







MedicalNet 3D Resnet预训练分割网络 代码详解
MedicalNet
这个代码也是医疗任务中比较出名的了 ,github上的star有1.4k. 作者也提供了许多预训练网络参数,我们可以将其应用到不同的医学任务上。
github代码: MedicalNet
数据集作者也给出了下载方式
这里,我修改了代码许多使用方式,以便我们可以将我们需要用到的部分直接应用到我们自己的项目中
参数设置
我们先看一下作者默认的参数设置(同时也是训练时使用的参数),方便我们改写函数
# arg_test.py
from setting import parse_opts
if __name__ == '__main__':
# settting
sets = parse_opts()
print('--------args----------')
for k in list(vars(sets).keys()):
print('%s: %s' % (k, vars(sets)[k]))
print('--------args----------\n')
if sets.ci_test:
sets.img_list = './toy_data/test_ci.txt'
sets.n_epochs = 1
sets.no_cuda = True
sets.data_root = './toy_data'
sets.pretrain_path = ''
sets.num_workers = 0
sets.model_depth = 10
sets.resnet_shortcut = 'A'
sets.input_D = 14
sets.input_H = 28
sets.input_W = 28
! python arg_test.py -h
usage: arg_test.py [-h] [--data_root DATA_ROOT] [--img_list IMG_LIST]
[--n_seg_classes N_SEG_CLASSES]
[--learning_rate LEARNING_RATE] [--num_workers NUM_WORKERS]
[--batch_size BATCH_SIZE] [--phase PHASE]
[--save_intervals SAVE_INTERVALS] [--n_epochs N_EPOCHS]
[--input_D INPUT_D] [--input_H INPUT_H] [--input_W INPUT_W]
[--resume_path RESUME_PATH] [--pretrain_path PRETRAIN_PATH]
[--new_layer_names NEW_LAYER_NAMES] [--no_cuda]
[--gpu_id GPU_ID [GPU_ID ...]] [--model MODEL]
[--model_depth MODEL_DEPTH]
[--resnet_shortcut RESNET_SHORTCUT]
[--manual_seed MANUAL_SEED] [--ci_test]
optional arguments:
-h, --help show this help message and exit
--data_root DATA_ROOT
Root directory path of data
--img_list IMG_LIST Path for image list file
--n_seg_classes N_SEG_CLASSES
Number of segmentation classes
--learning_rate LEARNING_RATE
Initial learning rate (divided by 10 while training by
lr scheduler)
--num_workers NUM_WORKERS
Number of jobs
--batch_size BATCH_SIZE
Batch Size
--phase PHASE Phase of train or test
--save_intervals SAVE_INTERVALS
Interation for saving model
--n_epochs N_EPOCHS Number of total epochs to run
--input_D INPUT_D Input size of depth
--input_H INPUT_H Input size of height
--input_W INPUT_W Input size of width
--resume_path RESUME_PATH
Path for resume model.
--pretrain_path PRETRAIN_PATH
Path for pretrained model.
--new_layer_names NEW_LAYER_NAMES
New layer except for backbone
--no_cuda If true, cuda is not used.
--gpu_id GPU_ID [GPU_ID ...]
Gpu id lists
--model MODEL (resnet | preresnet | wideresnet | resnext | densenet
|
--model_depth MODEL_DEPTH
Depth of resnet (10 | 18 | 34 | 50 | 101)
--resnet_shortcut RESNET_SHORTCUT
Shortcut type of resnet (A | B)
--manual_seed MANUAL_SEED
Manually set random seed
--ci_test If true, ci testing is used.
训练时用到的参数,不使用分布式训练
! python arg_test.py --gpu_id 0 # single-gpu training on gpu 0
--------args----------
data_root: ./data
img_list: ./data/train.txt
n_seg_classes: 2
learning_rate: 0.001
num_workers: 4
batch_size: 1
phase: train
save_intervals: 10
n_epochs: 200
input_D: 56
input_H: 448
input_W: 448
resume_path:
pretrain_path: pretrain/resnet_50.pth
new_layer_names: ['conv_seg']
no_cuda: False
gpu_id: [0]
model: resnet
model_depth: 50
resnet_shortcut: B
manual_seed: 1
ci_test: False
save_folder: ./trails/models/resnet_50
--------args----------
分割模型
med3d的模型是使用resnet网络作为编码器,然后后面加上解码器的结构。
这里不对模型每一层的构建做具体分析,而是看一下怎样使用他们
所有网络构建的过程在 /MedicalNet-master/models/resnet.py 中
编码器结构一共有七种 ‘resnet10’, ‘resnet18’, ‘resnet34’, ‘resnet50’, ‘resnet101’, ‘resnet152’, ‘resnet200’
建立模型
import torch
from torch import nn
from models import resnet
model = resnet.resnet50(
sample_input_W=448,
sample_input_H=448,
sample_input_D=56,
shortcut_type='B',
no_cuda=False,
num_seg_classes=2)
print(model)
DataParallel(
(module): ResNet(
(conv1): Conv3d(1, 64, kernel_size=(7, 7, 7), stride=(2, 2, 2), padding=(3, 3, 3), bias=False)
(bn1): BatchNorm3d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(maxpool): MaxPool3d(kernel_size=(3, 3, 3), stride=2, padding=1, dilation=1, ceil_mode=False)
(layer1): Sequential(
(0): Bottleneck(
(conv1): Conv3d(64, 64, kernel_size=(1, 1, 1), stride=(1, 1, 1), bias=False)
(bn1): BatchNorm3d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv3d(64, 64, kernel_size=(3, 3, 3), stride=(1, 1, 1), padding=(1, 1, 1), bias=False)
(bn2): BatchNorm3d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv3d(64, 256, kernel_size=(1, 1, 1), stride=(1, 1, 1), bias=False)
(bn3): BatchNorm3d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(downsample): Sequential(
(0): Conv3d(64, 256, kernel_size=(1, 1, 1), stride=(1, 1, 1), bias=False)
(1): BatchNorm3d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): Bottleneck(
(conv1): Conv3d(256, 64, kernel_size=(1, 1, 1), stride=(1, 1, 1), bias=False)
(bn1): BatchNorm3d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv3d(64, 64, kernel_size=(3, 3, 3), stride=(1, 1, 1), padding=(1, 1, 1), bias=False)
(bn2): BatchNorm3d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv3d(64, 256, kernel_size=(1, 1, 1), stride=(1, 1, 1), bias=False)
(bn3): BatchNorm3d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(2): Bottleneck(
(conv1): Conv3d(256, 64, kernel_size=(1, 1, 1), stride=(1, 1, 1), bias=False)
(bn1): BatchNorm3d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv3d(64, 64, kernel_size=(3, 3, 3), stride=(1, 1, 1), padding=(1, 1, 1), bias=False)
(bn2): BatchNorm3d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv3d(64, 256, kernel_size=(1, 1, 1), stride=(1, 1, 1), bias=False)
(bn3): BatchNorm3d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
)
(layer2): Sequential(
(0): Bottleneck(
(conv1): Conv3d(256, 128, kernel_size=(1, 1, 1), stride=(1, 1, 1), bias=False)
(bn1): BatchNorm3d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv3d(128, 128, kernel_size=(3, 3, 3), stride=(2, 2, 2), padding=(1, 1, 1), bias=False)
(bn2): BatchNorm3d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv3d(128, 512, kernel_size=(1, 1, 1), stride=(1, 1, 1), bias=False)
(bn3): BatchNorm3d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(downsample): Sequential(
(0): Conv3d(256, 512, kernel_size=(1, 1, 1), stride=(2, 2, 2), bias=False)
(1): BatchNorm3d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): Bottleneck(
(conv1): Conv3d(512, 128, kernel_size=(1, 1, 1), stride=(1, 1, 1), bias=False)
(bn1): BatchNorm3d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv3d(128, 128, kernel_size=(3, 3, 3), stride=(1, 1, 1), padding=(1, 1, 1), bias=False)
(bn2): BatchNorm3d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv3d(128, 512, kernel_size=(1, 1, 1), stride=(1, 1, 1), bias=False)
(bn3): BatchNorm3d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(2): Bottleneck(
(conv1): Conv3d(512, 128, kernel_size=(1, 1, 1), stride=(1, 1, 1), bias=False)
(bn1): BatchNorm3d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv3d(128, 128, kernel_size=(3, 3, 3), stride=(1, 1, 1), padding=(1, 1, 1), bias=False)
(bn2): BatchNorm3d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv3d(128, 512, kernel_size=(1, 1, 1), stride=(1, 1, 1), bias=False)
(bn3): BatchNorm3d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(3): Bottleneck(
(conv1): Conv3d(512, 128, kernel_size=(1, 1, 1), stride=(1, 1, 1), bias=False)
(bn1): BatchNorm3d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv3d(128, 128, kernel_size=(3, 3, 3), stride=(1, 1, 1), padding=(1, 1, 1), bias=False)
(bn2): BatchNorm3d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv3d(128, 512, kernel_size=(1, 1, 1), stride=(1, 1, 1), bias=False)
(bn3): BatchNorm3d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
)
(layer3): Sequential(
(0): Bottleneck(
(conv1): Conv3d(512, 256, kernel_size=(1, 1, 1), stride=(1, 1, 1), bias=False)
(bn1): BatchNorm3d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv3d(256, 256, kernel_size=(3, 3, 3), stride=(1, 1, 1), padding=(2, 2, 2), dilation=(2, 2, 2), bias=False)
(bn2): BatchNorm3d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv3d(256, 1024, kernel_size=(1, 1, 1), stride=(1, 1, 1), bias=False)
(bn3): BatchNorm3d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(downsample): Sequential(
(0): Conv3d(512, 1024, kernel_size=(1, 1, 1), stride=(1, 1, 1), bias=False)
(1): BatchNorm3d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): Bottleneck(
(conv1): Conv3d(1024, 256, kernel_size=(1, 1, 1), stride=(1, 1, 1), bias=False)
(bn1): BatchNorm3d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv3d(256, 256, kernel_size=(3, 3, 3), stride=(1, 1, 1), padding=(2, 2, 2), dilation=(2, 2, 2), bias=False)
(bn2): BatchNorm3d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv3d(256, 1024, kernel_size=(1, 1, 1), stride=(1, 1, 1), bias=False)
(bn3): BatchNorm3d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(2): Bottleneck(
(conv1): Conv3d(1024, 256, kernel_size=(1, 1, 1), stride=(1, 1, 1), bias=False)
(bn1): BatchNorm3d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv3d(256, 256, kernel_size=(3, 3, 3), stride=(1, 1, 1), padding=(2, 2, 2), dilation=(2, 2, 2), bias=False)
(bn2): BatchNorm3d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv3d(256, 1024, kernel_size=(1, 1, 1), stride=(1, 1, 1), bias=False)
(bn3): BatchNorm3d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(3): Bottleneck(
(conv1): Conv3d(1024, 256, kernel_size=(1, 1, 1), stride=(1, 1, 1), bias=False)
(bn1): BatchNorm3d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv3d(256, 256, kernel_size=(3, 3, 3), stride=(1, 1, 1), padding=(2, 2, 2), dilation=(2, 2, 2), bias=False)
(bn2): BatchNorm3d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv3d(256, 1024, kernel_size=(1, 1, 1), stride=(1, 1, 1), bias=False)
(bn3): BatchNorm3d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(4): Bottleneck(
(conv1): Conv3d(1024, 256, kernel_size=(1, 1, 1), stride=(1, 1, 1), bias=False)
(bn1): BatchNorm3d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv3d(256, 256, kernel_size=(3, 3, 3), stride=(1, 1, 1), padding=(2, 2, 2), dilation=(2, 2, 2), bias=False)
(bn2): BatchNorm3d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv3d(256, 1024, kernel_size=(1, 1, 1), stride=(1, 1, 1), bias=False)
(bn3): BatchNorm3d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(5): Bottleneck(
(conv1): Conv3d(1024, 256, kernel_size=(1, 1, 1), stride=(1, 1, 1), bias=False)
(bn1): BatchNorm3d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv3d(256, 256, kernel_size=(3, 3, 3), stride=(1, 1, 1), padding=(2, 2, 2), dilation=(2, 2, 2), bias=False)
(bn2): BatchNorm3d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv3d(256, 1024, kernel_size=(1, 1, 1), stride=(1, 1, 1), bias=False)
(bn3): BatchNorm3d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
)
(layer4): Sequential(
(0): Bottleneck(
(conv1): Conv3d(1024, 512, kernel_size=(1, 1, 1), stride=(1, 1, 1), bias=False)
(bn1): BatchNorm3d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv3d(512, 512, kernel_size=(3, 3, 3), stride=(1, 1, 1), padding=(4, 4, 4), dilation=(4, 4, 4), bias=False)
(bn2): BatchNorm3d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv3d(512, 2048, kernel_size=(1, 1, 1), stride=(1, 1, 1), bias=False)
(bn3): BatchNorm3d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(downsample): Sequential(
(0): Conv3d(1024, 2048, kernel_size=(1, 1, 1), stride=(1, 1, 1), bias=False)
(1): BatchNorm3d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): Bottleneck(
(conv1): Conv3d(2048, 512, kernel_size=(1, 1, 1), stride=(1, 1, 1), bias=False)
(bn1): BatchNorm3d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv3d(512, 512, kernel_size=(3, 3, 3), stride=(1, 1, 1), padding=(4, 4, 4), dilation=(4, 4, 4), bias=False)
(bn2): BatchNorm3d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv3d(512, 2048, kernel_size=(1, 1, 1), stride=(1, 1, 1), bias=False)
(bn3): BatchNorm3d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(2): Bottleneck(
(conv1): Conv3d(2048, 512, kernel_size=(1, 1, 1), stride=(1, 1, 1), bias=False)
(bn1): BatchNorm3d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv3d(512, 512, kernel_size=(3, 3, 3), stride=(1, 1, 1), padding=(4, 4, 4), dilation=(4, 4, 4), bias=False)
(bn2): BatchNorm3d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv3d(512, 2048, kernel_size=(1, 1, 1), stride=(1, 1, 1), bias=False)
(bn3): BatchNorm3d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
)
(conv_seg): Sequential(
(0): ConvTranspose3d(2048, 32, kernel_size=(2, 2, 2), stride=(2, 2, 2))
(1): BatchNorm3d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
(3): Conv3d(32, 32, kernel_size=(3, 3, 3), stride=(1, 1, 1), padding=(1, 1, 1), bias=False)
(4): BatchNorm3d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): ReLU(inplace=True)
(6): Conv3d(32, 2, kernel_size=(1, 1, 1), stride=(1, 1, 1), bias=False)
)
)
)
然后加载预训练模型
import os
os.environ["CUDA_VISIBLE_DEVICES"]=str('[0]')
model = model.cuda()
model = nn.DataParallel(model, device_ids=None)
net_dict = model.state_dict()
对于存在于预训练模型中的层的参数,我们将其提取出来并加载到我们的模型中
print('loading pretrained model {}'.format('./MedicalNet_pytorch_files2/pretrain/resnet_50_23dataset.pth'))
pretrain = torch.load('./MedicalNet_pytorch_files2/pretrain/resnet_50_23dataset.pth')
pretrain_dict = {k: v for k, v in pretrain['state_dict'].items() if k in net_dict.keys()}
# k 是每一层的名称,v是权重数值
net_dict.update(pretrain_dict) #字典 dict2 的键/值对更新到 dict 里。
model.load_state_dict(net_dict) #model.load_state_dict()函数把加载的权重复制到模型的权重中去
因为我们是迁移学习,所以对于这些加载预训练参数的层,我们想要他们的学习小一些,对于最后的分割层,我们想要他们的学习率大一些,所以,我们要找出来最后那些实现分割的解码器部分
for pname, p in model.named_parameters(): #返回各层中参数名称和数据。
for layer_name in ['conv_seg']:
if pname.find(layer_name) >= 0:
print(pname)
module.conv_seg.0.weight
module.conv_seg.0.bias
module.conv_seg.1.weight
module.conv_seg.1.bias
module.conv_seg.3.weight
module.conv_seg.4.weight
module.conv_seg.4.bias
module.conv_seg.6.weight
可以看到这些层正是我们的反卷积层,我们将他们作为new_parameters
new_parameters = []
for pname, p in model.named_parameters(): #返回各层中参数名称和数据。
for layer_name in ['conv_seg']:
if pname.find(layer_name) >= 0:
new_parameters.append(p)
break
new_parameters_id = list(map(id, new_parameters))
base_parameters = list(filter(lambda p: id(p) not in new_parameters_id, model.parameters()))
parameters = {'base_parameters': base_parameters,
'new_parameters': new_parameters}
base_parameters是从全部参数中删除new_parameters之后得到的,这部分的学习率应该小一点
learning_rate = 0.001
params = [
{ 'params': parameters['base_parameters'], 'lr': learning_rate },
{ 'params': parameters['new_parameters'], 'lr': learning_rate*100 }
]
optimizer = torch.optim.SGD(params, momentum=0.9, weight_decay=1e-3)
scheduler = torch.optim.lr_scheduler.ExponentialLR(optimizer, gamma=0.99)
数据读取
在代码中,数据的读取是靠./datasets/brains18.py中的BrainS18Dataset实现的。我们看看它是怎样实现数据读取的
我们的数据信息储存在test文件中,如下图
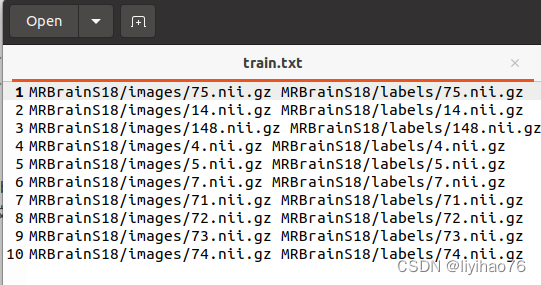
img_list_path = './MedicalNet_pytorch_files2/data/train.txt'
with open(img_list_path, 'r') as f:
img_list = [line.strip() for line in f]
print(img_list)
['MRBrainS18/images/75.nii.gz MRBrainS18/labels/75.nii.gz', 'MRBrainS18/images/14.nii.gz MRBrainS18/labels/14.nii.gz', 'MRBrainS18/images/148.nii.gz MRBrainS18/labels/148.nii.gz', 'MRBrainS18/images/4.nii.gz MRBrainS18/labels/4.nii.gz', 'MRBrainS18/images/5.nii.gz MRBrainS18/labels/5.nii.gz', 'MRBrainS18/images/7.nii.gz MRBrainS18/labels/7.nii.gz', 'MRBrainS18/images/71.nii.gz MRBrainS18/labels/71.nii.gz', 'MRBrainS18/images/72.nii.gz MRBrainS18/labels/72.nii.gz', 'MRBrainS18/images/73.nii.gz MRBrainS18/labels/73.nii.gz', 'MRBrainS18/images/74.nii.gz MRBrainS18/labels/74.nii.gz']
我们通过index随机选择一个病人的数据,其数据和label是用空格隔开的,所以使用split分割。
index = 4
ith_info = img_list[index].split(" ")# 随机病人
img_name = os.path.join(root_dir, ith_info[0]) # 空格之前,数据
label_name = os.path.join(root_dir, ith_info[1]) # 空格之后,label
img = nibabel.load(img_name)
mask = nibabel.load(label_name)
print(img.shape) # (143, 227, 196)
print(mask.shape) # (143, 227, 196)
之后是数据增强的一些列操作,对于训练集,包括 drop out the invalid range, crop data, resize data, normalization datas不再细讲,
对于测试集, resize data 和 normalization datas。最后无论测试集还是训练集,都要转化为通道优先的tensor.float格式。
[z, y, x] = data.shape
new_data = np.reshape(data, [1, z, y, x])
new_data = new_data.astype("float32")
预测
首先我们看一下模型的输出
masks = []
net.eval() # for testing
for batch_id, batch_data in enumerate(data_loader):
volume = batch_data
volume = volume.cuda()
probs = net(volume)
print(probs.shape)
print(probs)
break
./MedicalNet_pytorch_files2/data/MRBrainS18/images/070.nii.gz
./MedicalNet_pytorch_files2/data/MRBrainS18/images/1.nii.gz
torch.Size([1, 2, 14, 112, 112])
tensor([[[[[ 2.3572, 3.2305, 2.5040, ..., 3.3233, 2.6650, 2.4683],
[ 2.5960, 3.7108, 3.5842, ..., 3.8498, 3.8370, 2.4464],
[ 1.9724, 3.8006, 2.9288, ..., 3.9905, 3.1618, 3.4655],
...,
[ 2.2988, 3.2938, 3.1303, ..., 3.5413, 3.5571, 2.2862],
[ 1.7334, 3.4097, 2.5658, ..., 3.7633, 3.0198, 3.3636],
[ 2.1904, 2.4030, 3.0236, ..., 2.6609, 3.4335, 2.1247]],
[[ 3.1380, 3.6765, 3.2885, ..., 3.7196, 3.4645, 1.5695],
[ 3.6905, 3.7357, 3.6641, ..., 3.8547, 3.8975, 1.8173],
[ 3.4629, 3.9321, 4.4336, ..., 4.0658, 4.6976, 2.2134],
...,
[ 3.2965, 3.2443, 3.1581, ..., 3.5299, 3.6044, 1.6438],
[ 3.1583, 3.5555, 4.0245, ..., 3.8481, 4.5026, 2.1327],
[ 2.0114, 2.1212, 2.4448, ..., 2.3623, 2.8170, 1.5200]],
[[ 2.2081, 3.2668, 2.5174, ..., 3.3637, 2.6923, 2.4794],
[ 2.8818, 3.7679, 4.0831, ..., 3.9105, 4.3547, 2.6905],
[ 2.1275, 4.3144, 3.3491, ..., 4.5489, 3.6542, 4.1641],
...,
[ 2.5915, 3.3633, 3.6023, ..., 3.6855, 4.1384, 2.5465],
[ 1.9393, 4.0032, 3.0043, ..., 4.3745, 3.5407, 4.0696],
[ 2.4386, 2.6604, 3.6452, ..., 2.9201, 4.0965, 2.5302]],
...,
[[ 3.2162, 3.8304, 3.5620, ..., 4.2622, 4.0508, 1.9827],
[ 3.7052, 3.9873, 3.9947, ..., 4.5104, 4.4925, 2.4904],
[ 3.4403, 4.0276, 4.6908, ..., 4.5218, 5.3362, 2.7125],
...,
[ 3.1479, 3.1952, 3.1191, ..., 3.0581, 3.0709, 1.3184],
[ 2.9994, 3.3553, 3.8687, ..., 3.3441, 3.9474, 1.7926],
[ 1.9566, 2.0547, 2.4030, ..., 2.0817, 2.5090, 1.3808]],
[[ 2.4635, 3.5702, 2.8475, ..., 3.9538, 3.4170, 3.0005],
[ 3.1944, 4.0586, 4.5052, ..., 4.6464, 5.2472, 3.2948],
[ 2.4489, 4.6542, 3.8148, ..., 5.1960, 4.4505, 4.8568],
...,
[ 2.7437, 3.4353, 3.8114, ..., 3.5400, 4.0578, 2.4587],
[ 2.1210, 4.1165, 3.2304, ..., 4.3206, 3.5381, 3.9597],
[ 2.5213, 2.7691, 3.8226, ..., 2.9159, 4.0929, 2.5082]],
[[ 2.8008, 2.9333, 2.7532, ..., 3.2060, 3.0967, 1.5881],
[ 3.3183, 3.8508, 3.7065, ..., 4.2754, 4.1927, 2.8809],
[ 3.6245, 3.7408, 4.6611, ..., 4.1380, 5.2102, 2.7259],
...,
[ 3.0637, 3.4555, 3.2841, ..., 3.4542, 3.3532, 2.3253],
[ 3.4461, 3.4548, 4.3016, ..., 3.4862, 4.4400, 2.2713],
[ 2.3500, 2.6865, 2.8765, ..., 2.7495, 2.9998, 2.3213]]],
[[[-4.0294, -4.5309, -4.0302, ..., -4.6081, -4.1637, -3.8640],
[-4.2734, -4.7440, -4.6096, ..., -4.8508, -4.8040, -3.9139],
[-4.0585, -4.8143, -4.6290, ..., -4.9377, -4.8233, -4.3723],
...,
[-3.9798, -4.3973, -4.2285, ..., -4.5733, -4.5448, -3.7697],
[-3.8256, -4.5039, -4.3072, ..., -4.7553, -4.6792, -4.2943],
[-4.0440, -4.0397, -4.7244, ..., -4.2716, -5.1174, -3.6966]],
[[-4.3242, -5.2208, -3.7476, ..., -5.2469, -3.8840, -3.6045],
[-4.5879, -4.4781, -4.0913, ..., -4.5301, -4.2751, -3.0066],
[-4.4390, -5.3211, -4.4363, ..., -5.4304, -4.6379, -3.9783],
...,
[-4.2916, -4.1292, -3.7032, ..., -4.2663, -4.0244, -2.8723],
[-4.1888, -4.9893, -4.1171, ..., -5.2277, -4.4994, -3.8948],
[-4.1051, -3.7245, -4.1535, ..., -3.8798, -4.5081, -3.2509]],
[[-3.7841, -4.2897, -3.8935, ..., -4.3361, -4.0256, -3.4978],
[-4.1025, -4.5303, -4.2630, ..., -4.6366, -4.4535, -4.0137],
[-4.1383, -4.5765, -4.8744, ..., -4.7105, -5.1178, -4.1179],
...,
[-3.8618, -4.2027, -3.8886, ..., -4.4402, -4.2697, -3.8870],
[-3.9734, -4.3566, -4.5914, ..., -4.5757, -5.0030, -4.0484],
[-4.2849, -4.3252, -4.7248, ..., -4.5373, -5.0862, -4.0792]],
...,
[[-4.4014, -5.2513, -3.9510, ..., -5.6438, -4.3286, -3.8794],
[-4.5907, -4.4249, -4.2662, ..., -4.8473, -4.7317, -3.4385],
[-4.4027, -5.2870, -4.6016, ..., -5.7981, -5.1315, -4.3473],
...,
[-4.1812, -3.8634, -3.6210, ..., -3.7719, -3.6041, -2.5724],
[-4.0350, -4.6998, -3.9777, ..., -4.7150, -4.0457, -3.5576],
[-4.0831, -3.5535, -4.1286, ..., -3.5784, -4.2557, -3.0805]],
[[-3.8953, -4.4040, -4.0720, ..., -4.7450, -4.5712, -3.8096],
[-4.2245, -4.6695, -4.4627, ..., -5.2251, -5.0896, -4.4852],
[-4.2681, -4.6525, -5.1348, ..., -5.1070, -5.7651, -4.5150],
...,
[-3.8731, -4.1726, -3.9207, ..., -4.2435, -4.0924, -3.7632],
[-3.9943, -4.2486, -4.6245, ..., -4.3753, -4.8689, -3.8804],
[-4.3257, -4.3622, -4.8110, ..., -4.4940, -5.0384, -4.0203]],
[[-4.2909, -4.5753, -4.1038, ..., -4.8523, -4.4084, -3.6155],
[-5.1585, -5.4281, -5.4802, ..., -5.8144, -5.9134, -4.6329],
[-4.9422, -5.6485, -5.4592, ..., -6.0236, -5.8996, -4.8365],
...,
[-4.9429, -5.1119, -5.1581, ..., -5.1131, -5.2351, -4.1735],
[-4.7887, -5.4022, -5.1749, ..., -5.4524, -5.3054, -4.4307],
[-4.4951, -4.9009, -5.1628, ..., -4.9595, -5.2885, -4.2641]]]]],
device='cuda:0', grad_fn=<CudnnConvolutionBackward0>)
可以看到我们模型的输出为[1, 2, 14, 112, 112] 第一个参数1是batch_size的个数,第二个是通道数,最后三位是我们预测出的mask大小。 这和我们的gt图像大小不一致,所以我们需要把我们gt图像缩放为和模型输出一样的大小。
在训练的过程中,我们如下操作
# resize label 如果大小不相同,进行缩放
[n, _, d, h, w] = out_masks.shape # n = batch_size
new_label_masks = np.zeros([n, d, h, w])
for label_id in range(n): # 对于每一个图像,缩放到和模型输出大小相同
label_mask = label_masks[label_id]
[ori_c, ori_d, ori_h, ori_w] = label_mask.shape
label_mask = np.reshape(label_mask, [ori_d, ori_h, ori_w])
scale = [d*1.0/ori_d, h*1.0/ori_h, w*1.0/ori_w]
label_mask = ndimage.interpolation.zoom(label_mask, scale, order=0)
new_label_masks[label_id] = label_mask
新的gt为new_label_masks,其大小为[n, d, h, w],和模型的输出相同,这样我们就可以进行loss和metric的计算。
而在预测过程中,我们则是把模型的输出所放到和原图相同的大小。
因为我们是做预测,所以得到模型的输出之后,加一个softmax将概率转化到0或1
masks = []
net.eval() # for testing
for batch_id, batch_data in enumerate(data_loader):
volume = batch_data
volume = volume.cuda()
probs = net(volume)
probs = F.softmax(probs, dim=1) # 将概率转化到0或1
print('model output size = ',probs.shape)
[batchsize, _, mask_d, mask_h, mask_w] = probs.shape
data = nib.load(os.path.join(root_dir, img_names[batch_id]))
data = data.get_fdata()
[depth, height, width] = data.shape
print('data original size =',data.shape)
mask = probs[0].detach().cpu().numpy()
scale = [1, depth*1.0/mask_d, height*1.0/mask_h, width*1.0/mask_w]
mask = ndimage.interpolation.zoom(mask, scale, order=1)
mask = np.argmax(mask, axis=0)
print('after scale, prediction mask size =',mask.shape)
masks.append(mask)
break
./MedicalNet_pytorch_files2/data/MRBrainS18/images/070.nii.gz
./MedicalNet_pytorch_files2/data/MRBrainS18/images/1.nii.gz
model output size = torch.Size([1, 2, 14, 112, 112])
data original size = (143, 228, 194)
after scale, prediction mask size = (143, 228, 194)
之后,对于每个病人,我们计算prediction mask和gt之间的dice值
# evaluation: calculate dice
label_names = [info.split(" ")[1] for info in load_lines(img_list_path)]
Nimg = len(label_names)
seg_classes = 2
dices = np.zeros([Nimg, seg_classes])
for idx in range(Nimg):
label = nib.load(os.path.join(root_dir, label_names[idx]))
label = label.get_data()
a=seg_eval(masks[idx], label, range(seg_classes))
print('dice =',a)
break
dice = [0.95794859 0.87390118]
完整代码
依赖
import torch
from torch import nn
import math
import os
import random
import numpy as np
from torch.utils.data import Dataset
import nibabel
from scipy import ndimage
from torch.utils.data import DataLoader
from utils.logger import log
import time
本地函数文件
from models import resnet
MedicalNet
def generate_model(model_type='resnet', model_depth=50,
input_W=448, input_H=448, input_D=56, resnet_shortcut='B',
no_cuda=False, gpu_id=[0],
phase='train', pretrain_path = 'pretrain/resnet_50.pth',
new_layer_names= ['conv_seg'] ,n_seg_classes=2):
assert model_type in [
'resnet'
]
if model_type == 'resnet':
assert model_depth in [10, 18, 34, 50, 101, 152, 200]
if model_depth == 10:
model = resnet.resnet10(
sample_input_W=input_W,
sample_input_H=input_H,
sample_input_D=input_D,
shortcut_type=resnet_shortcut,
no_cuda=no_cuda,
num_seg_classes=n_seg_classes)
elif model_depth == 18:
model = resnet.resnet18(
sample_input_W=input_W,
sample_input_H=input_H,
sample_input_D=input_D,
shortcut_type=resnet_shortcut,
no_cuda=no_cuda,
num_seg_classes=n_seg_classes)
elif model_depth == 34:
model = resnet.resnet34(
sample_input_W=input_W,
sample_input_H=input_H,
sample_input_D=input_D,
shortcut_type=resnet_shortcut,
no_cuda=no_cuda,
num_seg_classes=n_seg_classes)
elif model_depth == 50:
model = resnet.resnet50(
sample_input_W=input_W,
sample_input_H=input_H,
sample_input_D=input_D,
shortcut_type=resnet_shortcut,
no_cuda=no_cuda,
num_seg_classes=n_seg_classes)
elif model_depth == 101:
model = resnet.resnet101(
sample_input_W=input_W,
sample_input_H=input_H,
sample_input_D=input_D,
shortcut_type=resnet_shortcut,
no_cuda=no_cuda,
num_seg_classes=n_seg_classes)
elif model_depth == 152:
model = resnet.resnet152(
sample_input_W=input_W,
sample_input_H=input_H,
sample_input_D=input_D,
shortcut_type=resnet_shortcut,
no_cuda=no_cuda,
num_seg_classes=n_seg_classes)
elif model_depth == 200:
model = resnet.resnet200(
sample_input_W=input_W,
sample_input_H=input_H,
sample_input_D=input_D,
shortcut_type=resnet_shortcut,
no_cuda=no_cuda,
num_seg_classes=n_seg_classes)
if not no_cuda:
if len(gpu_id) > 1:
model = model.cuda()
model = nn.DataParallel(model, device_ids=gpu_id)
net_dict = model.state_dict()
else:
import os
os.environ["CUDA_VISIBLE_DEVICES"]=str(gpu_id[0])
model = model.cuda()
model = nn.DataParallel(model, device_ids=None)
net_dict = model.state_dict()
else:
net_dict = model.state_dict()
# load pretrain
if phase != 'test' and pretrain_path:
print('loading pretrained model {}'.format(pretrain_path))
pretrain = torch.load(pretrain_path)
pretrain_dict = {k: v for k, v in pretrain['state_dict'].items() if k in net_dict.keys()}
# k 是每一层的名称,v是权重数值
net_dict.update(pretrain_dict) #字典 dict2 的键/值对更新到 dict 里。
model.load_state_dict(net_dict) #model.load_state_dict()函数把加载的权重复制到模型的权重中去
new_parameters = []
for pname, p in model.named_parameters(): #返回各层中参数名称和数据。
for layer_name in new_layer_names:
if pname.find(layer_name) >= 0:
new_parameters.append(p)
break
new_parameters_id = list(map(id, new_parameters))
base_parameters = list(filter(lambda p: id(p) not in new_parameters_id, model.parameters()))
parameters = {'base_parameters': base_parameters,
'new_parameters': new_parameters}
print("-------- pre-train model load successfully --------")
return model, parameters
print("-------- no pre-train model load ---------")
return model, model.parameters()
model, parameters = generate_model(model_type='resnet', model_depth=50,
input_W=448, input_H=448, input_D=56, resnet_shortcut='B',
no_cuda=False, gpu_id=[0],
phase='train', pretrain_path = './MedicalNet_pytorch_files2/pretrain/resnet_50_23dataset.pth',
new_layer_names= ['conv_seg'] ,n_seg_classes=2)
下面是所有预训练模型的参数,使用时需要将模型与参数匹配
'''
############################ pre-trained network parameters settings ###########################################
Model name : parameters settings
resnet_10.pth: --model_type resnet --model_depth 10 --resnet_shortcut B
resnet_18.pth: --model_type resnet --model_depth 18 --resnet_shortcut A
resnet_34.pth: --model_type resnet --model_depth 34 --resnet_shortcut A
resnet_50.pth: --model_type resnet --model_depth 50 --resnet_shortcut B
resnet_101.pth: --model_type resnet --model_depth 101 --resnet_shortcut B
resnet_152.pth: --model_type resnet --model_depth 152 --resnet_shortcut B
resnet_200.pth: --model_type resnet --model_depth 200 --resnet_shortcut B
resnet_10_23dataset.pth: --model_type resnet --model_depth 10 --resnet_shortcut B
resnet_18_23dataset.pth: --model_type resnet --model_depth 18 --resnet_shortcut A
resnet_34_23dataset.pth: --model_type resnet --model_depth 34 --resnet_shortcut A
resnet_50_23dataset.pth: --model_type resnet --model_depth 50 --resnet_shortcut B
'''
学习率设置
learning_rate = 0.001
params = [
{ 'params': parameters['base_parameters'], 'lr': learning_rate },
{ 'params': parameters['new_parameters'], 'lr': learning_rate*100 }
]
optimizer = torch.optim.SGD(params, momentum=0.9, weight_decay=1e-3)
scheduler = torch.optim.lr_scheduler.ExponentialLR(optimizer, gamma=0.99)
数据加载
class BrainS18Dataset(Dataset):
def __init__(self, root_dir, img_list, input_D,input_H,input_W,phase):
with open(img_list, 'r') as f:
self.img_list = [line.strip() for line in f]
print("Processing {} datas".format(len(self.img_list)))
self.root_dir = root_dir
self.input_D = input_D
self.input_H = input_H
self.input_W = input_W
self.phase = phase
def __nii2tensorarray__(self, data):
[z, y, x] = data.shape
new_data = np.reshape(data, [1, z, y, x])
new_data = new_data.astype("float32")
return new_data
def __len__(self):
return len(self.img_list)
def __getitem__(self, idx):
if self.phase == "train":
# read image and labels
ith_info = self.img_list[idx].split(" ")
img_name = os.path.join(self.root_dir, ith_info[0])
label_name = os.path.join(self.root_dir, ith_info[1])
assert os.path.isfile(img_name)
assert os.path.isfile(label_name)
img = nibabel.load(img_name) # We have transposed the data from WHD format to DHW
assert img is not None
mask = nibabel.load(label_name)
assert mask is not None
# data processing
img_array, mask_array = self.__training_data_process__(img, mask)
# 2 tensor array
img_array = self.__nii2tensorarray__(img_array)
mask_array = self.__nii2tensorarray__(mask_array)
assert img_array.shape == mask_array.shape, "img shape:{} is not equal to mask shape:{}".format(img_array.shape, mask_array.shape)
return img_array, mask_array
elif self.phase == "test":
# read image
ith_info = self.img_list[idx].split(" ")
img_name = os.path.join(self.root_dir, ith_info[0])
print(img_name)
assert os.path.isfile(img_name)
img = nibabel.load(img_name)
assert img is not None
# data processing
img_array = self.__testing_data_process__(img)
# 2 tensor array
img_array = self.__nii2tensorarray__(img_array)
return img_array
def __drop_invalid_range__(self, volume, label=None):
"""
Cut off the invalid area
"""
zero_value = volume[0, 0, 0]
non_zeros_idx = np.where(volume != zero_value)
[max_z, max_h, max_w] = np.max(np.array(non_zeros_idx), axis=1)
[min_z, min_h, min_w] = np.min(np.array(non_zeros_idx), axis=1)
if label is not None:
return volume[min_z:max_z, min_h:max_h, min_w:max_w], label[min_z:max_z, min_h:max_h, min_w:max_w]
else:
return volume[min_z:max_z, min_h:max_h, min_w:max_w]
def __random_center_crop__(self, data, label):
from random import random
"""
Random crop
"""
target_indexs = np.where(label>0)
[img_d, img_h, img_w] = data.shape
[max_D, max_H, max_W] = np.max(np.array(target_indexs), axis=1)
[min_D, min_H, min_W] = np.min(np.array(target_indexs), axis=1)
[target_depth, target_height, target_width] = np.array([max_D, max_H, max_W]) - np.array([min_D, min_H, min_W])
Z_min = int((min_D - target_depth*1.0/2) * random())
Y_min = int((min_H - target_height*1.0/2) * random())
X_min = int((min_W - target_width*1.0/2) * random())
Z_max = int(img_d - ((img_d - (max_D + target_depth*1.0/2)) * random()))
Y_max = int(img_h - ((img_h - (max_H + target_height*1.0/2)) * random()))
X_max = int(img_w - ((img_w - (max_W + target_width*1.0/2)) * random()))
Z_min = np.max([0, Z_min])
Y_min = np.max([0, Y_min])
X_min = np.max([0, X_min])
Z_max = np.min([img_d, Z_max])
Y_max = np.min([img_h, Y_max])
X_max = np.min([img_w, X_max])
Z_min = int(Z_min)
Y_min = int(Y_min)
X_min = int(X_min)
Z_max = int(Z_max)
Y_max = int(Y_max)
X_max = int(X_max)
return data[Z_min: Z_max, Y_min: Y_max, X_min: X_max], label[Z_min: Z_max, Y_min: Y_max, X_min: X_max]
def __itensity_normalize_one_volume__(self, volume):
"""
normalize the itensity of an nd volume based on the mean and std of nonzeor region
inputs:
volume: the input nd volume
outputs:
out: the normalized nd volume
"""
pixels = volume[volume > 0]
mean = pixels.mean()
std = pixels.std()
out = (volume - mean)/std
out_random = np.random.normal(0, 1, size = volume.shape)
out[volume == 0] = out_random[volume == 0]
return out
def __resize_data__(self, data):
"""
Resize the data to the input size
"""
[depth, height, width] = data.shape
scale = [self.input_D*1.0/depth, self.input_H*1.0/height, self.input_W*1.0/width]
data = ndimage.interpolation.zoom(data, scale, order=0)
return data
def __crop_data__(self, data, label):
"""
Random crop with different methods:
"""
# random center crop
data, label = self.__random_center_crop__ (data, label)
return data, label
def __training_data_process__(self, data, label):
# crop data according net input size
data = data.get_fdata()
label = label.get_fdata()
# drop out the invalid range
data, label = self.__drop_invalid_range__(data, label)
# crop data
data, label = self.__crop_data__(data, label)
# resize data
data = self.__resize_data__(data)
label = self.__resize_data__(label)
# normalization datas
data = self.__itensity_normalize_one_volume__(data)
return data, label
def __testing_data_process__(self, data):
# crop data according net input size
data = data.get_fdata()
# resize data
data = self.__resize_data__(data)
# normalization datas
data = self.__itensity_normalize_one_volume__(data)
return data
img_list_path = './MedicalNet_pytorch_files2/data/train.txt'
root_dir = './MedicalNet_pytorch_files2/data'
training_dataset = BrainS18Dataset(root_dir = root_dir, img_list= img_list_path, input_D = 56,input_H = 448,input_W = 448,phase = 'train')
data_loader = DataLoader(training_dataset, batch_size=4, shuffle=True, num_workers=8, pin_memory=True)
训练
total_epochs = 200
batches_per_epoch = len(data_loader)
log.info('{} epochs in total, {} batches per epoch'.format(total_epochs, batches_per_epoch))
loss_seg = nn.CrossEntropyLoss(ignore_index=-1)
model.train()
train_time_sp = time.time()
for epoch in range(total_epochs):
log.info('Start epoch {}'.format(epoch))
log.info('lr = {}'.format(scheduler.get_last_lr()))
for batch_id, batch_data in enumerate(data_loader):
# getting data batch
batch_id_sp = epoch * batches_per_epoch
volumes, label_masks = batch_data
volumes = volumes.cuda()
optimizer.zero_grad()
out_masks = model(volumes)
# resize label 如果大小不相同,进行缩放
[n, _, d, h, w] = out_masks.shape # n = batch_size
new_label_masks = np.zeros([n, d, h, w])
for label_id in range(n):
label_mask = label_masks[label_id]
[ori_c, ori_d, ori_h, ori_w] = label_mask.shape
label_mask = np.reshape(label_mask, [ori_d, ori_h, ori_w])
scale = [d*1.0/ori_d, h*1.0/ori_h, w*1.0/ori_w]
label_mask = ndimage.interpolation.zoom(label_mask, scale, order=0)
new_label_masks[label_id] = label_mask
new_label_masks = torch.tensor(new_label_masks).to(torch.int64)
new_label_masks = new_label_masks.cuda()
# calculating loss
loss_value_seg = loss_seg(out_masks, new_label_masks)
loss = loss_value_seg
loss.backward()
optimizer.step()
scheduler.step()
avg_batch_time = (time.time() - train_time_sp) / (1 + batch_id_sp)
log.info(
'Batch: {}-{} ({}), loss = {:.3f}, loss_seg = {:.3f}, avg_batch_time = {:.3f}'\
.format(epoch, batch_id, batch_id_sp, loss.item(), loss_value_seg.item(), avg_batch_time))
# save model
save_interval = 10
save_folder = './weights'
if batch_id == 0 and batch_id_sp != 0 and batch_id_sp % save_interval == 0:
#if batch_id_sp != 0 and batch_id_sp % save_interval == 0:
model_save_path = '{}_epoch_{}_batch_{}.pth.tar'.format(save_folder, epoch, batch_id)
model_save_dir = os.path.dirname(model_save_path)
if not os.path.exists(model_save_dir):
os.makedirs(model_save_dir)
log.info('Save checkpoints: epoch = {}, batch_id = {}'.format(epoch, batch_id))
torch.save({
'ecpoch': epoch,
'batch_id': batch_id,
'state_dict': model.state_dict(),
'optimizer': optimizer.state_dict()},
model_save_path)
print('Finished training')
训练过程
2022-04-11 13:30:53 INFO [<ipython-input-11-e5c972c55254>:4] Start epoch 0
2022-04-11 13:30:53 INFO [<ipython-input-11-e5c972c55254>:7] lr = [0.001, 0.1]
2022-04-11 13:31:01 INFO [<ipython-input-11-e5c972c55254>:43] Batch: 0-0 (0), loss = 0.567, loss_seg = 0.567, avg_batch_time = 7.482
2022-04-11 13:31:03 INFO [<ipython-input-11-e5c972c55254>:43] Batch: 0-1 (0), loss = 0.477, loss_seg = 0.477, avg_batch_time = 8.861
2022-04-11 13:31:03 INFO [<ipython-input-11-e5c972c55254>:43] Batch: 0-2 (0), loss = 0.567, loss_seg = 0.567, avg_batch_time = 9.601
2022-04-11 13:31:03 INFO [<ipython-input-11-e5c972c55254>:4] Start epoch 1
2022-04-11 13:31:03 INFO [<ipython-input-11-e5c972c55254>:7] lr = [0.000970299, 0.0970299]
2022-04-11 13:31:10 INFO [<ipython-input-11-e5c972c55254>:43] Batch: 1-0 (3), loss = 0.428, loss_seg = 0.428, avg_batch_time = 4.157
2022-04-11 13:31:11 INFO [<ipython-input-11-e5c972c55254>:43] Batch: 1-1 (3), loss = 0.405, loss_seg = 0.405, avg_batch_time = 4.452
2022-04-11 13:31:12 INFO [<ipython-input-11-e5c972c55254>:43] Batch: 1-2 (3), loss = 0.381, loss_seg = 0.381, avg_batch_time = 4.636
2022-04-11 13:31:12 INFO [<ipython-input-11-e5c972c55254>:4] Start epoch 2
2022-04-11 13:31:12 INFO [<ipython-input-11-e5c972c55254>:7] lr = [0.0009414801494009999, 0.0941480149401]
2022-04-11 13:31:19 INFO [<ipython-input-11-e5c972c55254>:43] Batch: 2-0 (6), loss = 0.344, loss_seg = 0.344, avg_batch_time = 3.687
2022-04-11 13:31:21 INFO [<ipython-input-11-e5c972c55254>:43] Batch: 2-1 (6), loss = 0.301, loss_seg = 0.301, avg_batch_time = 3.851
2022-04-11 13:31:21 INFO [<ipython-input-11-e5c972c55254>:43] Batch: 2-2 (6), loss = 0.343, loss_seg = 0.343, avg_batch_time = 3.957
2022-04-11 13:31:21 INFO [<ipython-input-11-e5c972c55254>:4] Start epoch 3
2022-04-11 13:31:21 INFO [<ipython-input-11-e5c972c55254>:7] lr = [0.0009135172474836408, 0.09135172474836409]
2022-04-11 13:31:28 INFO [<ipython-input-11-e5c972c55254>:43] Batch: 3-0 (9), loss = 0.286, loss_seg = 0.286, avg_batch_time = 3.464
2022-04-11 13:31:30 INFO [<ipython-input-11-e5c972c55254>:43] Batch: 3-1 (9), loss = 0.270, loss_seg = 0.270, avg_batch_time = 3.584
2022-04-11 13:31:30 INFO [<ipython-input-11-e5c972c55254>:43] Batch: 3-2 (9), loss = 0.267, loss_seg = 0.267, avg_batch_time = 3.661
2022-04-11 13:31:30 INFO [<ipython-input-11-e5c972c55254>:4] Start epoch 4
2022-04-11 13:31:30 INFO [<ipython-input-11-e5c972c55254>:7] lr = [0.0008863848717161291, 0.08863848717161292]
2022-04-11 13:31:37 INFO [<ipython-input-11-e5c972c55254>:43] Batch: 4-0 (12), loss = 0.256, loss_seg = 0.256, avg_batch_time = 3.366
2022-04-11 13:31:39 INFO [<ipython-input-11-e5c972c55254>:43] Batch: 4-1 (12), loss = 0.224, loss_seg = 0.224, avg_batch_time = 3.455
2022-04-11 13:31:39 INFO [<ipython-input-11-e5c972c55254>:43] Batch: 4-2 (12), loss = 0.209, loss_seg = 0.209, avg_batch_time = 3.512
2022-04-11 13:31:39 INFO [<ipython-input-11-e5c972c55254>:4] Start epoch 5
2022-04-11 13:31:39 INFO [<ipython-input-11-e5c972c55254>:7] lr = [0.0008600583546412883, 0.08600583546412884]
2022-04-11 13:31:46 INFO [<ipython-input-11-e5c972c55254>:43] Batch: 5-0 (15), loss = 0.204, loss_seg = 0.204, avg_batch_time = 3.295
2022-04-11 13:31:48 INFO [<ipython-input-11-e5c972c55254>:43] Batch: 5-1 (15), loss = 0.200, loss_seg = 0.200, avg_batch_time = 3.367
2022-04-11 13:31:48 INFO [<ipython-input-11-e5c972c55254>:43] Batch: 5-2 (15), loss = 0.201, loss_seg = 0.201, avg_batch_time = 3.414
2022-04-11 13:31:48 INFO [<ipython-input-11-e5c972c55254>:4] Start epoch 6
2022-04-11 13:31:48 INFO [<ipython-input-11-e5c972c55254>:7] lr = [0.0008345137614500873, 0.08345137614500873]
2022-04-11 13:31:55 INFO [<ipython-input-11-e5c972c55254>:43] Batch: 6-0 (18), loss = 0.221, loss_seg = 0.221, avg_batch_time = 3.252
2022-04-11 13:31:57 INFO [<ipython-input-11-e5c972c55254>:43] Batch: 6-1 (18), loss = 0.172, loss_seg = 0.172, avg_batch_time = 3.313
2022-04-11 13:31:57 INFO [<ipython-input-11-e5c972c55254>:43] Batch: 6-2 (18), loss = 0.192, loss_seg = 0.192, avg_batch_time = 3.352
2022-04-11 13:31:57 INFO [<ipython-input-11-e5c972c55254>:4] Start epoch 7
2022-04-11 13:31:57 INFO [<ipython-input-11-e5c972c55254>:7] lr = [0.0008097278682212583, 0.08097278682212583]
2022-04-11 13:32:04 INFO [<ipython-input-11-e5c972c55254>:43] Batch: 7-0 (21), loss = 0.171, loss_seg = 0.171, avg_batch_time = 3.211
2022-04-11 13:32:05 INFO [<ipython-input-11-e5c972c55254>:43] Batch: 7-1 (21), loss = 0.217, loss_seg = 0.217, avg_batch_time = 3.264
2022-04-11 13:32:06 INFO [<ipython-input-11-e5c972c55254>:43] Batch: 7-2 (21), loss = 0.147, loss_seg = 0.147, avg_batch_time = 3.298
2022-04-11 13:32:06 INFO [<ipython-input-11-e5c972c55254>:4] Start epoch 8
2022-04-11 13:32:06 INFO [<ipython-input-11-e5c972c55254>:7] lr = [0.0007856781408072188, 0.07856781408072187]
2022-04-11 13:32:13 INFO [<ipython-input-11-e5c972c55254>:43] Batch: 8-0 (24), loss = 0.164, loss_seg = 0.164, avg_batch_time = 3.184
2022-04-11 13:32:14 INFO [<ipython-input-11-e5c972c55254>:43] Batch: 8-1 (24), loss = 0.156, loss_seg = 0.156, avg_batch_time = 3.230
2022-04-11 13:32:15 INFO [<ipython-input-11-e5c972c55254>:43] Batch: 8-2 (24), loss = 0.159, loss_seg = 0.159, avg_batch_time = 3.260
2022-04-11 13:32:15 INFO [<ipython-input-11-e5c972c55254>:4] Start epoch 9
2022-04-11 13:32:15 INFO [<ipython-input-11-e5c972c55254>:7] lr = [0.0007623427143471034, 0.07623427143471034]
2022-04-11 13:32:22 INFO [<ipython-input-11-e5c972c55254>:43] Batch: 9-0 (27), loss = 0.158, loss_seg = 0.158, avg_batch_time = 3.159
2022-04-11 13:32:23 INFO [<ipython-input-11-e5c972c55254>:43] Batch: 9-1 (27), loss = 0.144, loss_seg = 0.144, avg_batch_time = 3.200
2022-04-11 13:32:24 INFO [<ipython-input-11-e5c972c55254>:43] Batch: 9-2 (27), loss = 0.137, loss_seg = 0.137, avg_batch_time = 3.226
2022-04-11 13:32:24 INFO [<ipython-input-11-e5c972c55254>:4] Start epoch 10
2022-04-11 13:32:24 INFO [<ipython-input-11-e5c972c55254>:7] lr = [0.0007397003733882801, 0.073970037338828]
2022-04-11 13:32:31 INFO [<ipython-input-11-e5c972c55254>:43] Batch: 10-0 (30), loss = 0.166, loss_seg = 0.166, avg_batch_time = 3.145
2022-04-11 13:32:31 INFO [<ipython-input-11-e5c972c55254>:57] Save checkpoints: epoch = 10, batch_id = 0
2022-04-11 13:32:33 INFO [<ipython-input-11-e5c972c55254>:43] Batch: 10-1 (30), loss = 0.137, loss_seg = 0.137, avg_batch_time = 3.198
2022-04-11 13:32:33 INFO [<ipython-input-11-e5c972c55254>:43] Batch: 10-2 (30), loss = 0.150, loss_seg = 0.150, avg_batch_time = 3.221
预测
依赖
import torch
import numpy as np
from torch.utils.data import DataLoader
import torch.nn.functional as F
from scipy import ndimage
import nibabel as nib
import sys
import os
from utils.file_process import load_lines
import numpy as np
加载模型
checkpoint = torch.load('./MedicalNet_pytorch_files2/trails/models/resnet_50_epoch_110_batch_0.pth.tar')
net, _ = generate_model(model_type='resnet', model_depth=50,
input_W=448, input_H=448, input_D=56, resnet_shortcut='B',
no_cuda=False, gpu_id=[0],
phase='test', pretrain_path = './MedicalNet_pytorch_files2/pretrain/resnet_50_23dataset.pth',
new_layer_names= ['conv_seg'] ,n_seg_classes=2)
net.load_state_dict(checkpoint['state_dict'])
数据读取
img_list_path = './MedicalNet_pytorch_files2/data/val.txt'
root_dir = './MedicalNet_pytorch_files2/data'
testing_data = BrainS18Dataset(root_dir = root_dir, img_list= img_list_path, input_D = 56,input_H = 448,input_W = 448,phase = 'test')
data_loader = DataLoader(testing_data, batch_size=1, shuffle=False, num_workers=1, pin_memory=False)
预测结果
img_names = [info.split(" ")[0] for info in load_lines(img_list_path)]
print(img_names) # ['MRBrainS18/images/070.nii.gz', 'MRBrainS18/images/1.nii.gz']
masks = []
net.eval() # for testing
for batch_id, batch_data in enumerate(data_loader):
volume = batch_data
volume = volume.cuda()
probs = net(volume)
probs = F.softmax(probs, dim=1) # 将概率转化到0或1
print('model output size = ',probs.shape)
[batchsize, _, mask_d, mask_h, mask_w] = probs.shape
data = nib.load(os.path.join(root_dir, img_names[batch_id]))
data = data.get_fdata()
[depth, height, width] = data.shape
print('data original size =',data.shape)
mask = probs[0].detach().cpu().numpy()
scale = [1, depth*1.0/mask_d, height*1.0/mask_h, width*1.0/mask_w]
mask = ndimage.interpolation.zoom(mask, scale, order=1)
mask = np.argmax(mask, axis=0)
print('after scale, prediction mask size =',mask.shape)
masks.append(mask)
./MedicalNet_pytorch_files2/data/MRBrainS18/images/070.nii.gz
./MedicalNet_pytorch_files2/data/MRBrainS18/images/1.nii.gz
model output size = torch.Size([1, 2, 14, 112, 112])
data original size = (143, 228, 194)
after scale, prediction mask size = (143, 228, 194)
model output size = torch.Size([1, 2, 14, 112, 112])
data original size = (143, 227, 192)
after scale, prediction mask size = (143, 227, 192)
计算dice
def seg_eval(pred, label, clss):
"""
calculate the dice between prediction and ground truth
input:
pred: predicted mask
label: groud truth
clss: eg. [0, 1] for binary class
"""
Ncls = len(clss)
dices = np.zeros(Ncls)
[depth, height, width] = pred.shape
for idx, cls in enumerate(clss):
# binary map
pred_cls = np.zeros([depth, height, width])
pred_cls[np.where(pred == cls)] = 1
label_cls = np.zeros([depth, height, width])
label_cls[np.where(label == cls)] = 1
# cal the inter & conv
s = pred_cls + label_cls
inter = len(np.where(s >= 2)[0])
conv = len(np.where(s >= 1)[0]) + inter
try:
dice = 2.0 * inter / conv
except:
print("conv is zeros when dice = 2.0 * inter / conv")
dice = -1
dices[idx] = dice
return dices
label_names = [info.split(" ")[1] for info in load_lines(img_list_path)]
print(label_names)
# evaluation: calculate dice
label_names = [info.split(" ")[1] for info in load_lines(img_list_path)]
Nimg = len(label_names)
seg_classes = 2
dices = np.zeros([Nimg, seg_classes])
for idx in range(Nimg):
label = nib.load(os.path.join(root_dir, label_names[idx]))
label = label.get_data()
dices[idx, :] = seg_eval(masks[idx], label, range(seg_classes))
打印结果
for idx in range(1, seg_classes):
mean_dice_per_task = np.mean(dices[:, idx])
print('mean dice for class-{} is {}'.format(idx, mean_dice_per_task))
mean dice for class-1 is 0.8957158185438696
补充:Resnet3D 用于分类
因为是分类,所以我们将最后的分割层改为分类层。
def generate_model(model_type='resnet', model_depth=50,
input_W=224, input_H=224, input_D=224, resnet_shortcut='B',
no_cuda=False, gpu_id=[0],
pretrain_path='resnet_50_23dataset.pth',
nb_class=1, pretrained=True , input_channel =3):
'''
this function should write in the model.py
############################ pre-trained network parameters settings ###########################################
Model name : parameters settings
resnet_10.pth: --model_type resnet --model_depth 10 --resnet_shortcut B
resnet_18.pth: --model_type resnet --model_depth 18 --resnet_shortcut A
resnet_34.pth: --model_type resnet --model_depth 34 --resnet_shortcut A
resnet_50.pth: --model_type resnet --model_depth 50 --resnet_shortcut B
resnet_101.pth: --model_type resnet --model_depth 101 --resnet_shortcut B
resnet_152.pth: --model_type resnet --model_depth 152 --resnet_shortcut B
resnet_200.pth: --model_type resnet --model_depth 200 --resnet_shortcut B
resnet_10_23dataset.pth: --model_type resnet --model_depth 10 --resnet_shortcut B
resnet_18_23dataset.pth: --model_type resnet --model_depth 18 --resnet_shortcut A
resnet_34_23dataset.pth: --model_type resnet --model_depth 34 --resnet_shortcut A
resnet_50_23dataset.pth: --model_type resnet --model_depth 50 --resnet_shortcut B
'''
assert model_type in [
'resnet'
]
if model_type == 'resnet':
assert model_depth in [10, 18, 34, 50, 101, 152, 200]
if model_depth == 10:
model = resnet10(
sample_input_W=input_W,
sample_input_H=input_H,
sample_input_D=input_D,
shortcut_type=resnet_shortcut,
no_cuda=no_cuda,
num_seg_classes=1)
fc_input = 256
elif model_depth == 18:
model = resnet18(
sample_input_W=input_W,
sample_input_H=input_H,
sample_input_D=input_D,
shortcut_type=resnet_shortcut,
no_cuda=no_cuda,
num_seg_classes=1)
fc_input = 512
elif model_depth == 34:
model = resnet34(
sample_input_W=input_W,
sample_input_H=input_H,
sample_input_D=input_D,
shortcut_type=resnet_shortcut,
no_cuda=no_cuda,
num_seg_classes=1)
fc_input = 512
elif model_depth == 50:
model = resnet50(
sample_input_W=input_W,
sample_input_H=input_H,
sample_input_D=input_D,
shortcut_type=resnet_shortcut,
no_cuda=no_cuda,
num_seg_classes=1)
fc_input = 2048
elif model_depth == 101:
model = resnet101(
sample_input_W=input_W,
sample_input_H=input_H,
sample_input_D=input_D,
shortcut_type=resnet_shortcut,
no_cuda=no_cuda,
num_seg_classes=1)
fc_input = 2048
elif model_depth == 152:
model = resnet152(
sample_input_W=input_W,
sample_input_H=input_H,
sample_input_D=input_D,
shortcut_type=resnet_shortcut,
no_cuda=no_cuda,
num_seg_classes=1)
fc_input = 2048
elif model_depth == 200:
model = resnet200(
sample_input_W=input_W,
sample_input_H=input_H,
sample_input_D=input_D,
shortcut_type=resnet_shortcut,
no_cuda=no_cuda,
num_seg_classes=1)
fc_input = 2048
model.conv_seg = nn.Sequential(nn.AdaptiveAvgPool3d((1, 1, 1)), nn.Flatten(),
nn.Linear(in_features=fc_input, out_features=nb_class, bias=True))
# change layer segmentation to dense layer
if input_channel == 3:
model.conv1 = nn.Conv3d(3, 64, kernel_size=(7, 7, 7), stride=(2, 2, 2), padding=(3, 3, 3), bias=False)
# changer to 3 canal for early fusion
if not no_cuda:
if len(gpu_id) > 1:
model = model.cuda()
model = nn.DataParallel(model, device_ids=gpu_id)
net_dict = model.state_dict()
else:
import os
os.environ["CUDA_VISIBLE_DEVICES"] = str(gpu_id[0])
model = model.cuda()
model = nn.DataParallel(model, device_ids=None)
net_dict = model.state_dict()
else:
net_dict = model.state_dict()
if pretrained == True:
print('loading pretrained model {}'.format(pretrain_path))
pretrain = torch.load(pretrain_path)
# print(pretrain['state_dict'].keys())
pretrain_dict = {k: v for k, v in pretrain['state_dict'].items() if k in net_dict.keys()}
if input_channel == 3:
pretrain_dict.pop('module.conv1.weight') # the para of first layer is diff
# print(pretrain_dict.keys())
# k 是每一层的名称,v是权重数值
#net_dict.update(pretrain_dict) #字典 dict2 的键/值对更新到 dict 里。
model.load_state_dict(pretrain_dict,strict=False) # model.load_state_dict()函数把加载的权重复制到模型的权重中去
#model.load_state_dict(net_dict)
# print(net_dict)
print("-------- pre-train model load successfully --------")
new_parameters = []
for pname, p in model.named_parameters(): # 返回各层中参数名称和数据。
for layer_name in ['conv_seg']:
if pname.find(layer_name) >= 0:
new_parameters.append(p)
break
new_parameters_id = list(map(id, new_parameters))
base_parameters = list(filter(lambda p: id(p) not in new_parameters_id, model.parameters()))
parameters = {'base_parameters': base_parameters,
'new_parameters': new_parameters}
return model,parameters
return model

















 4425
4425

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









