







monai Vit 网络 图文分析
Vision Transformer (ViT)
ViT的总体想法是基于纯Transformer结构来做图像分类任务,论文中相关实验证明在大规模数据集上做完预训练后的ViT模型,在迁移到中小规模数据集的分类任务上以后,能够取得比CNN更好的性能。
L’idée générale de ViT est d’effectuer des tâches de classification d’images basées sur la structure Transformer pure. Les expériences pertinentes dans l’article prouvent que le modèle ViT après pré-formation sur des ensembles de données à grande échelle peut être transféré aux tâches de classification de petites et ensembles de données à moyenne échelle Meilleures performances que CNN.
Paper : An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Code : monai-Vit
Reference:
- Vision Transformer (ViT)
- ViT:视觉Transformer backbone网络ViT论文与代码详解
- Self-attention Hung-yi Lee
- Transformer Hung-yi Lee
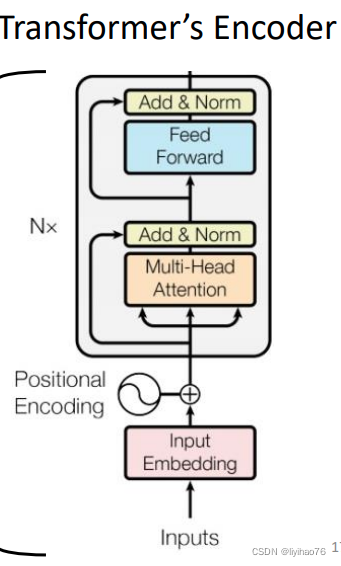
Network structure
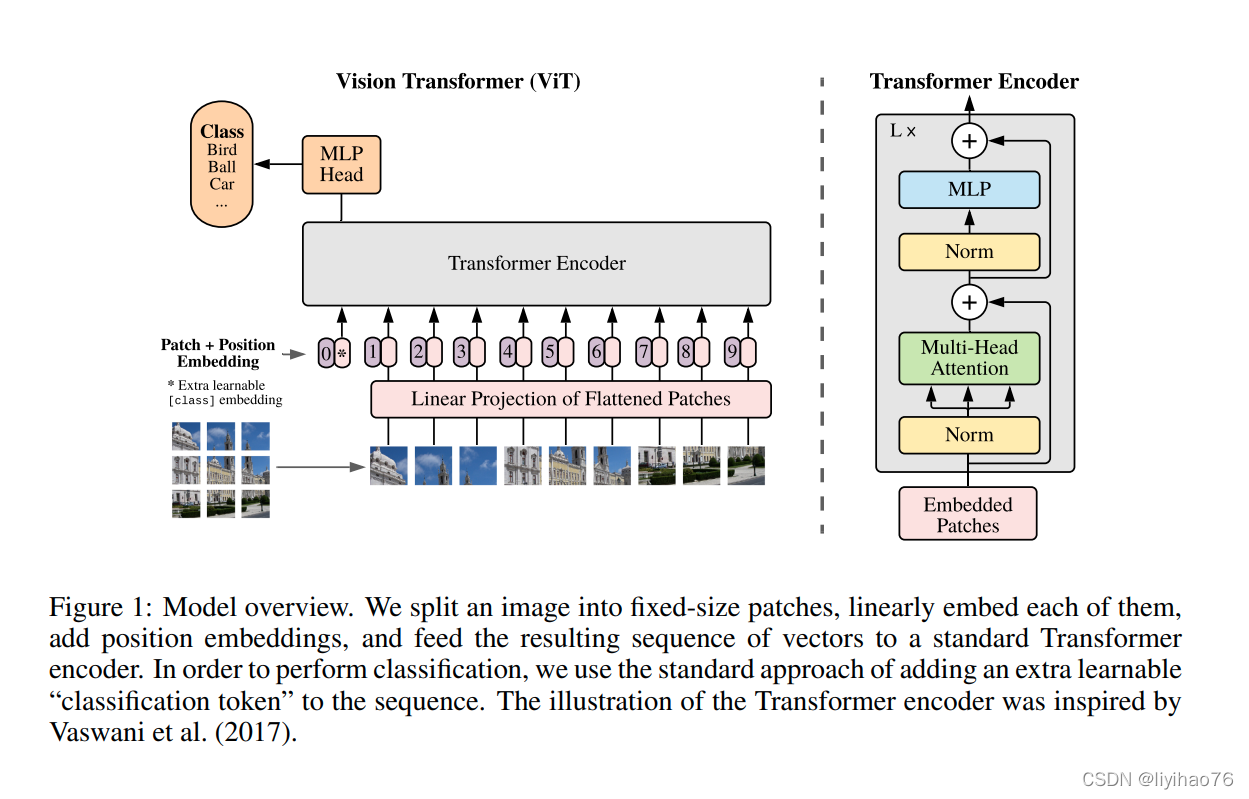
ViT的核心流程包括图像分块处理 (make patches)、图像块嵌入 (patch embedding)与位置编码、Transformer编码器和MLP分类处理等4个主要部分
Le processus de base de ViT comprend quatre parties principales : le traitement des patchs d’image (make patches), l’incorporation de patchs d’image (patch embedding) et l’encodage de position, l’encodeur Transformer et le traitement de classification MLP.
- make patches
第一步可以看作是一个图像预处理步骤。在CNN中,直接对图像进行二维卷积处理即可,不需要特殊的预处理流程。但Transformer结构不能直接处理图像,在此之前需要对其进行分块处理。
La première étape peut être vue comme une étape de prétraitement d’image. Dans CNN, le traitement de convolution bidimensionnelle peut être effectué directement sur l’image et aucun processus de prétraitement spécial n’est requis. Cependant, la structure Transformer ne peut pas traiter directement l’image, et elle doit être traitée par blocs avant cela.
- patch embedding
所谓图像块嵌入,其实就是对每一个展平后的patch向量做一个线性变换,即全连接层,降维后的维度为D。
L’incorporation de blocs d’image est en fait une transformation linéaire de chaque vecteur de patch aplati, c’est-à-dire un calque entièrement connecté, et la dimension après réduction de dimension est D.

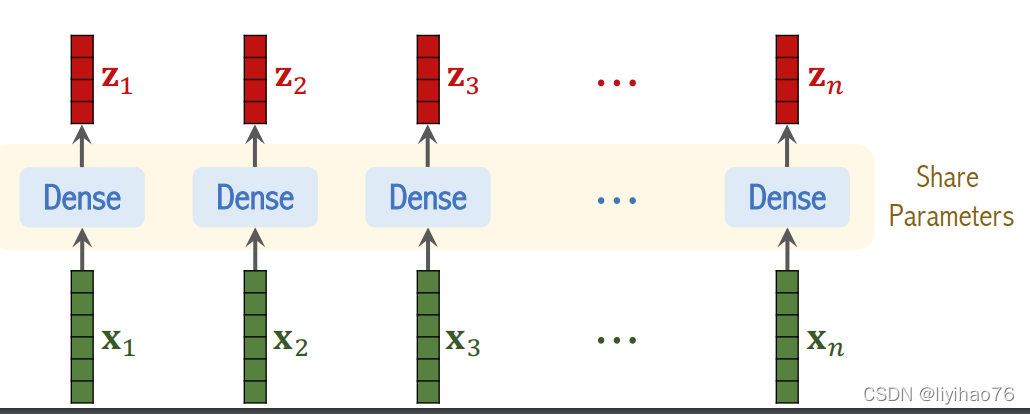
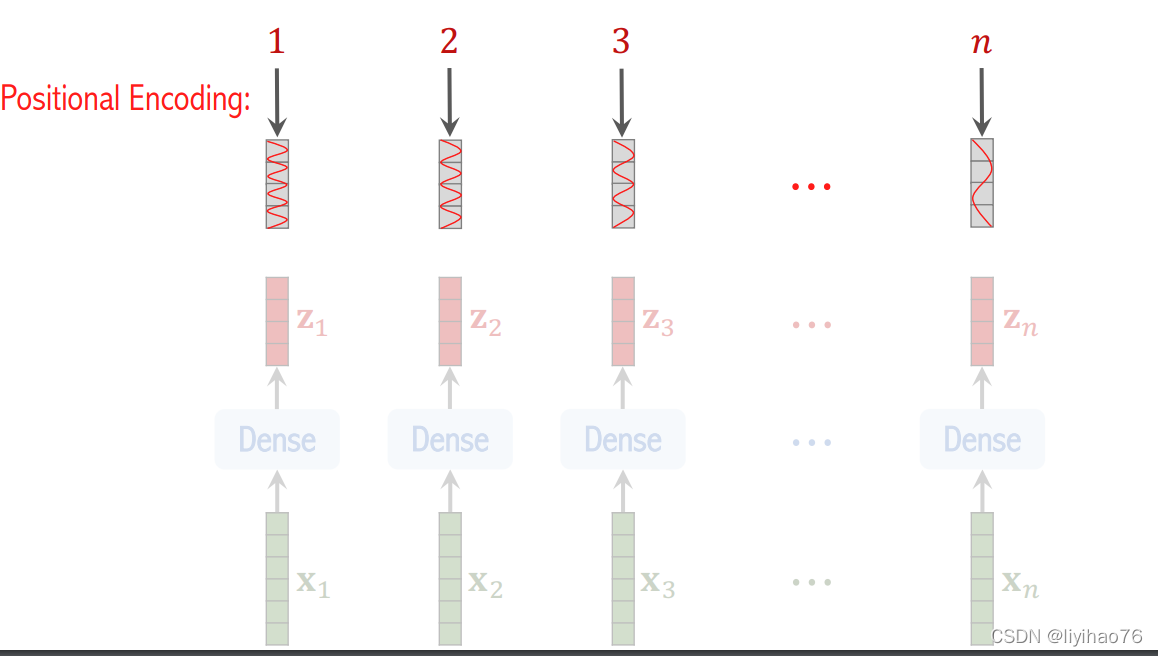
- position encoding
为了保持输入图像patch之间的空间位置信息,还需要对图像块嵌入中添加一个位置编码向量
Afin de maintenir les informations de position spatiale entre les patchs d’image d’entrée, il est également nécessaire d’ajouter un vecteur de codage de position à l’incorporation de bloc d’image.
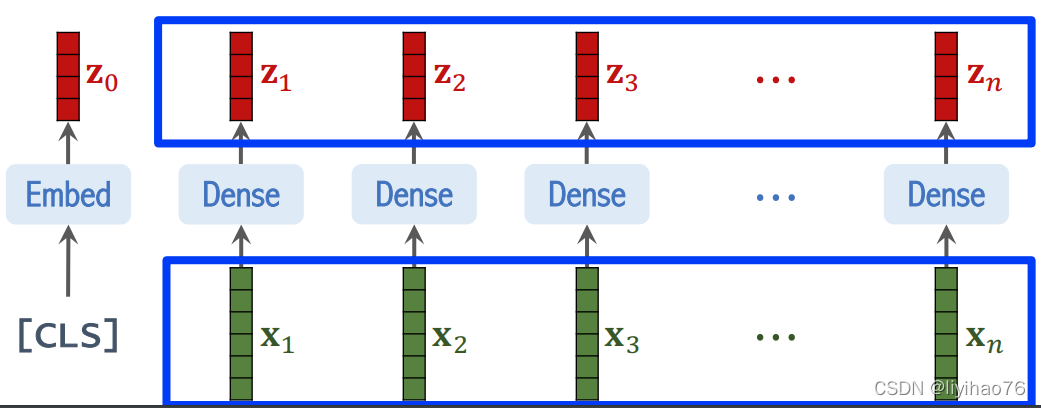
- class token
值得注意的是,上式中给长度为N的向量还追加了一个分类向量,用于Transformer训练过程中的类别信息学习。假设将图像分为9个patch,即N=9,输入到Transformer编码器中就有9个向量,但对于这9个向量而言,该取哪一个向量做分类预测呢?取哪一个都不合适。一个合理的做法就是人为添加一个类别向量,该向量是可学习的嵌入向量,与其他9个patch嵌入向量一起输入到Transformer编码器中,最后取第一个向量作为类别预测结果。所以,这个追加的向量可以理解为其他9个图像patch寻找的类别信息。
Il convient de noter qu’un vecteur de classification est ajouté au vecteur de longueur N dans la formule ci-dessus, qui est utilisé pour l’apprentissage des informations de catégorie dans le processus de formation Transformer. En supposant que l’image est divisée en 9 patchs, c’est-à-dire N = 9, il y a 9 vecteurs entrés dans l’encodeur Transformer, mais pour ces 9 vecteurs, quel vecteur doit être utilisé pour la prédiction de classification ? Ni l’un ni l’autre ne convient. Une approche raisonnable consiste à ajouter artificiellement un vecteur de catégorie, qui est un vecteur d’intégration apprenable, et de l’entrer dans l’encodeur Transformer avec les 9 autres vecteurs d’intégration de patch, et enfin de prendre le premier vecteur comme résultat de prédiction de catégorie. Par conséquent, ce vecteur supplémentaire peut être compris comme les informations de catégorie recherchées par les 9 autres patchs d’image.
- Transformer encoder
集合了类别向量追加、图像块嵌入和位置编码为一体的嵌入输入向量后,就可以直接进入Transformer编码器部分了,主要包括MSA和MLP两个部分。
MSA: 包括多头自注意力、跳跃连接 (Add) 和层规范化 (Norm)
MLP: 前馈网络 (FFN)、跳跃连接 (Add) 和层规范化 (Norm)
这两个部分结合起来当作Transformer encoder block,可以重复N次
Après avoir intégré le vecteur d’entrée intégré de l’ajout de vecteur de catégorie, l’intégration de blocs d’image et le codage de position, il peut entrer directement dans la partie codeur du transformateur, qui comprend principalement MSA et MLP.
MSA : comprend l’auto-attention multi-têtes, les connexions ignorées (Add) et la normalisation des couches (Norm)
MLP : Réseaux Feedforward (FFN), Skip Connections (Add) et Layer Normalization (Norm)
Ces deux parties sont combinées en un bloc d’encodeur Transformer, qui peut être répété N fois
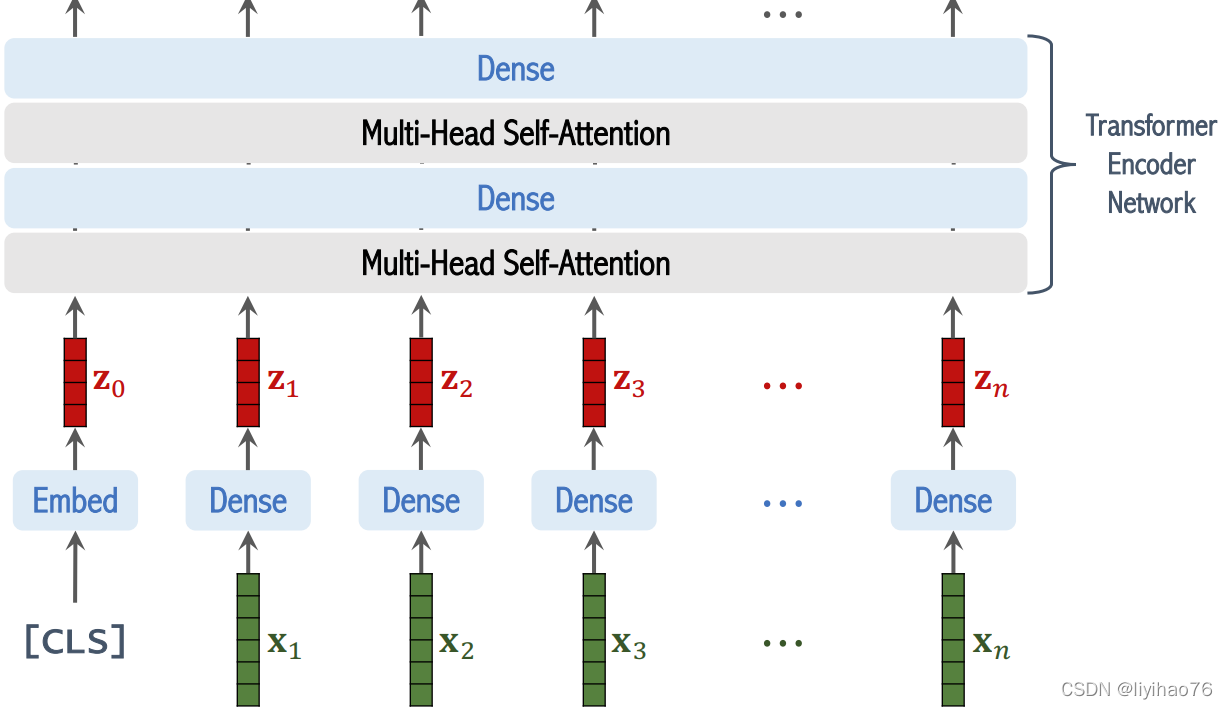
- Classification Head
最后使用MLP,根据class token的输出进行分类
Enfin, utilisez MLP pour classer en fonction de la sortie du jeton de classe
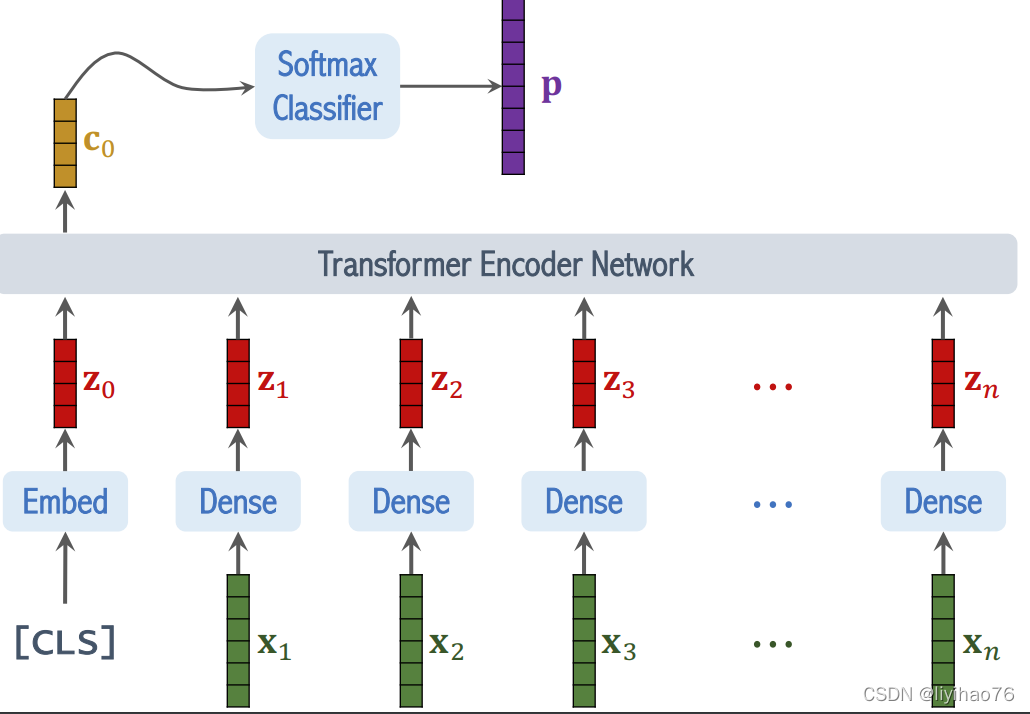
Composition
1. PatchEmbeddingBlock
Description
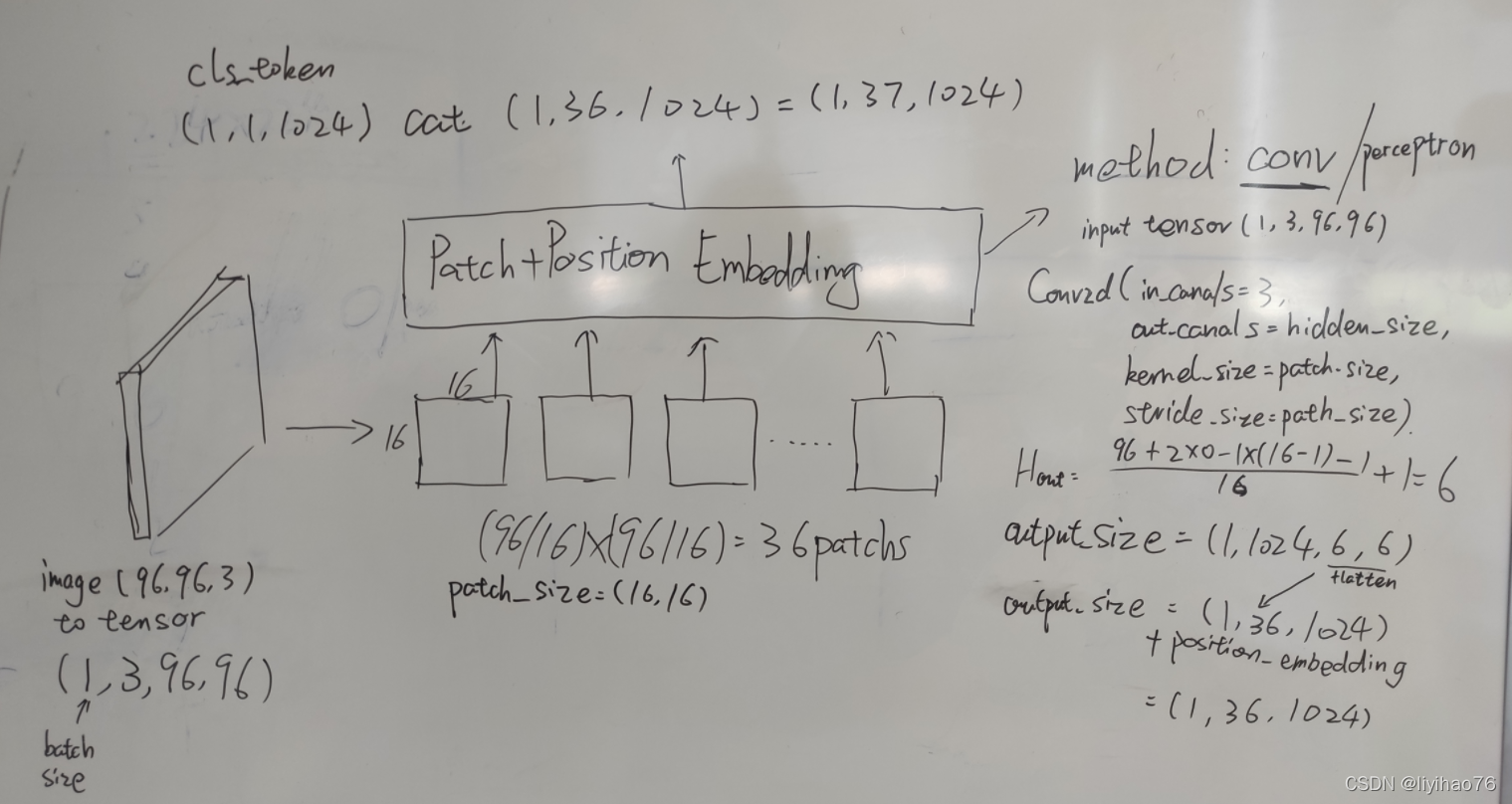
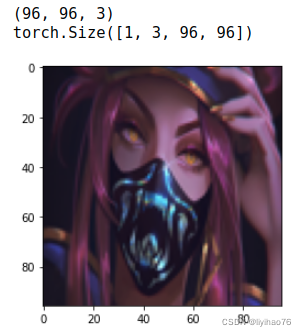
大小为(96,96)的原始图片作为我们的输入
Image originale de taille (96,96) comme entrée
import matplotlib.pyplot as plt
from PIL import Image
import numpy as np
I = Image.open('./test.jpg')
I = I.resize((96,96))
I.show()
I_array = np.array(I)
plt.imshow(I_array)
print(I_array.shape)
I_array = I_array.transpose(2 , 0, 1)
I_array = I_array[np.newaxis,:,:,:]
im = torch.from_numpy(I_array).float()
print(im.shape)
计算patch参数
Calculer les paramètres de patch
# 计算要分成多少个patches
img_size = (96,96)
patch_size = (16,16)
n_patches = np.prod([im_d // p_d for im_d, p_d in zip(img_size, patch_size)]) #累乘
print(n_patches) # 36
# 计算图片embedding之后的大小
in_channels = 3
patch_dim = in_channels * np.prod(patch_size) # 16*16*3 将图片flatten
print(patch_dim) # 768
通过conv的方法实现embedding,还有一种方法perceptron
L’embedding est implémentée par la méthode conv, et il existe également une méthode perceptron
spatial_dims = 2
hidden_size = 1024
conv_embeding = Conv[Conv.CONV, spatial_dims](
in_channels=in_channels, out_channels=hidden_size, kernel_size=patch_size, stride=patch_size)
position_embeddings = nn.Parameter(torch.zeros(1, n_patches, hidden_size))
cls_token = nn.Parameter(torch.zeros(1, 1, hidden_size))

卷积的操作既实现了patch的分割,也实现了embedding
L’opération de convolution réalise à la fois la segmentation et l’embedding des patchs
最后加入position_embeddings和cls_token
Ajoutez enfin position_embeddings et cls_token
resultat = conv_embeding(im)
print(resultat.shape) # torch.Size([1, 1024, 6, 6])
resultat = resultat.flatten(2).transpose(-1, -2)
print(resultat.shape) # torch.Size([1, 36, 1024])
embeddings = resultat + position_embeddings
print(resultat.shape) # torch.Size([1, 36, 1024])
cls_token = nn.Parameter(torch.zeros(1, 1, hidden_size))
print(cls_token.shape) # torch.Size([1, 1, 1024])
cls_token = cls_token.expand(embeddings.shape[0], -1, -1)
print(cls_token.shape) # torch.Size([1, 1, 1024])
embeddings = torch.cat((cls_token, embeddings), dim=1)
print(embeddings.shape) # torch.Size([1, 37, 1024])
Source code
import math
from typing import Sequence, Union
import numpy as np
import torch
import torch.nn as nn
from monai.networks.layers import Conv
from monai.utils import ensure_tuple_rep, optional_import
from monai.utils.module import look_up_option
Rearrange, _ = optional_import("einops.layers.torch", name="Rearrange")
SUPPORTED_EMBEDDING_TYPES = {"conv", "perceptron"}
class PatchEmbeddingBlock(nn.Module):
"""
A patch embedding block, based on: "Dosovitskiy et al.,
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale <https://arxiv.org/abs/2010.11929>"
Example::
>>> from monai.networks.blocks import PatchEmbeddingBlock
>>> PatchEmbeddingBlock(in_channels=4, img_size=32, patch_size=8, hidden_size=32, num_heads=4, pos_embed="conv")
"""
def __init__(
self,
in_channels: int,
img_size: Union[Sequence[int], int],
patch_size: Union[Sequence[int], int],
hidden_size: int,
num_heads: int,
pos_embed: str,
dropout_rate: float = 0.0,
spatial_dims: int = 3,
) -> None:
"""
Args:
in_channels: dimension of input channels.
img_size: dimension of input image.
patch_size: dimension of patch size.
hidden_size: dimension of hidden layer.
num_heads: number of attention heads.
pos_embed: position embedding layer type.
dropout_rate: faction of the input units to drop.
spatial_dims: number of spatial dimensions.
"""
super().__init__()
if not (0 <= dropout_rate <= 1): # check
raise ValueError("dropout_rate should be between 0 and 1.")
if hidden_size % num_heads != 0: # check
raise ValueError("hidden size should be divisible by num_heads.")
self.pos_embed = look_up_option(pos_embed, SUPPORTED_EMBEDDING_TYPES) #check
img_size = ensure_tuple_rep(img_size, spatial_dims) # check
patch_size = ensure_tuple_rep(patch_size, spatial_dims) # check
for m, p in zip(img_size, patch_size): # check
if m < p:
raise ValueError("patch_size should be smaller than img_size.")
if self.pos_embed == "perceptron" and m % p != 0:
raise ValueError("patch_size should be divisible by img_size for perceptron.")
self.n_patches = np.prod([im_d // p_d for im_d, p_d in zip(img_size, patch_size)])# 累乘
self.patch_dim = in_channels * np.prod(patch_size)
self.patch_embeddings: nn.Module
if self.pos_embed == "conv":
self.patch_embeddings = Conv[Conv.CONV, spatial_dims](
in_channels=in_channels, out_channels=hidden_size, kernel_size=patch_size, stride=patch_size
)
elif self.pos_embed == "perceptron":
# for 3d: "b c (h p1) (w p2) (d p3)-> b (h w d) (p1 p2 p3 c)"
chars = (("h", "p1"), ("w", "p2"), ("d", "p3"))[:spatial_dims]
from_chars = "b c " + " ".join(f"({k} {v})" for k, v in chars)
to_chars = f"b ({' '.join([c[0] for c in chars])}) ({' '.join([c[1] for c in chars])} c)"
axes_len = {f"p{i+1}": p for i, p in enumerate(patch_size)}
self.patch_embeddings = nn.Sequential(
Rearrange(f"{from_chars} -> {to_chars}", **axes_len), nn.Linear(self.patch_dim, hidden_size)
)
self.position_embeddings = nn.Parameter(torch.zeros(1, self.n_patches, hidden_size))
self.cls_token = nn.Parameter(torch.zeros(1, 1, hidden_size))
self.dropout = nn.Dropout(dropout_rate)
self.trunc_normal_(self.position_embeddings, mean=0.0, std=0.02, a=-2.0, b=2.0)
self.apply(self._init_weights)
def _init_weights(self, m):
if isinstance(m, nn.Linear):
self.trunc_normal_(m.weight, mean=0.0, std=0.02, a=-2.0, b=2.0)
if isinstance(m, nn.Linear) and m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.LayerNorm):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1.0)
def trunc_normal_(self, tensor, mean, std, a, b): # trunc_normal初始化,从截断的正态分布中输出随机值
# From PyTorch official master until it's in a few official releases - RW
# Method based on https://people.sc.fsu.edu/~jburkardt/presentations/truncated_normal.pdf
def norm_cdf(x):
return (1.0 + math.erf(x / math.sqrt(2.0))) / 2.0
with torch.no_grad():
l = norm_cdf((a - mean) / std)
u = norm_cdf((b - mean) / std)
tensor.uniform_(2 * l - 1, 2 * u - 1)
tensor.erfinv_()
tensor.mul_(std * math.sqrt(2.0))
tensor.add_(mean)
tensor.clamp_(min=a, max=b)
return tensor
def forward(self, x):
x = self.patch_embeddings(x)
if self.pos_embed == "conv":
x = x.flatten(2).transpose(-1, -2)
embeddings = x + self.position_embeddings
embeddings = self.dropout(embeddings)
return embeddings
To use
from monai.networks.blocks.patchembedding import PatchEmbeddingBlock
patch_embedding = PatchEmbeddingBlock(
in_channels=3,
img_size=(96,96),
patch_size = (16, 16),
hidden_size=800,
num_heads=1,
pos_embed='conv',
dropout_rate=0.1,
spatial_dims=2,
)
x= patch_embedding(im)
print(x.shape) # torch.Size([1, 36, 1024])
print(patch_embedding)
'''
PatchEmbeddingBlock(
(patch_embeddings): Conv2d(3, 800, kernel_size=(16, 16), stride=(16, 16))
(dropout): Dropout(p=0.1, inplace=False)
)
'''
2. Selfattention
Description
视觉注意力机制是人类视觉所特有的大脑信号处理机制。人类视觉通过快速扫描全局图像,获得需要重点关注的目标区域,也就是一般所说的注意力焦点,而后对这一区域投入更多注意力资源,以获取更多所需要关注目标的细节信息,而抑制其他无用信息。
Le mécanisme d’attention visuelle est un mécanisme de traitement du signal cérébral unique à la vision humaine. La vision humaine obtient la zone cible sur laquelle se concentrer en balayant rapidement l’image globale, qui est généralement appelée le centre d’attention, puis investit plus de ressources d’attention dans cette zone pour obtenir des informations plus détaillées sur la cible qui nécessite une attention. Et supprimer les autres informations inutiles.
对于每一个输入,我们计算他和其他输入之间的相关性,然后实现数据的重新分配。所以输出和输入的大小相同。
Pour chaque entrée, nous calculons la corrélation entre celle-ci et les autres entrées, puis réalisons la redistribution des données. Ainsi, la sortie et l’entrée ont la même taille.
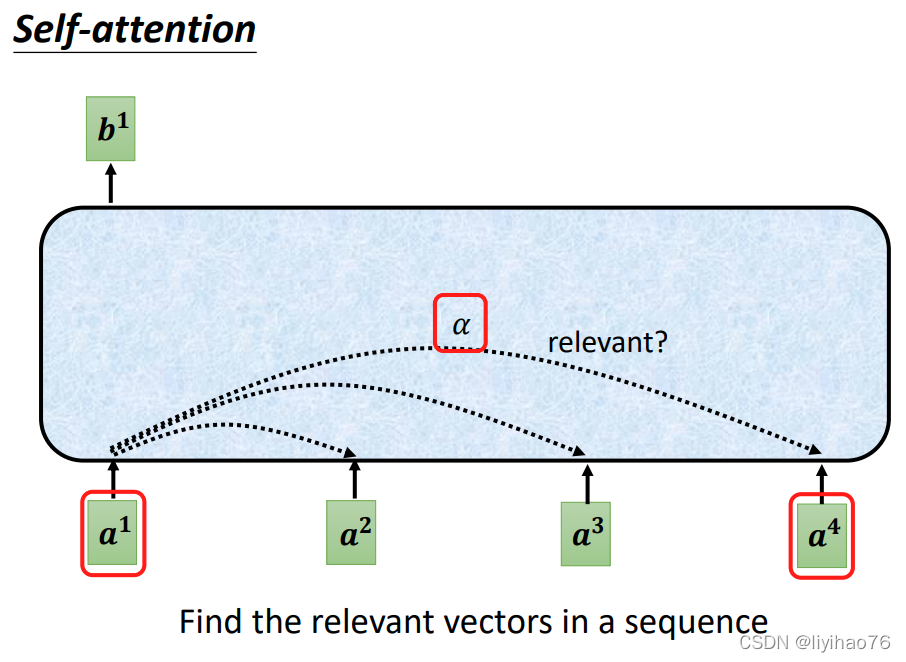
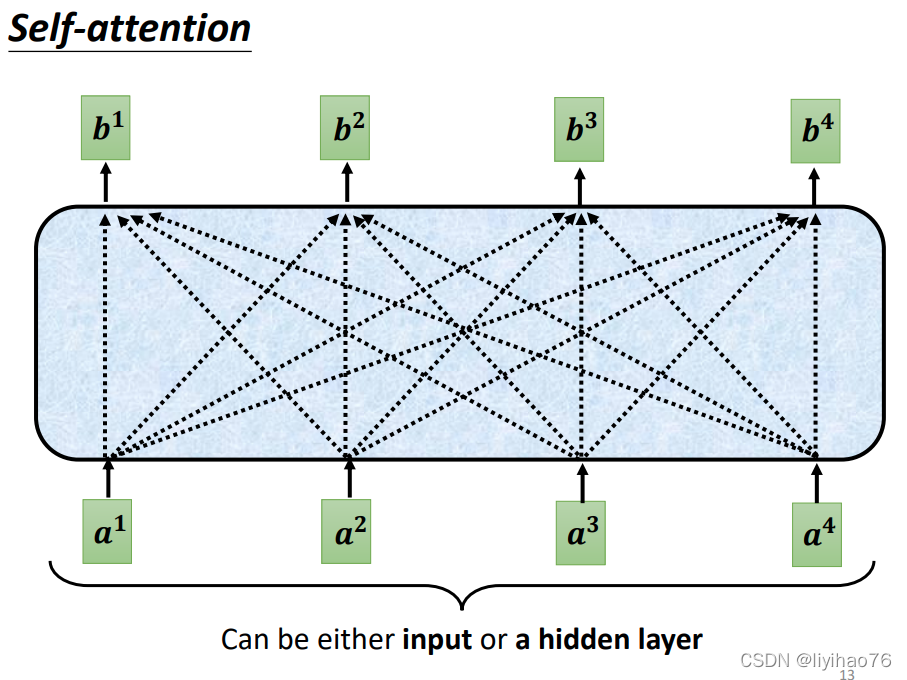
计算self attention的第一步是从每个Encoder的输入向量上创建3个向量。对于每个单词,我们创建一个Query向量,一个Key向量和一个Value向量。这些向量是通过输入乘以我们训练过程中创建的3个训练矩阵而产生的。
La première étape du calcul de l’auto-attention consiste à créer 3 vecteurs à partir du vecteur d’entrée de chaque encodeur. Pour chaque mot, nous créons un vecteur Query, un vecteur Key et un vecteur Value. Ces vecteurs sont produits en multipliant l’entrée par les 3 matrices de formation créées lors de notre processus de formation.
计算self attention的第二步是计算得分。通过将query向量和key向量点击来对相应的单词打分。当我们在某个位置编码单词时,分数决定了这个输入和其他输入的相关程度。
La deuxième étape du calcul de l’attention personnelle consiste à calculer le score. Noter les mots correspondants en cliquant sur le vecteur requête et le vecteur clé. Lorsque nous encodons un mot à une certaine position, le score détermine la pertinence de cette entrée par rapport aux autres entrées.
然后将每个Value向量乘以经过softmax得分,最后累加加权值的向量。 这会在此位置产生self-attention层的输出(对于第一个输入)。
Chaque vecteur de valeur est ensuite multiplié par le score softmax, et enfin le vecteur de valeurs pondérées est accumulé. Cela produit la sortie de la couche d’auto-attention à cette position (pour la première entrée).
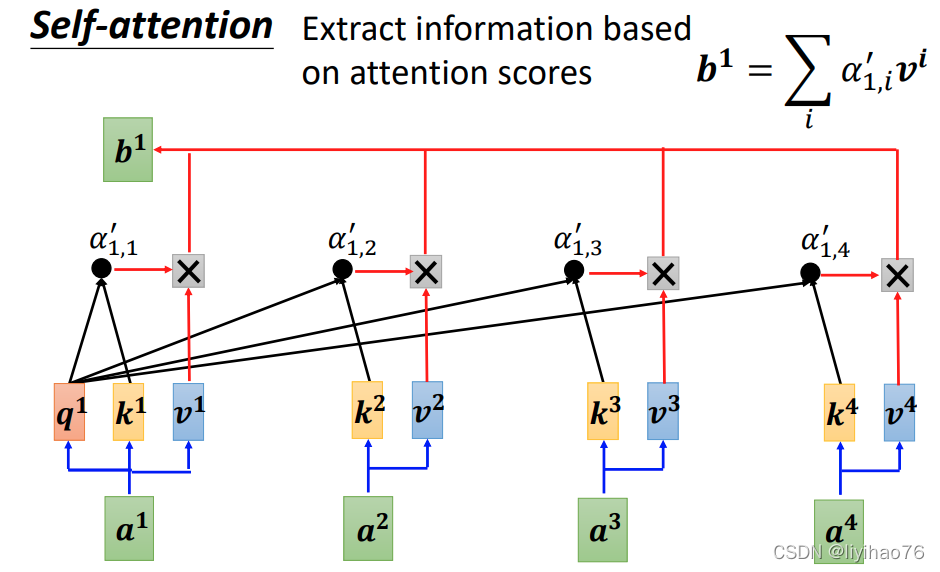
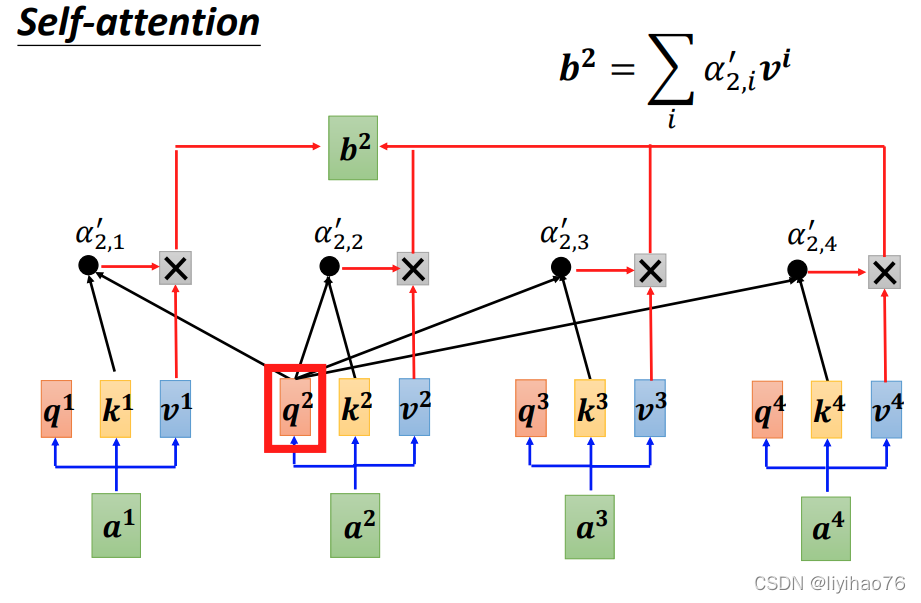
这些计算可以并行
Ces calculs peuvent être parallélisés

Ces calculs peuvent être parallélisés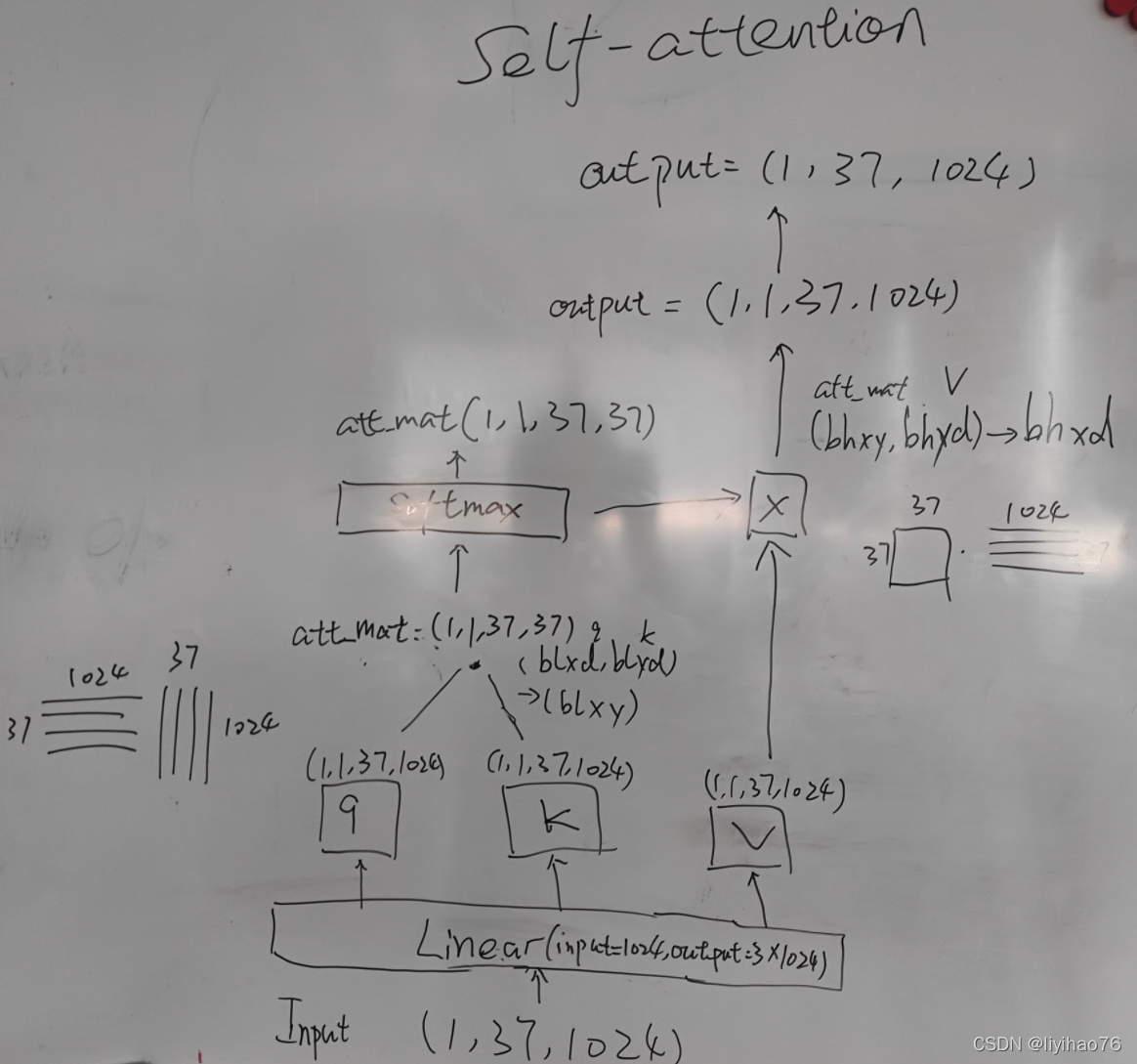
print(embeddings.shape) # torch.Size([1, 37, 1024])
qkv = nn.Linear(hidden_size, hidden_size * 3, bias=False)
embeddings = qkv(embeddings)
print(embeddings.shape) # torch.Size([1, 37, 3072])
num_heads = 1
q, k, v = einops.rearrange(embeddings, "b h (qkv l d) -> qkv b l h d", qkv=3, l=num_heads)
print(q.shape) # torch.Size([1, 1, 37, 1024])
print(k.shape) # torch.Size([1, 1, 37, 1024])
print(v.shape) # torch.Size([1, 1, 37, 1024])
计算A:att_mat
head_dim = 800 // 1
scale = head_dim**-0.5
att_mat = (torch.einsum("blxd,blyd->blxy", q, k) * scale).softmax(dim=-1)
print(att_mat.shape) # torch.Size([1, 1, 37, 37])
A和V计算结果
x = torch.einsum("bhxy,bhyd->bhxd", att_mat, v)
print(x.shape) # torch.Size([1, 1, 37, 1024])
x = einops.rearrange(x, "b h l d -> b l (h d)")
print(x.shape) # torch.Size([1, 37, 1024])
out_proj = nn.Linear(1024, 1024)
x = out_proj(x)
Multi-head Self-attention
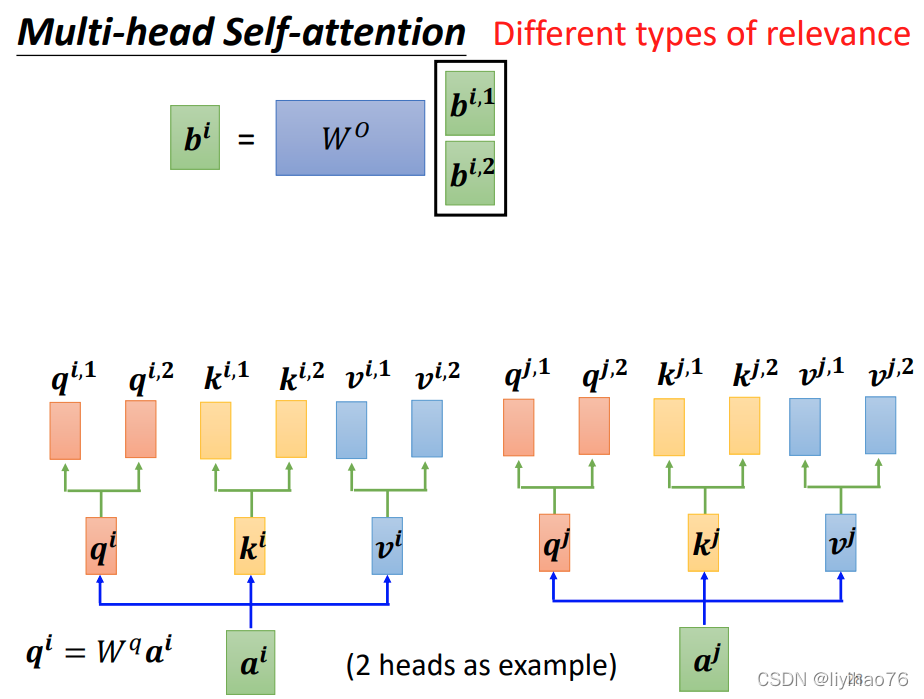

Source code
import torch
import torch.nn as nn
from monai.utils import optional_import
einops, _ = optional_import("einops")
class SABlock(nn.Module):
"""
A self-attention block, based on: "Dosovitskiy et al.,
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale <https://arxiv.org/abs/2010.11929>"
"""
def __init__(self, hidden_size: int, num_heads: int, dropout_rate: float = 0.0) -> None:
"""
Args:
hidden_size: dimension of hidden layer.
num_heads: number of attention heads.
dropout_rate: faction of the input units to drop.
"""
super().__init__()
if not (0 <= dropout_rate <= 1):
raise ValueError("dropout_rate should be between 0 and 1.")
if hidden_size % num_heads != 0:
raise ValueError("hidden size should be divisible by num_heads.")
self.num_heads = num_heads
self.out_proj = nn.Linear(hidden_size, hidden_size)
self.qkv = nn.Linear(hidden_size, hidden_size * 3, bias=False)
self.drop_output = nn.Dropout(dropout_rate)
self.drop_weights = nn.Dropout(dropout_rate)
self.head_dim = hidden_size // num_heads
self.scale = self.head_dim**-0.5
def forward(self, x):
q, k, v = einops.rearrange(self.qkv(x), "b h (qkv l d) -> qkv b l h d", qkv=3, l=self.num_heads)
att_mat = (torch.einsum("blxd,blyd->blxy", q, k) * self.scale).softmax(dim=-1)
att_mat = self.drop_weights(att_mat)
x = torch.einsum("bhxy,bhyd->bhxd", att_mat, v)
x = einops.rearrange(x, "b h l d -> b l (h d)")
x = self.out_proj(x)
x = self.drop_output(x)
return x
To use
from monai.networks.blocks.selfattention import SABlock
attn = SABlock(hidden_size=1024, num_heads=1, dropout_rate=0.1)
x = attn(embeddings)
print(x.shape) # torch.Size([1, 37, 1024])
3. Transformerblock
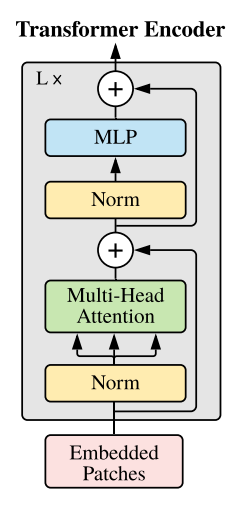
Source code
import torch.nn as nn
from monai.networks.blocks.mlp import MLPBlock
from monai.networks.blocks.selfattention import SABlock
class TransformerBlock(nn.Module):
"""
A transformer block, based on: "Dosovitskiy et al.,
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale <https://arxiv.org/abs/2010.11929>"
"""
def __init__(self, hidden_size: int, mlp_dim: int, num_heads: int, dropout_rate: float = 0.0) -> None:
"""
Args:
hidden_size: dimension of hidden layer.
mlp_dim: dimension of feedforward layer.
num_heads: number of attention heads.
dropout_rate: faction of the input units to drop.
"""
super().__init__()
if not (0 <= dropout_rate <= 1):
raise ValueError("dropout_rate should be between 0 and 1.")
if hidden_size % num_heads != 0:
raise ValueError("hidden_size should be divisible by num_heads.")
self.mlp = MLPBlock(hidden_size, mlp_dim, dropout_rate)
self.norm1 = nn.LayerNorm(hidden_size)
self.attn = SABlock(hidden_size, num_heads, dropout_rate)
self.norm2 = nn.LayerNorm(hidden_size)
def forward(self, x):
x = x + self.attn(self.norm1(x))
x = x + self.mlp(self.norm2(x))
return x
class MLPBlock(nn.Module):
"""
A multi-layer perceptron block, based on: "Dosovitskiy et al.,
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale <https://arxiv.org/abs/2010.11929>"
"""
def __init__(self, hidden_size: int, mlp_dim: int, dropout_rate: float = 0.0) -> None:
"""
Args:
hidden_size: dimension of hidden layer.
mlp_dim: dimension of feedforward layer.
dropout_rate: faction of the input units to drop.
"""
super().__init__()
if not (0 <= dropout_rate <= 1):
raise ValueError("dropout_rate should be between 0 and 1.")
self.linear1 = nn.Linear(hidden_size, mlp_dim)
self.linear2 = nn.Linear(mlp_dim, hidden_size)
self.fn = nn.GELU()
self.drop1 = nn.Dropout(dropout_rate)
self.drop2 = nn.Dropout(dropout_rate)
def forward(self, x):
x = self.fn(self.linear1(x))
x = self.drop1(x)
x = self.linear2(x)
x = self.drop2(x)
return x
ViT Source code
from typing import Sequence, Union
import torch
import torch.nn as nn
from monai.networks.blocks.patchembedding import PatchEmbeddingBlock
from monai.networks.blocks.transformerblock import TransformerBlock
__all__ = ["ViT"]
class ViT(nn.Module):
"""
Vision Transformer (ViT), based on: "Dosovitskiy et al.,
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale <https://arxiv.org/abs/2010.11929>"
"""
def __init__(
self,
in_channels: int,
img_size: Union[Sequence[int], int],
patch_size: Union[Sequence[int], int],
hidden_size: int = 768,
mlp_dim: int = 3072,
num_layers: int = 12,
num_heads: int = 12,
pos_embed: str = "conv",
classification: bool = False,
num_classes: int = 2,
dropout_rate: float = 0.0,
spatial_dims: int = 3,
) -> None:
"""
Args:
in_channels: dimension of input channels.
img_size: dimension of input image.
patch_size: dimension of patch size.
hidden_size: dimension of hidden layer.
mlp_dim: dimension of feedforward layer.
num_layers: number of transformer blocks.
num_heads: number of attention heads.
pos_embed: position embedding layer type.
classification: bool argument to determine if classification is used.
num_classes: number of classes if classification is used.
dropout_rate: faction of the input units to drop.
spatial_dims: number of spatial dimensions.
Examples::
# for single channel input with image size of (96,96,96), conv position embedding and segmentation backbone
>>> net = ViT(in_channels=1, img_size=(96,96,96), pos_embed='conv')
# for 3-channel with image size of (128,128,128), 24 layers and classification backbone
>>> net = ViT(in_channels=3, img_size=(128,128,128), pos_embed='conv', classification=True)
# for 3-channel with image size of (224,224), 12 layers and classification backbone
>>> net = ViT(in_channels=3, img_size=(224,224), pos_embed='conv', classification=True, spatial_dims=2)
"""
super().__init__()
if not (0 <= dropout_rate <= 1):
raise ValueError("dropout_rate should be between 0 and 1.")
if hidden_size % num_heads != 0:
raise ValueError("hidden_size should be divisible by num_heads.")
self.classification = classification
self.patch_embedding = PatchEmbeddingBlock(
in_channels=in_channels,
img_size=img_size,
patch_size=patch_size,
hidden_size=hidden_size,
num_heads=num_heads,
pos_embed=pos_embed,
dropout_rate=dropout_rate,
spatial_dims=spatial_dims,
)
self.blocks = nn.ModuleList(
[TransformerBlock(hidden_size, mlp_dim, num_heads, dropout_rate) for i in range(num_layers)]
)
self.norm = nn.LayerNorm(hidden_size)
if self.classification:
self.cls_token = nn.Parameter(torch.zeros(1, 1, hidden_size))
self.classification_head = nn.Sequential(nn.Linear(hidden_size, num_classes), nn.Tanh())
def forward(self, x):
x = self.patch_embedding(x)
if self.classification:
cls_token = self.cls_token.expand(x.shape[0], -1, -1)
x = torch.cat((cls_token, x), dim=1)
hidden_states_out = []
for blk in self.blocks:
x = blk(x)
hidden_states_out.append(x)
x = self.norm(x)
if self.classification:
x = self.classification_head(x[:, 0])
To use
from monai.networks.nets import ViT
net = ViT(patch_size = (16, 16, 16), in_channels=3, img_size=(128,128,128),
pos_embed='conv', classification=True, num_classes =4,num_layers = 12)
ViT(
(patch_embedding): PatchEmbeddingBlock(
(patch_embeddings): Conv3d(3, 768, kernel_size=(16, 16, 16), stride=(16, 16, 16))
(dropout): Dropout(p=0.0, inplace=False)
)
(blocks): ModuleList(
(0): TransformerBlock(
(mlp): MLPBlock(
(linear1): Linear(in_features=768, out_features=3072, bias=True)
(linear2): Linear(in_features=3072, out_features=768, bias=True)
(fn): GELU()
(drop1): Dropout(p=0.0, inplace=False)
(drop2): Dropout(p=0.0, inplace=False)
)
(norm1): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(attn): SABlock(
(out_proj): Linear(in_features=768, out_features=768, bias=True)
(qkv): Linear(in_features=768, out_features=2304, bias=False)
(drop_output): Dropout(p=0.0, inplace=False)
(drop_weights): Dropout(p=0.0, inplace=False)
)
(norm2): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
)
(1): TransformerBlock(
(mlp): MLPBlock(
(linear1): Linear(in_features=768, out_features=3072, bias=True)
(linear2): Linear(in_features=3072, out_features=768, bias=True)
(fn): GELU()
(drop1): Dropout(p=0.0, inplace=False)
(drop2): Dropout(p=0.0, inplace=False)
)
(norm1): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(attn): SABlock(
(out_proj): Linear(in_features=768, out_features=768, bias=True)
(qkv): Linear(in_features=768, out_features=2304, bias=False)
(drop_output): Dropout(p=0.0, inplace=False)
(drop_weights): Dropout(p=0.0, inplace=False)
)
(norm2): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
)
(2): TransformerBlock(
(mlp): MLPBlock(
(linear1): Linear(in_features=768, out_features=3072, bias=True)
(linear2): Linear(in_features=3072, out_features=768, bias=True)
(fn): GELU()
(drop1): Dropout(p=0.0, inplace=False)
(drop2): Dropout(p=0.0, inplace=False)
)
(norm1): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(attn): SABlock(
(out_proj): Linear(in_features=768, out_features=768, bias=True)
(qkv): Linear(in_features=768, out_features=2304, bias=False)
(drop_output): Dropout(p=0.0, inplace=False)
(drop_weights): Dropout(p=0.0, inplace=False)
)
(norm2): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
)
(3): TransformerBlock(
(mlp): MLPBlock(
(linear1): Linear(in_features=768, out_features=3072, bias=True)
(linear2): Linear(in_features=3072, out_features=768, bias=True)
(fn): GELU()
(drop1): Dropout(p=0.0, inplace=False)
(drop2): Dropout(p=0.0, inplace=False)
)
(norm1): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(attn): SABlock(
(out_proj): Linear(in_features=768, out_features=768, bias=True)
(qkv): Linear(in_features=768, out_features=2304, bias=False)
(drop_output): Dropout(p=0.0, inplace=False)
(drop_weights): Dropout(p=0.0, inplace=False)
)
(norm2): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
)
(4): TransformerBlock(
(mlp): MLPBlock(
(linear1): Linear(in_features=768, out_features=3072, bias=True)
(linear2): Linear(in_features=3072, out_features=768, bias=True)
(fn): GELU()
(drop1): Dropout(p=0.0, inplace=False)
(drop2): Dropout(p=0.0, inplace=False)
)
(norm1): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(attn): SABlock(
(out_proj): Linear(in_features=768, out_features=768, bias=True)
(qkv): Linear(in_features=768, out_features=2304, bias=False)
(drop_output): Dropout(p=0.0, inplace=False)
(drop_weights): Dropout(p=0.0, inplace=False)
)
(norm2): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
)
(5): TransformerBlock(
(mlp): MLPBlock(
(linear1): Linear(in_features=768, out_features=3072, bias=True)
(linear2): Linear(in_features=3072, out_features=768, bias=True)
(fn): GELU()
(drop1): Dropout(p=0.0, inplace=False)
(drop2): Dropout(p=0.0, inplace=False)
)
(norm1): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(attn): SABlock(
(out_proj): Linear(in_features=768, out_features=768, bias=True)
(qkv): Linear(in_features=768, out_features=2304, bias=False)
(drop_output): Dropout(p=0.0, inplace=False)
(drop_weights): Dropout(p=0.0, inplace=False)
)
(norm2): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
)
(6): TransformerBlock(
(mlp): MLPBlock(
(linear1): Linear(in_features=768, out_features=3072, bias=True)
(linear2): Linear(in_features=3072, out_features=768, bias=True)
(fn): GELU()
(drop1): Dropout(p=0.0, inplace=False)
(drop2): Dropout(p=0.0, inplace=False)
)
(norm1): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(attn): SABlock(
(out_proj): Linear(in_features=768, out_features=768, bias=True)
(qkv): Linear(in_features=768, out_features=2304, bias=False)
(drop_output): Dropout(p=0.0, inplace=False)
(drop_weights): Dropout(p=0.0, inplace=False)
)
(norm2): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
)
(7): TransformerBlock(
(mlp): MLPBlock(
(linear1): Linear(in_features=768, out_features=3072, bias=True)
(linear2): Linear(in_features=3072, out_features=768, bias=True)
(fn): GELU()
(drop1): Dropout(p=0.0, inplace=False)
(drop2): Dropout(p=0.0, inplace=False)
)
(norm1): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(attn): SABlock(
(out_proj): Linear(in_features=768, out_features=768, bias=True)
(qkv): Linear(in_features=768, out_features=2304, bias=False)
(drop_output): Dropout(p=0.0, inplace=False)
(drop_weights): Dropout(p=0.0, inplace=False)
)
(norm2): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
)
(8): TransformerBlock(
(mlp): MLPBlock(
(linear1): Linear(in_features=768, out_features=3072, bias=True)
(linear2): Linear(in_features=3072, out_features=768, bias=True)
(fn): GELU()
(drop1): Dropout(p=0.0, inplace=False)
(drop2): Dropout(p=0.0, inplace=False)
)
(norm1): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(attn): SABlock(
(out_proj): Linear(in_features=768, out_features=768, bias=True)
(qkv): Linear(in_features=768, out_features=2304, bias=False)
(drop_output): Dropout(p=0.0, inplace=False)
(drop_weights): Dropout(p=0.0, inplace=False)
)
(norm2): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
)
(9): TransformerBlock(
(mlp): MLPBlock(
(linear1): Linear(in_features=768, out_features=3072, bias=True)
(linear2): Linear(in_features=3072, out_features=768, bias=True)
(fn): GELU()
(drop1): Dropout(p=0.0, inplace=False)
(drop2): Dropout(p=0.0, inplace=False)
)
(norm1): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(attn): SABlock(
(out_proj): Linear(in_features=768, out_features=768, bias=True)
(qkv): Linear(in_features=768, out_features=2304, bias=False)
(drop_output): Dropout(p=0.0, inplace=False)
(drop_weights): Dropout(p=0.0, inplace=False)
)
(norm2): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
)
(10): TransformerBlock(
(mlp): MLPBlock(
(linear1): Linear(in_features=768, out_features=3072, bias=True)
(linear2): Linear(in_features=3072, out_features=768, bias=True)
(fn): GELU()
(drop1): Dropout(p=0.0, inplace=False)
(drop2): Dropout(p=0.0, inplace=False)
)
(norm1): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(attn): SABlock(
(out_proj): Linear(in_features=768, out_features=768, bias=True)
(qkv): Linear(in_features=768, out_features=2304, bias=False)
(drop_output): Dropout(p=0.0, inplace=False)
(drop_weights): Dropout(p=0.0, inplace=False)
)
(norm2): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
)
(11): TransformerBlock(
(mlp): MLPBlock(
(linear1): Linear(in_features=768, out_features=3072, bias=True)
(linear2): Linear(in_features=3072, out_features=768, bias=True)
(fn): GELU()
(drop1): Dropout(p=0.0, inplace=False)
(drop2): Dropout(p=0.0, inplace=False)
)
(norm1): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(attn): SABlock(
(out_proj): Linear(in_features=768, out_features=768, bias=True)
(qkv): Linear(in_features=768, out_features=2304, bias=False)
(drop_output): Dropout(p=0.0, inplace=False)
(drop_weights): Dropout(p=0.0, inplace=False)
)
(norm2): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
)
)
(norm): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(classification_head): Sequential(
(0): Linear(in_features=768, out_features=4, bias=True)
(1): Tanh()
)
)

















 4220
4220

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









