







一、TextVQA拟解决的问题
许多的vqa问题包含图像中的文字信息。之前的VQA模型无法解决。
TextVQA与传统VQA的的区别是:
识别出图片中的文字信息,从这些文字、图像信息及相关推理中预测答案

TextVQA需要解决的主要问题如下所示
-
辨别出问题问的是有关文本的信息
-
检测出包含文本的区域
-
文本的图像信息转化成文本表示
-
分析各种特种从而关注到正确的文本区域
-
最终的答案是否需要对文本表示再处理
二、LoRRA(Look,Read,Reason & Answer)
模型主要包含三个部分
-
VQA模型:分析图像与问题的表示(可以是之前的任何注意力VQA模型)
-
OCR部分:阅读文字信息(可以是任何OCR模型)
-
答案部分:决定指向预设的答案空间或指向检测文本

1、VQA Model
question通过某种RNN(eg:LSTM)得到问题的特征表示
图像通过某种注意力机制(grid-based, bounding-box都行)获得图像的区域特征
组合如下公式
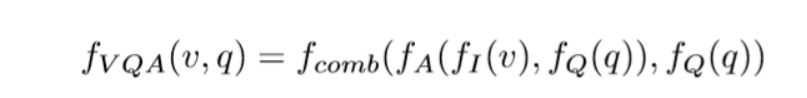
2、Reading Component
使用目标检测及OCR得到各个词,将词嵌入带入以下公式
与上面公式唯一不同的是将图像的区域特征变成了检测到的各个词的embedding,进入注意力机制
这里与VQA Model中的参数不共享
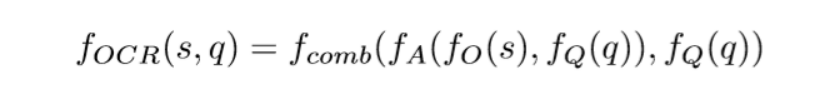
此外还将注意力权重与最后的OCR特征相连,确保之后的Answer Model能得到原始的注意力权重即ordering information
3、Answer Module
拓展answer space为N个预设答案加M个识别出的文字答案,MLP分类
如果最后Classify的答案为识别出的文字答案,我们直接复制为预测答案,即 copy if you need
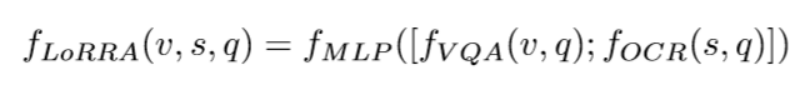
4、模型的不足之处
-
vqa中的大约十分之一的问题需要使用多个文本进行组合分析,而这里只对某个答案进行直接的复制。(论文的作者说之后会做更多的相关工作)
-
(本人观点)关于OCR文本的注意力机制,只与问题有关,而忽略了图像中的信息。相当于仅根据问题与检测出的文本对各个文本进行注意力的标注。对于一些复杂的问题,比如答案关系到文本在图片中具体位置的问题(例如:红色车的车牌号是多少?而此时图片中有好几辆车)便不能做出很好的回答。 本模型图像信息与text信息的融合仅在最后一步Classify,还有改进空间。
-
文本检测无法识别出倾斜和遮盖不清晰的文字。但是论文的作者相信,TextVQA的出现一定会促进OCR相关领域的发展。
-
毕竟是TextVQA领域中的第一篇paper,模型许多地方的处理显得过于朴素简单,但还是为这一领域之后的发展提供了解决问题的相关思路,奠定了基础。















 1115
1115











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









