









文章目录
论文题目: Generative Adversarial Nets
原论文下载地址: https://arxiv.org/pdf/1406.2661.pdf
今天来看一下生成对抗网络GAN,这个还蛮有意思的,这篇论文是GAN系列的开山鼻祖。
这是一篇很重要的论文,即使不做GAN专门的研究,也要好好读一下这篇论文。
一、Abstract(摘要)
摘要作者提出他的生成对抗框架的大概。这里不是模型了,之前的VGG啊 inception什么的都是模型,这里原文使用的是framework 就是框架,相当于定了个范式,该框架下会产生 生成式模型。
里面有两个模型:
- 生成器G:捕捉原始数据分布。
- 判别器D:判断生成的数据来自原始数据分布还是生成器G生成的假数据。
生成器G的目标就是使判别器D尽可能的犯错,判别器D的目标就是尽可能的分辨出来生成器G生成的假图。
G和D就对抗起来了~~~所以论文叫做GAN的意思就是两边‘干’起来?哈哈。
G和D都使用多层感知机,就是多层全连接。
最终目标:生成器G能够产生使得判别器D无法判断出真假的图像。
二、Introduction(引言)
引言第一段提出了当前深度学习中的痛点,就是大多数模型,图像啊,音频啊,文字啊等等,都是在判别器D上的发展,比如卷积池化BN dropout等,而生成器G没怎么发展。
生成器要拟合原始数据概率分布,产生出符合该概率分布的新图,他就要通过一堆比较复杂的概率运算,于是作者提出了一种新的生成式模型规避了这个问题。就是不去拟合原始数据了,而是通过对抗学习的方式生成符合该概率分布的假图。
引言的最后一段作者说他的大框架可以生成各种各样的GAN模型,本文使用了一个特例就是他的D和G模型,这俩都是多层全连接网络, 生成器G输入随机数,判别器D输入真假图像,这种网络叫做:adversarial nets。
用传统的深度学习网络来训练,训练完了用生成器G前向传播生成假图。
可以看出来这是个端到端的训练过程。
三、Related work(相关工作)
这一章节我看过好几个版本,有的版本里直接就没有这一章节,后来查了一下,发现原始版本是没有这一章的,其实是,这毕竟是一篇GAN的开山之作,没有前人工作可以借鉴也是理所应当的,后面又加入这一章节,可能是为了发期刊吧。
这一章我觉得不用太深究,作者提到了很多前人的工作,很多的模型,深究的话我觉得得花很长时间,但是现在这些老模型都不用了,所以大概看一下就行。
- 限制玻尔兹曼机(RBMs),深玻尔兹曼机(DBMs)。由随机变量所有状态的全局求和/积分进行归一化。这个数量(配分函数)和它的梯度是棘手的。
- 深度置信网络(DBNs)。存在与无向和有向模型相关的计算困难。
- 分数匹配和噪声对比估计(NCE)。当模型学习到即使是在观察变量的一个小子集上的一个近似正确的分布之后,学习速度也会显著减慢。
总之作者就是说了一堆,然后表明他们的模型都不行。
四、Adversarial nets(对抗网络)
这一章属于比较硬核的数学推理阶段。
其中参数:
- Z :随机噪声;
- P(Z): 随机噪声Z服从的概率分布;
- G :生成器,输入Z,输出假图;
- D:判别器,输入图像,输出该图真的概率;
- X:真实数据服从的概率分布;
- Pg:生成器生成的假图服从的概率分布;
最小化函数: log(1-D(G)(z))
论文中给出公式:
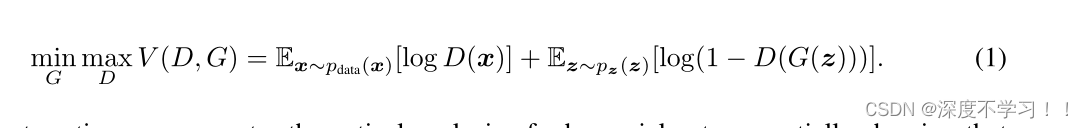
可以看到是两个E相加,即两个期望部分的相加。
给定生成器,训练判别器:(最大化)
左边的期望:当输入图像时真图,判别器输出越大越好,期望最大化。
右边的期望:当输入假图时,输出越小越好,期望最小化。
给定判别器,训练生成器:(最小化)
左边是个常数,只需要优化右边就行。
将他们俩交替训练,使得D和G都能达到最优。
论文后面给出了一张图:
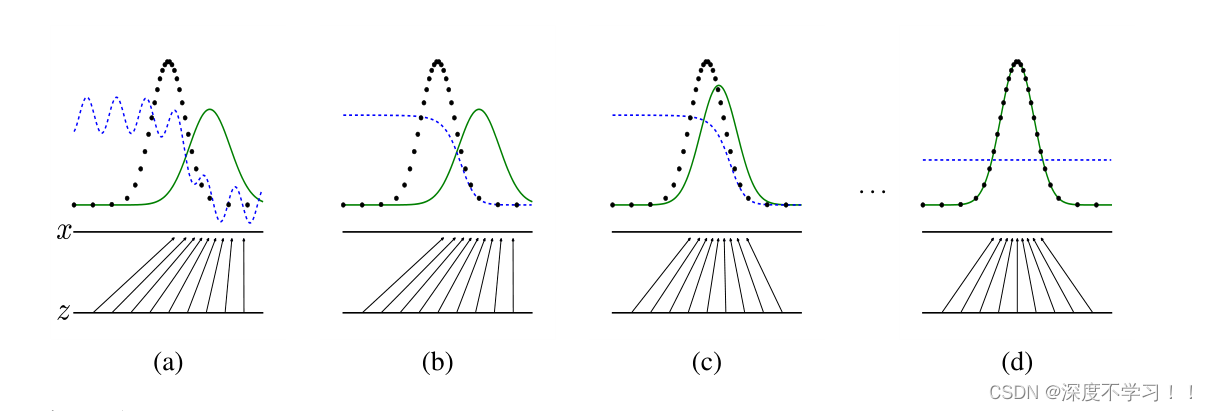
这张图里下面的就是X和Z轴之间的时噪声空间,X上面蓝线是判别器预测为真图的概率,黑线是真图分布,绿线是假图分布,从a中可以看到,蓝线在真图(黑线)附近 比较高,在绿线(假图)附近比较低,这属于一个正常情况。
训练判别器D之后为b图,可以看到 真图打高分,假图打低分效果已经非常好了。
训练生成器G之后为c图,生成器就是让判别器出错,所以c图中也可以看到,绿线生成的假图故意往蓝线处靠。
经过不断的优化交替训练到d图的时候,绿色和黑色的真假图已经完全重合 ,并且蓝线也完全无法分辨真假图。
五、Theoretical Results(理论结果)
这一章就是各种的公式。
上来给了一段伪代码,总体上是 在一个for循环里,训练K次判别器,训练1次生成器,里面的公式就还是上面说过的那个。
下面为一个循环:
-
在每一步中,先采样m个噪音样本,再采样m个真实样本。真实样本放进判别器,噪声放到生成器生成假图,假图给判别器,然后判别器求参数梯度啥的之后更新判别器,这样做K步。
-
之后再采样m个噪声样本,放进生成器。这样做1步
步骤:采样噪声 -> 生成器 -> 假图 -> 判别器 -> 真图概率。
目标:判别器输出的真图概率越大越好。
后面是各种的数学证明,我是看不了。溜了溜了。
GAN工作原理的通俗理解:
假设我们玩游戏,一个游戏画面的输出背后可能有几百行代码在控制。对于GAN来讲,GAN模仿这个游戏,就只模仿画面,GAN并不知道游戏背后代码的控制逻辑,他只猜了一下可能有一百行代码在控制,那GAN这边也就产生一百个向量来模仿,用这些向量来输出游戏画面。
GAN猜测的游戏背后的代码数量就是拟合的数据分布的过程。
六、小总结
- GAN直接利用现有的深度学习进行端到端的训练。
- 一个生成器G一个判别器D,两者对抗 使得G生成出D无法判别真假的图。
- GAN是一种生成式模型,相比较其他生成模型(玻尔兹曼机和GSNs)只用到了反向传播,而不需要复杂的马尔科夫链。
- GAN采用的是一种无监督的学习方式训练,可以被广泛用在无监督学习和半监督学习领域。
- 不是直接使用原始数据训练,也不是去直接拟合原始数据分布,而是用判别器间接训练,也就是说G的梯度更新信息来自判别器D,而不是来自数据样本。
- 由于其使用判别器间接训练,所以一定程度上避免了过拟合问题。
- 步骤:采样噪声 -> 生成器 -> 假图 -> 判别器 -> 真图概率。
- GAN不适合处理离散形式的数据,比如文本。

















 978
978











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











