







 Zookeeper是一个开源的分布式协调服务,提供统一配置管理、统一命名服务、分布式锁和集群管理等功能。其数据结构类似Unix文件系统,由Znode节点组成,分为持久和临时节点。选举机制采用半数机制,确保集群可用性。ZAB协议保证数据一致性和命令全局有序性,通过监听器实现节点变化的实时响应。Zookeeper适用于分布式系统中的配置管理、命名服务、分布式锁和集群状态管理等场景。安装部署包括单机和分布式模式,集群至少需要3台机器。
Zookeeper是一个开源的分布式协调服务,提供统一配置管理、统一命名服务、分布式锁和集群管理等功能。其数据结构类似Unix文件系统,由Znode节点组成,分为持久和临时节点。选举机制采用半数机制,确保集群可用性。ZAB协议保证数据一致性和命令全局有序性,通过监听器实现节点变化的实时响应。Zookeeper适用于分布式系统中的配置管理、命名服务、分布式锁和集群状态管理等场景。安装部署包括单机和分布式模式,集群至少需要3台机器。
什么是zk
1. 基本概念
-
1)总结
– ZooKeeper主要服务于分布式系统,可以用ZooKeeper来做:统一配置管理、统一命名服务、分布式锁、集群管理。
– 使用分布式系统就无法避免对节点管理的问题(需要实时感知节点的状态、对节点进行统一管理等等),而由于这些问题处理起来可能相对麻烦和提高了系统的复杂性,ZooKeeper作为一个能够通用解决这些问题的中间件就应运而生了。 -
2)数据结构
ZooKeeper的数据结构,跟Unix文件系统非常类似,可以看做是一颗树,每个节点叫做ZNode。每一个节点可以通过路径来标识,结构图如下:
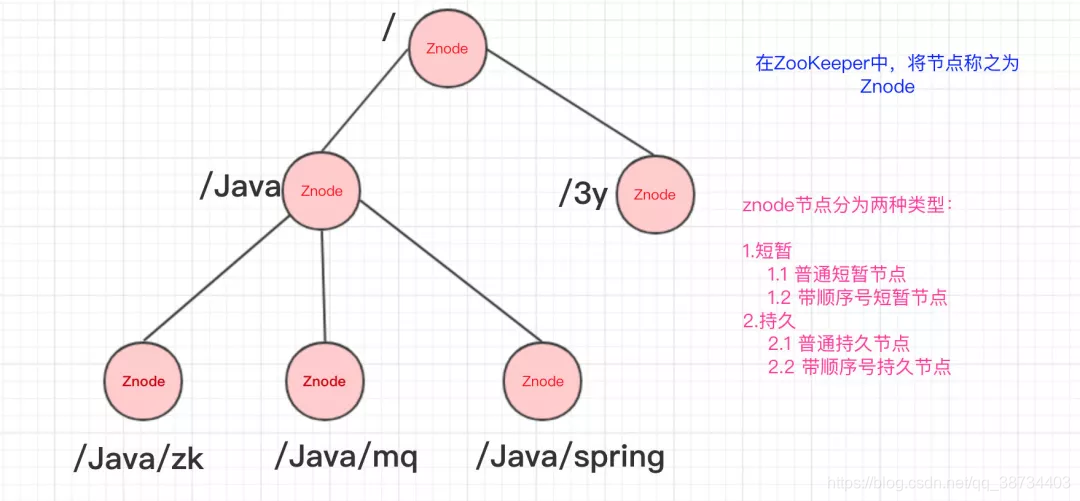
-
3)Znode分为两种类型:
– 短暂/临时(Ephemeral):当客户端和服务端断开连接后,所创建的Znode(节点)会自动删除
– 持久(Persistent):当客户端和服务端断开连接后,所创建的Znode(节点)不会删除 -
4)ZooKeeper和Redis一样,也是C/S结构(分成客户端和服务端)
2. 监听器
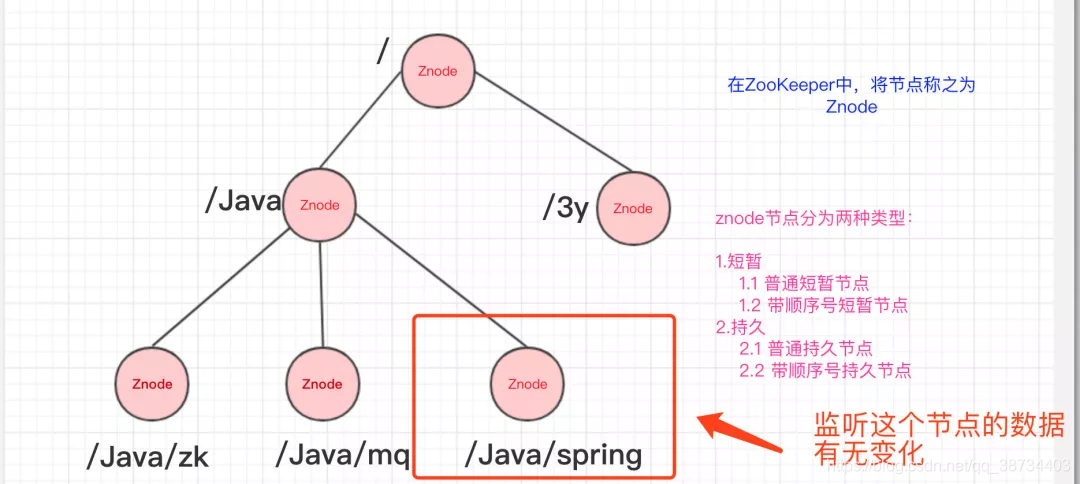
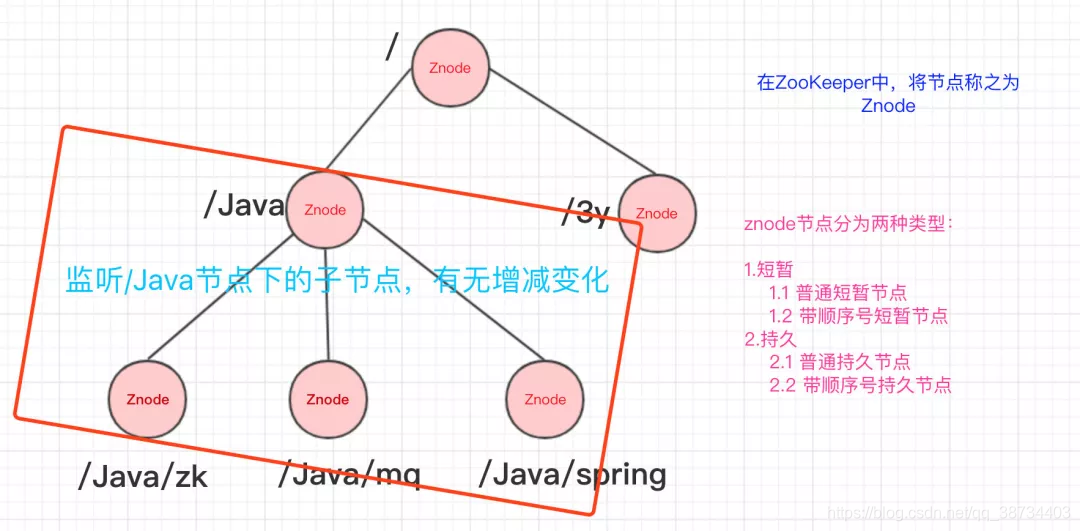
- 常见的监听场景有以下两项:
– 监听Znode节点的数据变化
– 监听子节点的增减变化
3. zk功能实现
- 监听+Znode节点(持久/短暂[临时])–实现多种功能
- ZooKeeper怎么来做:统一配置管理、统一命名服务、分布式锁、集群管理。
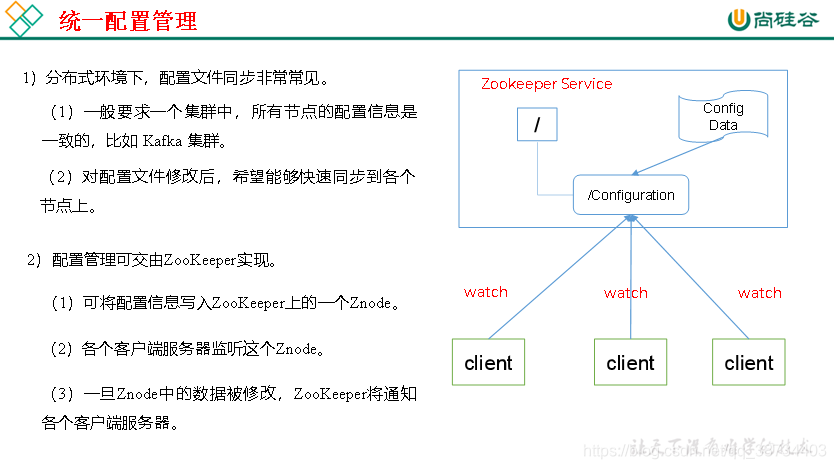
3.1 统一配置管理
-
1 需求分析
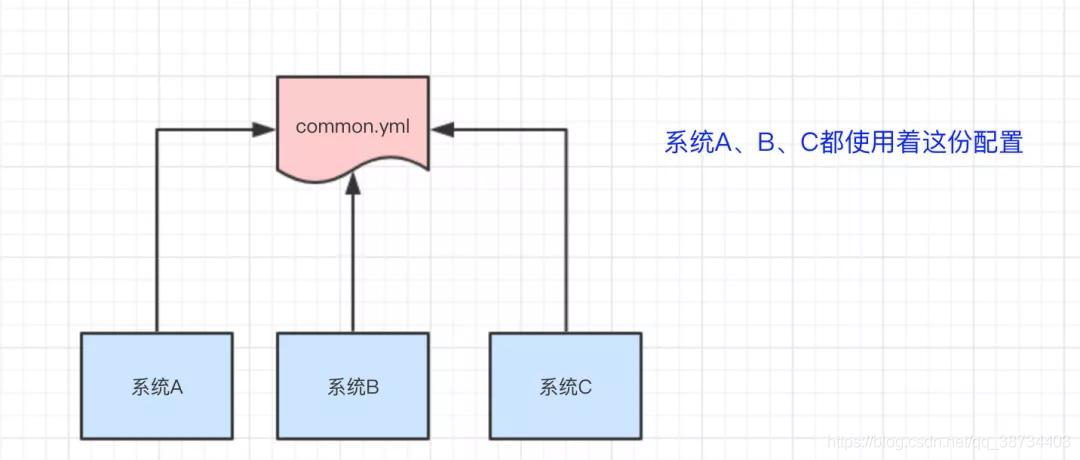
– 比如我们现在有三个系统A、B、C,他们有三份配置,分别是ASystem.yml、BSystem.yml、CSystem.yml,然后,这三份配置又非常类似,很多的配置项几乎都一样。
– 此时,如果我们要改变其中一份配置项的信息,很可能其他两份都要改。并且,改变了配置项的信息很可能就要重启系统
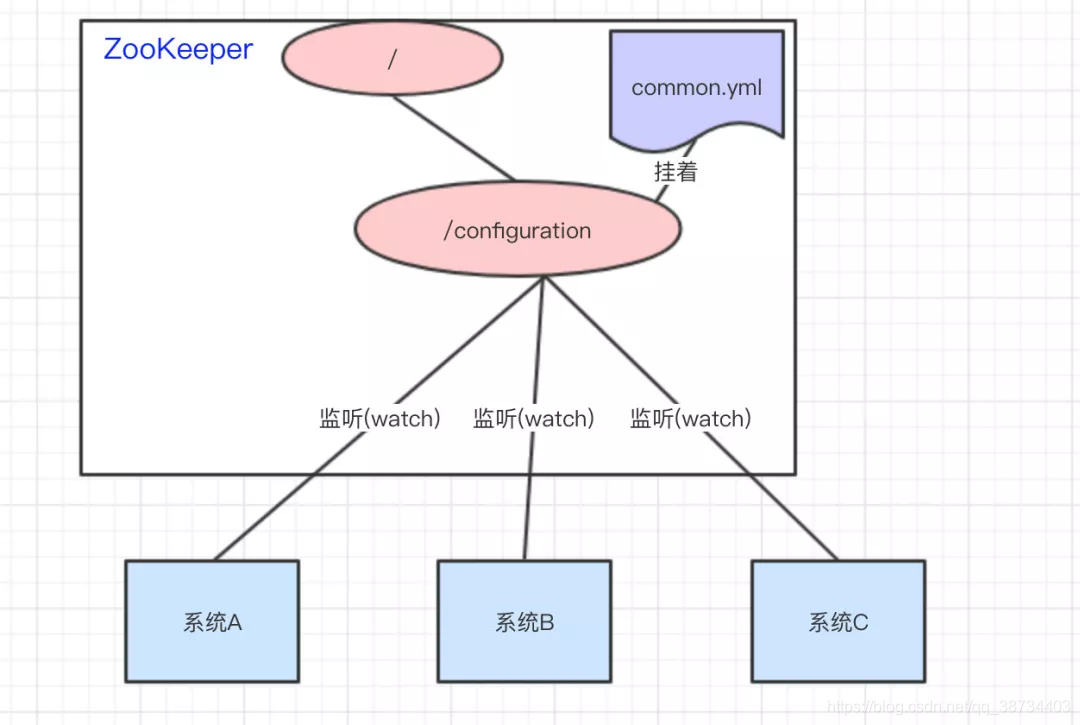
–于是,我们希望把ASystem.yml、BSystem.yml、CSystem.yml相同的配置项抽取出来成一份公用的配置common.yml,并且即便common.yml改了,也不需要系统A、B、C重启。
-
2 实现
将common.yml这份配置放在ZooKeeper的Znode节点中,系统A、B、C监听着这个Znode节点有无变更,如果变更了,及时响应。
3.2 统一命名服务
- 1)需求分析
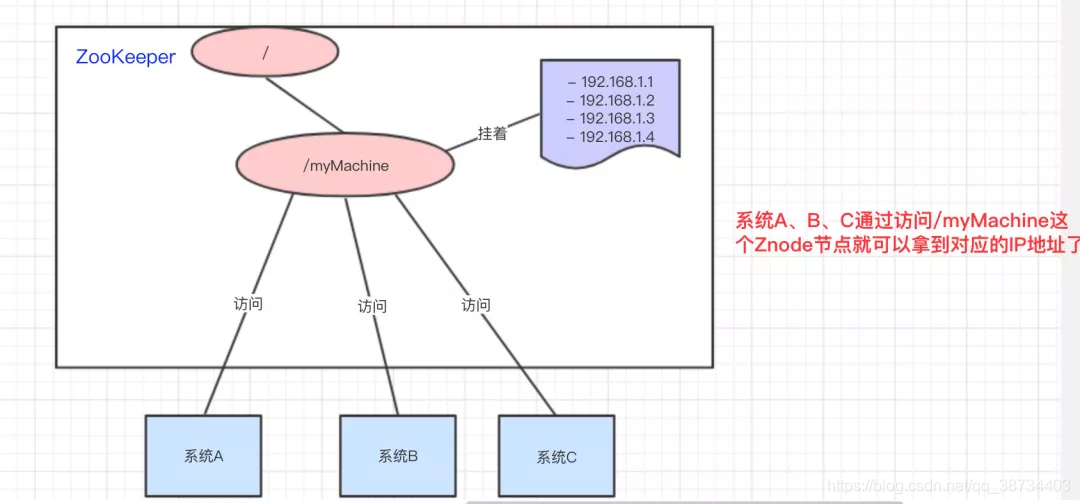
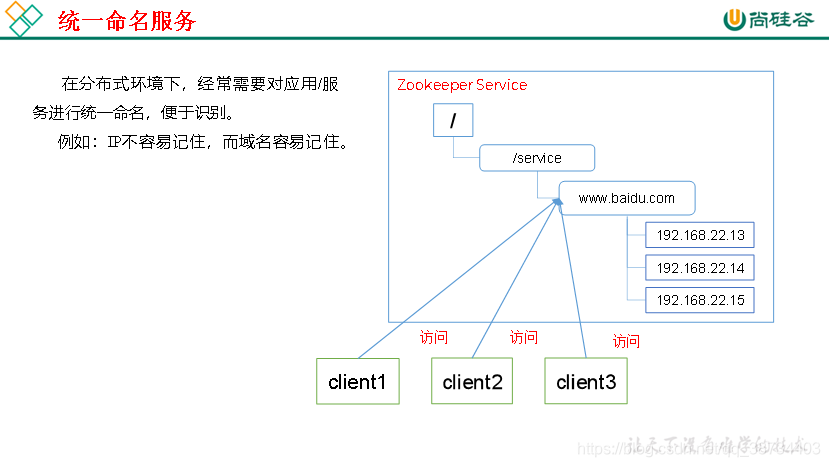
– 统一命名服务的理解其实跟域名一样,是我们为这某一部分的资源给它取一个名字,别人通过这个名字就可以拿到对应的资源。
– 比如说,现在我有一个域名www.java3y.com,但我这个域名下有多台机器:
192.168.1.1
192.168.1.2
192.168.1.3
192.168.1.4
– 别人访问www.java3y.com即可访问到我的机器,而不是通过IP去访问。
3.3 分布式锁
- 1)需求
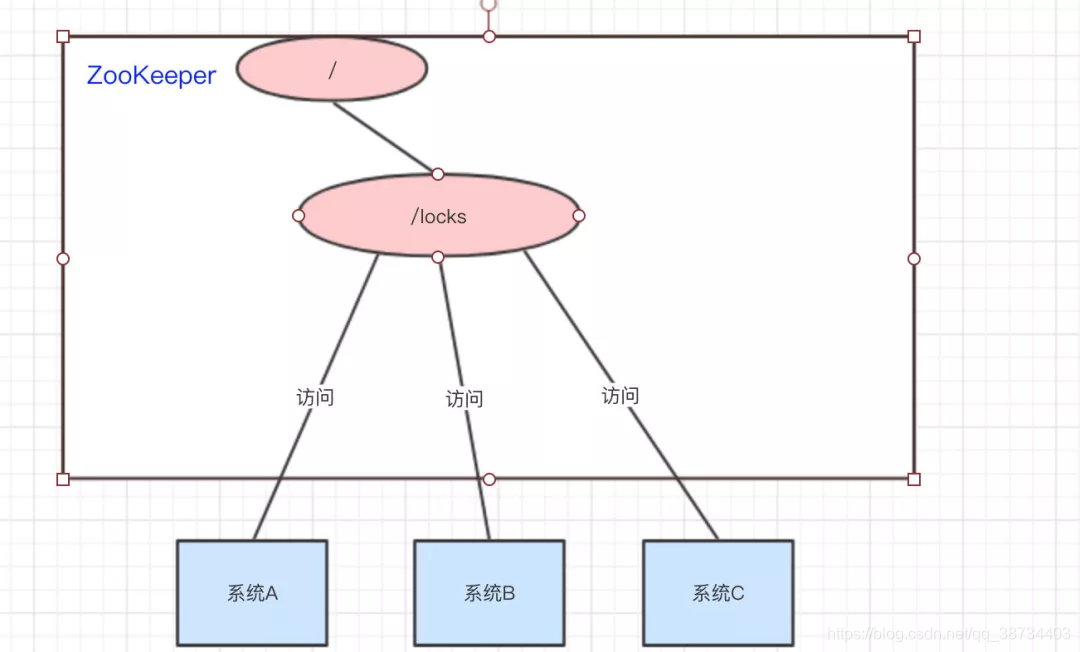
可以使用ZooKeeper来实现分布式锁,那是怎么做的呢??下面来看看: - 2)实现
– 系统A、B、C都去访问/locks节点
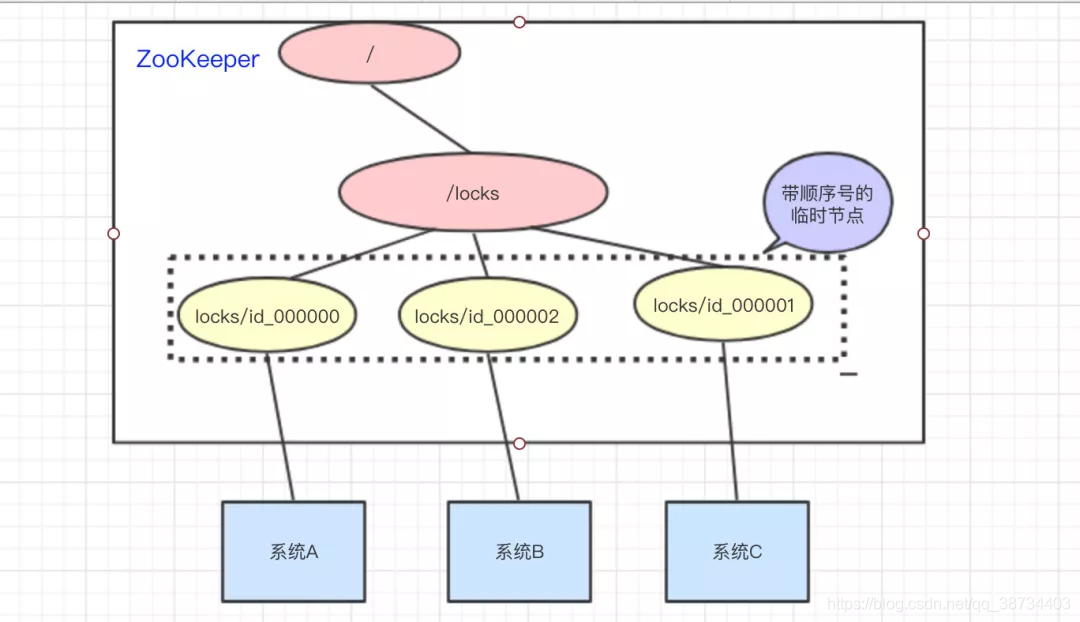
– 访问的时候会创建带顺序号的临时/短暂(EPHEMERAL_SEQUENTIAL)节点,比如,系统A创建了id_000000节点,系统B创建了id_000002节点,系统C创建了id_000001节点。
– 拿到/locks节点下的所有子节点(id_000000,id_000001,id_000002),判断自己创建的是不是最小的那个节点
a. 如果是,则拿到锁。
释放锁:执行完操作后,把创建的节点给删掉
b. 如果不是,则监听比自己要小1的节点变化
- 3)例子
举个例子:
– 系统A拿到/locks节点下的所有子节点,经过比较,发现自己(id_000000),是所有子节点最小的。所以得到锁
– 系统B拿到/locks节点下的所有子节点,经过比较,发现自己(id_000002),不是所有子节点最小的。所以监听比自己小1的节点id_000001的状态
– 系统C拿到/locks节点下的所有子节点,经过比较,发现自己(id_000001),不是所有子节点最小的。所以监听比自己小1的节点id_000000的状态
……
– 等到系统A执行完操作以后,将自己创建的节点删除(id_000000)。通过监听,系统C发现id_000000节点已经删除了,发现自己已经是最小的节点了,于是顺利拿到锁
– ….系统B如上
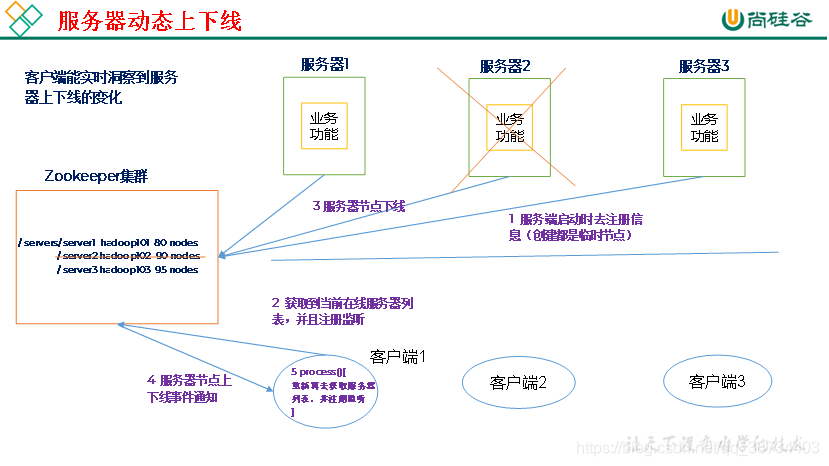
3.4 集群状态
- 1)需求问题
- ZooKeeper是怎么"感知"节点的动态新增或者删除的;
- 2)例子
以我们三个系统A、B、C为例,在ZooKeeper中创建临时节点即可:
– 只要系统A挂了,那 /groupMember/A 这个节点就会删除,通过 监听groupMember 下的子节点,系统B和C就能够感知到系统A已经挂了。(新增也是同理)
– 除了能够感知节点的上下线变化,ZooKeeper还可以实现 动态选举Master 的功能。(如果集群是主从架构模式下)
– 原理:
原理也很简单,如果想要实现动态选举Master的功能,Znode节点的类型是带顺序号的临时节点(EPHEMERAL_SEQUENTIAL)就好了。Zookeeper会每次选举最小编号的作为Master,如果Master挂了,自然对应的Znode节点就会删除。然后让新的最小编号作为Master,这样就可以实现动态选举的功能了。
1 zk介绍
1.1概述
Zookeeper是一个开源的分布式的,为分布式应用提供协调服务的Apache项目。
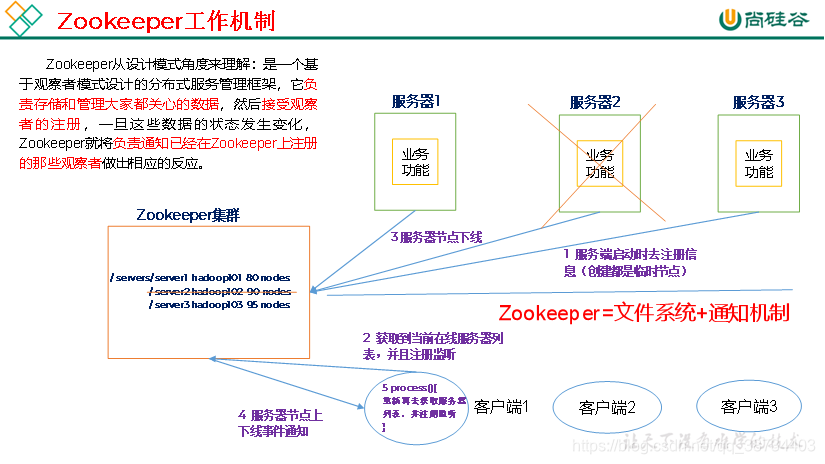
1.2 特点
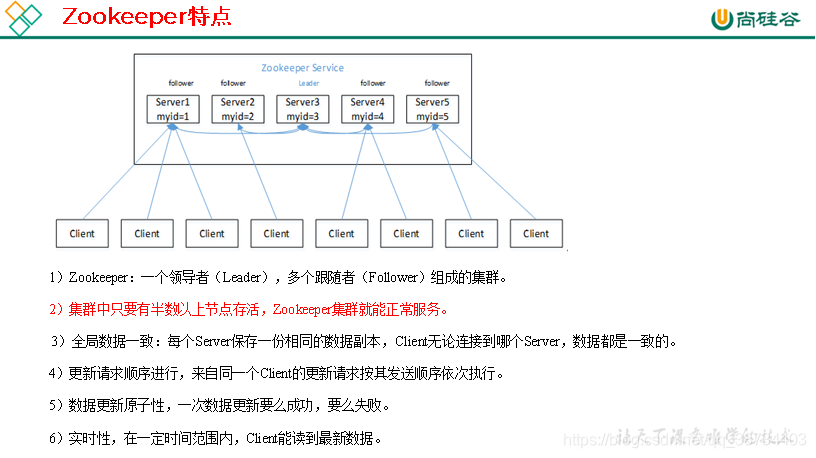
1.3 数据结构
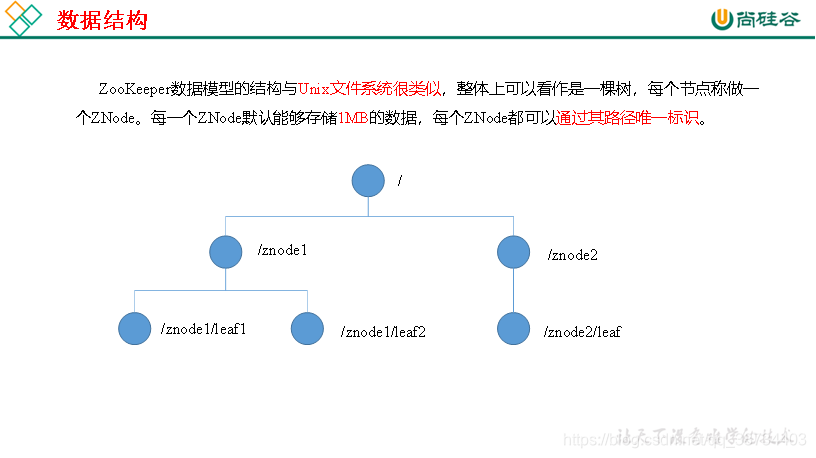
1.4 应用场景
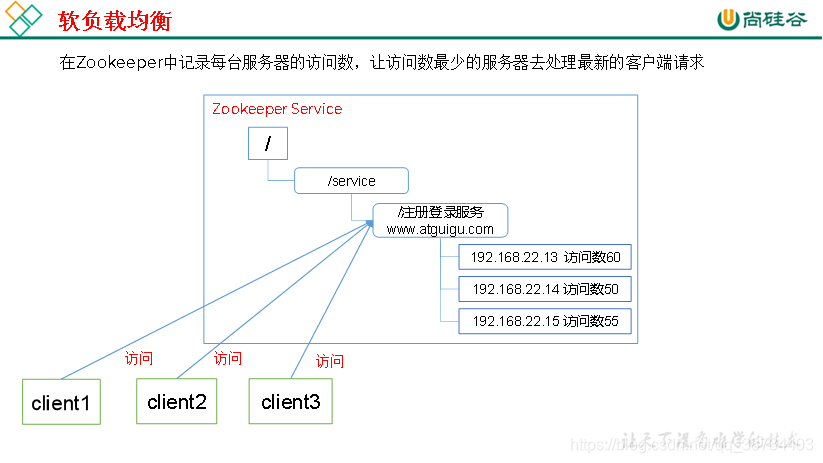
提供的服务包括:统一命名服务、统一配置管理、统一集群管理、服务器节点动态上下线、软负载均衡等。
2 zk内部原理
2.1 选举机制(重点)
-
1 选举机制
1)半数机制:集群中半数以上机器存活,集群可用。所以Zookeeper适合安装奇数台服务器。
2)Zookeeper虽然在配置文件中并没有指定Master和Slave。但是,Zookeeper工作时,是有一个节点为Leader,其他则为Follower,Leader是通过内部的选举机制临时产生的。
3)以一个简单的例子来说明整个选举的过程。 -
2 初次上线的选举例子
假设有五台服务器组成的Zookeeper集群,它们的id从1-5,同时它们都是最新启动的,也就是没有历史数据,在存放数据量这一点上,都是一样的。假设这些服务器依序启动,来看看会发生什么,如图5-8所示。
(1)服务器1启动,此时只有它一台服务器启动了,它发出去的报文没有任何响应,所以它的选举状态一直是LOOKING状态。
(2)服务器2启动,它与最开始启动的服务器1进行通信,互相交换自己的选举结果,由于两者都没有历史数据,所以id值较大的服务器2胜出,但是由于没有达到超过半数以上的服务器都同意选举它(这个例子中的半数以上是3),所以服务器1、2还是继续保持LOOKING状态。
(3)服务器3启动,根据前面的理论分析,服务器3成为服务器1、2、3中的老大,而与上面不同的是,此时有三台服务器选举了它,所以它成为了这次选举的Leader。
(4)服务器4启动,根据前面的分析,理论上服务器4应该是服务器1、2、3、4中最大的,但是由于前面已经有半数以上的服务器选举了服务器3,所以它只能接收当小弟的命了。
(5)服务器5启动,同4一样当小弟。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2054
2054

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









