






 本文探讨了深度学习中梯度下降的概念及其在寻找最优解中的应用。讲解了分类与回归任务的区别,并介绍了如何通过调整内部参数来优化模型。同时,文章还解释了凸函数与非凸函数的特点及对模型训练的影响。
本文探讨了深度学习中梯度下降的概念及其在寻找最优解中的应用。讲解了分类与回归任务的区别,并介绍了如何通过调整内部参数来优化模型。同时,文章还解释了凸函数与非凸函数的特点及对模型训练的影响。
梯度下降,非凸函数
在跑深度学习网络的时候,总是能听到说对模型求梯度,找凸函数的凸函数的最优解,一直很不理解这个说法来源。
这次深入看代码的时候才深刻的注意到,我们训练模型,是训练什么东西,你的目标是为了得到什么!?
首先我们常见的网络的目的大致分为,分类与回归。
分类就是把数据放入你训练的网络模型,经过各种操作之后得出之前定义好的分类推测结果,这是分类的大致过程。比如说,对猫狗进行分类……
回归就是把数据放入你训练的网络模型,经过各种操作之后得出预期的结果,就比如说根据以前的房价,经过将各种会影响房价的数据输入模型之后,得出未来预期的房价。
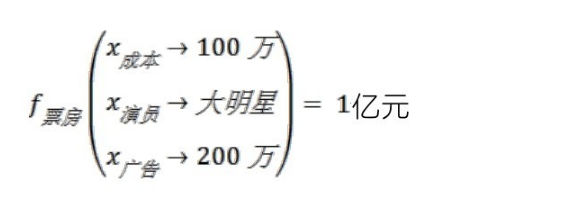
需要提到的重点就是我们在训练所需要的模型的时候,如何训练好这个模型是我们最为关注的。训练模型也可以理解为去生成一个函数,而训练模型就是我们所说的找到函数的参数,这个参数分为内部参数和外部参数(超参)。
内部参数的确定就是通过损失函数,一步步反向梯度跟新所确定的。也就是当你的网络模型搭建好之后,就是需要确定函数的参数,一般这个函数可以理解为多元的一个函数。
怎么去确定一个多元的函数的参数呢?(内部参数)
引入凹凸函数性质:
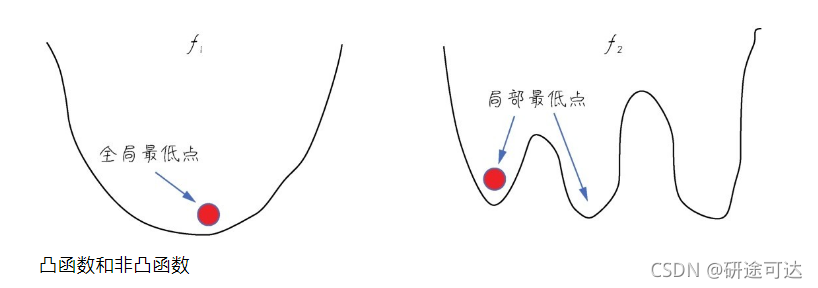
凸函数的定义比较抽象,这里只通过函数图形从直观上去理解。首先函数形状必须是连续的,而不是断续的。其次,函数平滑,只存在一个最低点,整个函数呈现一个碗状。而非凸函数,可能呈现各种形状,有多个底部(也就是局部最低点),这个需要加设(dropout)来解决。
内部参数的确定就是通过损失函数,一步步反向梯度跟新所确定的。
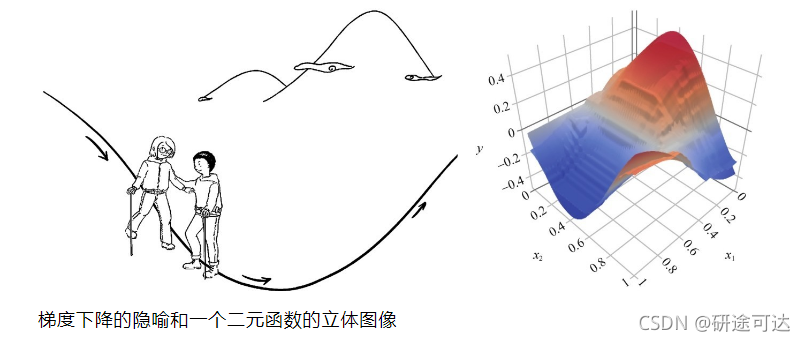
梯度下降就是深度学习的一个动力之源,目的就是为了找到函数的最优匹配参数。也就是说如果你的网络模型(你的函数)是凸函数,那么梯度下降法理论上就能得到局部最优解。
其实现的目标就是尽量减少预测值与真实值间的误差(深度学习一般叫做损失值)
其实现的途径就是首先建立误差和模型参数之间的函数(最好是凸函数),然后通过梯度下降引导我们走到凸函数的全局最低点,也就是找到误差最小的参数,从而确定内部参数。
当然这里面还有一些损失函数的选择,激活函数的选择,模型(函数)的评价指标等等都能和之前的联系起来了。

















 6万+
6万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









