







go语言优势
- 简单好记的语法,易上手
- 高效率,有比c++/java更高的编译效率,同时运行效率媲美c,同时开发效率非常高
- 生态强大,类库丰富
- 语法检查严格,高安全性
- go mod依赖管理
- 强大的编译检查
- 跨平台交叉编译,win上也能编译出linux可执行程序
- 异步编程复杂度低
- 并发性高、性能好、安全性强、易于部署
hello world
安装goland和go环境后,进入目录使用命令创建项目工程
go mod init hello
创建main.go文件
package main
import "fmt"
func main() {
fmt.Print("hello world")
}
变量
变量声明
所有变量声明后都为默认值,int为0,float为0.0,bool为false,string为空字符串,指针为nil
标准声明
var 变量名 变量类型
批量声明
var (
变量名1 变量类型1
变量名2 变量类型2
变量名3 变量类型3
)
变量初始化
//方式1
var i int
i=1
//方式2
var i int64 = 1
//方式3
var i = 1
//方式4
i:=1
特殊情况,多重赋值
conn,err := net.Dial("tcp","127.0.0.1:5000")
fmt.Print(conn)
fmt.Print(err)
多重赋值的匿名形式:
conn,_ := net.Dial("tcp","127.0.0.1:5000")
fmt.Print(conn)
例子,变量交换
//第一种
a:=1
b:=2
var c
c=a
a=b
b=c
//第二种
a:=1
b:=2
a,b=b,a//python直呼内行
变量基本类型
- bool:布尔型,只有true或者false
- string:字符串类型
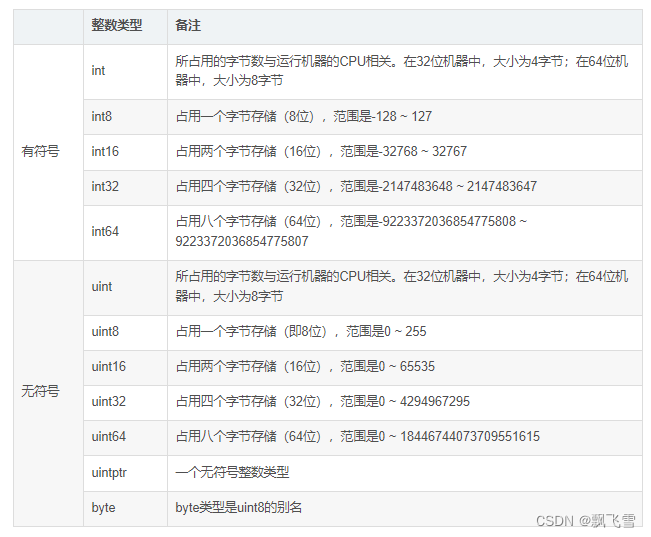
- int(一般占4个字节)、int8(1字节)、int16(2字节)、int32(4字节)、int64(8字节):整型
- uinit(无符号整数)、uint8、uint16、uint32、uint64:无符号类型
- byte(uint8别名):字符类型
- rune(uint32别名,代表1个Unicode码):Unicode码字符类型
- float32、float64:浮点型
- complex64、complex128:复数类型
整型
有符号的范围:-2的(n-1)次方~2的(n-1)次方-1
无符号的范围:0~2的n次方-1
这里的n根据类型来定,比如int32那么n就是32
浮点型
float32:范围1.4e-45到3.4e38
float64:范围4.4e-324到1.8e308
格式化打印:
f:=6.022e23
fmt.Printf("%.2f",f)
例子中的f是使用科学计数法来进行赋值
布尔值
bool只有true和false,且不参与任何计算与类型转换
字符类型
go语言有2种字符类型:
- 一种是uint8类型,或者叫byte类型,代表ascii码字符
- 另一种是rune类型,代表UTF-8字符,等价于int32类型
字符定义:
//使用单引号 表示一个字符
var ch byte = 'A'
//在 ASCII 码表中,A 的值是 65,也可以这么定义
var ch byte = 65
//65使用十六进制表示是41,所以也可以这么定义 \x 总是紧跟着长度为 2 的 16 进制数
var ch byte = '\x41'
//65的八进制表示是101,所以使用八进制定义 \后面紧跟着长度为 3 的八进制数
var ch byte = '\101'
fmt.Printf("%c",ch)
在书写 Unicode 字符时,需要在 16 进制数之前加上前缀\u或者\U。如果需要使用到 4 字节,则使用\u前缀,如果需要使用到 8 个字节,则使用\U前缀。
var ch rune = '\u0041'
var ch1 int64 = '\U00000041'
//格式化说明符%c用于表示字符,%v或%d会输出用于表示该字符的整数,%U输出格式为 U+hhhh 的字符串。
fmt.Printf("%c,%c,%U",ch,ch1,ch)
Unicode 包中内置了一些用于测试字符的函数,这些函数的返回值都是一个布尔值,如下所示(其中 ch 代表字符):
- 判断是否为字母:unicode.IsLetter(ch)
- 判断是否为数字:unicode.IsDigit(ch)
- 判断是否为空白符号:unicode.IsSpace(ch)
字符串类型
一个字符串是一个不可改变的字节序列,字符串可以包含任意的数据,但是通常是用来包含可读的文本,字符串是 UTF-8 字符的一个序列。
go语言中,字符串分为2种,一种为ascii字符串,另一种为utf8字符串。纯英文为ascii字符串,中文或者中英文混合的为utf8字符串
获取字符串长度
- len(str) 表示统计字符串的字节长度
- utf8.RuneCountInString(str) 统计字符串字节长度
s := "a中国"
fmt.Println(len(s)) // 统计的是字节长度
fmt.Println(utf8.RuneCountInString(s)) // 统计字符长度
l := "hello"
fmt.Println(len(l)) // 统计的是字节长度
fmt.Println(utf8.RuneCountInString(l)) // 统计字符长度
结果:
7
3
5
5
字符串切片
func main() {
s := "hello world中国"
fmt.Println(s[10]) // 获取字符串索引位置为n的原始字节
fmt.Println(s[1:12]) // 获取字符串索引位置为1到9的字符串
fmt.Println(s[1:]) // 获取字符串索引位置为1到len(s)-1的字符串
fmt.Println(s[:10]) // 获取字符串索引位置为0到9的字符串
}
结果:
100
ello world�
ello world中国
hello worl
为什么会乱码呢,因为中国需要占用3byte,而这边只有1个byte
字符串拼接
- 使用+号拼接字符串
- 使用fmt包的Sprintf()函数
- 使用strings包的Join()函数
func main() {
s := "hello world中国"
l := "爱你"
fmt.Println(s + l)
fmt.Println(fmt.Sprintf("%s,%s", s, l))
fmt.Println(strings.Join([]string{s, l}, ","))
}
结果:
hello world中国爱你
hello world中国,爱你
hello world中国,爱你
字符串格式化
%c 单一字符
%T 动态类型
%v 本来值的输出
%+v 字段名+值打印
%d 十进制打印数字
%p 指针,十六进制
%f 浮点数
%b 二进制
%s string
常用方法
获取某个字符
对于中英文混合的字符串如何获取某个字符呢?
func main() {
s := "hello中国"
fmt.Println(string([]rune(s)[5]))
}
结果:
中
修改字符串某个字符
func main() {
s1 := "localhost:8080"
fmt.Println(s1)
// 强制类型转换 string to byte
strByte := []byte(s1)
// 下标修改
strByte[len(s1)-1] = '1'
fmt.Println(strByte)
// 强制类型转换 []byte to string
s2 := string(strByte)
fmt.Println(s2)
}
结果:
localhost:8080
[108 111 99 97 108 104 111 115 116 58 56 48 56 49]
localhost:8081
遍历字符串
unicode字符集使用for range进行遍历,ascii字符集可以使用for range或者for循环遍历
var str1 string = "hello"
var str2 string = "hello,哈哈哈哈"
// 遍历
for i :=0; i< len(str1); i++{
fmt.Printf("ascii: %c %d\n", str1[i], str1[i])
}
for _, s := range str1{
fmt.Printf("unicode: %c %d\n ", s, s)
}
// 中文只能用 for range
for _, s := range str2{
fmt.Printf("unicode: %c %d\n ", s, s)
}
结果:
ascii: h 104
ascii: e 101
ascii: l 108
ascii: l 108
ascii: o 111
unicode: h 104
unicode: e 101
unicode: l 108
unicode: l 108
unicode: o 111
unicode: h 104
unicode: e 101
unicode: l 108
unicode: l 108
unicode: o 111
unicode: , 44
unicode: 哈 21704
unicode: 哈 21704
unicode: 哈 21704
unicode: 哈 21704
Split&Replace&Trim
func main() {
fmt.Println(strings.Split("a,b,c", ","))
fmt.Println(strings.Replace("oink oink oink", "k", "ky", 2))
fmt.Println(strings.Replace("oink oink oink", "oink", "moo", -1))
fmt.Println(strings.Trim(" !!! Achtung !!! ", "! "))
fmt.Println(strings.Trim(" Achtung ", " "))
}
结果:
[a b c]
oinky oinky oink
moo moo moo
Achtung
Achtung
ToLower&ToUpper
func main() {
fmt.Println(strings.ToLower("Gopher"))
fmt.Println(strings.ToUpper("Gopher"))
}
结果:
gopher
GOPHER
类型转换
//类型 B 的值 = 类型 B(类型 A 的值)
valueOfTypeB = type B(valueOfTypeA)
//示例
a := 5.0
b := int(a)
作用域
- 函数内定义的变量叫做局部变量
- 函数外定义的变量叫做全局变量
- 函数定义中的变量为形式参数
局部变量
局部变量作用域只能在函数之内
package main
import "fmt"
func main() {
var a = 0
fmt.Print(a)
}
全局变量
全局变量在一个源文件中定义,就可以在所有源文件中使用。当然其他文件使用另一个文件时候需要inport。
全局变量必须以var开头。如果要在外部包使用全局变量首字母要大写。
package main
import "fmt"
var a int
func main() {
a = 9
fmt.Print(a)
}
注意:局部变量和全局变量的名称相同时,优先使用局部变量
形式参数
定义参数时,函数名后面括号中的变量叫做形式参数。形式参数只有函数调用时才会生效,函数调用结束后就会被销毁,在函数调用时,形式参数不会占用实际存储单元,也没有实际值。形式参数会作为函数的局部变量来使用。
package main
import "fmt"
func main() {
fmt.Print(sum(1, 3))
}
func sum(a int, b int) int {
return a + b
}
值传递与引用传递
Go语言中函数的参数有两种传递方式:按值传递和按引用传递。
Go默认使用按值传递来传递参数,也就是传递参数的副本。在函数中对副本的值进行更改操作时,不会影响到原来的变量。
按引用传递其实也可以称作”按值传递”,只不过该副本是一个地址的拷贝,通过它可以修改这个值所指向的地址上的值。
Go语言中,在函数调用时,引用类型(slice、map、interface、channel)都默认使用引用传递,另外使用指针也可以进行引用传递。
注意,结构体不使用引用传递
例子:
package main
import (
"fmt"
)
type dog struct {
name string
age int
}
func (d *dog) setValue(name string, age int) {
d.name = name
d.age = age
}
func test(d *dog) {
d.name = "小花"
}
func test2(d *dog) {
d.setValue("小红", 6)
}
func test3(d dog) {
d.name = "小白"
}
func test4(d dog) {
d.setValue("小米", 2)
}
func main() {
d := dog{"小唐", 10}
test(&d)
fmt.Println(d)
test2(&d)
fmt.Println(d)
test3(d)
fmt.Println(d)
test4(d)
fmt.Println(d)
}
结果:
{小花 10}
{小红 6}
{小红 6}
{小红 6}
我们看到test和test2函数修改了原来结构体的值,但是test3和test4并没有修改。可以看出,如果以结构体作为参数传入函数,会copy一份作为输入
常量
Go语言中的常量使用关键字const定义,用于存储不会改变的数据,常量是在编译时被创建的,即使定义在函数内部也是如此,并且只能是布尔型、数字型(整数型、浮点型和复数)和字符串型。
由于编译时的限制,定义常量的表达式必须为能被编译器求值的常量表达式。
声明格式:
const name [type] = value
例如:
const pi = 3.14159
type可以省略
和变量声明一样,可以批量声明多个常量:
const (
e = 2.7182818
pi = 3.1415926
)
所有常量的运算都可以在编译期完成,这样不仅可以减少运行时的工作,也方便其他代码的编译优化,当操作数是常量时,一些运行时的错误也可以在编译时被发现,例如整数除零、字符串索引越界、任何导致无效浮点数的操作等。
iota 常量生成器
常量声明可以使用 iota 常量生成器初始化,它用于生成一组以相似规则初始化的常量,但是不用每行都写一遍初始化表达式。
在一个 const 声明语句中,在第一个声明的常量所在的行,iota 将会被置为 0,然后在每一个有常量声明的行加1
比如,定义星期日到星期六,从0-6
const (
Sunday = iota //0
Monday
Tuesday
Wednesday
Thursday
Friday
Saturday //6
)
指针
- Go语言中使用在变量名前面添加
&操作符(前缀)来获取变量的内存地址 - 当使用
&操作符对普通变量进行取地址操作并得到变量的指针后,可以对指针使用*操作符,也就是指针取值
func main() {
var room int = 10
var ptr = &room
fmt.Printf("%p\n", &room)
fmt.Printf("%T, %p\n", ptr, ptr)
fmt.Println("指针地址", ptr)
fmt.Println("指针地址代表的值", *ptr)
}
结果
0xc00001a098
*int, 0xc00001a098
指针地址 0xc00001a098
指针地址代表的值 10
使用指针修改值
package main
func main(){
// 利用指针修改值
var num = 10
modifyFromPoint(num)
fmt.Println("未使用指针,方法外",num)
var num2 = 22
newModifyFromPoint(&num2) // 传入指针
fmt.Println("使用指针 方法外",num2)
}
func modifyFromPoint(num int) {
// 未使用指针
num = 10000
fmt.Println("未使用指针,方法内:",num)
}
func newModifyFromPoint(ptr *int) {
// 使用指针
*ptr = 1000 // 修改指针地址指向的值
fmt.Println("使用指针,方法内:",*ptr)
}
结果:
未使用指针,方法内: 10000
未使用指针,方法外 10
使用指针,方法内: 1000
使用指针 方法外 1000
new和make
make 关键字的主要作用是创建 slice、map 和 Channel 等内置的数据结构,而 new 的主要作用是为类型申请一片内存空间,并返回指向这片内存的指针。
- make 分配空间后,会进行初始化,new分配的空间被清零
- new 分配返回的是指针,即类型 *Type。make 返回引用,即 Type;
- new 可以分配任意类型的数据;
数据结构
数组
数组是一个由固定长度的特定类型元素组成的序列,一个数组可以由零个或多个元素组成。
因为数组的长度是固定的,所以在Go语言中很少直接使用数组。
数组的声明
var 数组变量名 [元素数量]Type
- 数组变量名:数组声明及使用时的变量名。
- 元素数量:数组的元素数量,可以是一个表达式,但最终通过编译期计算的结果必须是整型数值,元素数量不能含有到运行时才能确认大小的数值。
- Type:可以是任意基本类型,包括数组本身,类型为数组本身时,可以实现多维数组。
例子:
//默认数组中的值是类型的默认值
var arr [3]int
数组的赋值
var arr [3]int = [3]int{1,2,3}
//如果第三个不赋值,就是默认值0
var arr [3]int = [3]int{1,2}
//可以使用简短声明
arr := [3]int{1,2,3}
//如果不写数据数量,而使用...,表示数组的长度是根据初始化值的个数来计算
arr := [...]int{1,2,3}
数组比较
如果两个数组类型相同(包括数组的长度,数组中元素的类型)的情况下,我们可以直接通过较运算符(==和!=)来判断两个数组是否相等,只有当两个数组的所有元素都是相等的时候数组才是相等的,不能比较两个类型不同的数组,否则程序将无法完成编译。
多维数组
声明多维数组的语法如下所示:
//array_name 为数组的名字,array_type 为数组的类型,size1、size2 等等为数组每一维度的长度。
var array_name [size1][size2]...[sizen] array_type
二维数组是最简单的多维数组,二维数组本质上是由多个一维数组组成的。
// 声明一个二维整型数组,两个维度的长度分别是 4 和 2
var array [4][2]int
// 使用数组字面量来声明并初始化一个二维整型数组
array = [4][2]int{{10, 11}, {20, 21}, {30, 31}, {40, 41}}
// 声明并初始化数组中索引为 1 和 3 的元素
array = [4][2]int{1: {20, 21}, 3: {40, 41}}
// 声明并初始化数组中指定的元素
array = [4][2]int{1: {0: 20}, 3: {1: 41}}
赋值:
// 声明一个 2×2 的二维整型数组
var array [2][2]int
// 设置每个元素的整型值
array[0][0] = 10
array[0][1] = 20
array[1][0] = 30
array[1][1] = 40
切片
切片(Slice)与数组一样,也是可以容纳若干类型相同的元素的容器。与数组不同的是,无法通过切片类型来确定其值的长度。
每个切片值都会将数组作为其底层数据结构。我们也把这样的数组称为切片的底层数组。切片(slice)是对数组的一个连续片段的引用,所以切片是一个引用类型。这个片段可以是整个数组,也可以是由起始和终止索引标识的一些项的子集,需要注意的是,终止索引标识的项不包括在切片内(左闭右开的区间)。
切片的声明
切片类型声明格式如下:
//name 表示切片的变量名,Type 表示切片对应的元素类型。
var name []Type
// 声明字符串切片
var strList []string
// 声明整型切片
var numList []int
// 声明一个空切片
var numListEmpty = []int{}
// 输出3个切片
fmt.Println(strList, numList, numListEmpty)
// 输出3个切片大小
fmt.Println(len(strList), len(numList), len(numListEmpty))
// 切片判定空的结果
fmt.Println(strList == nil)
fmt.Println(numList == nil)
fmt.Println(numListEmpty == nil)
使用 make() 函数构造切片
如果需要动态地创建一个切片,可以使用 make() 内建函数,格式如下:
make( []Type, size, cap )
Type 是指切片的元素类型,size 指的是为这个类型分配多少个元素,cap 为预分配的元素数量,这个值设定后不影响 size,只是能提前分配空间,降低多次分配空间造成的性能问题。
a := make([]int, 2)
b := make([]int, 2, 10)
fmt.Println(a, b)
//容量不会影响当前的元素个数,因此 a 和 b 取 len 都是 2
//但如果我们给a 追加一个 a的长度就会变为3
fmt.Println(len(a), len(b))
使用 make() 函数生成的切片一定发生了内存分配操作,但给定开始与结束位置(包括切片复位)的切片只是将新的切片结构指向已经分配好的内存区域,设定开始与结束位置,不会发生内存分配操作。
添加元素
声明新的切片后,可以使用 append() 函数向切片中添加元素
var strList []string
// 追加一个元素
strList = append(strList,"hello")
fmt.Println(strList)
删除元素
go中并没有内置删除方法,不过我们可以使用切片的特性来达成删除的效果。
如:删除3这个元素,它的下标索引为2
func main() {
var s1 = []int{1, 2, 3, 4}
fmt.Println("---删除之前---")
fmt.Printf("s1: %v\n", s1)
//删除3这个元素,它的下标索引为2
s1 = append(s1[:2], s1[3:]...)
fmt.Println("---删除之后---")
fmt.Printf("s1: %v\n", s1)
}
修改元素
func main() {
var s1 = []int{1, 2, 3, 4, 5}
s1[1] = 100 //索引1的值改为100
fmt.Printf("s1: %v\n", s1)
}
切片的拷贝
由于切片是引用类型,所以需要有copy的方法。
copy( destSlice, srcSlice []T) int
例子:
func main() {
var s1 = []int{1, 2, 3, 4, 5}
var s2 = make([]int, 4) //需要make一个切片的类型,指定有5个元素
copy(s2, s1) //指定复制的切片
s2[0] = 100
fmt.Printf("s1: %v\n", s1)
fmt.Printf("s2: %v\n", s2)
}
map
map 是一种无序的键值对的集合。map 最重要的一点是通过 key 来快速检索数据,key 类似于索引,指向数据的值。map 是一种集合,所以我们可以像迭代数组和切片那样迭代它。不过,map 是无序的,我们无法决定它的返回顺序,这是因为 map 是使用 hash 表来实现的。
map的声明
map 是引用类型,可以使用如下方式声明:
//[keytype] 和 valuetype 之间允许有空格。
var mapname map[keytype]valuetype
其中:
- mapname 为 map 的变量名。
- keytype 为键类型。
- valuetype 是键对应的值类型。
在声明的时候不需要知道 map 的长度,因为 map 是可以动态增长的,未初始化的 map 的值是 nil,使用函数 len() 可以获取 map 中 键值对的数目。
map的另外一种创建方式:
make(map[keytype]valuetype)
map 增加和更新
map["key"] = value // 如果 key 还没有,就增加,如果 key 存在就修改。
map的删除
使用 delete() 内建函数从 map 中删除一组键值对,delete() 函数的格式如下:
delete(map, 键)
map 为要删除的 map 实例,键为要删除的 map 中键值对的键。
scene := make(map[string]int)
// 准备map数据
scene["cat"] = 66
scene["dog"] = 4
scene["pig"] = 960
delete(scene, "dog")
for k, v := range scene {
fmt.Println(k, v)
}
Go语言中并没有为 map 提供任何清空所有元素的函数、方法,清空 map 的唯一办法就是重新 make 一个新的 map,不用担心垃圾回收的效率,Go语言中的并行垃圾回收效率比写一个清空函数要高效的多。
map的遍历
map 的遍历过程使用 for range 循环完成,代码如下:
scene := make(map[string]int)
scene["cat"] = 66
scene["dog"] = 4
scene["pig"] = 960
for k, v := range scene {
fmt.Println(k, v)
}
注意:map是无序的,不要期望 map 在遍历时返回某种期望顺序的结果
线程安全的map
并发情况下读写 map 时会出现问题,需要并发读写时,一般的做法是加锁,但这样性能并不高,Go语言在 1.9 版本中提供了一种效率较高的并发安全的 sync.Map,sync.Map 和 map 不同,不是以语言原生形态提供,而是在 sync 包下的特殊结构。
sync.Map 有以下特性:
- 无须初始化,直接声明即可。
- sync.Map 不能使用 map 的方式进行取值和设置等操作,而是使用 sync.Map 的方法进行调用,Store 表示存储,Load 表示获取,Delete 表示删除。
- 使用 Range 配合一个回调函数进行遍历操作,通过回调函数返回内部遍历出来的值,Range 参数中回调函数的返回值在需要继续迭代遍历时,返回 true,终止迭代遍历时,返回 false。
package main
import (
"fmt"
"sync"
)
func main() {
//sync.Map 不能使用 make 创建
var scene sync.Map
// 将键值对保存到sync.Map
//sync.Map 将键和值以 interface{} 类型进行保存。
scene.Store("greece", 97)
scene.Store("london", 100)
scene.Store("egypt", 200)
// 从sync.Map中根据键取值
fmt.Println(scene.Load("london"))
// 根据键删除对应的键值对
scene.Delete("london")
// 遍历所有sync.Map中的键值对
//遍历需要提供一个匿名函数,参数为 k、v,类型为 interface{},每次 Range() 在遍历一个元素时,都会调用这个匿名函数把结果返回。
scene.Range(func(k, v interface{}) bool {
fmt.Println("iterate:", k, v)
return true
})
}
container容器
Container — 容器数据类型:该包实现了三个复杂的数据结构:堆、链表、环
- List:Go中对链表的实现,其中List:双向链表,Element:链表中的元素
- Ring:实现的是一个循环链表,也就是我们俗称的环
- Heap:Go中对堆的实现
List
Go中对链表的实现,其中List:双向链表,Element:链表中的元素
方法列表:
type Element
func (e *Element) Next() *Element // 返回该元素的下一个元素,如果没有下一个元素则返回 nil
func (e *Element) Prev() *Element // 返回该元素的前一个元素,如果没有前一个元素则返回nil
type List
func New() *List // 返回一个初始化的list
func (l *List) Back() *Element // 获取list l的最后一个元素
func (l *List) Front() *Element // 获取list l的第一个元素
func (l *List) Init() *List // list l 初始化或者清除 list l
func (l *List) InsertAfter(v interface{}, mark *Element) *Element // 在 list l 中元素 mark 之后插入一个值为 v 的元素,并返回该元素,如果 mark 不是list中元素,则 list 不改变
func (l *List) InsertBefore(v interface{}, mark *Element) *Element // 在 list l 中元素 mark 之前插入一个值为 v 的元素,并返回该元素,如果 mark 不是list中元素,则 list 不改变
func (l *List) Len() int // 获取 list l 的长度
func (l *List) MoveAfter(e, mark *Element) // 将元素 e 移动到元素 mark 之后,如果元素e 或者 mark 不属于 list l,或者 e==mark,则 list l 不改变
func (l *List) MoveBefore(e, mark *Element) // 将元素 e 移动到元素 mark 之前,如果元素e 或者 mark 不属于 list l,或者 e==mark,则 list l 不改变
func (l *List) MoveToBack(e *Element) // 将元素 e 移动到 list l 的末尾,如果 e 不属于list l,则list不改变
func (l *List) MoveToFront(e *Element) // 将元素 e 移动到 list l 的首部,如果 e 不属于list l,则list不改变
func (l *List) PushBack(v interface{}) *Element // 在 list l 的末尾插入值为 v 的元素,并返回该元素
func (l *List) PushBackList(other *List) // 在 list l 的尾部插入另外一个 list,其中l 和 other 可以相等
func (l *List) PushFront(v interface{}) *Element // 在 list l 的首部插入值为 v 的元素,并返回该元素
func (l *List) PushFrontList(other *List) // 在 list l 的首部插入另外一个 list,其中 l 和 other 可以相等
func (l *List) Remove(e *Element) interface{} // 如果元素 e 属于list l,将其从 list 中删除,并返回元素 e 的值
例子:
package main
import (
"container/list"
"fmt"
)
type student struct {
name string
age int
}
func main() {
// 初始化双向链表
l := list.New()
// 链表头插入
l.PushFront(student{name: "dexuan", age: 3})
// 链表尾插入
l.PushBack(student{name: "dexuan2", age: 4})
l.PushFront(student{name: "dexuan3", age: 5})
// 从头开始遍历
for head := l.Front(); head != nil; head = head.Next() {
fmt.Println(head.Value)
}
}
结果:
{dexuan3 5}
{dexuan 3}
{dexuan2 4}
栈
栈数据结构的特点为后进先出,go中可以使用List进行实现
package main
import (
"container/list"
"fmt"
)
type student struct {
name string
age int
}
func Push(l *list.List, v interface{}) *list.Element {
return l.PushBack(v)
}
func Pop(l *list.List) interface{} {
elem := l.Back()
return l.Remove(elem)
}
func main() {
// 初始化栈
stack := list.New()
// 栈的push操作
Push(stack, student{name: "dexuan", age: 3})
Push(stack, student{name: "dexuan2", age: 4})
Push(stack, student{name: "dexuan2", age: 5})
// 从头开始遍历
for head := stack.Front(); head != nil; head = head.Next() {
fmt.Println(head.Value)
}
//栈的pop操作
s := Pop(stack)
fmt.Println("pop:", s)
}
结果:
{dexuan 3}
{dexuan2 4}
{dexuan2 5}
pop: {dexuan2 5}
这边简单实现了Push和Pop方法
队列
队列数据结构的特点为先进先出,go中也可以使用List进行实现
package main
import (
"container/list"
"fmt"
)
type student struct {
name string
age int
}
func Push(l *list.List, v interface{}) *list.Element {
return l.PushBack(v)
}
func Pop(l *list.List) interface{} {
elem := l.Front()
return l.Remove(elem)
}
func main() {
// 初始化栈
stack := list.New()
// 栈的push操作
Push(stack, student{name: "dexuan", age: 3})
Push(stack, student{name: "dexuan2", age: 4})
Push(stack, student{name: "dexuan2", age: 5})
// 从头开始遍历
for head := stack.Front(); head != nil; head = head.Next() {
fmt.Println(head.Value)
}
//栈的pop操作
s := Pop(stack)
fmt.Println("pop:", s)
// 从头开始遍历
for head := stack.Front(); head != nil; head = head.Next() {
fmt.Println(head.Value)
}
}
结果:
{dexuan 3}
{dexuan2 4}
{dexuan2 5}
pop: {dexuan 3}
{dexuan2 4}
{dexuan2 5}
Ring
Go中提供的ring是一个双向的循环链表,与list的区别在于没有表头和表尾,ring表头和表尾相连,构成一个环。
方法:
type Ring
func New(n int) *Ring // 初始化环
func (r *Ring) Do(f func(interface{})) // 循环环进行操作
func (r *Ring) Len() int // 环长度
func (r *Ring) Link(s *Ring) *Ring // 连接两个环
func (r *Ring) Move(n int) *Ring // 指针从当前元素开始向后移动或者向前(n 可以为负数)
func (r *Ring) Next() *Ring // 当前元素的下个元素
func (r *Ring) Prev() *Ring // 当前元素的上个元素
func (r *Ring) Unlink(n int) *Ring // 从当前元素开始,删除 n 个元素
例子:
func main() {
// 初始化3个元素的环,返回头节点
r := ring.New(3)
// 给环填充值
for i := 1;i <= 3;i++{
r.Value = i
r = r.Next()
}
sum := 0
// 对环的每个元素进行处理
r.Do(func(i interface{}) {
sum = i.(int) + sum
})
fmt.Println(sum)
}
约瑟夫问题
问题描述:
约瑟夫问题是个有名的问题:N个人围成一圈,从第一个开始报数,第M个将被杀掉,最后剩下一个,其余人都将被杀掉。例如N=6,M=5,被杀掉的顺序是:5,4,6,2,3。
约瑟夫环问题是这样的:
1, …, n 这 n 个数字排成一个圆圈,从数字 1 开始,每次从这个圆圈里删除第 m 个数字,然后从第m+1个数字开始循环重新求出这个圆圈里剩下的最后一个数字。
go语言实现:
package main
import (
"container/ring"
"fmt"
)
const n = 6
const m = 5
func main() {
r := ring.New(n)
// 给环填充值
for i := 1; i <= n; i++ {
r.Value = i
r = r.Next()
}
cnt := 1
for r.Len() > 1 {
r = r.Move(m - 2)
fmt.Printf("第%d次淘汰的编号为%d\n", cnt, r.Next().Value)
r.Unlink(1)
r = r.Next()
cnt++
}
fmt.Println("最终结果为", r.Value)
}
结果:
第1次淘汰的编号为5
第2次淘汰的编号为4
第3次淘汰的编号为6
第4次淘汰的编号为2
第5次淘汰的编号为3
最终结果为 1
Heap
Go中堆使用的数据结构是最小二叉树,即根节点比左边子树和右边子树的所有值都小。
heap的使用,需要先实现5个函数,Len(),Less(),Swap(),Push(),Pop(),因为heap的API 需要用到这些基本的操作函数。
heap一般用于解决topk问题,可以实现优先队列。
例子1: 整数堆
package main
import (
"container/heap"
"fmt"
)
type IntHeap []int
func (h IntHeap) Len() int { return len(h) }
func (h IntHeap) Less(i, j int) bool { return h[i] < h[j] } //最小堆
func (h IntHeap) Swap(i, j int) { h[i], h[j] = h[j], h[i] }
func (h *IntHeap) Push(x interface{}) {
// Push 和 Pop 使用 pointer receiver 作为参数,
// 因为它们不仅会对切片的内容进行调整,还会修改切片的长度。
*h = append(*h, x.(int))
}
func (h *IntHeap) Pop() interface{} {
old := *h
n := len(old)
x := old[n-1]
*h = old[0 : n-1]
return x
}
// 这个示例会将一些整数插入到堆里面, 接着检查堆中的最小值,
// 之后按顺序从堆里面移除各个整数。
func main() {
h := &IntHeap{2, 1, 5, 9, 0, 3, 4}
heap.Init(h)
heap.Push(h, 10)
fmt.Printf("minimum: %d\n", (*h)[0])
for h.Len() > 0 {
fmt.Printf("%d ", heap.Pop(h))
}
}
例子2: 结构体堆
package main
import (
"container/heap"
"fmt"
)
type Student struct {
Name string
Grade int
}
type StudentHeap []Student
func (h StudentHeap) Len() int { return len(h) }
func (h StudentHeap) Less(i, j int) bool { return h[i].Grade < h[j].Grade }
func (h StudentHeap) Swap(i, j int) { h[i], h[j] = h[j], h[i] }
func (h *StudentHeap) Push(x interface{}) {
*h = append(*h, x.(Student))
}
func (h *StudentHeap) Pop() interface{} {
old := *h
n := len(old)
x := old[n-1]
*h = old[:n-1]
return x
}
// 按照Grade排序的最小堆
func main() {
h := StudentHeap{}
h = append(h, Student{Name: "mingming", Grade: 90})
h = append(h, Student{Name: "xiaoxiao", Grade: 60})
h = append(h, Student{Name: "congcong", Grade: 88})
heap.Init(&h)
heap.Push(&h, Student{Name: "sese", Grade: 78})
for h.Len() > 0 {
fmt.Printf("%v ", heap.Pop(&h))
}
}
只是重写了Less方法,其他的相同
排序
sort包主要针对[]int、[]float64、[]string、以及其他自定义切片的排序。
sort 包 在内部实现了四种基本的排序算法:插入排序(insertionSort)、归并排序(symMerge)、堆排序(heapSort)和快速排序(quickSort); sort 包会依据实际数据自动选择最优的排序算法。所以我们写代码时只需要考虑实现 sort.Interface 这个类型就可以了。
sortp的使用,需要先实现3个函数,Len(),Less(),Swap()
package main
import (
"fmt"
"sort"
)
type NewInts []uint
func (n NewInts) Len() int {
return len(n)
}
func (n NewInts) Less(i, j int) bool {
return n[i] < n[j]
}
func (n NewInts) Swap(i, j int) {
n[i], n[j] = n[j], n[i]
}
func main() {
n := []uint{1, 3, 2, 6, 5, 4}
sort.Sort(NewInts(n))
fmt.Println(n)
}
想要更改比较规则,重写Less方法即可
流程控制
判断语句
if语句
第一种
if condition {
// 条件为真执行
}
第二种
if condition {
// 条件为真 执行
} else {
// 条件不满足 执行
}
第三种
if condition1 {
// condition1 满足 执行
} else if condition2 {
// condition1 不满足 condition2满足 执行
}else {
// condition1和condition2都不满足 执行
}
switch语句
/* 定义局部变量 */
var grade string = "B"
var score int = 90
switch score {
case 90: grade = "A"
case 80: grade = "B"
case 50,60,70 : grade = "C"
default: grade = "D"
}
//swtich后面如果没有条件表达式,则会对true进行匹配
//swtich后面如果没有条件表达式,则会对true进行匹配
switch {
case grade == "A" :
fmt.Printf("优秀!\n" )
case grade == "B", grade == "C" :
fmt.Printf("良好\n" )
case grade == "D" :
fmt.Printf("及格\n" )
case grade == "F":
fmt.Printf("不及格\n" )
default:
fmt.Printf("差\n" )
}
fmt.Printf("你的等级是 %s\n", grade )
循环语句
go语言中的循环语句只支持 for 关键字,这个其他语言是不同的。
sum := 0
//i := 0; 赋初值,i<10 循环条件 如果为真就继续执行 ;i++ 后置执行 执行后继续循环
for i := 0; i < 10; i++ {
sum += i
}
第二种写法:
sum := 0
for {
sum++
if sum > 100 {
//break是跳出循环
break
}
}
上述的代码,如果没有break跳出循环,那么其将无限循环
第三种写法:
n := 10
for n>0 {
n--
fmt.Println(n)
}
break和continue字段go也是支持的
函数
函数是组织好的、可重复使用的、用来实现单一或相关联功能的代码段,其可以提高应用的模块性和代码的重复利用率。
Go 语言支持普通函数、匿名函数和闭包,从设计上对函数进行了优化和改进,让函数使用起来更加方便。
Go 语言的函数有以下特性:
- 函数本身可以作为值进行传递。
- 支持匿名函数和闭包(closure)。
- 函数可以满足接口。
函数定义:
func function_name( [parameter list] ) [return_types] {
函数体
}
- func:函数由 func 开始声明
- function_name:函数名称,函数名和参数列表一起构成了函数签名。
- parameter list:参数列表,参数就像一个占位符,当函数被调用时,你可以将值传递给参数,这个值被称为
实际参数。参数列表指定的是参数类型、顺序、及参数个数。参数是可选的,也就是说函数也可以不包含参数。 - return_types:
返回类型,函数返回一列值。return_types 是该列值的数据类型。有些功能不需要返回值,这种情况下 return_types 不是必须的。 - 函数体:函数定义的代码集合。
示例:
package main
import "fmt"
func main() {
fmt.Println(max(1, 10))
fmt.Println(max(-1, -2))
}
//类型相同的相邻参数,参数类型可合并。
func max(n1, n2 int) int {
if n1 > n2 {
return n1
}
return n2
}
返回值可以为多个:
func test(x, y int, s string) (int, string) {
// 类型相同的相邻参数,参数类型可合并。 多返回值必须用括号。
n := x + y
return n, fmt.Sprintf(s, n)
}
函数作为参数
func test(fn func() int) int {
return fn()
}
func fn() int{
return 200
}
func main() {
//这是直接使用匿名函数
s1 := test(func() int { return 100 })
//这是传入一个函数
s1 := test(fn)
fmt.Println(s1)
}
不定参数传值
不定参数传值 就是函数的参数不是固定的,后面的类型是固定的。
func myfunc(args ...int) { //0个或多个参数
}
func add(a int, args…int) int { //1个或多个参数
}
func add(a int, b int, args…int) int { //2个或多个参数
}
例子:
package main
import (
"fmt"
)
func test(s string, args ...int) {
fmt.Println(s, args)
}
func main() {
s := []int{1, 2, 3}
test("sum", s...)
}
结果:
sum [1 2 3]
‘…’ 其实是go的一种语法糖。
它的第一个用法主要是用于函数有多个不定参数的情况,可以接受多个不确定数量的参数。
第二个用法是slice可以被打散进行传递。
匿名函数
在Go里面,函数可以像普通变量一样被传递或使用,Go语言支持随时在代码里定义匿名函数。
例子:
package main
import (
"fmt"
"math"
)
func main() {
//这里将一个函数当做一个变量一样的操作。
getSqrt := func(a float64) float64 {
return math.Sqrt(a)
}
fmt.Println(getSqrt(4))
}
闭包
所谓“闭包”,指的是一个拥有许多变量和绑定了这些变量的环境的表达式(通常是一个函数),因而这些变量也是该表达式的一部分。
闭包=函数+引用环境
众所周知,当函数执行完成之后,其内部的局部变量就会被销毁,那么我们如何强行保留内部的变量不被销毁呢?闭包就起到了很关键的作用。
相比全局变量和局部变量,闭包有两大特点:
1.闭包拥有全局变量的不被释放的特点
2.闭包拥有局部变量的无法被外部访问的特点
闭包的好处:
1.可以让一个变量长期在内存中不被释放
2.避免全局变量的污染,和全局变量不同,闭包中的变量无法被外部使用
3.私有成员的存在,无法被外部调用,只能直接内部调用
例子:
package main
import (
"fmt"
)
func closure(name string) func() (string, int) {
// 血量一直为150
hp := 150
// 返回创建的闭包
return func() (string, int) {
hp--
// 将变量引用到闭包中
return name, hp
}
}
func main() {
generator := closure("tdx")
name, hp := generator()
fmt.Println(name, hp)
name1, hp1 := generator()
fmt.Println(name1, hp1)
}
结果:
tdx 149
tdx 148
defer延迟调用
类似于函数生命周期中在函数执行完成后的回调
defer特性:
- 关键字 defer 用于注册延迟调用。
- 这些调用直到 return 前才被执。因此,可以用来做资源清理。
- 多个defer语句,按先进后出的方式执行。
- defer语句中的变量,在defer声明时就决定了。
defer的用途:
- 关闭文件句柄
- 锁资源释放
- 数据库连接释放
例子:
package main
import (
"log"
"time"
)
func main() {
start := time.Now()
log.Printf("开始时间为:%v", start)
defer func() {
log.Printf("开始调用defer")
log.Printf("时间差:%v", time.Since(start))
log.Printf("结束调用defer")
}()
time.Sleep(3 * time.Second)
log.Printf("函数结束")
}
结果:
2022/10/30 17:25:22 开始时间为:2022-10-30 17:25:22.2977257 +0800 CST m=+0.005104501
2022/10/30 17:25:25 函数结束
2022/10/30 17:25:25 开始调用defer
2022/10/30 17:25:25 时间差:3.0202335s
2022/10/30 17:25:25 结束调用defer
异常处理
Go语言中使用 panic 抛出错误,recover 捕获错误。
异常的使用场景简单描述:Go中可以抛出一个panic的异常,然后在defer中通过recover捕获这个异常,然后正常处理。
panic
- 内置函数
- 假如函数F中书写了panic语句,会终止其后要执行的代码,在panic所在函数F内如果存在要执行的defer函数列表,按照defer的逆序执行
- 返回函数F的调用者G,在G中,调用函数F语句之后的代码不会执行,假如函数G中存在要执行的defer函数列表,按照defer的逆序执行
- 直到goroutine整个退出,并报告错误
package main
import (
"fmt"
"math/rand"
)
func test() {
fmt.Println("开始")
defer func() {
// defer panic 会打印
fmt.Println(recover())
}()
if rand.Intn(10) < 5 {
panic("随机数小于5")
}
fmt.Println("结束")
}
func main() {
test()
fmt.Println("程序结束")
}
如果触发了panic流程,下面的"结束"和"程序结束"将不会被打印
recover
- 内置函数
- 用来捕获panic,从而影响应用的行为
- 利用recover处理panic指令,defer 必须放在 panic 之前定义,另外 recover 只有在 defer 调用的函数中才有效。否则当panic时,recover无法捕获到panic,无法防止panic扩散。
- recover 处理异常后,逻辑并不会恢复到 panic 那个点去,函数跑到 defer 之后的那个点。
package main
import (
"fmt"
"math/rand"
)
func test() {
fmt.Println("开始")
defer func() {
// defer panic 会打印
fmt.Println(recover())
}()
if rand.Intn(10) < 5 {
panic("随机数小于5")
}
fmt.Println("结束")
}
func main() {
test()
fmt.Println("程序结束")
}
结果:
开始
随机数小于5
程序结束
此时由于异常被捕获,”程序结束“仍然可以打印出来
error
除用 panic 引发中断性错误外,还可返回 error 类型错误对象来表示函数调用状态,error与panic的区别是error不会导致程序的崩溃。一般导致关键流程出现不可修复性错误的使用 panic,其他使用 error。
package main
import (
"errors"
"fmt"
)
var ErrDivByZero = errors.New("division by zero")
func div(x, y int) (int, error) {
if y == 0 {
return 0, ErrDivByZero
}
return x / y, nil
}
func main() {
z, err := div(10, 0)
fmt.Println(err)
fmt.Println(z)
}
结果:
division by zero
0
Go实现类似 try catch 的异常处理:
package main
import "fmt"
func Try(fun func(), handler func(interface{})) {
defer func() {
if err := recover(); err != nil {
handler(err)
}
}()
fun()
}
func testFun() {
panic("test panic")
}
func main() {
Try(testFun, func(err interface{}) {
fmt.Println(err)
})
}
结构体
使用关键字 type 可以将各种基本类型定义为自定义类型,基本类型包括整型、字符串、布尔等。结构体是一种复合的基本类型,通过 type 定义为自定义类型后,使结构体更便于使用。
结构体的定义格式如下:
type 类型名 struct {
字段1 字段1类型
字段2 字段2类型
…
}
- 类型名:标识自定义结构体的名称,在同一个包内不能重复。
- struct{}:表示结构体类型,
type 类型名 struct{}可以理解为将 struct{} 结构体定义为类型名的类型。 - 字段1、字段2……:表示结构体字段名,结构体中的字段名必须唯一。
- 字段1类型、字段2类型……:表示结构体各个字段的类型。
实例化
实例化就是根据结构体定义的格式创建一份与格式一致的内存区域,结构体实例与实例间的内存是完全独立的。
普通创建
package main
import "fmt"
type dog struct {
name string
age int
}
func main() {
var d dog //如果不赋值 结构体中的变量会使用零值初始化
fmt.Println(d)
var p = dog { //也可以这么创建
name: "小红",
age: 2
}
fmt.Println(p)
}
创建指针类型的结构体:
package main
import "fmt"
type dog struct {
name string
age int
}
func main() {
d := new(dog)
fmt.Println(d)
}
与上面不同的是new返回的是一个指针
匿名结构体
匿名结构体没有类型名称,无须通过 type 关键字定义就可以直接使用。
ins := struct {
// 匿名结构体字段定义
字段1 字段类型1
字段2 字段类型2
…
}{
// 字段值初始化
初始化字段1: 字段1的值,
初始化字段2: 字段2的值,
…
}
- 字段1、字段2……:结构体定义的字段名。
- 初始化字段1、初始化字段2……:结构体初始化时的字段名,可选择性地对字段初始化。
- 字段类型1、字段类型2……:结构体定义字段的类型。
- 字段1的值、字段2的值……:结构体初始化字段的初始值。
接收器
接收器的格式如下:
func (接收器变量 接收器类型) 方法名(参数列表) (返回参数) {
函数体
}
- 接收器变量:接收器中的参数变量名在命名时,官方建议使用接收器类型名的第一个小写字母,而不是 self、this 之类的命名。例如,Socket 类型的接收器变量应该命名为 s,Connector 类型的接收器变量应该命名为 c 等。
- 接收器类型:接收器类型和参数类似,可以是指针类型和非指针类型。
- 方法名、参数列表、返回参数:格式与函数定义一致。
接收器根据接收器的类型可以分为指针接收器、非指针接收器,两种接收器在使用时会产生不同的效果,根据效果的不同,两种接收器会被用于不同性能和功能要求的代码中。
指针类型的接收器:
指针类型的接收器由一个结构体的指针组成,更接近于面向对象中的 this 或者 self。
由于指针的特性,调用方法时,修改接收器指针的任意成员变量,在方法结束后,修改都是有效的。
示例:
使用结构体定义一个属性(Property),为属性添加 SetValue() 方法以封装设置属性的过程,通过属性的 Value() 方法可以重新获得属性的数值,使用属性时,通过 SetValue() 方法的调用,可以达成修改属性值的效果:
package main
import "fmt"
// 定义属性结构
type Property struct {
value int // 属性值
}
// 设置属性值
func (p *Property) SetValue(v int) {
// 修改p的成员变量
p.value = v
}
// 取属性值
func (p *Property) Value() int {
return p.value
}
func main() {
// 实例化属性
p := new(Property)
// 设置值
p.SetValue(100)
// 打印值
fmt.Println(p.Value())
}
非指针类型的接收器:
当方法作用于非指针接收器时,Go语言会在代码运行时将接收器的值复制一份,在非指针接收器的方法中可以获取接收器的成员值,但修改后无效。
点(Point)使用结构体描述时,为点添加 Add() 方法,这个方法不能修改 Point 的成员 X、Y 变量,而是在计算后返回新的 Point 对象,Point 属于小内存对象,在函数返回值的复制过程中可以极大地提高代码运行效率:
package main
import (
"fmt"
)
// 定义点结构
type Point struct {
X int
Y int
}
// 非指针接收器的加方法
func (p Point) Add(other Point) Point {
// 成员值与参数相加后返回新的结构
return Point{p.X + other.X, p.Y + other.Y}
}
func main() {
// 初始化点
p1 := Point{1, 1}
p2 := Point{2, 2}
// 与另外一个点相加
result := p1.Add(p2)
// 输出结果
fmt.Println(result)
}
在计算机中,小对象由于值复制时的速度较快,所以适合使用非指针接收器,大对象因为复制性能较低,适合使用指针接收器,在接收器和参数间传递时不进行复制,只是传递指针。
方法
在面向对象编程中,存在类与方法,那么go语言中结构体就类似于类,我们就可以使用接收器当做面向对象中类的方法。
一个类型加上它的方法等价于面向对象中的一个类
因为接收器这个设定的存在,go可以给任何对象添加方法,下面是给自定义整型对象添加方法的代码:
package main
import (
"fmt"
)
// 将int定义为MyInt类型
type MyInt int
// 为MyInt添加IsZero()方法
func (m MyInt) IsZero() bool {
return m == 0
}
// 为MyInt添加Add()方法
func (m MyInt) Add(other int) int {
return other + int(m)
}
func main() {
var b MyInt
fmt.Println(b.IsZero())
b = 1
fmt.Println(b.Add(2))
}
结果:
true
3
结构体之间的比较
在Go语言中,可以通过==运算符或DeeplyEqual()方法比较两个结构相同的类型并包含相同的字段值的结构。如果结构彼此相等(就其字段值而言),则运算符和方法均返回true;否则,返回false。并且,如果比较的变量属于不同的结构,则编译器将给出错误。
package main
import (
"fmt"
"reflect"
)
type Cat struct {
name string
age int
}
func main() {
c := Cat{"小花", 6}
d := Cat{"小花", 6}
fmt.Println(c == d)
fmt.Println(reflect.DeepEqual(c, d))
}
结果:
true
true
package main
import (
"fmt"
"reflect"
)
type Cat struct {
name string
age int
son []int
}
func main() {
c := Cat{"小花", 6, []int{1, 2}}
d := Cat{"小花", 6, []int{1, 2}}
fmt.Println(c == d)
fmt.Println(reflect.DeepEqual(c, d))
}
c == d报错,此时只能用reflect.DeepEqual(c, d)进行比较
接口
在Go语言中接口(interface)是一种类型,一种抽象的类型。
interface是一组method的集合,接口做的事情就像是定义一个协议(规则)
看以下例子:
package main
import (
"fmt"
)
type Cat struct{}
func (c Cat) Say() string { return "喵喵喵" }
type Dog struct{}
func (d Dog) Say() string { return "汪汪汪" }
func catSay(c Cat) {
fmt.Println(c.Say())
}
func dogSay(d Dog) {
fmt.Println(d.Say())
}
func main() {
c := Cat{}
d := Dog{}
catSay(c)
dogSay(d)
}
子这个例子中,猫和狗都会叫,此时定义了2个函数catSay和dogSay,如果我们后续再加上猪、青蛙等动物的话,我们的代码还会一直重复下去。那我们能不能把它们当成“能叫的动物”来处理呢?
每个接口类型由数个方法组成。接口的形式代码如下:
type 接口类型名 interface{
方法名1( 参数列表1 ) 返回值列表1
方法名2( 参数列表2 ) 返回值列表2
…
}
接口是一种抽象的类型。当你看到一个接口类型的值时,你不知道它是什么,唯一知道的是通过它的方法能做什么。
此时我们用接口的形式来对代码进行优化
package main
import (
"fmt"
)
type Animal interface {
Say() string
}
type Cat struct{}
func (c Cat) Say() string { return "喵喵喵" }
type Dog struct{}
func (d Dog) Say() string { return "汪汪汪" }
func say(a Animal) {
fmt.Println(a.Say())
}
func main() {
c := Cat{}
d := Dog{}
say(c)
say(d)
}
接口的实现条件
- 接口的方法与实现接口的类型方法格式一致
- 接口中所有方法均被实现
接口嵌套
接口与接口间可以通过嵌套创造出新的接口
// Sayer 接口
type Sayer interface {
say()
}
// Mover 接口
type Mover interface {
move()
}
// 接口嵌套
type animal interface {
Sayer
Mover
}
嵌套得到的接口的使用与普通接口一样,这里我们让cat实现animal接口:
type cat struct {
name string
}
func (c cat) say() {
fmt.Println("喵喵喵")
}
func (c cat) move() {
fmt.Println("猫会动")
}
func main() {
var x animal
x = cat{name: "花花"}
x.move()
x.say()
}
空接口
空接口是指没有定义任何方法的接口。
因此任何类型都实现了空接口。
空接口类型的变量可以存储任意类型的变量。
使用空接口实现可以接收任意类型的函数参数。
// 空接口作为函数参数
func show(a interface{}) {
fmt.Printf("type:%T value:%v\n", a, a)
}
空接口作为map的值
使用空接口实现可以保存任意值的字典。
// 空接口作为map值
var studentInfo = make(map[string]interface{})
studentInfo["name"] = "李白"
studentInfo["age"] = 18
studentInfo["married"] = false
fmt.Println(studentInfo)
类型断言
空接口可以存储任意类型的值,那我们如何获取其存储的具体数据呢?
想要判断空接口中的值这个时候就可以使用类型断言,其语法格式:
x.(T)
其中:
- x:表示类型为interface{}的变量
- T:表示断言x可能是的类型。
例子:
package main
import (
"fmt"
)
func main() {
var x interface{}
x = "hello word"
v, ok := x.(string)
if ok {
fmt.Println(v)
} else {
fmt.Println("类型断言失败")
}
x = 123
v1, ok1 := x.(string)
if ok1 {
fmt.Println(v1)
} else {
fmt.Println("类型断言失败")
}
}
结果:
hello word
类型断言失败
包管理机制
Go语言的包借助了目录树的组织形式,一般包的名称就是其源文件所在目录的名称,虽然Go语言没有强制要求包名必须和其所在的目录名同名,但还是建议包名和所在目录同名,这样结构更清晰。
包可以定义在很深的目录中,包名的定义是不包括目录路径的,但是包在引用时一般使用全路径引用。
包的习惯用法:
- 包名一般是小写的,使用一个简短且有意义的名称。
- 包名一般要和所在的目录同名,也可以不同,包名中不能包含
-等特殊符号。 - 包名为 main 的包为应用程序的入口包,编译不包含 main 包的源码文件时不会得到可执行文件。
- 一个文件夹下的所有源码文件只能属于同一个包,同样属于同一个包的源码文件不能放在多个文件夹下。
包的各种引入机制
-
标准引用格式
import "fmt"此时可以用
fmt.作为前缀来使用 fmt 包中的方法,这是常用的一种方式。package main import "fmt" func main() { fmt.Println("hello world") } -
自定义别名引用格式
在导入包的时候,我们还可以为导入的包设置别名,如下所示:
import F "fmt"其中 F 就是 fmt 包的别名,使用时我们可以使用
F.来代替标准引用格式的fmt.来作为前缀使用 fmt 包中的方法package main import F "fmt" func main() { F.Println("hello world") } -
省略引用格式
import . "fmt"这种格式相当于把 fmt 包直接合并到当前程序中,在使用 fmt 包内的方法是可以不用加前缀
fmt.,直接引用。package main import . "fmt" func main() { //不需要加前缀 fmt. Println("hello world") } -
匿名引用格式
在引用某个包时,如果只是希望执行包初始化的 init 函数,而不使用包内部的数据时,可以使用匿名引用格式,如下所示:
import _ "fmt"匿名导入的包与其他方式导入的包一样都会被编译到可执行文件中。
注意:
- 一个包可以有多个 init 函数,包加载时会执行全部的 init 函数,但并不能保证执行顺序,所以不建议在一个包中放入多个 init 函数,将需要初始化的逻辑放到一个 init 函数里面。
- 包不能出现环形引用的情况,比如包 a 引用了包 b,包 b 引用了包 c,如果包 c 又引用了包 a,则编译不能通过。
- 包的重复引用是允许的,比如包 a 引用了包 b 和包 c,包 b 和包 c 都引用了包 d。这种场景相当于重复引用了 d,这种情况是允许的,并且 Go 编译器保证包 d 的 init 函数只会执行一次。
go mod
go mod 有以下命令:
| 命令 | 说明 |
|---|---|
| download | download modules to local cache(下载依赖包) |
| edit | edit go.mod from tools or scripts(编辑go.mod) |
| graph | print module requirement graph (打印模块依赖图) |
| init | initialize new module in current directory(在当前目录初始化mod) |
| tidy | add missing and remove unused modules(拉取缺少的模块,移除不用的模块) |
| vendor | make vendored copy of dependencies(将依赖复制到vendor下) |
| verify | verify dependencies have expected content (验证依赖是否正确) |
| why | explain why packages or modules are needed(解释为什么需要依赖) |
- 常用的有
init tdiy edit
执行go get 命令,在下载依赖包的同时还可以指定依赖包的版本。
- 运行
go get -u命令会将项目中的包升级到最新的次要版本或者修订版本; - 运行
go get -u=patch命令会将项目中的包升级到最新的修订版本; - 运行
go get [包名]@[版本号]命令会下载对应包的指定版本或者将对应包升级到指定的版本。
详见:http://t.zoukankan.com/gtea-p-15608898.html
go并发编程
并发是go的精髓,21 世纪最重要的就是并发程序设计,而 Go 从语言层面就支持并发。首先来复习一下操作系统的一些概念:
- 协程:独立的栈空间,共享堆空间,调度由用户自己控制,本质上有点类似于用户级线程,这些用户级线程的调度也是自己实现的。
- 线程:一个线程上可以跑多个协程,协程是轻量级的线程。线程需要进行系统调用,进入内核态,其创建与销毁消耗资源较大,线程不具备任何的系统资源,它在同样一个进程里面与其他线程共享全部资源。
- 进程:一个进程可以运行多个线程,在执行进程的时候,一般会具有相互独立的多个内存单元。但是多个线程是可以共享内存的,这样运行效率就很大的程度上被提高了。
Goroutine
Goroutine 一般将其翻译为Go协程,也就是说Go语言在语言层面就实现了协程的支持。
在java/c++中我们要实现并发编程的时候,我们通常需要自己维护一个线程池,并且需要自己去包装一个又一个的任务,同时需要自己去调度线程执行任务并维护上下文切换,这一切通常会耗费程序员大量的心智。那么能不能有一种机制,程序员只需要定义很多个任务,让系统去帮助我们把这些任务分配到CPU上实现并发执行呢?
Go语言中的goroutine就是这样一种机制, goroutine是由Go的运行时(runtime)调度和管理的。Go程序会智能地将 goroutine 中的任务合理地分配给每个CPU。Go语言之所以被称为现代化的编程语言,就是因为它在语言层面已经内置了调度和上下文切换的机制。
goroutine的调度是在用户态下完成的, 不涉及内核态与用户态之间的频繁切换,包括内存的分配与释放,都是在用户态维护着一块大的内存池, 不直接调用系统的malloc函数(除非内存池需要改变),成本比调度OS线程低很多。 另一方面充分利用了多核的硬件资源,近似的把若干goroutine均分在物理线程上, 再加上本身goroutine的超轻量,以上种种保证了go调度方面的性能。
在Go语言编程中你不需要去自己写进程、线程、协程,你的技能包里只有一个技能–goroutine,当你需要让某个任务并发执行的时候,你只需要把这个任务包装成一个函数,开启一个goroutine去执行这个函数就可以了,就是这么简单粗暴。
一个goroutine必定对应一个函数,可以创建多个goroutine去执行相同的函数。
go 函数名( 参数列表 )
- 函数名:要调用的函数名。
- 参数列表:调用函数需要传入的参数。
例子:
package main
import (
"fmt"
"time"
)
func hello(i int) {
fmt.Println("Hello Goroutine!" , i)
}
func main() {
for i := 0; i < 10; i++ {
go hello(i)
}
fmt.Println("main goroutine done!")
time.Sleep(time.Second * 2)
}
多次执行上面的代码,会发现每次打印的数字的顺序都不一致。这是因为10个goroutine是并发执行的,而goroutine的调度是随机的。
runtime包
runtime.Gosched() 让出cpu时间片
其实就类似于yeild或者sleep(0),进行cpu资源的切换
package main
import (
"fmt"
"runtime"
)
func main() {
go func(s string) {
for i := 0; i < 2; i++ {
fmt.Println(s)
}
}("world")
// 主协程
for i := 0; i < 2; i++ {
// 切一下,再次分配任务
runtime.Gosched()
fmt.Println("hello")
}
}
runtime.Goexit() 退出当前协程
package main
import (
"fmt"
"runtime"
"time"
)
func main() {
for i := 0; i < 5; i++ {
go func(i int) {
if i == 3 {
runtime.Goexit()
}
fmt.Println(i)
}(i)
}
time.Sleep(time.Second * 2)
}
runtime.GOMAXPROCS 指定系统级线程数量
Go运行时的调度器使用GOMAXPROCS参数来确定需要使用多少个OS线程来同时执行Go代码。默认值是机器上的CPU核心数。例如在一个8核心的机器上,调度器会把Go代码同时调度到8个OS线程上(GOMAXPROCS是m:n调度中的n)。
Go语言中可以通过runtime.GOMAXPROCS()函数设置当前程序并发时占用的CPU逻辑核心数。
Go1.5版本之前,默认使用的是单核心执行。Go1.5版本之后,默认使用全部的CPU逻辑核心数。
func a() {
for i := 1; i < 10; i++ {
fmt.Println("A:", i)
}
}
func b() {
for i := 1; i < 10; i++ {
fmt.Println("B:", i)
}
}
func main() {
runtime.GOMAXPROCS(1)
go a()
go b()
time.Sleep(time.Second)
}
Channel
单纯地将函数并发执行是没有意义的。函数与函数间需要交换数据才能体现并发执行函数的意义。
虽然可以使用共享内存进行数据交换,但是共享内存在不同的goroutine中容易发生竞态问题。为了保证数据交换的正确性,必须使用互斥量对内存进行加锁,这种做法势必造成性能问题。
Go语言的并发模型是CSP(Communicating Sequential Processes),提倡通过通信共享内存而不是通过共享内存而实现通信。
创建
通道是引用类型,通道类型的空值是nil。
var ch chan int
fmt.Println(ch) // <nil>
声明通道后需要使用make函数初始化之后才能使用。
创建channel的格式如下:
make(chan 元素类型, [缓冲大小])
channel的缓冲大小是可选的。
ch4 := make(chan int)
ch5 := make(chan bool)
ch6 := make(chan []int)
操作
发送:
将一个值发送到通道中。
ch <- 10 // 把10发送到ch中
接收:
从一个通道中接收值。
x := <- ch // 从ch中接收值并赋值给变量x
<-ch // 从ch中接收值,忽略结果
关闭:
我们通过调用内置的close函数来关闭通道。
close(ch)
无缓冲的通道
无缓冲的通道只有在有人接收值的时候才能发送值。就像你住的小区没有快递柜和代收点,快递员给你打电话必须要把这个物品送到你的手中,简单来说就是无缓冲的通道必须有接收才能发送。
无缓冲通道上的发送操作会阻塞,直到另一个goroutine在该通道上执行接收操作,这时值才能发送成功,两个goroutine将继续执行。相反,如果接收操作先执行,接收方的goroutine将阻塞,直到另一个goroutine在该通道上发送一个值。
package main
import (
"fmt"
"time"
)
func recv(c chan int) {
for {
fmt.Println("等待中")
ret := <-c
fmt.Println("接收成功", ret)
}
}
func main() {
ch := make(chan int)
go recv(ch) // 启用goroutine从通道接收值
ch <- 10
time.Sleep(time.Second * 3)
}
结果:
等待中
接收成功 10
等待中
有缓冲的通道
我们可以在使用make函数初始化通道的时候为其指定通道的容量,例如:
func main() {
ch := make(chan int, 1) // 创建一个容量为1的有缓冲区通道
ch <- 10
fmt.Println("发送成功")
}
只要通道的容量大于零,那么该通道就是有缓冲的通道,通道的容量表示通道中能存放元素的数量。
关闭管道
可以通过内置的close()函数关闭channel
package main
import "fmt"
func main() {
c := make(chan int)
go func() {
for i := 0; i < 5; i++ {
c <- i
}
close(c)
}()
for {
if data, ok := <-c; ok {
fmt.Println(data)
} else {
break
}
}
fmt.Println("main结束")
}
单向通道
有的时候我们会将通道作为参数在多个任务函数间传递,很多时候我们在不同的任务函数中使用通道都会对其进行限制,比如限制通道在函数中只能发送或只能接收。
chan<- int是一个只能发送的通道,可以发送但是不能接收;<-chan int是一个只能接收的通道,可以接收但是不能发送。
select
select的使用类似于switch语句,它有一系列case分支和一个默认的分支。每个case会对应一个通道的通信(接收或发送)过程。select会一直等待,直到某个case的通信操作完成时,就会执行case分支对应的语句。具体格式如下:
select {
case <-chan1:
// 如果chan1成功读到数据,则进行该case处理语句
case chan2 <- 1:
// 如果成功向chan2写入数据,则进行该case处理语句
default:
// 如果上面都没有成功,则进入default处理流程
}
select可以同时监听一个或多个channel,直到其中一个channel ready,如果多个channel同时ready,则随机选择一个执行。














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









