






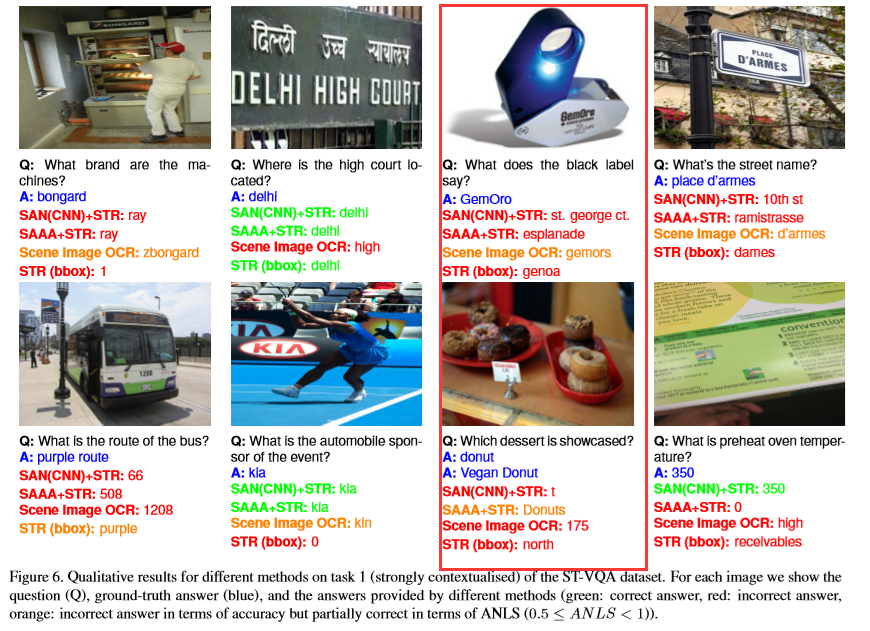
2019_ICCV_ST-VQA
- 关于ANLS(Average Normalized Levenshtein Similarity)
- 字符串相似度三种算法:https://www.cnblogs.com/lishanyang/p/6016737.html
- 字符串相似度算法——Levenshtein Distance算法:https://blog.csdn.net/weixin_34166847/article/details/86032234
- 编辑距离越小,两个串的相似度越大。编辑距离改进:https://www.cnblogs.com/zhoug2020/p/4224866.html
- 对光学字符识别错误进行轻微处罚(比如有些字母识别是对的,只是大小写有些区别)
- 、
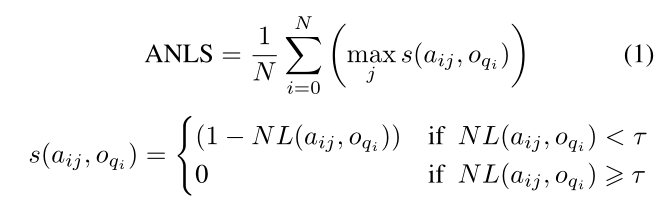


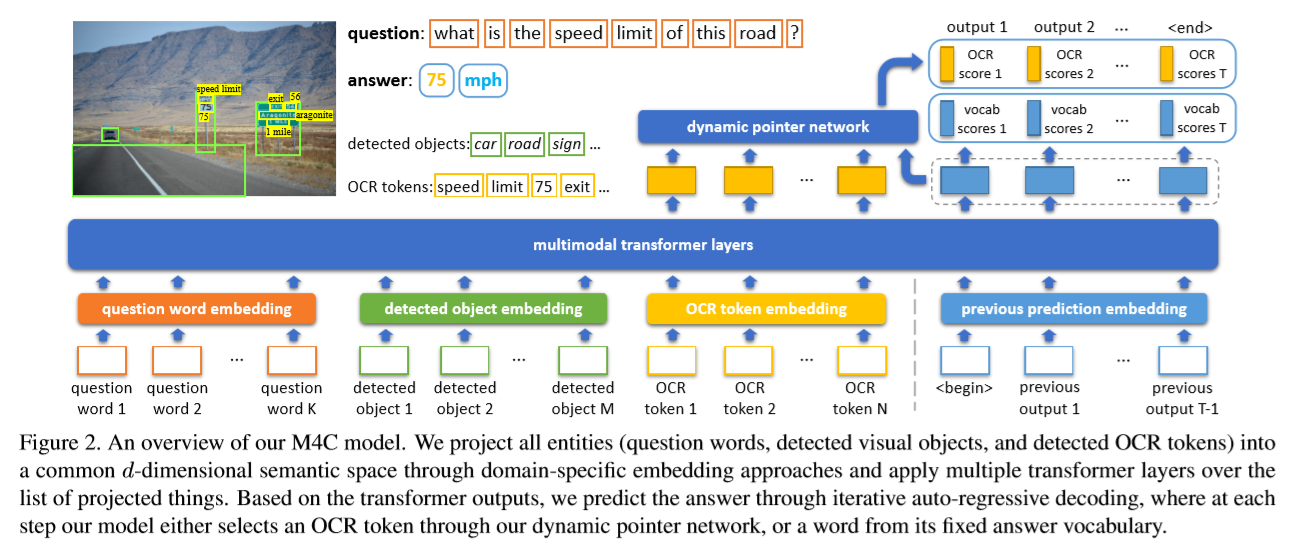
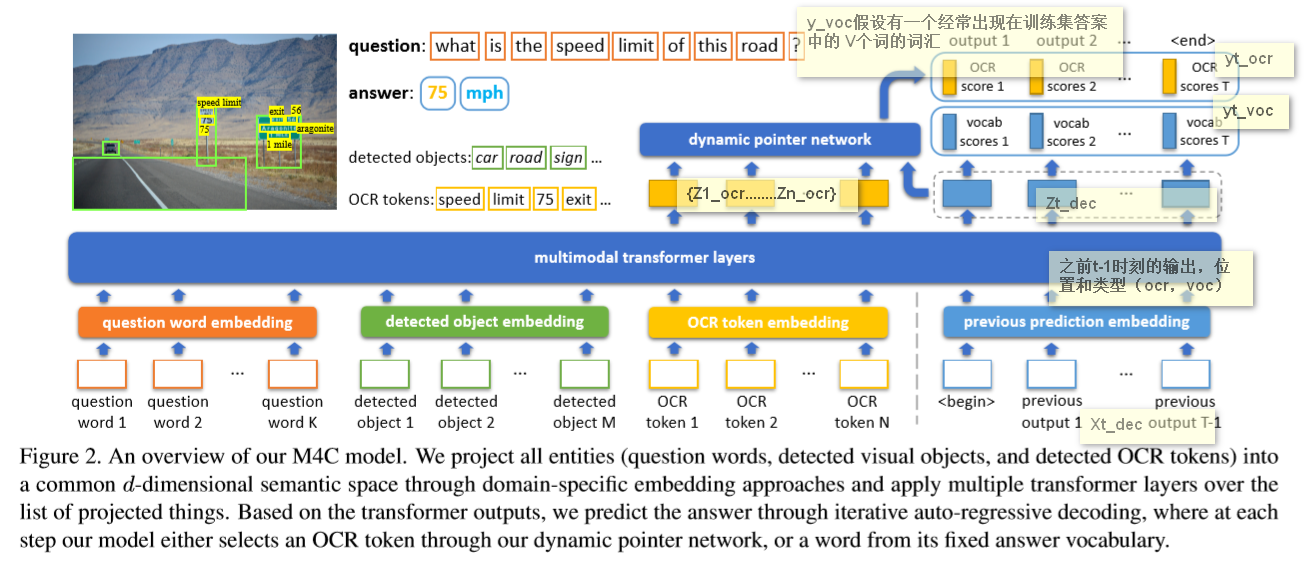
2020.3_CVPR_M4C
https://blog.csdn.net/m0_38007695/article/details/107772675
- idea
- 之前
- 基于两个模态的结合机制(如问题与图片特征的attention、问题与OCR提取文本的attention等)
- 将TextVQA当做分类任务,并且单步产生答案从OCR赋值或者直接生成。
- M4C
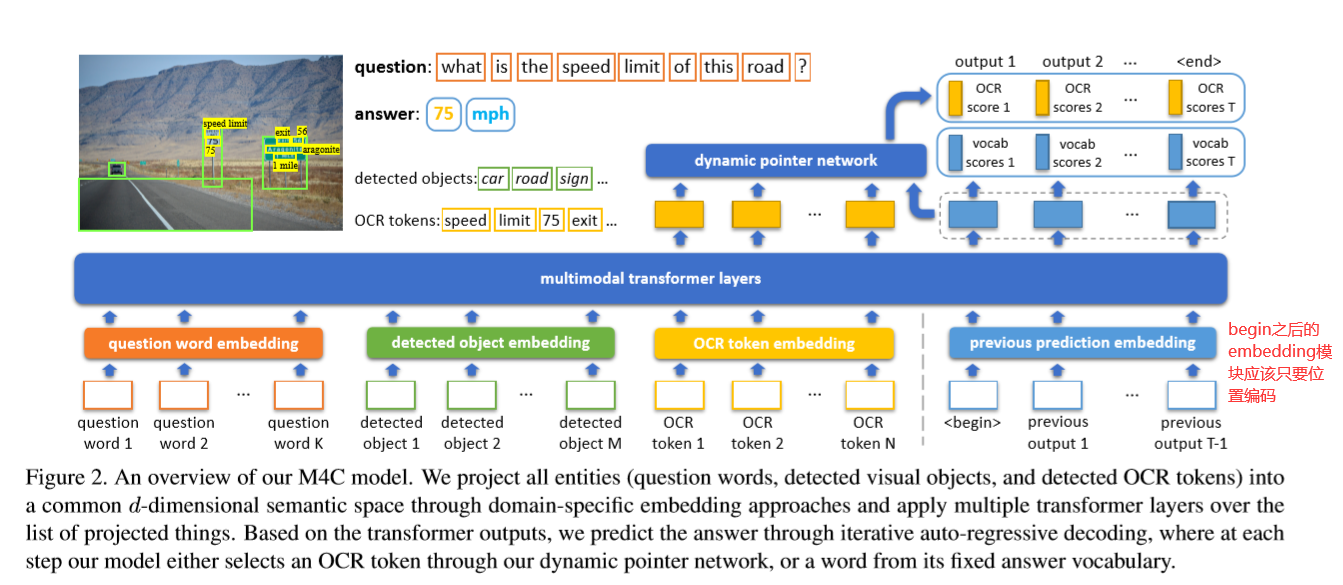
- 基于多模态(问题、图片、文本)的transformer架构和对于图片中文本的丰富表征,将所有模态中的实体投射到一个共同的语义embedding空间
- 可以进行分步预测产生答案,不是一次性产生
- 之前
- 框架
- encode
- 模型将问题中的单词、图片中识别到的物体、OCR识别文本作为向量投射到一个共同的embedding空间中,然后在所有的特征上使用多层transformer,丰富单个模态内以及模态相互之间的表征。
- 以均匀的方式对模态间和模态内的关系进行建模
- 输出是每个模态中实体的d维特征向量列表(特征),即在多模态上下文中的丰富嵌入
- decode
- 主要dynamic pointer network
- 自回归的方式逐个单词地对答案进行解码(解码时输入前一步的预测结果来进行下一步预测),每一步从OCR文本中复制或者从固定词汇表中选取
- 预测:固定答案词汇分数和动态OCR复制分数,从所有 V + N 候选者中选择得分最高的元素(词汇单词或者 OCR 字段)。
- pervious prediction embedding
- 两个额外的 d 维向量作为输入,一个对应于 t 步的位置嵌入向量,一个类型嵌入向量(表示前一个预测是固定词汇的单词还是 OCR 字段)
- encode

- begin之后的embedding是随机初始化或者是预训练模型里面查表得到的
2020.10.12_ACM MM_CRN
-
TextVQA难点
- 难以理解问题中复杂的逻辑,难以从丰富的图像内容中提取具体有用的信息来回答问题;
- 与文本相关的问题也与视觉概念相关,但难以捕捉文本与视觉概念之间的跨模态关系;
- 如果OCR(光学字符识别)系统检测不到目标文本,训练会非常困难
-
挑战
- 检测相当多的文本和对象,但并不是所有都与问题相关
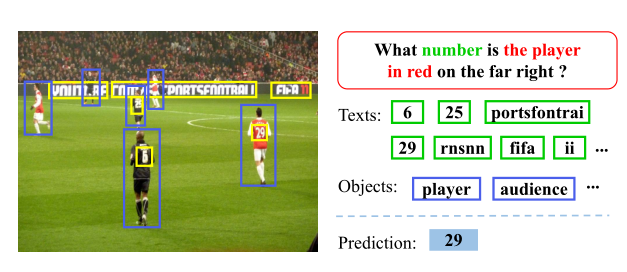
- 理解问题的复杂逻辑并从冗余的图像内容中提取特定的有用信息需要付出相当大的努力
- 光学字符的识别
- 检测相当多的文本和对象,但并不是所有都与问题相关
-
idea
- 一个渐进注意模块(PAM)和一个多模态推理图(MRG)模块组成。
- PAM将多模态信息融合操作视为一个逐步编码过程,并使用先前的关注结果来指导下一个融合过程。
- MRG旨在明确地模拟文本和视觉概念之间的联系和相互作用
- 一个渐进注意模块(PAM)和一个多模态推理图(MRG)模块组成。
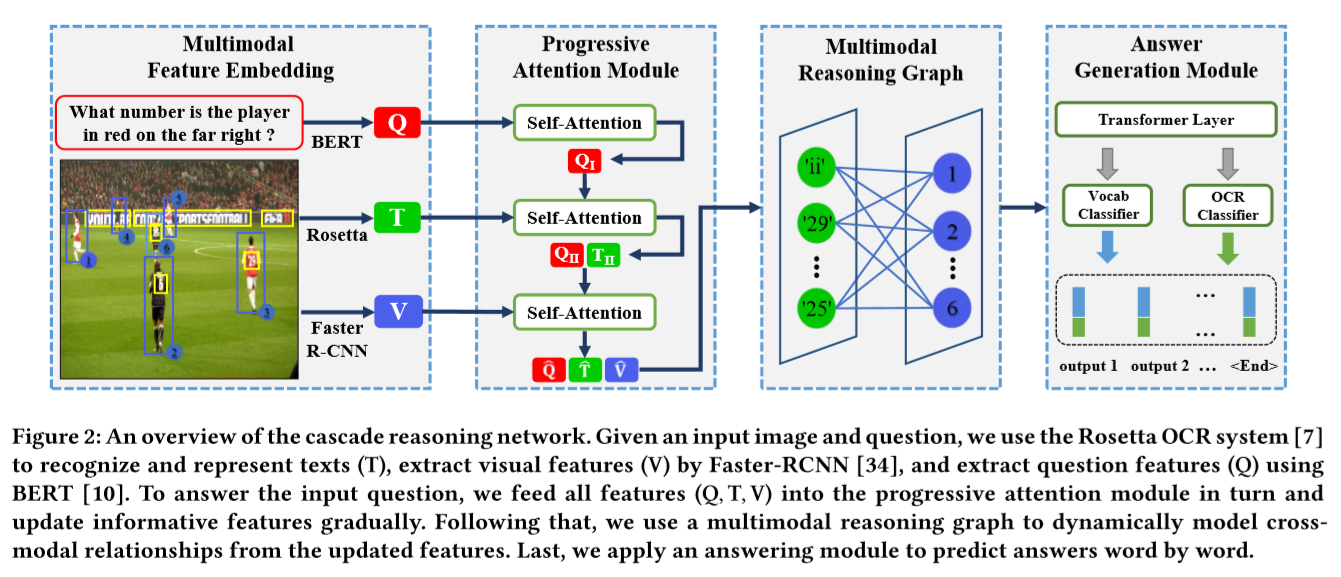
- CASCADE REASONING NETWORK
- Multimodal Feature Embedding
- 目的:在预训练模型下提取多模态的特征
- 问题
- BERT中提取特征,得到Q
- 图像
- Faster R-CNN to detect visual objects 得V
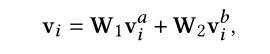
- V_a:视觉特征,V_b:位置信息(左上角,右下角)
- OCR system [7] to recognize texts (OCR tokens). 得T
- 四种不同类型的文本特征,基于M4C
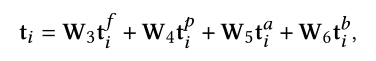
- t_f: a pretrained word embedding for the token
- t_p:capturing what characters are present in the token
- t_a:Faster RCNN中提取的外观特征 appearance feature
- t_b:Faster RCNN中提取的边框特征
- Faster R-CNN to detect visual objects 得V
- Progressive Attention Module (PAM,渐进注意力模块)
- 目的:融合多模态特征
- Q:we apply a stack of L1transformer layers with the parameters WI.
- 理解问题中的复杂逻辑和潜在信息
- Q-T
- 大多数问题与图像中的文本有关
- Q-T-V
- Multimodal Reasoning Graph (MRG,多模态的推理图)
- 图像中的文本和对象是一体的,都是视觉特征,而使用两中不同的模型会使得提取到的文本和对象特征独立分散,为了缓解这个问题,使用相对位置重建一个图像中文本与对象的关系。
- Graph construction.
- 构造了一个有向异构图
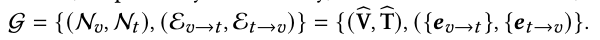
- Question-guided attention
- 融合文本和视觉对象之间的多模态信息(即T和V)
- 其实感觉就是融合了三个,Q和T,再Q和T和V
-

-

- Answer Generation Module (AGM)
- 一个L4-layer 的transformer和两个分类器
- 两个分类器表示
- 固定集:训练集中问题的答案标签频繁出现的words
- 动态集:从图片中识别的字符
- we use the prefix language modeling (LM) technique [33] to ensure that the input entries only use previous predictions,and avoid peeping at subsequent answering processes
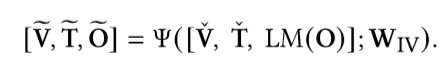
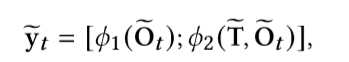
- 一个L4-layer 的transformer和两个分类器
- Multimodal Feature Embedding
- Training Loss
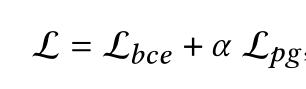
- 一个二元交叉熵损失L_bce
- 一个辅助任务得到的损失(强化学习)L_pg
- 目的:减轻模型对光学识别系统发依赖
- 如果模型的预测与目标高度相似,则模型可以获得辅助信号
- 强化学习:模型不仅学习语义信息,而且学习预测答案的字符组成
- S_ANLS 作为reward
- ANLS
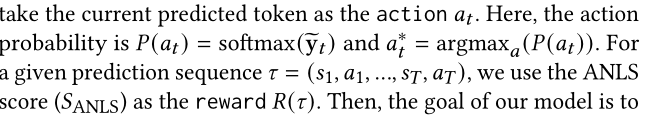
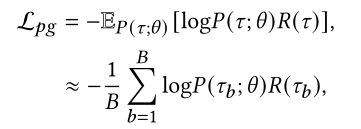
2020_ECCV_SA-M4C
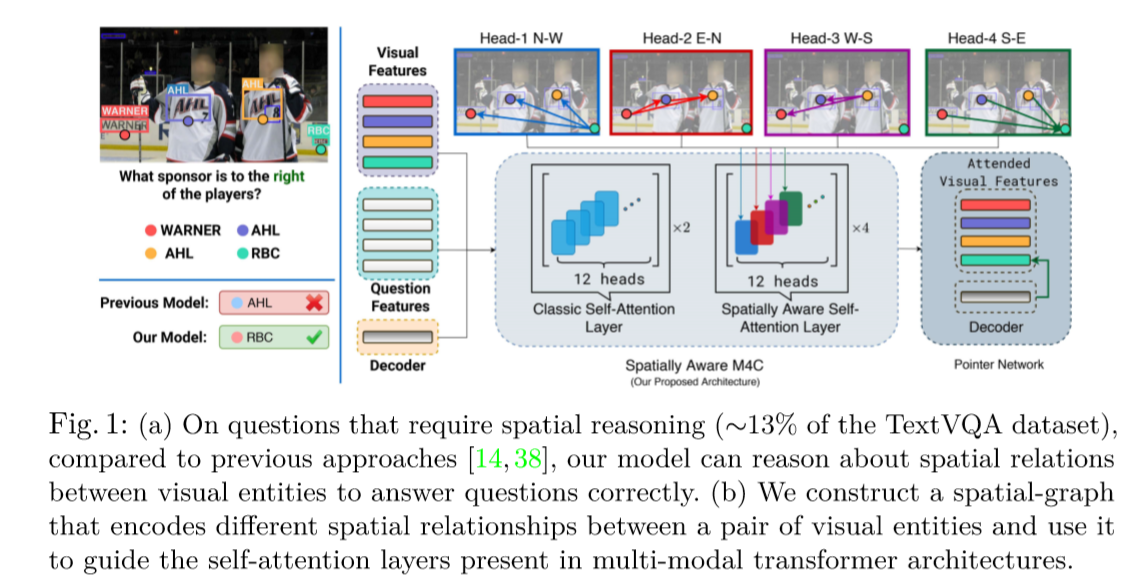
2021_AAAI_SSBaseline
-
https://blog.csdn.net/m0_38007695/article/details/112365357
-
A Simple Strong Baseline for TextVQA and TextCaps
-
本文方法将OCR特征分为视觉和语言特征分别处理,并且使用问题特征对OCR和object 特征进行过滤,去除冗余特征,减少计算消耗。在损失方面,添加了策略梯度损失来优化。
-

-

-

-

-
SSBaseline
-
Feature Preparation
- Question features
- 三层的 BERT 对问题进行编码
- OCR features
- OCR visual-part. 视觉
- 视觉特征由外观特征和空间特征组成,包含了文字的字体、颜色和背景。视觉特征从 Faster R-CNN 中提取

- OCR linguistic-part 语言
- OCR additional features
- 在识别OCR的 SBD-Trans 中,特定文本区域中的整体表征同时覆盖了OC的视觉和语言上下文
- 因此我们从该网络中引入 Recog-CNN 特征 X i o c r , r g {X_i^{ocr,rg}} Xiocr,rg来丰富文本特征
- Recog-CNN 特征同时加入到OCR视觉和语言特征中
-

- OCR visual-part. 视觉
- Visual features (OBJ)
- 在基于文本的任务中,图像中的视觉内容可以用来辅助推理过程中的文本信息
- 为了证明简单的注意力块(Attention Block)具有使用视觉特征的各种形式的能力,采用了基于网格的全局特征或基于区域的目标特征。(OBJ)
- Global features
- 从 ResNet-152 (在ImageNet上预训练)提取图像全局特征 X i g l o b {X_i^{glob}} Xiglob
- Object features
- 从与 OCR 相同的 Faster R-CNN 中提取基于区域的目标特征。 X i o b j {X_i^{obj}} Xiobj= X i o b j , f r {X_i^{obj,fr}} Xiobj,fr+ X i o b j , b x {X_i^{obj,bx}} Xiobj,bx
- Question features
-
Attention Block as Feature Summarizing

- 再将其与OCR_V,OCR_I,OBJ,做一个attention
- 输出一共六个向量
-
Stacked-Block Encoder
- TextVQA baseline model
- 输入到融合编码器(Fusion Encoder) 中,得到的六个向量以一对一的方式进行逐元素乘法,得到相应的嵌入,并将它们拼接在一起,然后使用全连接层把拼接嵌入转换为适当维度的上下文嵌入(context embedding)
- 在此基础上生成第一个答案。给定第一个答案,使用生成解码器生成剩余的答案
- TextCaps baseline model
- 在 TextCaps 中没有问题,使用 objects 作为 OCR 视觉和语言的 query,使用 OCR 作为 object 的 query,用 OCR 或 object 特征代替 question。其他与 TextVQA相同。
- TextVQA baseline model
-
Answer Generation Module
- 使用基于 transformer 的生成解码器回答一个问题或者生成字幕。
- 根据 context embedding 得到答案的第一个单词,然后使用解码器从预先建立的词汇表或从给定图像中提取的候选OCR中根据得分找到下一个词
- Training Loss
- 多标签二元交叉熵(bce)损失
- ANLS:计算两个短语之间的相似度

-
-
Element-wise Multiplication:逐元素乘法
-
Concatenated Embeddings:串联嵌入
-
Context Embedding:上下文嵌入
-
Object features:从与 OCR 相同的 Faster R-CNN 中提取基于区域的目标特征。
-
三个普通的注意力块来突出最相关的特征,并将它们组合成六个独立功能的向量,然后将其发送到基于变压器的融合编码器中。六个向量的参数少得多,节省了计算.
-
超参

-
- 先验知识
- 根据问题选择全局特征还是局部特征
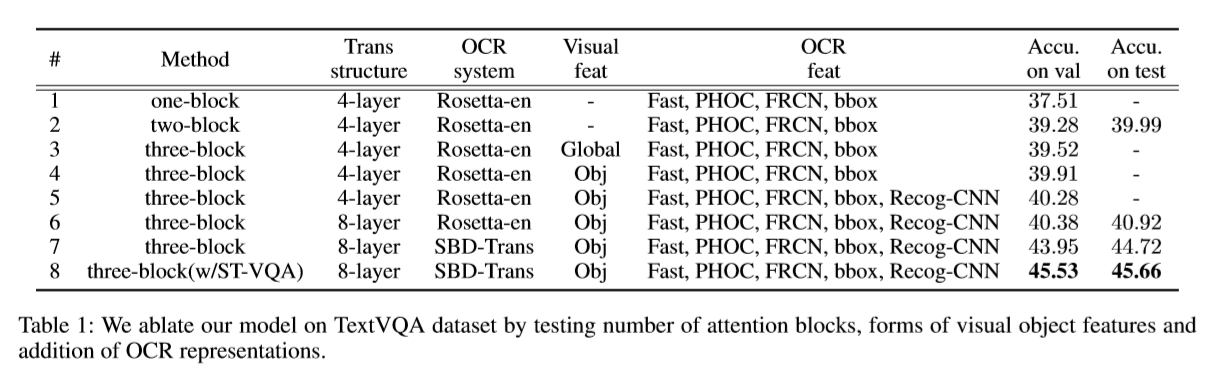
-

- OCR识别的准确性

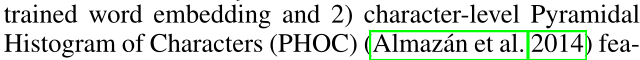

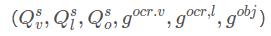
结果
CRN_TextVQA

SA-M4C-TextVQA
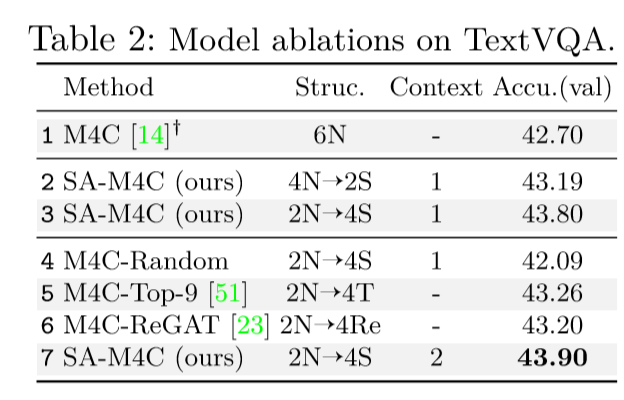
SSBaseline_TextVQA
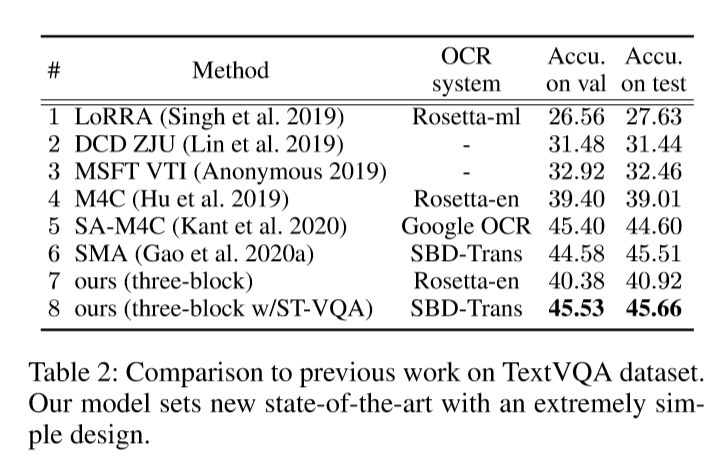
CRN_ST-VQA

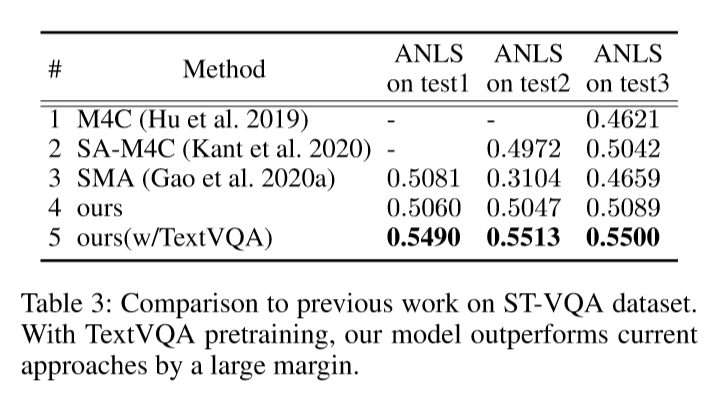
SA-M4C——ST-VQA
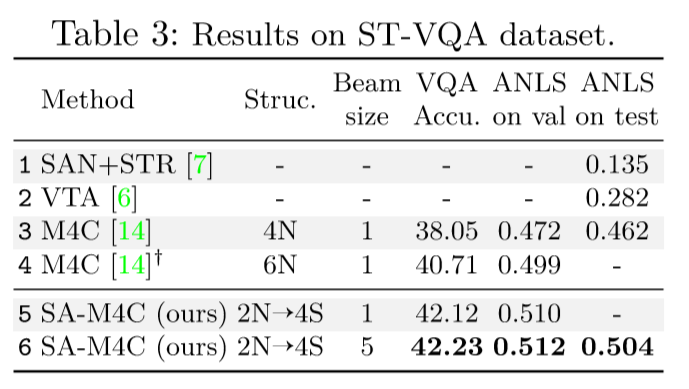
SSBaseline_ST-VQA
CRN——OCR-VQA

SSBaseline_TextCaps
1627096533990)]
SSBaseline_ST-VQA
[外链图片转存中…(img-P6TCg3el-1627096533992)]
CRN——OCR-VQA
SSBaseline_TextCaps


















 2571
2571

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









