







本文记录学习《算法图解》过程中的一些知识点,作为个人笔记。
《算法图解》个人笔记
第一章:算法简介
0. 算法复杂度指的是随着输入size的操作数的增速,而非秒。

第二章:选择排序
0. python中数组的存储是顺序的,访问方便,支持随机访问,插入删除麻烦;链表是非顺序的,插入删除方便,访问不方便。

第三章:递归
0. 递归:基线条件(边界)+递归条件
1. 栈与递归
第四章:分治
0. 归并排序的复杂度为O(n*logn),快排的平均复杂度为O(n*logn)。为何工程上通常采用快排。
答:快排常数项小。


1. 归并排序相比插入/选择/冒泡快的原因:mearge过程组内不重复计算。
第五章:散列表/哈希表/字典
0. 数组的读取速度为O(1),哈希表的查找速度为O(1);哈希表利用了数组的结构。
创建哈希表:a=dict() or a={}。
- 列表查找速度为O(n),哈希表为O(1)。
- 缓存:网站将数据以哈希表的形式存储,使用查找的方法避免重复计算。

- 哈希表的冲突
当两个变量的哈希映射结果相同时,产生冲突。以哈希表+链表的形式解决冲突;选择好的哈希函数至关重要。


- 哈希表的填装因子。


填装因子大于1意味着商品数量超过了数组的位置数。一旦填装因子开始增大,你就需要在散列表中添加位置,这被称为调整长度( resizing) 。填装因子越低,发生冲突的可能性越小,散列表的性能越高。一个不错的经验规则是:一旦填装因子大于0.7,就调整散列表的长度。
第六章:广度优先搜索(最小路径)
0. 构图(节点和边,哈希表构图)与编程实现。
散列表让你能够将键映射到值。在这里,你要将节点映射到其所有邻居



构图顺序不重要。
- 有向图与无向图。无向图代表关系是双向的。

2. 宽度优先搜索图,其实就是按层搜索二叉树。采用队列的形式,维护两个变量last和now记录当前层是否遍历完毕。

注意,如果存在双向图(导致循环),需要维护已遍历的数组,防止重复遍历导致死循环。完整代码如下:

第七章:狄克斯特拉算法(Dijkstra’s algorithm,加权图中最短路径)(从当前花费最小进行遍历,用哈希表维护从开始到每个节点的最小花费及其父节点)
0.

- 加权图最小路径实现的初始化:
首先需要用哈希表构建原始的加权图:
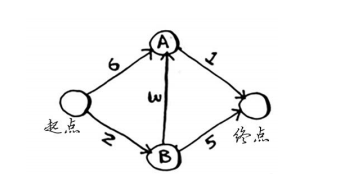
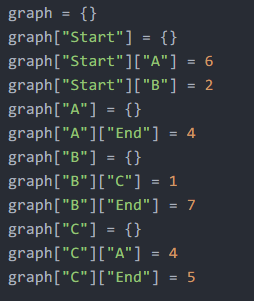
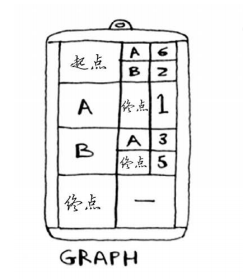
注意,这里采用二维嵌套哈希表,即字典中每个键值里也是字典。
第二步:维护从起点到各个节点最小cost,同样以哈希表形式表示。初始化为从start开始。
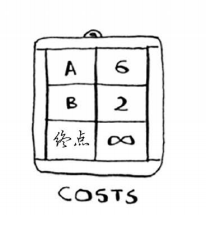

第三步,维护到每个节点最小花费的父节点,方便最后还原路径。
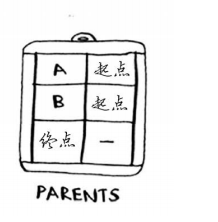
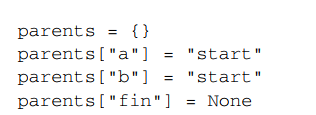

至此,完成初始化。
- 加权图最小路径实现:


- 小结

第八章:贪婪算法(近似解)
NP完全问题:没有快速解法的问题
第九章:动态规划
0. 背包问题:
和挖金矿一样,将背包的重量进行分割。最小商品重量是1,随意按照1为最小单位来划分。该表格(dp[行][列])按行填充值。dp[i][j]代表当前可以购买0-i行的商品组合,在j kg时获取的最大收益。每种动态规划解决方案都涉及网格。

动态规划的传递函数:按照当前行商品买或不买分两类取max。

- 最长公共子序列/子串
第十章 K近邻算法(KNN)
用法:
0. 分类,k个邻居的投票发
1. 推荐,k个邻居的喜好推荐
2. 回顾预测,k个邻居求均值
第十一章 接下来该如何做
- 二分法的树结构:二叉查找树,相比于有序数组,二叉查找树的插入和删除操作复杂度都是O(log(n))


- 并行计算:通过Hadoop 进行MapReduce分布式计算系统(一种编程模型)
MapReduce包括map映射和reduce归并。
Map:


Reduce:
















 5830
5830











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









