






目录
0.nvcc -V和nvidia-smi
nvcc
nvcc其实就是CUDA的编译器,可以从CUDA Toolkit的/bin目录中获取,类似于gcc就是c语言的编译器程序是要经过编译器编程成可执行的二进制文件,而cuda程序有两种代码,
- 一种是运行在cpu上的host代码,
- 一种是运行在gpu上的device代码,
所以
nvcc编译器要保证两部分代码能够编译成二进制文件在不同的机器上执行
nvidia-smi
nvidia-smi全程是NVIDIA System Management Interface ,它是一个基于前面介绍过的NVIDIA Management Library(NVML)构建的命令行实用工具,旨在帮助管理和监控NVIDIA GPU设备。
nvcc -V和nvidia-smi显示的CUDA版本不同?
nvcc -V
nvidia-smi
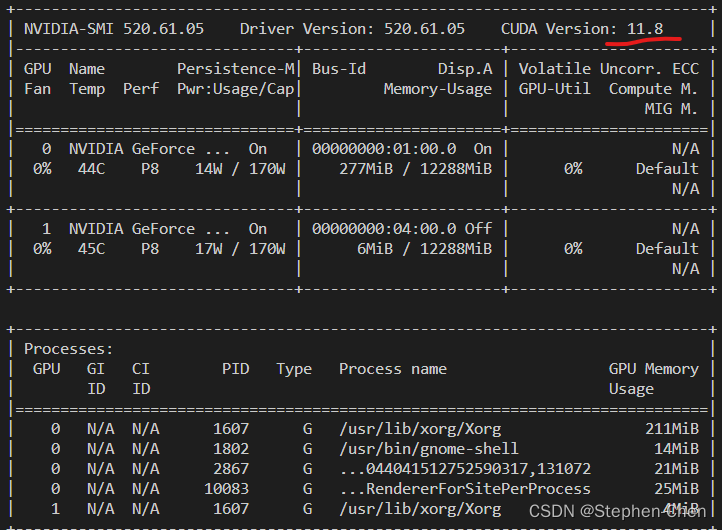
可以看到nvcc的CUDA 版本是11.3,而nvidia-smi的CUDA版本是11.8
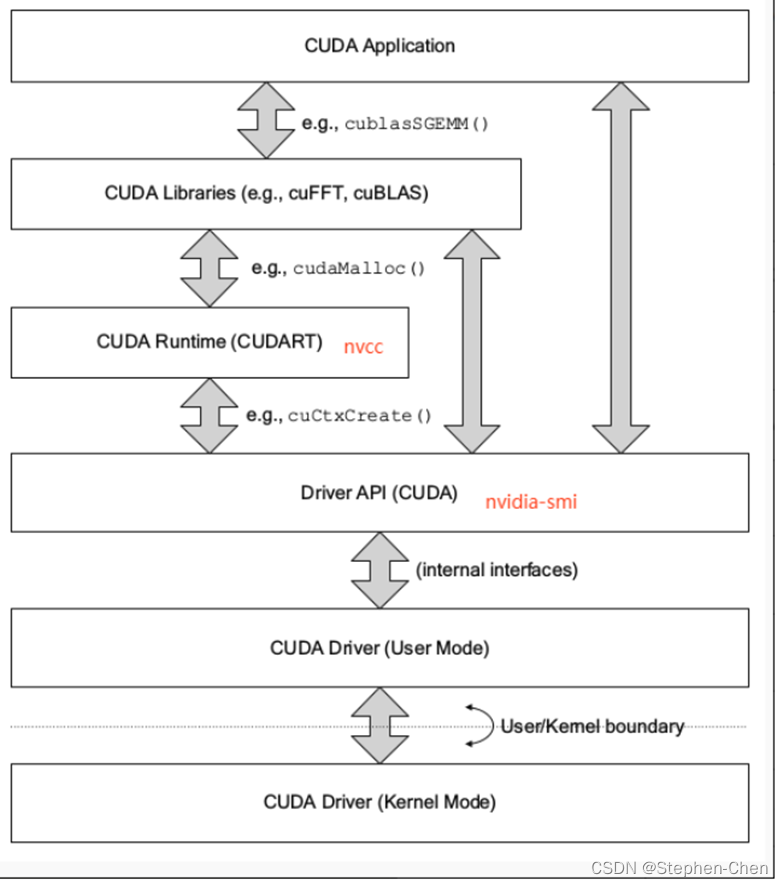
CUDA有两个主要的API:runtime(运行时) API和driver API。这两个API都有对应的CUDA版本(如9.2和10.0等)。
- 用于支持driver API的必要文件(如
libcuda.so)是由GPU driver installer安装的。nvidia-smi就属于这一类API。- 用于支持runtime API的必要文件(如
libcudart.so以及nvcc)是由CUDA Toolkit installer安装的。(CUDA Toolkit Installer有时可能会集成了GPU driver Installer)。nvcc是与CUDA Toolkit一起安装的CUDA compiler-driver tool,它只知道它自身构建时的CUDA runtime版本。它不知道安装了什么版本的GPU driver,甚至不知道是否安装了GPU driver。综上,如果driver API和runtime API的CUDA版本不一致可能是因为你使用的是单独的GPU driver installer,而不是CUDA Toolkit installer里的GPU driver installer。就装CUDA的时候没装对应驱动选项
Runtime API和Driver API区别
runtime和driver API在很多情况非常相似,也就是说用起来的效果是等价的,但是你不能混合使用这两个API,因为二者是互斥的。
区别:
复杂性:
- runtime API通过提供隐式初始化、上下文管理和模块管理来简化设备代码管理。这使得代码更简单,但也缺乏驱动程序API所具有的控制级别。
- 相比之下,driver API提供了更细粒度的控制,特别是在上下文和模块加载方面。实现内核启动要复杂得多,因为执行配置和内核参数必须用显式函数调用指定。
控制:
- 对于runtime API,其在运行时,所有内核都在初始化期间自动加载,并在程序运行期间保持加载状态。
- 而使用driver API,可以只加载当前需要的模块,甚至动态地重新加载模块。driver API也是语言独立的,因为它只处理
cubin对象。上下文管理:
上下文管理可以通过driver API完成,但是在runtime API中不公开。相反,runtime API自己决定为线程使用哪个上下文
- 如果一个上下文通过driver API成为调用线程的当前上下文,runtime将使用它,
- 如果没有这样的上下文,它将使用“主上下文(primary context)”。
runtime使用的上下文,即当前上下文或主上下文,可以用cudaDeviceSynchronize()同步,也可以用cudaDeviceReset()销毁。但是,将runtime API与主上下文一起使用会有tradeoff。例如,对于那些需要给较大的软件包写插件的开发者来说者会带来不少麻烦,因为如果所有的插件都在同一个进程中运行,它们将共享一个上下文,但可能无法相互通信。也就是说,如果其中一个在完成所有CUDA工作后调用cudaDeviceReset(),其他插件将失败,因为它们使用的上下文在它们不知情的情况下被破坏。
为了避免这个问题,CUDA clients可以使用driver API来创建和设置当前上下文,然后使用runtime API来处理它。但是,上下文可能会消耗大量的资源,比如设备内存、额外的主机线程和设备上上下文切换的性能成本。当将driver API与基于runtime API(如cuBLAS或cuFFT)构建的库一起使用时,这种runtime-driver上下文共享非常重要。
一.DriverAPI
- CUDA Driver 是与GPU沟通的驱动级别底层API。
- 对DriverAPI的理解有利于理解RuntimeAPI
- CUDA Driver随着显卡的驱动发布,和cudatoolkit分开看
- CUDA Driver对应于cuda.h和libcuda.so文件
主要知识点:Context的管理机制,CUDA系列接口的开发习惯(错误检查方法)以及还有内存模型
关于context:
- 手动管理的context:cuCtxCreate(手动管理,以堆栈方式push/pop)
- 自动管理的context:cuDevicePrimaryCtxRetain(自动管理,runtime api以此为基础)
关于内存:
1.CPU内存(Host Memory)
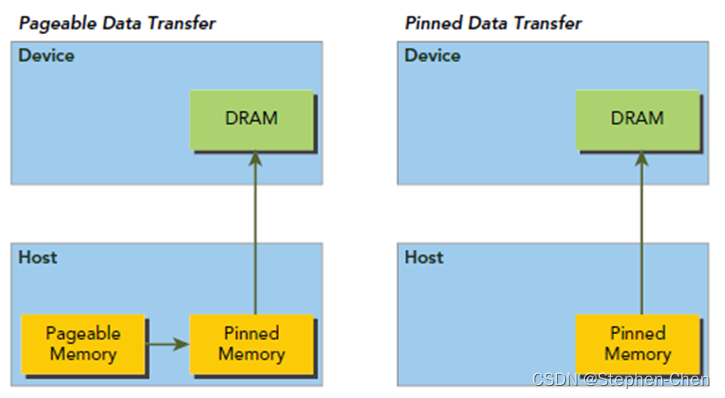
- Pageable Memory:可分页内存
- Page-Locked Memory:页锁定内存
2.GPU内存(Device Memory)
- Global Memory:全局内存
- Shared Memory:共享内存
- 以及其他多种内存
二.CUDA初始化
culnit意义:初始化驱动API,如果不执行所有API都将返回错误,全局只需要执行一次。
初始化没有对应的cuDestroy,不需要释放,程序销毁自动释放。
// CUDA驱动头文件cuda.h
#include <cuda.h>
#include <stdio.h> // 因为要使用printf
#include <string.h>
int main(){
/*
cuInit(int flags), 这里的flags目前必须给0;
对于cuda的所有函数,必须先调用cuInit,否则其他API都会返回CUDA_ERROR_NOT_INITIALIZED
https://docs.nvidia.com/cuda/archive/11.2.0/cuda-driver-api/group__CUDA__INITIALIZE.html
*/
CUresult code=cuInit(0); //CUresult 类型:用于接收一些可能的错误代码
if(code != CUresult::CUDA_SUCCESS){
const char* err_message = nullptr;
cuGetErrorString(code, &err_message); // 获取错误代码的字符串描述
// cuGetErrorName (code, &err_message); // 也可以直接获取错误代码的字符串
printf("Initialize failed. code = %d, message = %s\n", code, err_message);
return -1;
}
/*
测试获取当前cuda驱动的版本
显卡、CUDA、CUDA Toolkit
1. 显卡驱动版本,比如:Driver Version: 460.84
2. CUDA驱动版本:比如:CUDA Version: 11.2
3. CUDA Toolkit版本:比如自行下载时选择的10.2、11.2等;这与前两个不是一回事, CUDA Toolkit的每个版本都需要最低版本的CUDA驱动程序
三者版本之间有依赖关系, 可参照https://docs.nvidia.com/cuda/cuda-toolkit-release-notes/index.html
nvidia-smi显示的是显卡驱动版本和此驱动最高支持的CUDA驱动版本
*/
int driver_version = 0;
code = cuDriverGetVersion(&driver_version); // 获取驱动版本
printf("CUDA Driver version is %d\n", driver_version); // 若driver_version为11020指的是11.2
// 测试获取当前设备信息
char device_name[100]; // char 数组
CUdevice device = 0;
code = cuDeviceGetName(device_name, sizeof(device_name), device); // 获取设备名称、型号如:Tesla V100-SXM2-32GB // 数组名device_name当作指针
printf("Device %d name is %s\n", device, device_name);
return 0;
}三.返回值检查
- 正确友好的检查cuda函数的返回值,有利于程序的组织结构
- 使得代码可读性更好,错误更容易发现
第一个checkDriver版本:
用宏定义检查:
// 使用有参宏定义检查cuda driver是否被正常初始化, 并定位程序出错的文件名、行数和错误信息
// 宏定义中带do...while循环可保证程序的正确性
#define checkDriver(op) \
do{ \
auto code = (op); \
if(code != CUresult::CUDA_SUCCESS){ \
const char* err_name = nullptr; \
const char* err_message = nullptr; \
cuGetErrorName(code, &err_name); \
cuGetErrorString(code, &err_message); \
printf("%s:%d %s failed. \n code = %s, message = %s\n", __FILE__, __LINE__, #op, err_name, err_message); \
return -1; \
} \
}while(0)int main(){
//检查cuda driver的初始化。虽然不初始化或错误初始化某些API不会报错(不信你试试),但安全起见调用任何API前务必检查cuda driver初始化
// cuInit(2); // 正确的初始化应该给flag = 0
// checkDriver(cuInit(0));
// 测试获取当前cuda驱动的版本
int driver_version = 0;
checkDriver(cuDriverGetVersion(&driver_version));
printf("Driver version is %d\n", driver_version);
// 测试获取当前设备信息
char device_name[100];
CUdevice device = 0;
checkDriver(cuDeviceGetName(device_name, sizeof(device_name), device));
printf("Device %d name is %s\n", device, device_name);
return 0;
}checkDriver函数返回报错:
src/main.cpp:37 cuDeviceGetName(device_name, sizeof(device_name), device) failed.
code = CUDA_ERROR_NOT_INITIALIZED, message = initialization error
Makefile:72: recipe for target 'run' failed
make: *** [run] Error 255第二个checkDriver版本:
用bool值来做为返回参数
// 很明显,这种代码封装方式,更加的便于使用
//宏定义 #define <宏名>(<参数表>) <宏体>
#define checkDriver(op) __check_cuda_driver((op), #op, __FILE__, __LINE__)
bool __check_cuda_driver(CUresult code, const char* op, const char* file, int line){
if(code != CUresult::CUDA_SUCCESS){
const char* err_name = nullptr;
const char* err_message = nullptr;
cuGetErrorName(code, &err_name);
cuGetErrorString(code, &err_message);
printf("%s:%d %s failed. \n code = %s, message = %s\n", file, line, op, err_name, err_message);
return false;
}
return true;
}int main(){
// 检查cuda driver的初始化
// 实际调用的是__check_cuda_driver这个函数
checkDriver(cuInit(0));
// 测试获取当前cuda驱动的版本
int driver_version = 0;
if(!checkDriver(cuDriverGetVersion(&driver_version))){
return -1;
}
printf("Driver version is %d\n", driver_version);
// 测试获取当前设备信息
char device_name[100];
CUdevice device = 0;
checkDriver(cuDeviceGetName(device_name, sizeof(device_name), device));
printf("Device %d name is %s\n", device, device_name);
return 0;
}四.CUcontext:cuda的上下文
context只是为了方便控制deviced一种手段而提出来的
- context是一种上下文,关联对GPU的所有操作
- context与一块显卡关联,一个显卡可以被多个context关联
- 每个线程都有一个栈结构存储context,栈顶是当前使用的context,所有的api都以当前context为操作目标:栈的存在是为了方便控制多个设备
- 试想一下,如果执行任何操作你都需要传递一个device决定送到哪个设备执行,得多麻烦

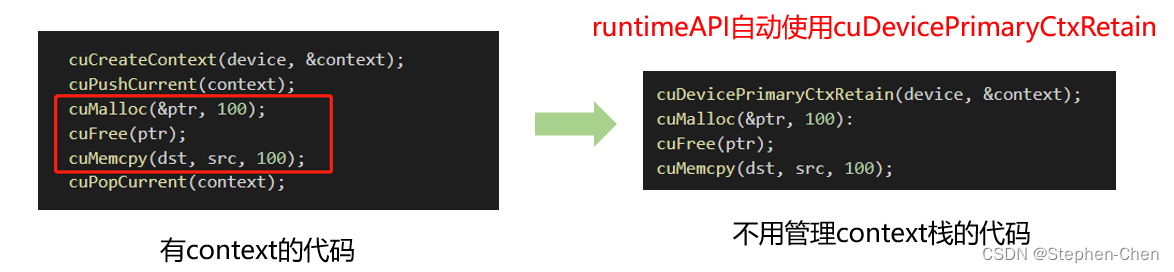
优化:将CreateContext、PushCurrent、PopCurrent操作合并为cuDevicePrimaryCtxRetain
- primaryContext:给我设备id,给你context并设置好,此时一个显卡对应一个primary context
- 不同线程,只要设备id一样,primary context就一样。context是线程安全的

五.内存分配
1. 内存分配: - 1.1. 分配线性内存`cuMemAlloc()`: - 1.1.1. 线性内存:线性内存被组织在单个连续的地址空间中,可以直接以及线性地访问这些内存位置。 - 1.1.2. 内存分配空间以字节为大小,并返回所分配的内存地址 - 1.2. 分配主机锁页内存`cuMemAllocHost()`: - 2.1. 锁页内存: - 2.1.1. 定义:页面不允许被调入调出的叫锁页内存,反之叫可分页内存。 - 2.1.2. 有啥好处:快。 - a. 设备可以直接访问内存,与可分页内存相比,它的读写带宽要高得多 - b. 驱动程序会跟踪使用`cuMemAllocHost()`分配的虚拟内存范围,并自动加速对cuMemcpy()等函数的调用。 - 2.1.3. 使用注意:分配过多锁业内存会减少系统可用于分页的内存量,可能会降低系统性能。因此,在主机和设备之间为数据交换分配临时区域时,最好少用此功能。 - 2.2. 这里是从主机分配内存,因此不是输入device prt的地址,而是一个主机的二级地址。 2. 内存的初始化`cuMemsetD32(CUdeviceptr dstDevice, unsigned int ui, size_t N)`, 将N个32位值的内存范围设置为指定的值ui 3. 内存的释放`cuMemFreeHost()`: 有借有还 再借不难~
// CUDA驱动头文件cuda.h
#include <cuda.h>
#include <stdio.h>
#include <string.h>
#define checkDriver(op) __check_cuda_driver((op), #op, __FILE__, __LINE__)
bool __check_cuda_driver(CUresult code, const char* op, const char* file, int line){
if(code != CUresult::CUDA_SUCCESS){
const char* err_name = nullptr;
const char* err_message = nullptr;
cuGetErrorName(code, &err_name);
cuGetErrorString(code, &err_message);
printf("%s:%d %s failed. \n code = %s, message = %s\n", file, line, op, err_name, err_message);
return false;
}
return true;
}
int main(){
// 检查cuda driver的初始化
checkDriver(cuInit(0));
// 创建上下文
CUcontext context = nullptr;
CUdevice device = 0;
checkDriver(cuCtxCreate(&context, CU_CTX_SCHED_AUTO, device));
printf("context = %p\n", context);
// 输入device prt向设备要一个100 byte的线性内存,并返回地址
CUdeviceptr device_memory_pointer = 0;
checkDriver(cuMemAlloc(&device_memory_pointer, 100)); // 注意这是指向device的pointer,
printf("device_memory_pointer = %p\n", device_memory_pointer);
// 输入二级指针向host要一个100 byte的锁页内存,专供设备访问。参考 2.cuMemAllocHost.jpg 讲解视频:https://v.douyin.com/NrYL5KB/
float* host_page_locked_memory = nullptr;
checkDriver(cuMemAllocHost((void**)&host_page_locked_memory, 100));
printf("host_page_locked_memory = %p\n", host_page_locked_memory);
// 向page-locked memory 里放数据(仍在CPU上),可以让GPU可快速读取
host_page_locked_memory[0] = 123;
printf("host_page_locked_memory[0] = %f\n", host_page_locked_memory[0]);
/*
记住这一点
host page locked memory 声明的时候为float*型,可以直接转换为device ptr,这才可以送给cuda核函数(利用DMA(Direct Memory Access)技术)
初始化内存的值: cuMemsetD32 ( CUdeviceptr dstDevice, unsigned int ui, size_t N )
初始化值必须是无符号整型,因此需要将new_value进行数据转换:
但不能直接写为:(int)value,必须写为*(int*)&new_value, 我们来分解一下这条语句的作用:
1. &new_value获取float new_value的地址
(int*)将地址从float * 转换为int*以避免64位架构上的精度损失
*(int*)取消引用地址,最后获取引用的int值
*/
float new_value = 555;
checkDriver(cuMemsetD32((CUdeviceptr)host_page_locked_memory, *(int*)&new_value, 1)); //??? cuMemset用来干嘛?
printf("host_page_locked_memory[0] = %f\n", host_page_locked_memory[0]);
// 释放内存
checkDriver(cuMemFreeHost(host_page_locked_memory));
return 0;
}参考文献:https://www.cnblogs.com/marsggbo/p/11838823.html

















 179
179

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









