







在深度学习领域梯度是个很重要的概念,梯度弥散和梯度爆炸现象(不同激活函数梯度弥散和梯度爆炸的现象不同):
梯度弥散:(以sigmoid为例)我们可以知道当网络层数越深的时候,它的学习速率就越大。通常每增加一层,该层的学习速率就要比相邻的的上一层增加数倍左右。到第四层的学习速率往往是第一层的100倍左右。然而在sigmoid函数中,所有的输入值都会被压缩到[0,1]之间,并且随着网络层次越深,参数经过的sigmoid函数就越多,就会导致参数变化幅度越小:
例如:x=(1,1),y=(2,100),斜率为(100-1)/1,但是将x,y都归一化到(0,1)那么斜率就会变得很小。归一化的次数越多,那么他们之间的斜率就越来越小。随着网络层次加深导致的梯度值就越小,最终趋近于0,参数更新幅度极小。
然而这种现象我们称之为梯度弥散。
梯度爆炸:在高度非线性的深度神经网络中或者循环神经网络中,目标函数通常包含由几个参数连乘而导致的参数空间的尖锐非线性。当参数更新到处于这样的悬崖区域的时候,梯度下降会使得更新的参数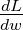

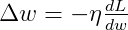
并且随着网络深度增大伴随学习速率指数级上升,所以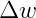
在模型进行反向传播的时候,为了寻找到最优点,每次反向传播都会让自变量向左或者向右移动deta w 而这个值就等于学习速率乘以当前损失函数对自变量w的一个梯度(以简单模型为例)。所以深度学习模型中的梯度是非常重要的。一旦发生梯度消失(弥散)或者梯度爆炸的时候,就不能找到最优值了。所以,嘿嘿,你懂的......















 979
979











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









