









一、A/B测试的定义
A/B测试指的是:为了验证一个新的产品交互设计、产品功能或者策略、算法的效果,在同一个时间段,给多组用户(一般称为对照组和试验组,用户分组方法统计上随机,使得多组用户在统计角度上无差别)分别展示优化前(对照组)和优化后(试验组、可以有多组)的产品交互设计、产品功能或者策略、算法,并通过数据分析,判断优化前后的产品交互设计、产品功能或则策略、算法在一个或者多个评估指标上是否符合预期的一种试验方法。
二、A/B测试的试验类型
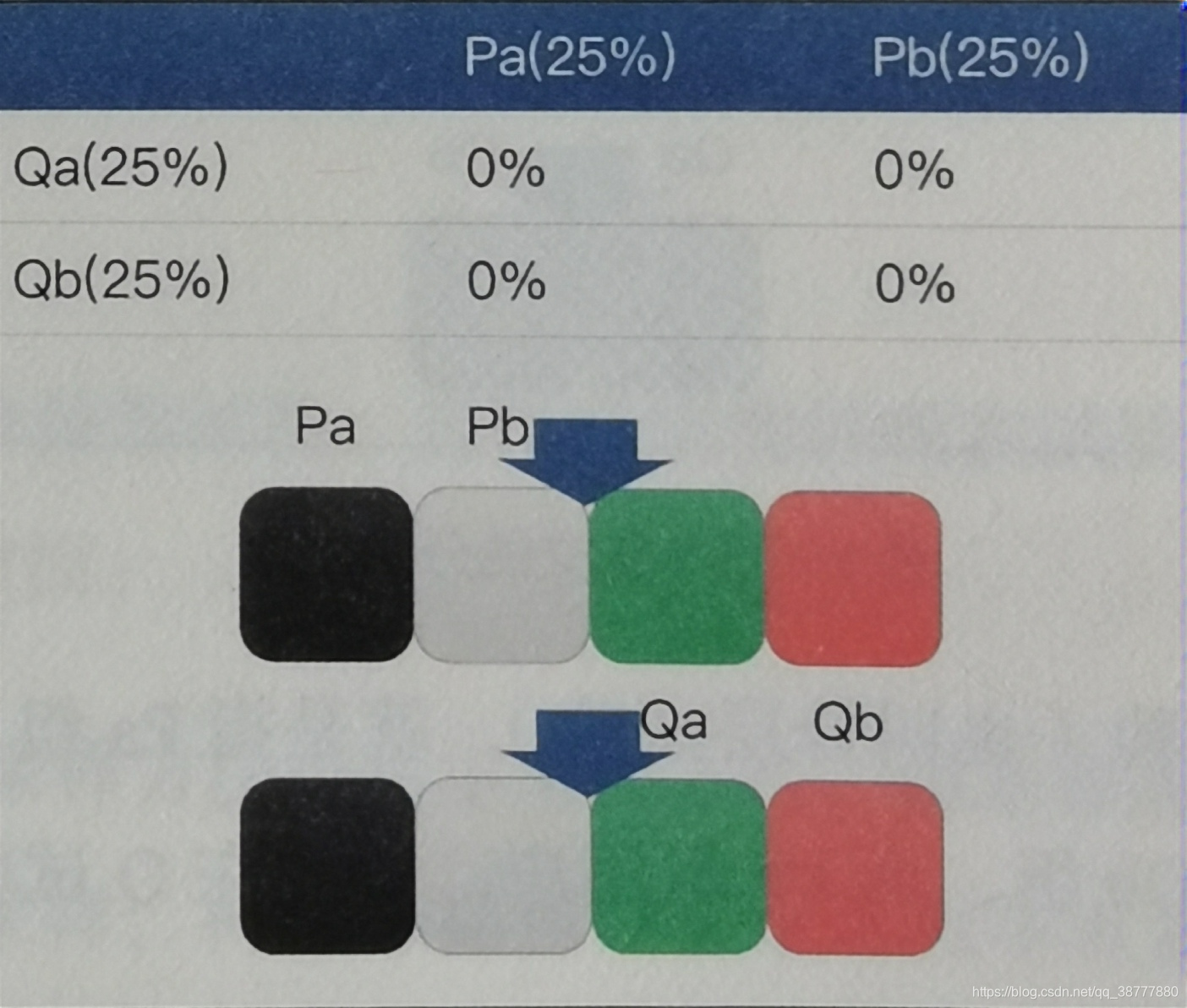
1. 正交实验
指的是:试验P中用户被分为Pa、Pb两组,在Q试验中,用户被分为Qa、Qb两组,且满足Pa组用户在试验Q中被均匀分入到Qa组和Qb组,同样地,Pb组用户在试验Q中也被均匀分入到Qa组和Qb组。这样做的结果就是在Pa试验组且在Qa试验组的用户比例为25%,在Pa试验组且在Qb试验组的用户比例为25%。
但是,正交实验使用的前提是各层试验的参数之间,对优化指标没有相互增强或者抵消的效果。只有这样,才能“各层试验之间的结果不会相互影响”。

2. 互斥实验
P试验使用的流量,Q试验不能使用,而Q试验使用的流量,P试验也不能使用,这种情况叫做互斥试验。这种试验不用担心正交实验里面“各层试验之间的结果不会相互影响”的前提不成立。坏处就是每层试验可用的流量可能会减少,使每层试验所需时间增加、迭代效率变低。
三、“伪”A/B测试
A/B测试存在很多误区,主要有一下几种。
1. 用户分流不科学--辛普森悖论
A/B测试强调对照组和测试组这2个版本的用户分布必须是一致的,否则很有可能导致辛普森悖论。
辛普森悖论:在某个条件下的两组数据,分别讨论时都会满足某个性质,但是一旦合并考虑,却可能导致相反的结论。
举一个关于辛普森悖论的简单例子。一个大学有商学院和法学院两个学院, 这两个学院的女生都抱怨“ 男生录取率比女生录取率高" , 有性别歧视。但是学校做总录取率统计后发现, 总体来说女生录取率远远高于男生录取率。商学院男生的录取率是75 % , 高于商学院女生录取率( 49 % ) , 法学院男生的录取率是10 % , 也高于法学院女生的录取率( 5 % ) , 但是总体来说男生录取率只有21 % , 只占女生录取率42 % 的一半。
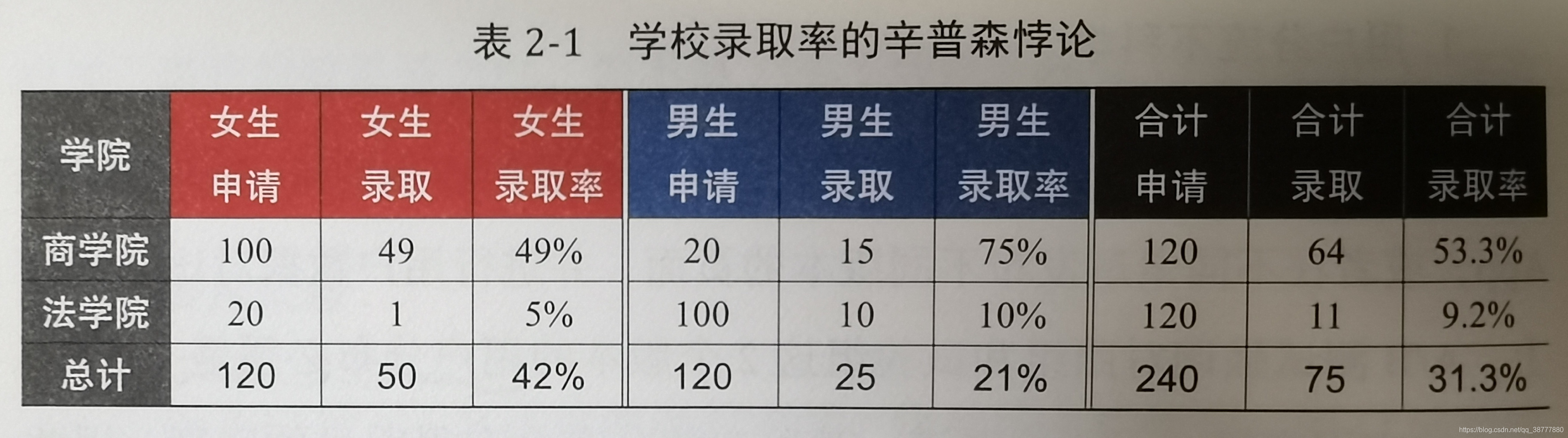
为什么两个学院都是男生录取率高于女生录取率, 但是总人数加起来后男生录取率却不如女生录取率呢? 主要是因为这两个学院男女比例很不一样, 具体的统计学原理我们在后面的章节中会详细介绍。
这个诡异(反直觉)的现象在现实生活中经常被忽略, 毕竟这只是一个统计学现象, 一般情况下都不会影响我们的行动。但是对于使用科学的A/B 测试进行试验的企业决策者来说, 如果不了解辛普森悖论, 就可能会错误地设计试验, 盲目地解读试验结论, 对决策产生不利影响。
因此,想要得到科学可信的A/B测试试验结果,就必须合理地进行正确的流量分割,保证试验组和对照组里的用户特征是一致的,并且都具有代表性,可以代表总体用户特征。
正交实验、互斥实验、定向试验(即针对细分人群的试验)、细分分析是我们规避辛普森悖论的有力工具。规避辛普森悖论,还要注意流量动态调整变化时新旧试验参与者的数据问题,试验组和对照组用户数量的差异问题,以及其他各种问题。
2. 盲目分层
盲目分层指的是所有的试验都放在不同的分层去做,都用正交试验的方式去做。这里需要注意两个正交试验需要保证2个试验所改动的变量相互独立、互不影响,这样的2个试验的数据结果才是可信的,否则有可能会给出错误的数据,做出错误的决策。
3. 不考虑实验数据的统计有效性
不能使用简单的采样统计量作为试验的结论,我们要关注试验的P值、统计功效、置信水平和置信区间,这几个统计量可以判断实验结果的有效性。
四、A/B测试中的抽样
在专业的A/B 测试系统中,用户韋分部算法应该根据田户特征对用户进行聚类,把用户分为具有相同代表性的多个小组,然后通过随机抽样的方式得到对照版本和试验版本的用户群(样本),保证了样本的代表性。
五、分组序贯检验方法
(这里我也没有弄得很透彻,先把书上的理论整理上来,供学习)
有时试验组和对照组的区别比预期的大,试验需要的样本数量比预计的少,可以提前结束试验,节约时间;有时试验组存在重大问题,需要及时终止试验,进行止损操作。由以上可知提前结束试验的需求是存在的,但会带来下面所讨论的多重检验问题:
t检验的相关计算是假设只在试验正常结束以后观察结果。而提前结束试验需要在试验过程中多次观察实时结果,这种预期之外的观察的行为会对准确性产生影响。多次观察试验结果,当出现统计显著时就立刻停止试验,相当于多重检验,第I类错误的概率会显著提高。
假设一次检验的第I类错误的概率是,当多次检验独立时,第I类错误的概率会变成,对进行中的试验进行多次观察,结果具有相关性,第I类错误的概率会比检验独立时小,但是仍然会比一次检验的第I类错误的概率显著提高。
为了免多次检验导致试验的实际第I类错误的概率比标称值高的问题,可以采用下面所述的分组序贯检验方法,对计算结果进行修正,把第I类错误的概率控制在标称值。
分组序贯检验方法把试验分成m个阶段,每个阶段观察一下试验结果,也就是Z统计量。同时给出Z统计量的m个拒绝域,当任何一个阶段的Z统计量落在拒绝域里,则拒绝原假设,提前结束试验。
Z统计量的m个拒绝域由数值方法计算确定,保证试验最终的第I类错误的概率和标称值相同。满足第I类错误的概率的Z值序列有多个,常见的由相等的Z值组成或者由逐渐减小的Z值组成。仿真结果显示,相等值构成的检验序列在早期试验阶段有较高的统计功效,但整个试验周期的统计功效不及逐渐减小的Z值组成的检验序列。
使用分组序贯检验后,置信区间的计算也需要进行调整。每个试验阶段在序列中选取对应的新的Z值来代替原来的Z值,表现为置信区间比之前膨胀了。仿真结果显示,如果逐渐减小Z值组成的检验序列,早期阶段置信区间的膨胀会比较严重,最后阶段的膨胀比例会减少到10%以下。
选择逐渐减小的Z值组成的检验序列普适性更强。对于m个阶段的试验,在第M阶段,可以选取(M/m)^0.5作为Z值比例系数,如对于四个阶段的试验,第一个阶段的Z值最高,逐渐下降,最后一个阶段的Z值下降到第一阶段的1/2。
以上就是学习A/B测试的笔记,祝我们变得更强!

















 563
563

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









