







数据科学最重要的技能之一就是数据可视化,在数据建模过程中,我们比较关心数据之间的相关性,而观察数据相关性我们使用最多的技能之一就是相关性矩阵。数据相关性矩阵可以让我们对数据之间的关联关系有更为直观的理解。这里简单汇总一下使用Python绘制传统相关性矩阵/下三角相关性矩阵/重点相关性矩阵的代码
1. 传统相关性矩阵
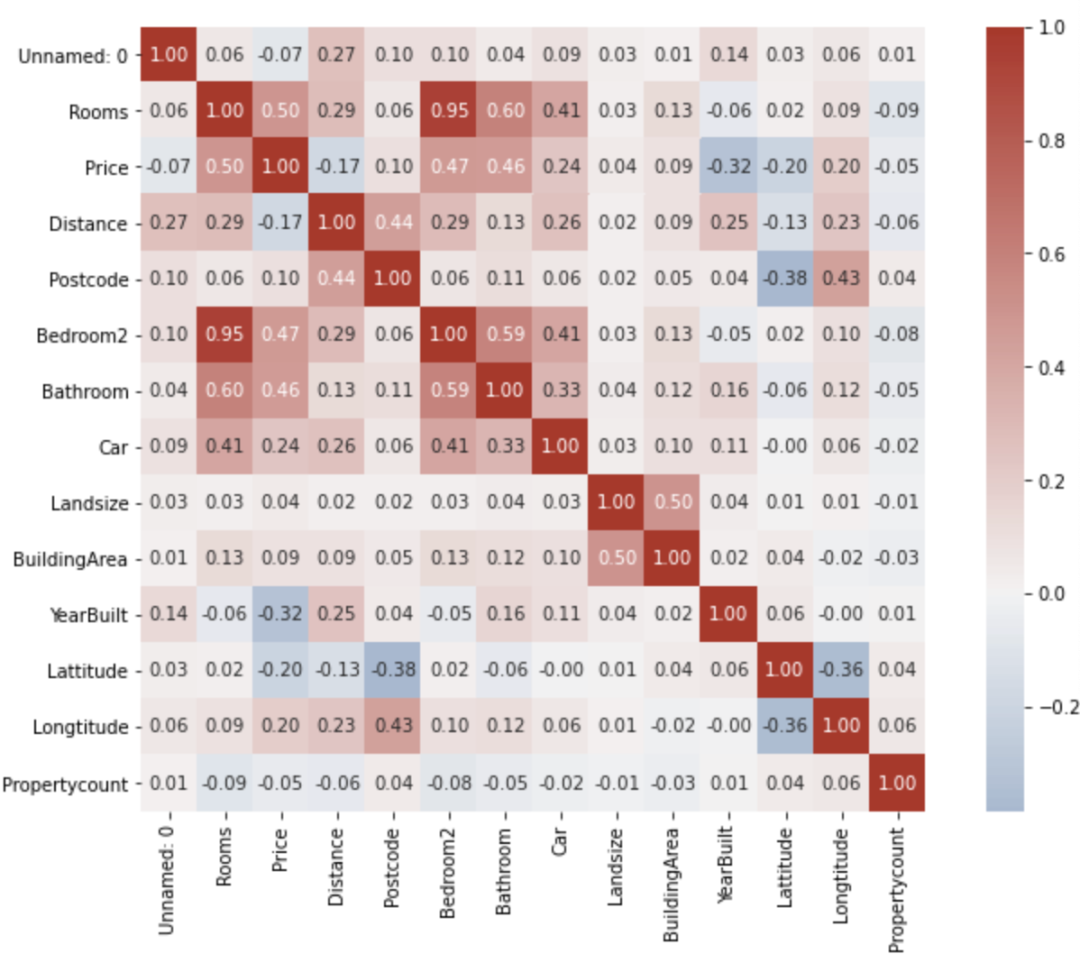
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
%matplotlib inline
df = pd.read_csv('./data/melb_data.csv')
# Calculate pairwise-correlation
matrix = df.corr()
cmap = sns.diverging_palette(250, 15, s=75, l=40, n=9, center="light", as_cmap=True)
plt.figure(figsize=(12, 8))
sns.heatmap(matrix, center=0, annot=True,
fmt='.2f', square=True, cmap=cmap)2. 下三角相关性矩阵
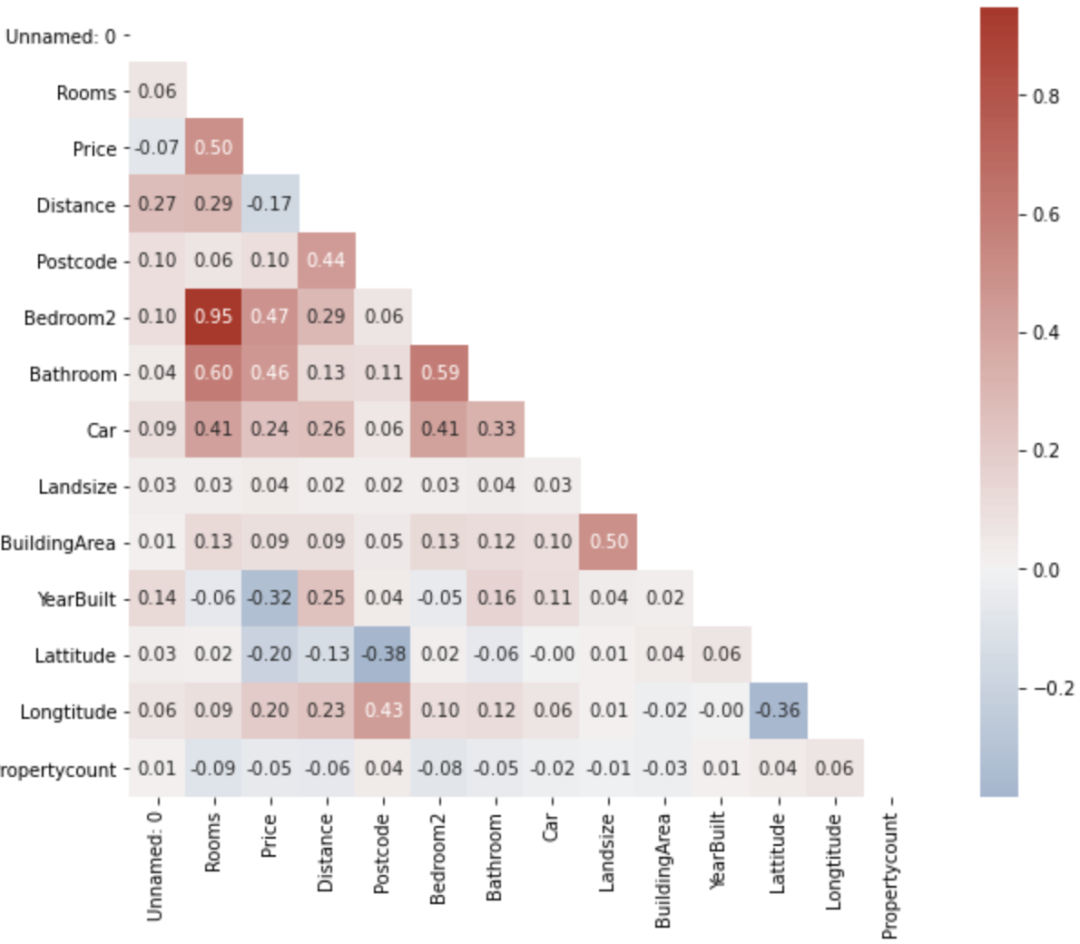
import numpy as np
# mask掉上三角部分
mask = np.triu(np.ones_like(matrix, dtype=bool))
plt.figure(figsize=(12, 8))
sns.heatmap(matrix, mask=mask, center=0, annot=True, fmt='.2f', square=True, cmap=cmap)
3. 重点相关性矩阵(即只画出相关性指数大于阈值的那部分)

# mask掉上三角 & 小于某个阈值的值
mask1 = np.triu(np.ones_like(matrix, dtype=bool))
mask2 = np.abs(matrix) <= 0.1
mask = mask1 | mask2
plt.figure(figsize=(12, 8))
sns.heatmap(matrix, mask=mask, center=0, annot=True,fmt='.2f', square=True, cmap=cmap)















 6598
6598











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









