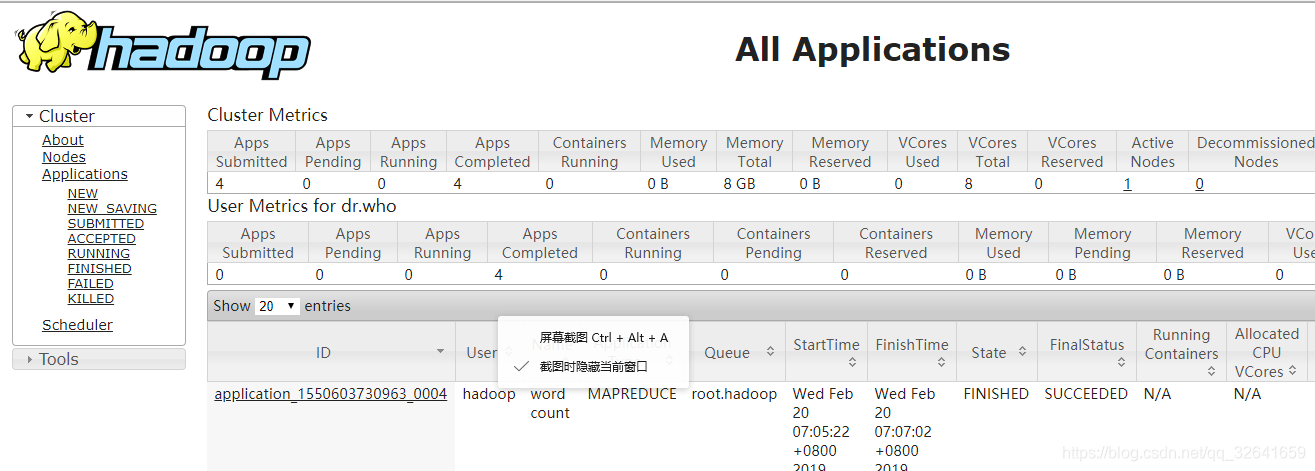
2.2 作业调度信息介绍
1)首先 我提交一个wordcout作业,案列代码使用的是hadoop安装包自带的jar
hadoop jar ~/app/hadoop-2.6.0-cdh5.7.0/share/hadoop/mapreduce2/hadoop-mapreduce-examples-2.6.0-cdh5.7.0.jar wordcount /wordcount/inputdata /wordcount/outputdata52)此时yarn界面会出现一个作业编号为1550603730963_0005的作业详细信息
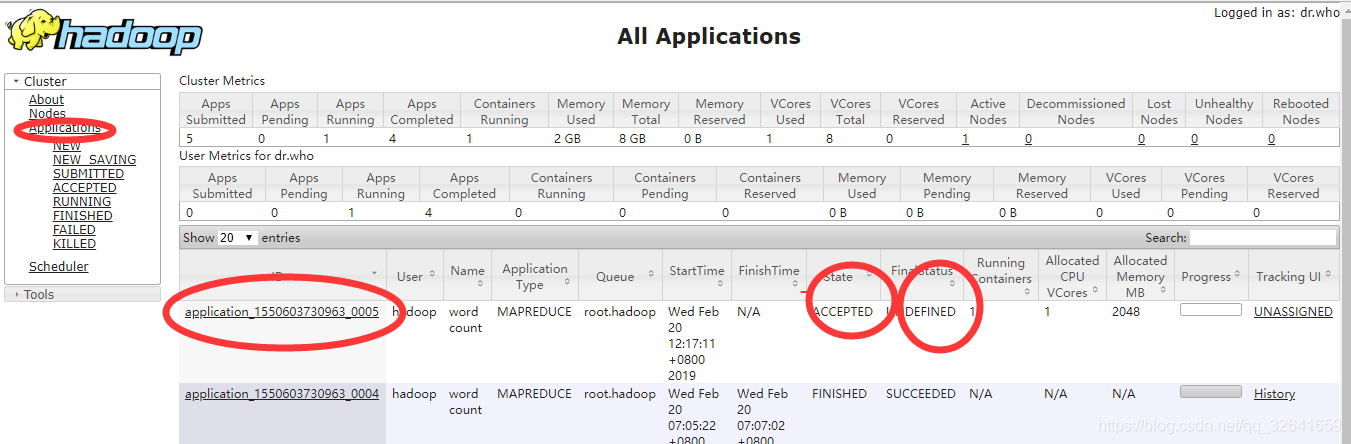
-
id:作业编号 -
queue:作业所处队列名称 -
stata:当前作业状态 -
finalstatus:作业最终状态 -
running container:运行的container数量 -
allocated cpu vcores:分配的逻辑CPU数 -
allocate memeory :分配的内存大小 -
progress: 作业处理的进程,百分比 -
tracking ui : history ,需要开启history服务才可查询。application master 点击显示作业详细信息,如map以及reduce数
3)作业日志查看:可在点击具体作业后 点击log连接,当作业出现问题,是可以查询日志快速定位

2.3 yarn信息介绍
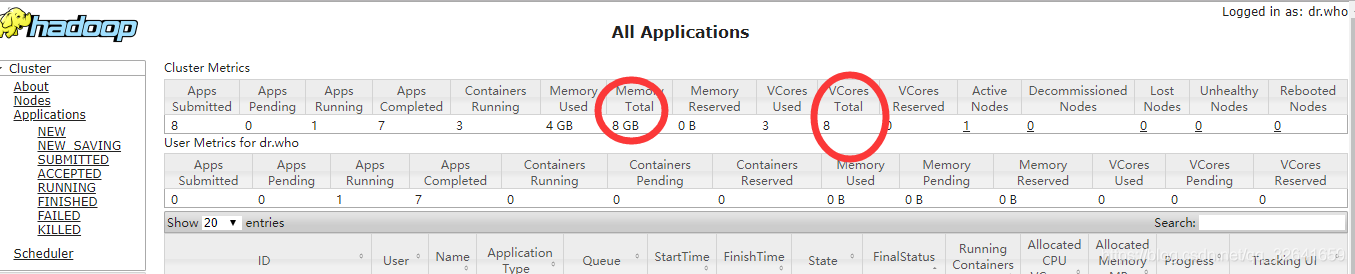 红圈分别代表当前yarn所有拥有的资源:8G的内存,8个逻辑cpu。
红圈分别代表当前yarn所有拥有的资源:8G的内存,8个逻辑cpu。














 5860
5860











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









