






Ansys Lumerical FDTD是一款光子仿真软件,其在统一设计环境中集成了FDTD、RCWA和STACK求解器。这有助于对衍射光栅、多层镀膜、uLED、CMOS图像传感器、超透镜和超表面等各种器件进行精确分析和优化,从而可在不同应用中实现业界领先的性能。对于最复杂的设计,Ansys Lumerical FDTD可实现快速的虚拟原型设计和数千次迭代的验证
ANSYS Lumerical FDTD主要用于求解纳米光子学和电磁波传播问题,典型应用包括:
光子器件(光波导、耦合器、光调制器)
微纳光学结构(金属纳米粒子、等离子体结构)
量子光学(单光子源、量子点)
显示技术(微透镜阵列、纳米结构调控光学性能)
半导体光电器件(LED、激光器、太阳能电池)
ANSYS Lumerical FDTD算法的计算效率高度依赖硬件配置。以下是针对FDTD的详细硬件优化指南:
一、 CPU vs GPU计算
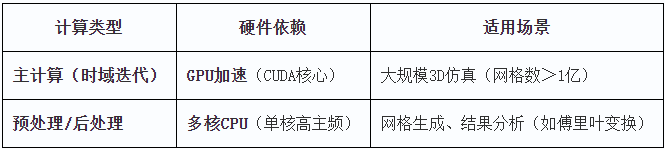
Lumerical FDTD 支持 CPU 和 GPU 两种计算方式,其中:
CPU 计算适用于大规模问题,高精度仿真,受限于核心数和内存带宽。
GPU 计算适用于加速计算,但受限于显存容量,适合中等规模问题。
GPU 计算通常适用于结构较为规则、网格划分均匀的问题,如果仿真模型网格不均匀或者包含大量复杂介质材料,CPU计算可能更优。
目前 NVIDIA CUDA计算卡可用于Lumerical FDTD计算,但建议使用高端计算卡(如 A100、H100、RTX 4090)以获得最佳性能。
- 计算模式
- GPU加速支持
推荐显卡:
NVIDIA Tesla A100/H100(显存≥40GB,支持FP64双精度)
NVIDIA RTX 6000 Ada/RTX 4090(48GB显存,性价比高)
关键特性:
需启用GPU Acceleration选项(在FDTD求解器设置中勾选)
显存容量直接限制可仿真网格规模(每百万网格约需0.5-1GB显存)
- CPU备用方案
若无GPU,FDTD可退化为纯CPU计算,但速度显著下降(约5-10倍)。
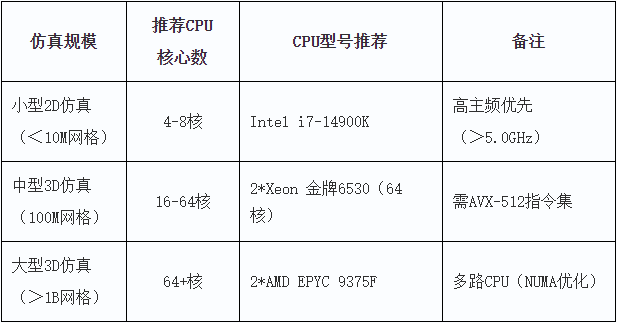
二、核心数与性能优化
- CPU配置
o 适用于高端工作站/服务器CPU,如 AMD EPYC 96核或Intel Xeon 56核。
o 推荐至少16~64 核(物理核心),超线程提升有限。
o 计算速度随核心数增加呈现亚线性加速,64核以上加速效果会逐渐下降(主要受内存带宽和I/O影响)。
- GPU配置
单卡性能极限:
单张高端 GPU(A100/H100/4090)可以加速,H100 80GB可处理约2亿网格(FP32精度),但大规模计算仍依赖 CPU
多卡并行:
通过NVIDIA NVLink互联(如4×H100,显存池化至320GB)
需在Lumerical中启用Multi-GPU Support
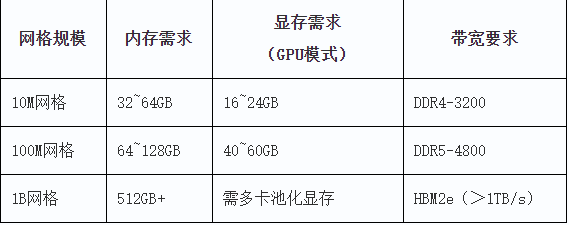
三、内存与存储需求
- 内存容量
Lumerical FDTD 对内存需求较高,取决于:
计算规模(网格点数):
小规模仿真(百万网格以下):16GB 内存足够
中等规模(几千万网格):推荐 64GB-128GB
大规模仿真(上亿网格):需要 256GB-1TB
内存带宽:
DDR5 / HBM2 服务器内存效果更佳,带宽瓶颈影响并行计算性能。
GPU 显存(如果使用 GPU 计算):
至少 48GB(如 RTX 4090、RTX A6000/6000 ada)
推荐 40GB+(如 A100、H100)
高精度大规模计算建议 80GB(如 A100 80GB)
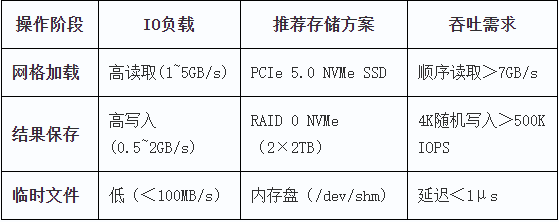
存储IO
对硬盘I/O读写要求
存储速度:
推荐PCIe 4.0或PCIe 5.0 NVMe SSD,读写速度至少5000MB/s 以上。
大规模仿真建议NVMe SSD闪存阵列 以加速数据存取。
传统HDD(机械硬盘)不适合FDTD仿真存储。
存储容量:
小规模仿真:2TB SSD足够。
大规模仿真:建议4TB+SSD,甚至搭配10TB机械盘存档数据。
并行存储优化:
支持 Lustre 分布式存储,适用于集群计算。
局部 NVMe + 网络存储(如 NFS、Ceph)搭配,提高大规模任务的存取速度。
四、硬件配置示例
- 高性能工作站(单节点)
CPU: 2*Xeon 金牌6530 (64核/128线程)
GPU: 2× NVIDIA RTX 4090 48GB
图卡:RTX A400 4GB
内存: 512GB DDR5-4800 RDIMM
存储:
-
主盘: 4TB NVME (PCIe 5.0)
-
副盘: 8TB SATA企业级 (备份)
平台: 双塔式(2200W)
显示器:27寸2K
售价 ¥157,000元
2.服务器(大规模计算)
CPU: 双路 AMD EPYC 9575F(128核)
内存: 768GB DDR5 RDIMM
GPU: 4x NVIDIA A100 80GB
存储: 2TB NVME+8TB NVMe + 20TB HDD
平台: 双塔式(2600w)
显示器:27寸4K
售价 ¥815000元
- 集群节点(分布式计算)
-
计算节点(数量 4个,每节点配置: 2× Xeon 金牌6530 (64核)/2× NVIDIA A100 80GB/1TB DDR5-4800 ECC/100G IB)
-
存储: Lustre并行文件系统(24核/192GB DDR4/45TB闪存阵列+1260TB并行存储/100G IB)
-
网络 36口100G高速网络(nfiniband)
-
42机柜、切换器
-
集群作业调度系统
售价 ¥2,025,590元
五、软件优化技巧
网格划分
使用Non-uniform Mesh减少总网格数
在关键区域(如光源附近)局部加密网格
GPU参数调优

结果保存优化
仅保存必要时间步的场数据(如frequency-domain field)
使用HDF5压缩格式:

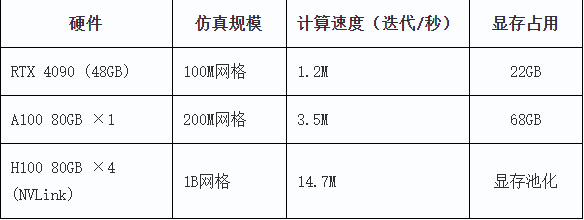
六、性能基准参考
七、常见问题解决
显存不足:降低网格分辨率或启用Subgridding技术。
CPU利用率低:检查是否启用Hyper-Threading(建议关闭)。
IO瓶颈:将临时目录指向RAM磁盘:
Bash
export TMPDIR=/dev/shm
如需处理超大规模仿真(如光子集成电路全芯片分析),建议分布式FDTD(D-FDTD)解决方案。
我们专注于行业计算应用,并拥有10年以上丰富经验,
通过分析软件计算特点,给出专业匹配的工作站硬件配置方案,
系统优化+低延迟响应+加速技术(超频技术、虚拟并行计算、超频集群技术、闪存阵列等),
多用户云计算(内网穿透)
保证最短时间完成计算,机器使用率最大化,事半功倍。
上述所有配置,代表最新硬件架构,同时保证是最完美,最快,如有不符,可直接退货
欲咨询机器处理速度如何、技术咨询、索取详细技术方案,提供远程测试,请联系

















 1040
1040

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









