









这两篇论文放一起看吧。
starganV1 :点我下载
starganV2 : 点我下载
Stargan-V1
贡献总结
- 提出 StarGAN 网络模型,仅使用一个 G 和 D 就可以实现多个领域之间图像生成和训练。
- 采用 mask vector 方法控制所有可用域图像标签以实现训练集之间的多领域图像转换。
- StarGAN 相对于基准模型, 在面部属性转移和面部表情合成的任务中有更好的效果 (具体数据请参看原论文中的实验部分)
核心
之前看的cyclegan 或者是pix2pix 都是两个领域之间互相转换,多个领域之间转换需要训练多个生成器,可以看论文中给出的那个图:
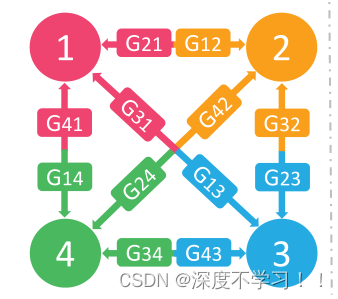
实现4个领域之间的相互转换,需要训练 12组生成器,也就是 n*(n-1)。
而作者的stargan实现了多领域之间的转换,并且只需要训练一个生成器和一个判别器。
随后作者给出他的stargan结构:
可以看到,有五个数据域,但只有一个G。
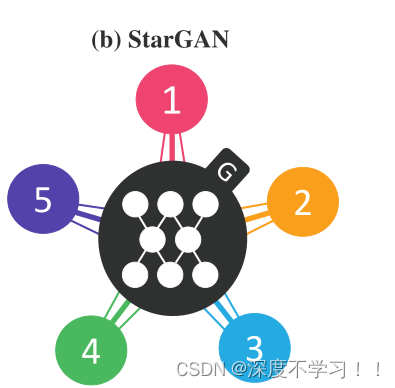
像一个星型,所以叫stargan。
之前输入都是噪声+输入,或者构思的素描轮廓什么的, 这里的stargan输入另要一个类别,类别可以这样理解,因为只需要一个生成器和一个判别器,但是这里却有很多个种类,所以要告诉生成器G你要生成的是哪一种风格的照片,所以引入了一个 向量,比如 1000 代表1号分类,0100代表二号分类,这样通过一个G再加一个向量 就能知道生成那种风格了。
判别器也是同理,也需要这个向量,毕竟他需要知道要判别哪一个域的真假图。
作者给出了整体结构的图:
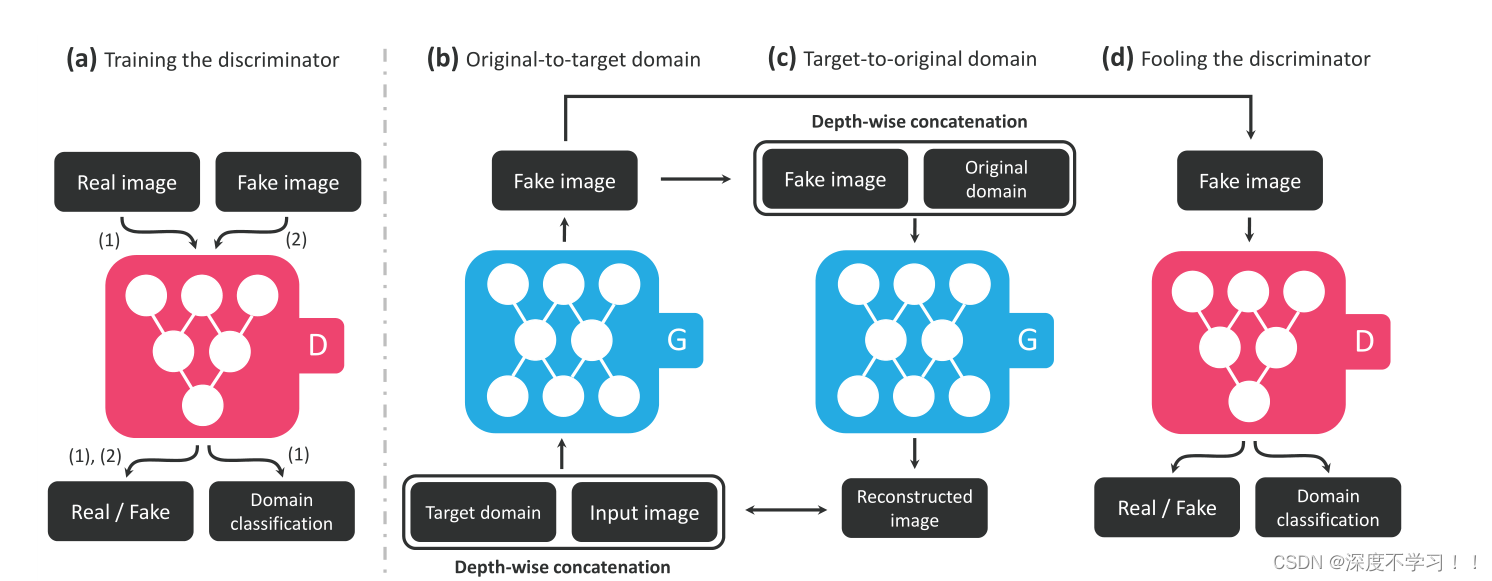
(a)D 对真假图片进行判别,真图片判真,假图片判假,真图片被分类到相应域。(b)G 接受真图片和目标域标签并生成假图片;
(c)G 在给定原始域标签的情况下将假图片重建为原始图片(重构损失);
(d)G 尽可能生成与真实图像无法区分的图像,并且通过 D 分类到目标域。
这张图中间的两个蓝色块就是参考cyclegan的那个循环结构,和他基本一样,判别器也是patchgan 的划分小块采样方法。
这里说的重构损失,Reconstruction loss ,其实就是cyclegan里的循环一致性损失,防止对抗生成模式崩塌的损失函数。
所以 生成器和判别器的输出和输入都是两个,一个是真假图,还有一个分类标签, 这个标签是one-hot编码表示的,作者将此输入称为mask vector。
更进一步的来说,stargan的核心之一就是可以同时训练多个数据集,但每个数据集包含不同的数据和不同的标签,所以对于每一个数据集,他仅仅是部分标签已知,在重构的时候需要完整标签,所以作者引入的mask vector,向量掩码 m,使 StarGAN 模型能够忽略不确定的标签(置为0),专注于特定数据集提供的明确的已知标签,D就拥有了可以生成假图的能力和判断图片属于那个类别的能力。
损失函数
生成器损失函数:Adversarial Loss(对抗损失)+Domain Classification Loss(域分类损失)+Reconstruction Loss (重构损失)
判别器损失函数:对抗损失+域分类损失
对抗损失:
这就是常见的GAN网络里的传统损失函数,目标:D 无法区分出来输出图像和生成图像之间的差别。(作者改进为梯度惩罚)
目标域分类损失函数:
对于一个输入图像 x 和目标分布标签 c ,目标是将 x 转换为输出图像 y后能够被正确分类为目标分布 c,作者在D之上还加入了一个辅助分类器。
重构误差:
这个没啥说的,就是cyclegan里的循环一致性损失函数,让假图通过G还原回真图, 在这个循环里,输入的真图和还原出来的真图越接近越好,防止对抗生成网络坍塌现象。
Stargan-V2
V1中的不足
首先介绍两个名词;
- 域(domain):一组可以在视觉上独特分类的图片,并且每一张图都有独特外观(称为样式style)。例如,可以设置图片的域是基于人的性别,这种情况下样式(style)可以包括妆容、胡须、发型等。
- 风格(style):每个图像具有的独特外观。
作者先提出了V1中的不足;缺少样式多样性和领域多样性,其实就是上面说的,V1里为了用一个G生成多个领域的图片,加入了一个类似于编码向量的标签用于区别不同的领域,比如1000这种独热编码。而在V2里更换了这种编码,并加入了一些模块。
- 样式多样性:即在从一个domain迁移到另外一个domain时需要生成这个domain的多个style。例如:女性,男性之间进行转化时:domain的style为:妆容,发型,胡须等等。并且不同的domain-specific style code生成的style都不一样。
- 领域多样性:一个Generator(source-img)可以通过接收不同的style-code生成不同domain的图片。
核心
为了解决上述的样式多样性和领域多样性问题。StarGAN v2提出两个模块,一个映射网络mapping network和一个样式编码器style encoder。 映射网络学习将随机高斯噪声转换为style code,编码器则学习从给定的参考图像中提取style code。 考虑到多个域,两个模块都具有多个输出分支,每个分支都提供特定域的style code
文章的核心就是下面这张图了:
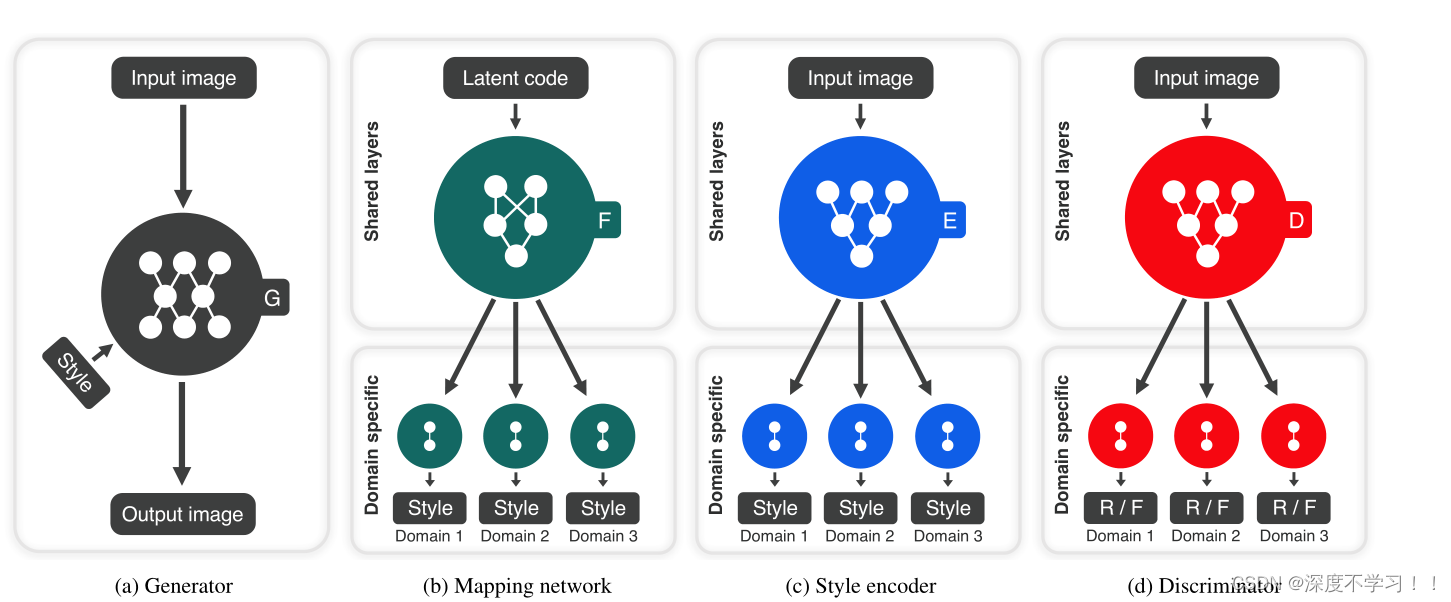
- 左边第一个:黑色的,生成器G,要输入图像x和特定风格编码s,s由映射网络或者风格编码器提供。使用adaptive instance normalization(AdaIN)来注入s到G中。最后生成器生成一张具有s风格的图片。
- 左边第二个:深绿色的,mapping network,给定一个潜在编码z和一个域y,映射网络生成风格编码 s,映射网络由带有多个输出分支的MLP组成,用来为所有可用域提供风格编码。映射网络通过随机采样潜在向量z和域y来提供多样化风格编码。
多任务架构允许映射网络高效地学习所有域的风格表达。(即给定随机高斯噪声和一个域,来生成风格编码) - 左边第三个:蓝色的。style encoder,给定图像x和它对应的域y,来生成相应的风格编码。
- 左边第四个,红色的,判别器D是一个多任务判别器,由多个输出分支组成。每个分支是一个二进制分类,判断图片是该域里的真图还是G生成的假图。
损失函数
对抗目标Adversarial objective:
这个就不说了,GAN都有这么个传统的损失函数,生成器要骗过判别器,判别器要努力识别假图。
风格重建Style reconstruction:
这个损失函数其实就是说,你G生成图像的时候是依据某种风格,依据该风格生成出来的假图经过一个encoder得到的结果应该和G使用的风格接近。这个优点类似于循环一致性损失了,就让你生成的假图强迫带上原始的风格或者说是需要的风格。
样式多样化Style diversification:
这就是用来控制风格多样性的,使用mapping network,输入的是随机噪声+一个域,通过一样的网络,所以生成的风格近似但不完全一样,该损失函数就是计算两个风格并使其差异尽可能的大(不同风格通过G生成的不同结果的差异)。
保留源特征Preserving source characteristics:
这个就是cyclegan里面的那个循环一致性损失,防止对抗生成模型崩塌的损失函数,不多说了。

















 367
367











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











