







一、研究背景
1.研究背景
在实际应用中,现实世界中的数据通常是不完整的,且任意视图的缺失是广泛存在的。具体地:
(1)缺失的视图具有高度的不确定性,单一的确定性插补是不合理的。
(2)插补数据本身的质量具有很高的不确定性。
因此,对不完整多视图数据进行分类是不可避免的。
2.拟解决问题
(1)简单忽略缺失视图的方法通常是无效的;
(2)基于深度学习方法估算缺失数据的方法缺乏可解释性,确定性估算方法无法表征缺失的不确定性,导致分类不稳定;
(3)很少有IMVC方法能够处理具有复杂缺失模式的多视图数据;
3.研究动机
为了探索和利用不确定性,我们提出了一个不确定性诱导的不完整多视图数据分类(UIMC)模型,在一个稳定可靠的框架下对不完整的多视图数据进行分类。
4.研究思路
UIMC 构造了一个分布并多次采样来表征缺失视图的不确定性,然后根据采样质量自适应地利用它们。因此,所提出的方法实现了更可感知的插补和可控的融合。具体来说,UIMC 对每个缺失的数据进行建模 ,并以可用视图为条件进行分布,从而引入不确定性。然后采用基于证据的融合策略来保证估算观点的可信整合。
5.贡献
(1)提出了一种探索和利用策略,通过表征缺失数据的不确定性来对不完整的多视图数据进行分类,这提高了利用插补数据的有效性和可信度。
(2)提出的UIMC是第一个在不完整多视图分类中断言不确定性的工作。
(3)从两个方面对插补数据进行加权,避免对单视图和多视图融合的负面影响,充分利用了高质量的插补数据,减少了低质量估算视图的影响。
(4)不确定性感知训练和融合极大地确保了整合不确定性估算数据的有效性和可靠性。
(5)实验方面
二、相关工作

三、研究方法
UIMC 旨在探索和利用不完全多视图数据的不确定性,提高模型的有效性和可信度。具体分析如下:
1.Background
给定具有V个视图的N个训练输入\{\mathbb{X}_n\}_{n=1}^N,即\mathbb{X}=\{\mathbf{x}^v\}_{v=1}^V,以及相应的类标签\{\mathbf{y}_n\}_{n=1}^N,多视图分类旨在通过利用互补的多视图数据来构建输入和标签之间的映射。3.1中定义了不完整多视图分类任务。
定义 3.1(不完整多视图分类)形式上,一个完整的多视图样本由 V 个视图组成,即\mathbb{X}=\{\mathbf{x}^v\}_{v=1}^V,X 和相应的类别标签 y。一个不完整的多视图是完整多视图的子集\overline{X}(即,\overline{\mathbb{X}}\subseteq\mathbb{X}),具有任意可能的 V 个视图,其中\begin{aligned}1\leq\overline{V}\leq V\end{aligned} 。给定一个不完整多视图训练数据集\{\overline{\mathbb{X}}_n,\mathbf{y}_n\}_{n=1}^N,其中 N 个样本,不完整多视图分类旨在学习不完整多视图与相应类别标签之间的映射。
不完整多视图分类问题的解决方法:缺失视图进行插补和忽略缺失视图。
具体而言,基于插补的方法根据观察到的数据插补完成缺失视图,但它们大都忽略了不可信插补可能对下游任务造成的影响。相反,忽略缺失视图的方法仅使用可用的视图训练分类模型,通常缺乏对不同视图之间相关性的探索。
UIMC旨在通过探索和利用缺失视图的不确定性来学习一个更可信的模型。
2. Imputing Missing Views
给定一个不完整的多视图数据实例,根据观察到的视图合理地插补其缺失视图,这有可能促进下游的分类模型。
对缺失视图进行不确定性建模。UIMC不采用确定性映射来插补缺失视图,而是利用基于最近邻的非参数化策略构建了一个分布来表征缺失视图的潜在不确定性。
构建最近邻集合。通常地,一个不完整的多视图训练实例\overline{X}及其对应的标签y,其中第m个视图缺失,UIMC基于其他训练样本的信息来估算缺失的视图x^m第m个视图可用。受经典分类算法k-最近邻[的启发,UIMC采用了一种非参数化方法,通过探索\overline{X}的邻居来构造缺失视图x^m的分布。具体来说,对于第v个视图(v̸=m),给定可用观测值x^v∈X,通过以下方式在具有相同标签的其他样本中找到其k个最近邻居来构建邻居集。首先,我们通过计算x^v和x^v_n之间的距离来构造距离集D^v,其中x^v_n是可用于第m个视图的样本的第v个视图的数据,并且y=y_n,则D^v:
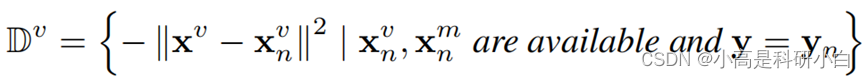
\mathbb{D}^v=\left\{-\left\|\mathbf{x}^v-\mathbf{x}_n^v\right\|^2\mid\mathbf{x}_n^v,\mathbf{x}_n^m\textit{ are available and }\mathbf{y}=\mathbf{y}_n\right\}
然后,最近邻指示符集I^v 为:
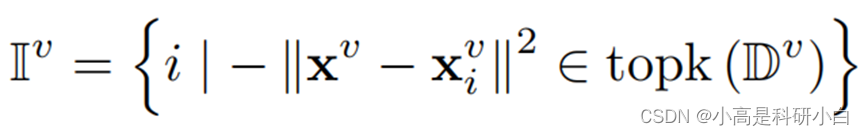
\mathbb{I}^v=\left\{i\mid-\left\|\mathbf{x}^v-\mathbf{x}_i^v\right\|^2\in\mathrm{topk}\left(\mathbb{D}^v\right)\right\}
其中topk(·)是根据距离集D^v从训练集中选择k个最近邻居的算子。请注意,在测试期间,通过从与标签无关的训练集中选择最近的邻居来估算缺失的视图x^m。
使用统计信息进行插补。

那么,通过从多元高斯分布中进行多次抽样,就可以进行插补。插补框架可以参考图1a。
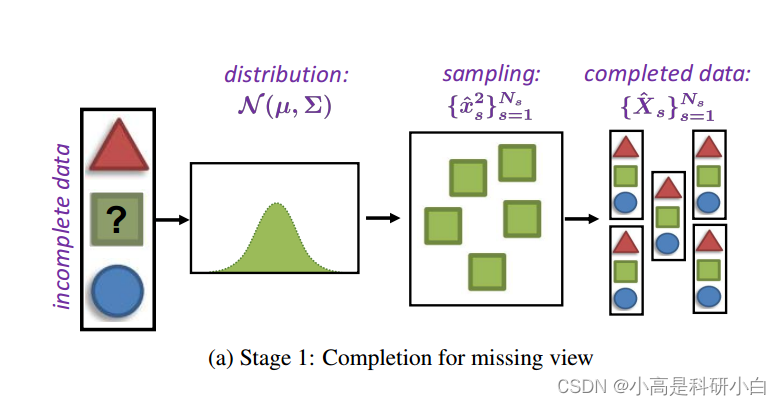
利用非参数最近邻策略基于多元高斯分布 N(μ,∑)表征缺失视图的潜在不确定性。然后,通过从缺失视图的分布中进行 ![]() 次抽样,我们可以获得
次抽样,我们可以获得![]() 个完整实例
个完整实例![]() 。
。
3. Classifying Imputed Multi-View Samples
获得插补的多视图训练数据后,通过利用插补样本的不确定性来减轻由低质量插补引起的负面影响。由于插补中存在固有的噪声,插补的多视图数据通常具有较高的不确定性。因此,
首先基于证据多视图学习框架估计不同视图的不确定性
然后进行基于不确定性的决策融合。总体框架如图1b所示。
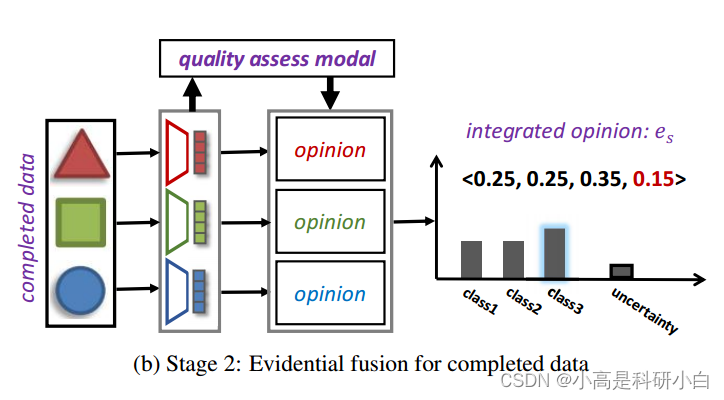
对于每个实例![]() ,为了减轻由低质量插补引起的负面影响,利用证据分类来探索每个视图的不确定性。然后,采用定义3.2中介绍的Dempster's组合规则来整合多个视图的主观意见,使模型能够可靠地利用插补数据。
,为了减轻由低质量插补引起的负面影响,利用证据分类来探索每个视图的不确定性。然后,采用定义3.2中介绍的Dempster's组合规则来整合多个视图的主观意见,使模型能够可靠地利用插补数据。
与传统的分类算法不同,证据分类定义了一个理论框架,以获得主观意见![]()


四、结论
-
提出框架: UIMC是一种新型的不完整多视图分类框架,致力于利用插补引起的不确定性,以提高模型有效性和置信度。
-
关注点: UIMC专注于在考虑插补质量的情况下对缺失视图进行插补。
-
不确定性处理: 由于UIMC从缺失视图的估计分布中进行多次抽样,因此引入了不可避免的不确定性。采用证据分类器表征每个视图的不确定性,并通过Dempster's组合规则融合多个插补的视图的不确定意见。
-
实证验证: 广泛的实验证明了UIMC方法的有效性和稳定性。
-
局限性及未来工作: 插补分布在多视图融合和分类之前已确定,未来工作将侧重于联合学习缺失视图的参数化分布和多视图分类器。另一个有趣的研究方向是通过理论分析展示引入不确定性对于处理缺失视图的必要性。
注意:有些部分直接使用了3.1博客中的内容截图,因为有太多公式,懒得打了,可以结合者来看。















 970
970











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









