






cuda高效的内存分配
统一内存(Unified addressing)
统一内存是CUDA编程模型的一个组成部分,CUDA 6.0首次介绍了该模型
它定义了一个托管(managed)内存空间,其中所有处理器(包括CPU和GPU)都可以看到共同的地址空间。
通过让底层系统自己管理CUDA数据访问和位置,避免显式数据拷贝,这主要带来两方面好处:
- 简化编程
- 通过透明地将数据迁移到使用它的处理器,可以最大限度地提高数据访问速度
设备是否支持统一内存可以通过一下代码查询
//如果支持,unifiedAddressing字段为1
int deviceCount;
cudaGetDeviceCount(&deviceCount);
int device;
for (device = 0; device < deviceCount; ++device) {
cudaDeviceProp deviceProp;
cudaGetDeviceProperties(&deviceProp, device);
printf("Device %d has compute capability %d.%d.\n",
device, deviceProp.major, deviceProp.minor);
}
当应用程序是64位进程,并且主机和所有具有计算能力2.0(附录说的是3.0以上)及更高版本的设备都使用一个地址空间
此时通过CUDA API分配的所有主机内存和所有受支持设备上开辟的设备内存都在此虚拟地址范围内
通过CUDA接口分配的主机内存或者任何使用统一地址空间的设备分配的设备内存都可以使用cudaPointerGetAttributes()的指针来确定地址。
使用统一内存进行数据拷贝不需要执行拷贝类型,只需使用cudaMemcpyDefault,这同样适用于不使用CUDA API分配的主机内存,只要设备使用的是统一地址
如果使用统一地址空间,通过cudaHostAlloc()分配的页锁定主机内存会默认cudaHostAllocPortable,此时指针可以直接在内核函数使用,而无需像页锁定内存那样先通过cudaHostGetDevicePointer()函数获取设备指针
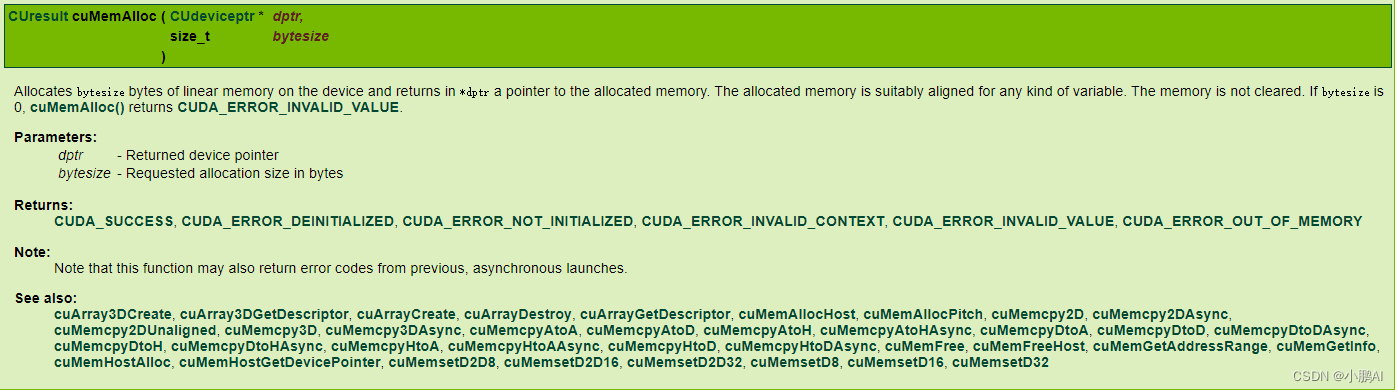
分配线性内存
cuMemAlloc()
线性内存被组织在单个连续的地址空间中,可以直接以及线性地访问这些内存位置。
内存分配空间以字节为大小,并返回所分配的内存地址
分配主机锁页内存
cuMemAllocHost()
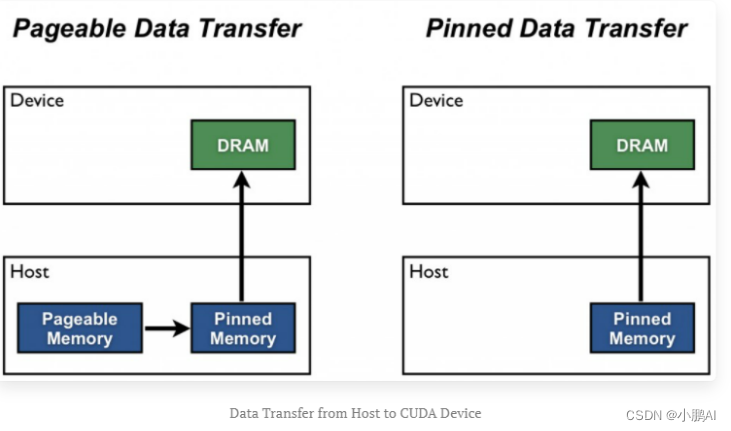
锁页内存:页面不允许被调入调出的叫锁页内存,反之叫可分页内存。
优点:
- 速度快
- 设备可以直接访问内存,与可分页内存相比,它的读写带宽要高得多
- 驱动程序会跟踪使用
cuMemAllocHost()分配的虚拟内存范围,并自动加速对cuMemcpy()等函数的调用
缺点:
-
分配过多锁业内存会减少系统可用于分页的内存量,可能会降低系统性能
-
在主机和设备之间为数据交换分配临时区域时,最好少用此功能。
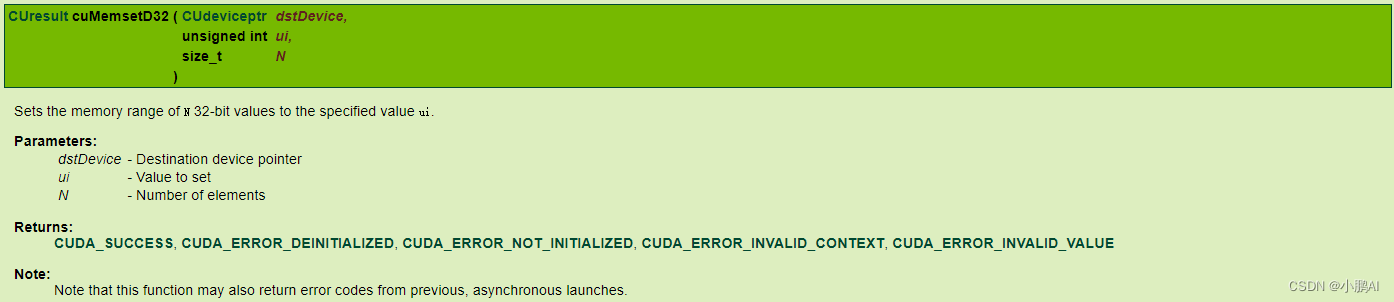
内存的初始化
cuMemsetD32(CUdeviceptr dstDevice, unsigned int ui, size_t N)
内存的释放
cuMemFreeHost()

代码示例
// CUDA驱动头文件cuda.h
#include <cuda.h>
#include <stdio.h>
#include <string.h>
#define checkDriver(op) __check_cuda_driver((op), #op, __FILE__, __LINE__)
bool __check_cuda_driver(CUresult code, const char* op, const char* file, int line){
if(code != CUresult::CUDA_SUCCESS){
const char* err_name = nullptr;
const char* err_message = nullptr;
cuGetErrorName(code, &err_name);
cuGetErrorString(code, &err_message);
printf("%s:%d %s failed. \n code = %s, message = %s\n", file, line, op, err_name, err_message);
return false;
}
return true;
}
int main(){
// 检查cuda driver的初始化
checkDriver(cuInit(0));
// 创建上下文
CUcontext context = nullptr;
CUdevice device = 0;
checkDriver(cuCtxCreate(&context, CU_CTX_SCHED_AUTO, device));
printf("context = %p\n", context);
// 输入device prt向设备要一个100 byte的线性内存,并返回地址
CUdeviceptr device_memory_pointer = 0;
checkDriver(cuMemAlloc(&device_memory_pointer, 100)); // 注意这是指向device的pointer,
printf("device_memory_pointer = %p\n", device_memory_pointer);
// 输入二级指针向host要一个100 byte的锁页内存,专供设备访问
float* host_page_locked_memory = nullptr;
checkDriver(cuMemAllocHost((void**)&host_page_locked_memory, 100));
printf("host_page_locked_memory = %p\n", host_page_locked_memory);
// 向page-locked memory 里放数据(仍在CPU上),可以让GPU可快速读取
host_page_locked_memory[0] = 123;
printf("host_page_locked_memory[0] = %f\n", host_page_locked_memory[0]);
/*
host page locked memory 声明的时候为float*型,可以直接转换为device ptr
这才可以送给cuda核函数(利用DMA(Direct Memory Access)技术)
初始化内存的值: cuMemsetD32 ( CUdeviceptr dstDevice, unsigned int ui, size_t N )
初始化值必须是无符号整型,因此需要将new_value进行数据转换:
但不能直接写为:(int)value,必须写为*(int*)&new_value, 我们来分解一下这条语句的作用:
1. &new_value获取float new_value的地址
(int*)将地址从float * 转换为int*以避免64位架构上的精度损失
*(int*)取消引用地址,最后获取引用的int值
*/
float new_value = 555;
checkDriver(cuMemsetD32((CUdeviceptr)host_page_locked_memory, *(int*)&new_value, 1));
printf("host_page_locked_memory[0] = %f\n", host_page_locked_memory[0]);
// 释放内存
checkDriver(cuMemFreeHost(host_page_locked_memory));
return 0;
}
参考文献
- https://developer.nvidia.com/cuda-toolkit-archive
- https://docs.nvidia.com/cuda/archive/11.2.0/
- https://developer.nvidia.com/blog/unified-memory-cuda-beginners/
- https://leimao.github.io/blog/Page-Locked-Host-Memory-Data-Transfer/
- https://www.youtube.com/watch?v=p9yZNLeOj4s
- https://blog.csdn.net/Geek_/article/details/104359596
- https://developer.download.nvidia.cn/compute/DevZone/docs/html/C/doc/html/
















 1714
1714











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











