







External Attention Usage
论文链接:Beyond Self-attention: External Attention using Two Linear Layers for Visual Tasks
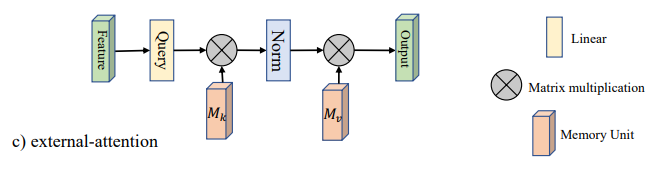
2.论文主要内容
这篇论文主要提出了一种新的外部注意力机制,称为External Attention using Two Linear Layers (简称 Linformer),用于解决视觉任务中的注意力问题。Linformer 机制采用了两个线性层来学习注意力矩阵,并将其应用于输入特征图上。与传统的自注意力机制相比,Linformer 具有更低的计算复杂度和更高的并行化效率,因此可以应用于更大的输入特征图。
Linformer 机制通过使用轻量级的矩阵分解技术来降低注意力矩阵的计算复杂度,同时引入了一种新的学习策略来优化注意力矩阵的性能。作者还提出了一种新的可视化方法来展示 Linformer 模型的注意力机制。
论文作者通过在多个视觉任务数据集上进行实验来验证 Linformer 的性能。实验结果表明,Linformer 在保持较高的准确性的同时,具有更快的训练速度和更少的计算复杂度。此外,Linformer 在对抗攻击方面也具有更好的鲁棒性。
总的来说,这篇论文提出了一种新的外部注意力机制,可以在视觉任务中具有更高的效率和鲁棒性,同时减少计算复杂度。
3.代码案例:
#导入基础包
import numpy as np
import torch
from torch import nn
from torch.nn import init
#定义了一个继承自 PyTorch 的 nn.Module 的类 ExternalAttention,表示外部注意力机制。
class ExternalAttention(nn.Module):
#定义了 ExternalAttention 类的构造函数。
# d_model 表示输入特征图的通道数,
# S 表示注意力矩阵的维度。
#
def __init__(self, d_model,S=64):
super().__init__() #调用了 nn.Module 的构造函数。
self.mk=nn.Linear(d_model,S,bias=False) #定义了一个线性层 mk,用于将输入特征图映射到 S 维度的注意力矩阵。
self.mv=nn.Linear(S,d_model,bias=False) #定义了一个线性层 mv,用于将注意力矩阵映射回 d_model 维度的特征图。
self.softmax=nn.Softmax(dim=1) #定义了一个 softmax 函数,用于对注意力矩阵进行归一化,使其成为概率分布。
self.init_weights() #调用了 ExternalAttention 类的 init_weights() 方法,用于初始化模型的权重。
def init_weights(self): #定义了 ExternalAttention 类的初始化函数,用于初始化模型的权重。
for m in self.modules(): #对模型中的所有模块进行遍历。
if isinstance(m, nn.Conv2d): #如果当前模块是 nn.Conv2d 类型的卷积层,则进行以下初始化操作:
#使用 Kaiming 正态分布初始化卷积层的权重。
init.kaiming_normal_(m.weight, mode='fan_out')
if m.bias is not None:
init.constant_(m.bias, 0)
#如果当前模块是 nn.BatchNorm2d 类型的批归一化层,则进行以下初始化操作:
elif isinstance(m, nn.BatchNorm2d):
init.constant_(m.weight, 1)
init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
init.normal_(m.weight, std=0.001)
if m.bias is not None:
init.constant_(m.bias, 0)
#定义了 ExternalAttention 类的前向传播函数,其中 queries 表示输入的特征图
def forward(self, queries):
# 将输入的特征图 queries 经过线性层 mk 映射到 S 维度的注意力矩阵。
#此时得到的 attn 的形状为 bs,n,S,其中 bs 表示批次大小,n 表示特征图的大小,
attn=self.mk(queries) #bs,n,S
attn=self.softmax(attn) #bs,n,S
attn=attn/torch.sum(attn,dim=2,keepdim=True) #bs,n,S
#将归一化后的注意力矩阵 attn 经过线性层 mv 映射回原来的特征图维度 d_model。
#此时得到的 out 的形状为 bs,n,d_model,与输入的特征图形状相同。
out=self.mv(attn) #bs,n,d_model
return out
if __name__ == '__main__':
input=torch.randn(50,49,512)
ea = ExternalAttention(d_model=512,S=8)
output=ea(input)
print(output.shape)


















 563
563

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











