







图像处理
图像的读取与大小变换
此部分需要导入的包:
import imageio #imageio用来读取图像
from skimage.transform import resize #resize更改图像尺寸大小
from matplotlib import pyplot as plt #plt提供画图工具
首先,我们根据图片路径使用imageio包中的imread函数来读取图片:
image_path = './img/img3.jpeg'
img = imageio.imread(image_path)
此时,图像的输出为imgHeight × imgWidth × 3的数据,因为我们自己随意找的原生图像可能宽和高不同,所以这里以imgHeight和imgWidth来代替。
接下来,为了更直观地查看图片我们要用matlibplot包中的pyplot(plt)来画图:
fig = plt.figure() #建立画布
a = fig.add_subplot(1, 2, 1)
plt.imshow(img) #此处的img为上面直接读取的img
a.set_title("Before")
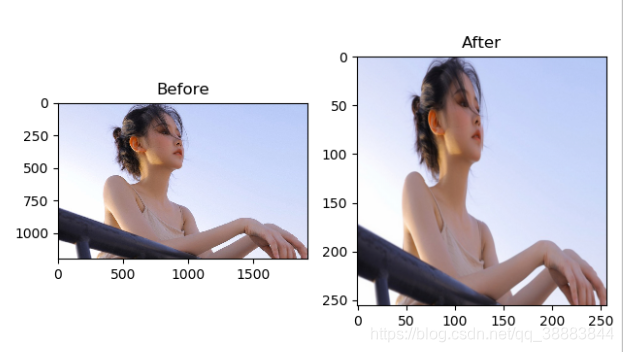
img = resize(img, (256, 256)) #这里将原生图像进行resize,变为256*256*3的形式
a = fig.add_subplot(1, 2, 2)
a.set_title("After")
plt.imshow(img)
plt.show() #show出两幅图,before为原生图像,after为resize后的图像
效果图:
图像的归一化
此部分需要导入的包:
import imageio #imageio用来读取图像
import torch #torch包,主要用来生成tensor
from skimage.transform import resize #resize更改图像尺寸大小
from matplotlib import pyplot as plt #plt提供画图工具
第一步,我们也需要先读入图像,并对其进行resize操作,并建立画布:
# 读取图像
img = imageio.imread(image_path)
img = resize(img, (256, 256)) #resize
print("Before normalize: \n",img)
# 建立画布
fig = plt.figure()
a = fig.add_subplot(1, 2, 1)
plt.imshow(img)
a.set_title("Before")
接下来,我们需要对大小为256 × 256 × 3的图像进行归一化处理,其中包含两步操作:
- 去均值
- 除方差
假设我们得到的大量图像数据集,如Flick30,很多实验人员已经测出对结果影响比较好的图像均值与方差,所以我们可以借鉴经验:
这里假设我们的均值为:
mean=[0.485, 0.456, 0.406] (RGB)
这里假设我们的方差为:
std=[0.229, 0.224, 0.225] (RGB)
mean=[0.485, 0.456, 0.406]
std=[0.229, 0.224, 0.225]
#下面将img、mean、std的维度保持一致,且将其类型均转换为 FloatTensor 方便运算
img = torch.FloatTensor(img)
mean = torch.FloatTensor(256*[256*[mean]])
std = torch.FloatTensor(256*[256*[std]])
# img-mean:去均值 , /std 除方差
img = (img - mean) / std
#下面是画图
print("After normalize: \n",img)
a = fig.add_subplot(1, 2, 2)
a.set_title("After")
plt.imshow(img)
plt.show() #show出差异
效果图1:
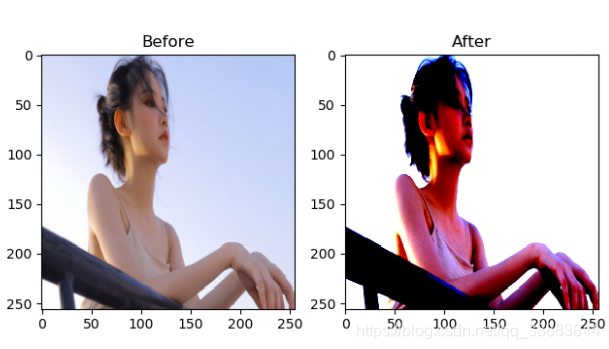
- 我们可以看到,对于这张图片,在归一化操作后,所有像素值都会落在[-1,1]之间,但又由于plt可以显示的像素值范围分别是[0,255](整数)、[0.,1](浮点数),所以我们在After图中看到的白色部分,其实是经过归一化后出现的负值或0。
- 在深度学习训练的反向传播过程中,梯度下降法在反向传播的过程中,经实验证明,如果数据是经过归一化操作的,梯度收敛的速度会被加快~。
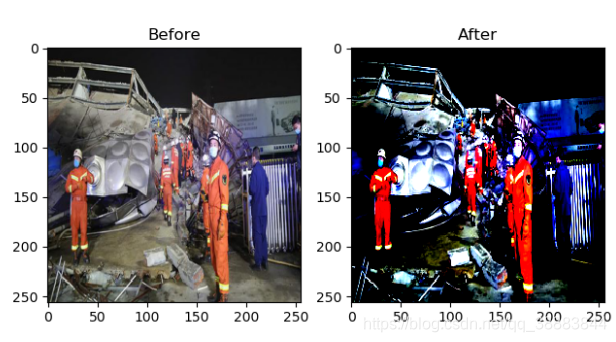
在这张图的对比中我们也可以看出,经过归一化的图,更突出了原图颜色突出的部分,而更忽略了色彩相对较淡的部分。
效果图2:
效果图3,归一化之前的部分图像数据:


效果图4,对应的归一化之后的部分图像数据:

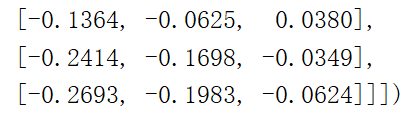
有不足之处望指出!

















 1044
1044

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









