









CVPR2019:LoRRA(数据集)
- 题目
Towards VQA Models That Can Read
下载链接
出自Facebook AI研究院 - 动机
视觉障碍者对于VQA的需求主要围绕于阅读图片上的问题,但是现有的VQA模型并没有这个功能。故本文提出了一个全新的数据集“TextVQA”,并基于此数据集提出了可以利用图片上文字信息进行VQA的方法LoRRA。

- 贡献
- 提出TextVQA数据集。
- 提出LoRRA方法(Look、Read、Reason & Answer),可以基于OCR的输出进行显式推理。
- 在TextVQA数据集上,LoRRA方法可以达到state-of-the-art。
- 方法
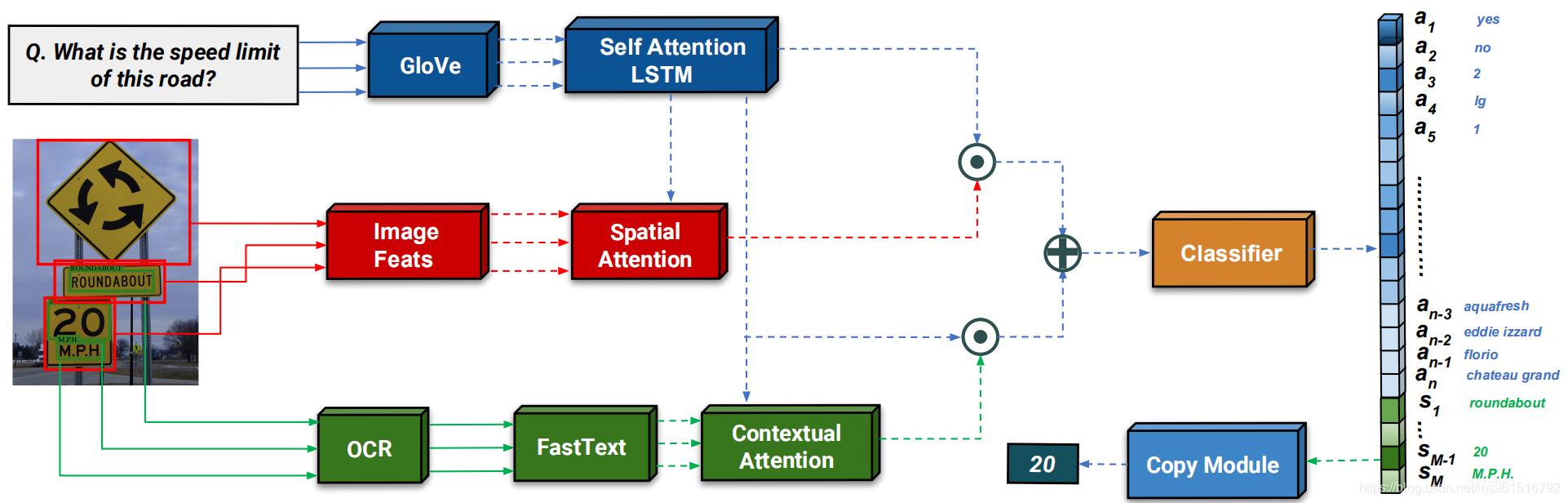
本文方法的整体框架如下图所示,共分为三个部分:对问题编码、提取图片特征、提取图片文字(OCR)。方法的流程一目了然,只是在传统的VQA方法上,添加了OCR模块提取图片中的文字信息,并在answer set中添加了OCR token。
TextVQA数据集的一些样本:

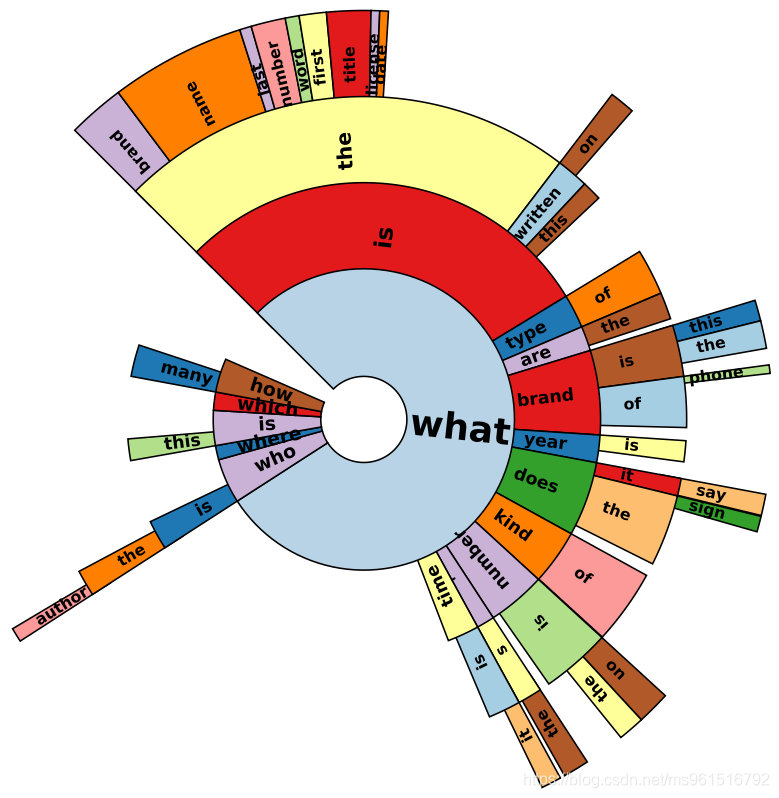
TextVQA数据集中,question中的word分布如下图所示。其中,以"what"开始的词比较多。
- 实验
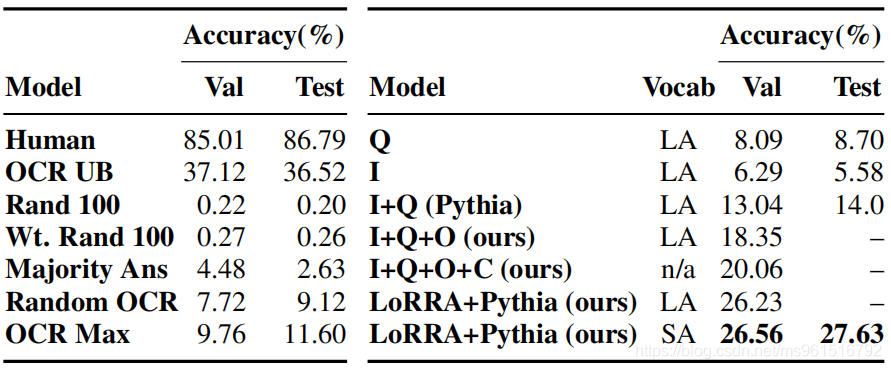
在TextVQA数据集上的实验结果。其中, Q Q Q代表Question特征, I I I代表Image特征, O O O代表OCR token特征, C C C代表Copy Module。
ICCV2019:ST-VQA(数据集)
- 题目
Scene Text Visual Question Answering
下载链接 - 动机
当前的VQA中,没有考虑图像中的文本信息。而作者认为,文本作为高级语义信息,应在VQA中占有一席之地,故提出ST-VQA数据集,并在此数据集上定义了一系列较难的任务。在这些任务中,需要考虑到上下文中的文本信息。同时,针对这些任务,本文提出了新的metric,可以同时考虑文本识别模块的推理错误和缺陷。

- 贡献
- 提出ST-VQA数据集,数据集中的问题和答案只能通过图像中的文本来回答。
- 提出了三种不同难度的任务,模拟不同程度上的先验知识(上下文信息)。
- 提出了一个新的metric,用于判别模型的准确性。
- 方法
如下图所示,ST-VQA数据集从六个不同的数据集搜集了共包括23038张图像和31791个问题,其中,训练集为19027/26308,测试集为2993/4163。

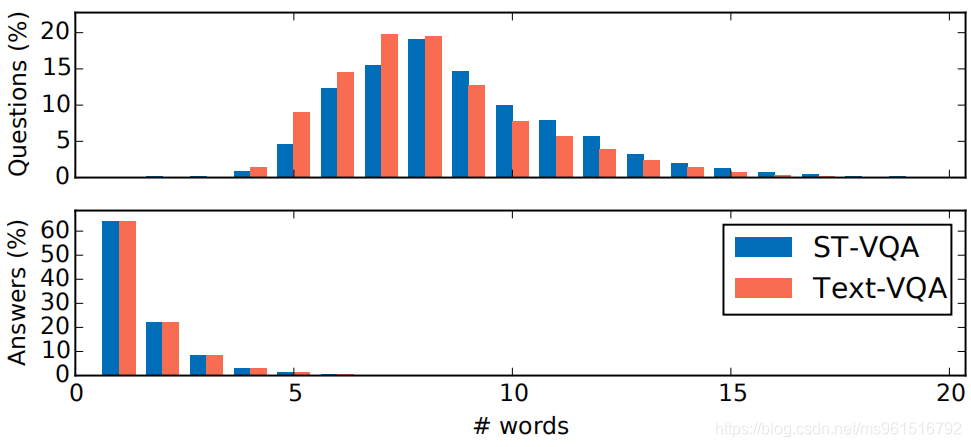
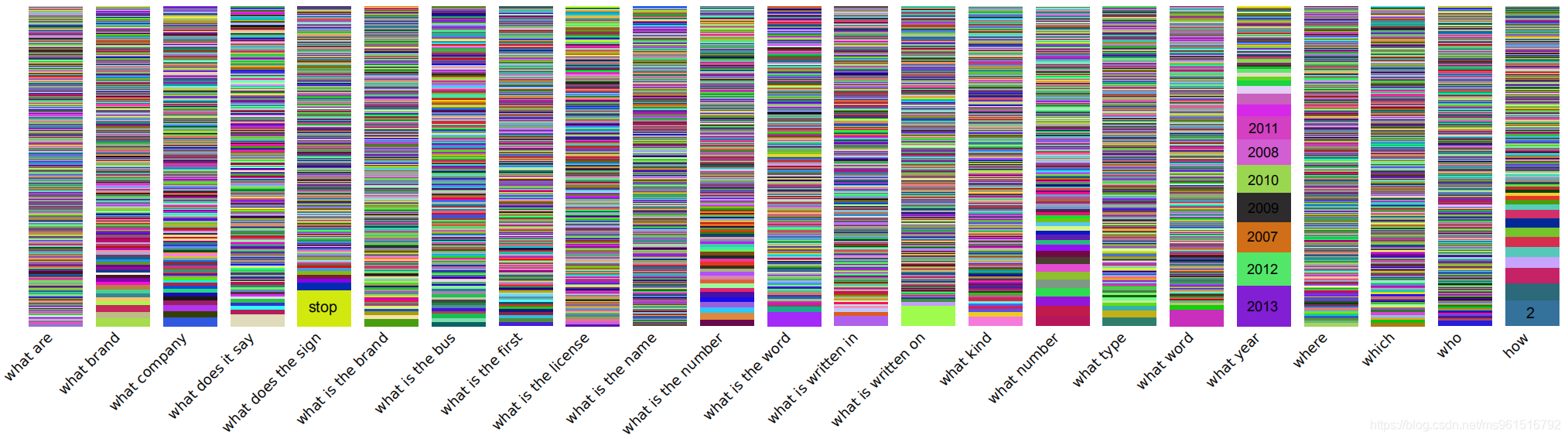
下图是ST-VQA数据中question和answer的单词长度的分布情况,和Text-VQA进行了对比,两个数据集的分布很相似。
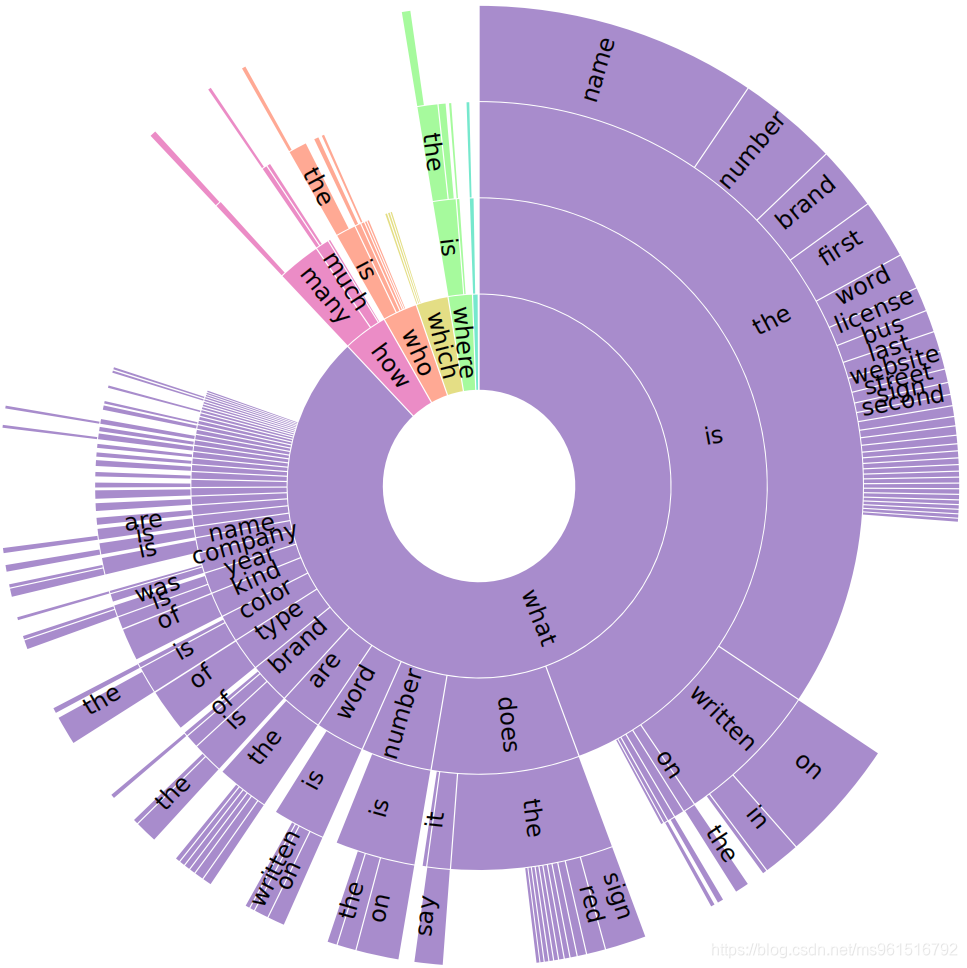
下图是ST-VQA数据集中,question中单词的使用频率分布,what 的使用频率最高。
下图是对于不同类型的问题,answer的分布情况。可以看出,对于不同类型的问题,answer的分布都较为平均。
- 实验
下图是一些baselines在ST-VQA数据集上的实验结果,其中,ANLS代表Average Normalized Levenshtein similarity(平均正则化编辑距离),是本文针对ST-VQA数据集提出的新metric。本文提出了三种不同的Task,分别是:strongly contextualised(强上下文)、weakly contextualised(弱上下文)和open vocabulary(开放词汇)。这三种不同的task使用不同的先验知识(字典)。对于强上下文,每张图片具有自己的字典,字典中包括100个单词。对于弱上下文,所有图片共用一个大的字典,字典中包括30000个单词,其中22000个是ground truth,其他的是干扰项。对于开放词汇,字典是空的,即:没有先验知识。
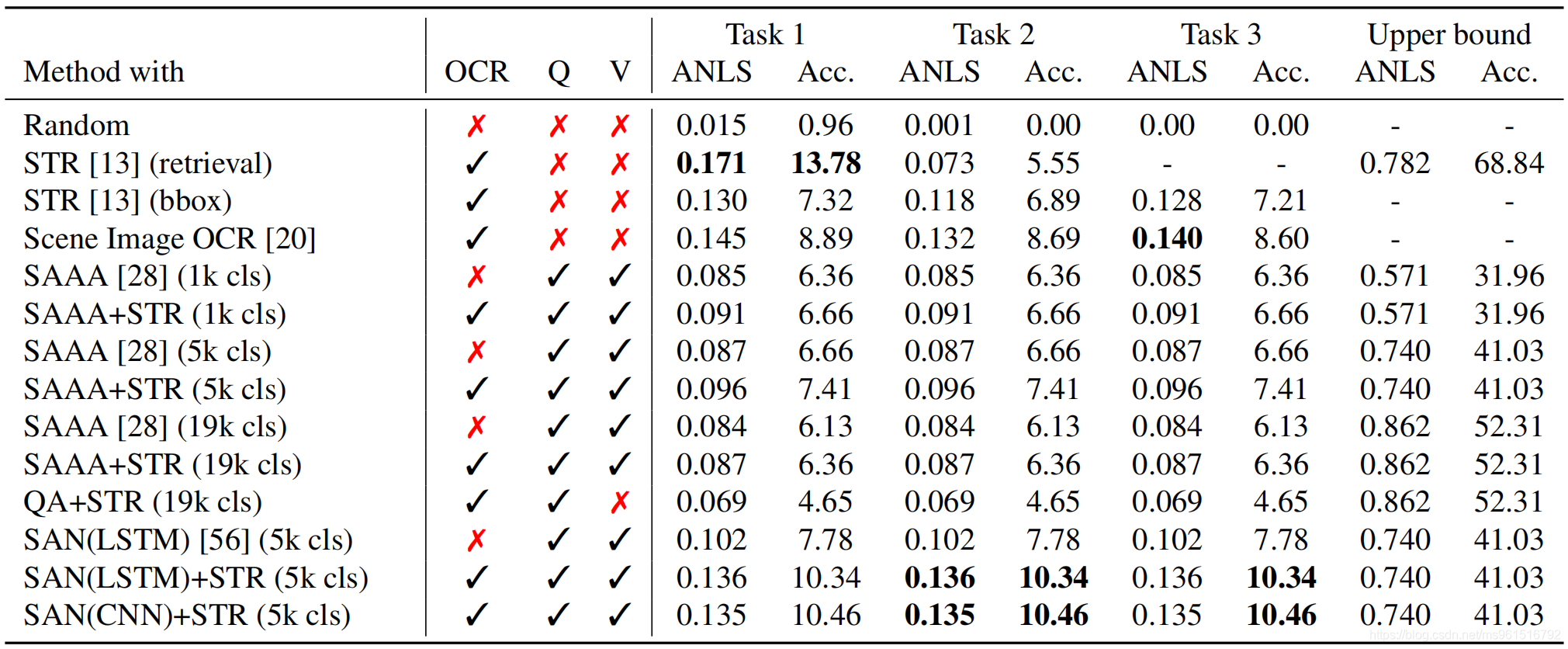
在上述实验结果中,Random代表从字典中随机抽取一个作为答案。STR的全称是Scene Text Recognition(场景文本识别),STR(retrieval)和STR(bbox)使用了两种不同的策略,前者使用特定的任务字典作为给定图像的查询,后者针对图像中最大的文本示例提出问题。Scene Image OCR将检测到的文本排序输出置信度最高的。SAAA是一个标准的VQA模型结构,使用CNN+LSTM。SAN也是标准的VQA模型结构,使用预训练的VGG提取图像特征,使用LSTM提取question特征。
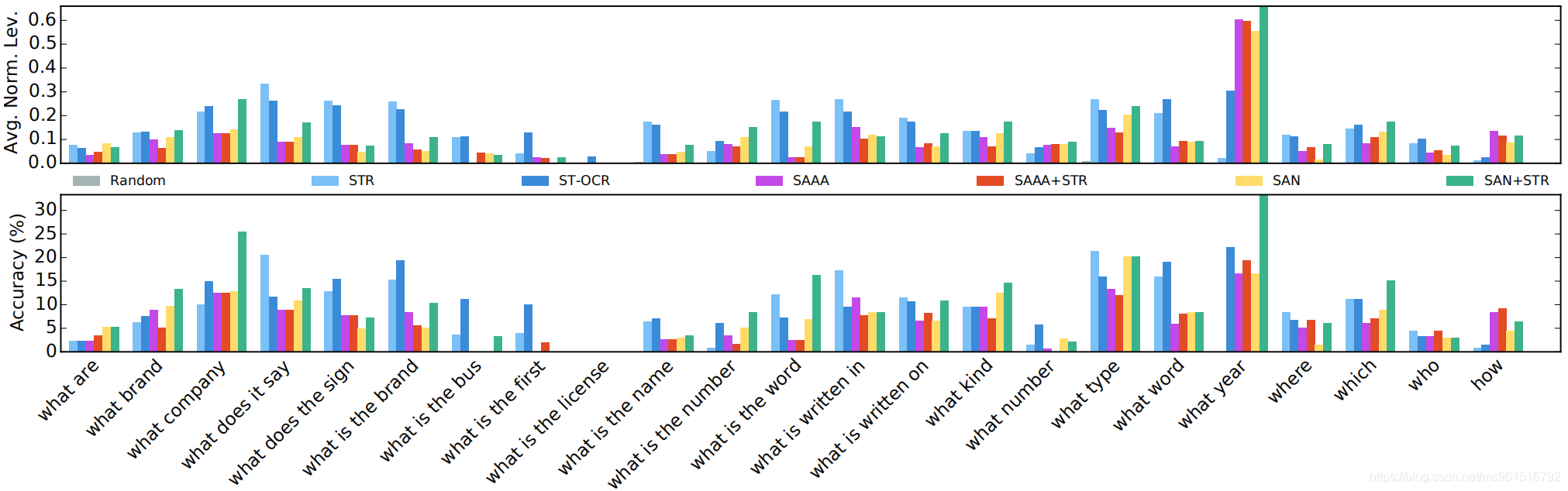
在task3上,不同方法的在不同类型问题上的准确率展示。
在task1上的结果展示:


















 1618
1618

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









