






题目:不完整多视图分类的不确定性探索与利用
作者:谢梦瑶,韩宗波,张长青,白一臣,胡庆华,天津大学智能与计算学院
摘要

1.引言


2.相关工作
2.1. Incomplete Multi-View Learning
多视图学习的不完整性通常可以从如何处理缺失视图的角度分为两个主要方向。具体而言,现有的研究主要集中在基于深度学习方法来忽略或补全缺失视图。没有插补的方法。该方法主要使用现有视图,直接学习用于聚类[19–21]和分类[8, 9]的所有视图的共同潜在子空间或表示。生成方法中,一些方法使用现有视图填充缺失视图,然后利用重构的完整数据进行下游任务[10, 11, 22–28]。具体而言,其中一种最流行的方法是在部分多视图数据上应用变分自动编码器的结构来重构缺失视图[10, 11, 22]。生成对抗网络也被用来生成缺失视图[26–28]。此外,还有一些基于核CCA [23]、谱图[24]和信息理论[25]的方法来获得插补。与上述算法相比,我们的方法不仅获得单一插补,而且动态评估插补质量。因此,可以执行更可靠的下游分类任务。
2.2. Uncertainty Estimation
我们方法的关键之一是探索和利用缺失数据中的不确定性。近几年,为了实现高质量的不确定性估计,已经提出了许多方法[29–31]。深度学习中的不确定性通常可以分为Aleatoric(同方差)不确定性和(epistemic)异方差不确定性[32–34]。Aleatoric不确定性是由数据引起的不确定性,它测量数据的固有噪声。Aleatoric不确定性可以进一步分为同方差不确定性和异方差不确定性,而第一个随不同任务变化通常用于估计多任务学习中的不确定性[35, 36],而后者随输入变化在输入空间包含可变噪声时是有用的[37, 38]。另一方面,epistemic不确定性是由于模型训练不足而引起的不确定性,理论上可以消除。通过使用具有不同参数的模型来预测不确定的观察,可以估计epistemic不确定性,预测结果的不稳定性反映了epistemic不确定性[32, 39]。在这项工作中,我们通过采用主观逻辑[40]和Dempster-Shafer理论[41]来估计插补的aleatoric不确定性,从而构建一个值得信赖和可靠的多视图分类网络。
3.方法
本文提出的方法的关键目标是探索和利用不完整多视图数据的不确定性,提升模型的效果和可信度。我们首先在第3.1节介绍不完整多视图分类的背景,然后在第3.2节中展示如何表征插补视图的不确定性,利用插补不确定性并在第3.3节中整合不确定的决策,最后在第3.4节展示如何通过多次插补获得分类预测。
3.1. Background
 多视图分类的目标是通过利用互补的多视图数据构建输入和标签之间的映射。在本文中,我们关注定义3.1中的不完整多视图分类任务。
多视图分类的目标是通过利用互补的多视图数据构建输入和标签之间的映射。在本文中,我们关注定义3.1中的不完整多视图分类任务。
定义 3.1(不完整多视图分类)形式上,一个完整的多视图样本由 V 个视图组成,即,X 和相应的类别标签 y。一个不完整的多视图是完整多视图的子集(即,X⊆\bar{X}),具有任意可能的 V 个视图,其中 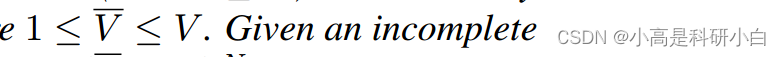 。给定一个不完整多视图训练数据集
。给定一个不完整多视图训练数据集![]() ,其中 N 个样本,不完整多视图分类旨在学习不完整多视图与相应类别标签之间的映射。
,其中 N 个样本,不完整多视图分类旨在学习不完整多视图与相应类别标签之间的映射。
解决不完整多视图分类问题有两个主要方向,包括对缺失视图进行插补和忽略缺失视图。具体而言,基于插补的方法[10–13]根据观察到的数据完成缺失视图,但它们基本上忽略了不可信插补可能对下游任务造成的影响。相反,忽略缺失视图的方法[8,9]仅使用可用的视图训练分类模型,通常缺乏对不同视图之间相关性的探索。所提出的方法旨在通过探索和利用缺失视图的不确定性来学习一个更可信的模型。
3.2. Imputing Missing Views
给定一个不完整的多视图数据实例 ,我们考虑根据观察到的视图合理地插补其缺失视图,这有可能促进下游的分类模型。
对缺失视图进行不确定性建模。大多数现有的不完整多视图分类方法[10–13]采用单一插补来填充缺失视图。形式上,它们通常构建了一个确定性映射,从不完整的多视图数据实例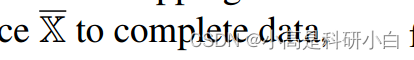 到完整数据,即,
到完整数据,即,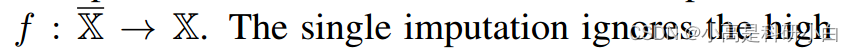 单一插补忽略了插补数据的高不确定性特性,这可能由于不可信的插补而对下游分类任务产生负面影响。这种现象在具有缺失属性的单视图分类任务中也得到了充分认识 [18, 42]。我们不采用确定性映射来插补缺失视图,而是利用基于最近邻的非参数化策略构建了一个分布来表征缺失视图的潜在不确定性。
单一插补忽略了插补数据的高不确定性特性,这可能由于不可信的插补而对下游分类任务产生负面影响。这种现象在具有缺失属性的单视图分类任务中也得到了充分认识 [18, 42]。我们不采用确定性映射来插补缺失视图,而是利用基于最近邻的非参数化策略构建了一个分布来表征缺失视图的潜在不确定性。
构建最近邻集合。通常,我们考虑一个不完整的多视图训练实例和其相应的标签
,其中第 m 个视图缺失,我们的目标是基于其他训练样本的信息来插补缺失的视图
。受经典分类算法 k-nearest neighbors [43] 的启发,我们采用一个非参数化方法来构建缺失视图
的分布,通过探索
的邻居。具体而言,对于第 v 个视图(
),给定可用的观察
,我们通过以下方式在具有相同标签的其他样本中找到其 k 个最近邻来构建一个邻居集。首先,通过计算
与
之间的距离,其中
是用于第 m 个视图的可用样本的第 v 个视图的数据且
,构建距离集合
:
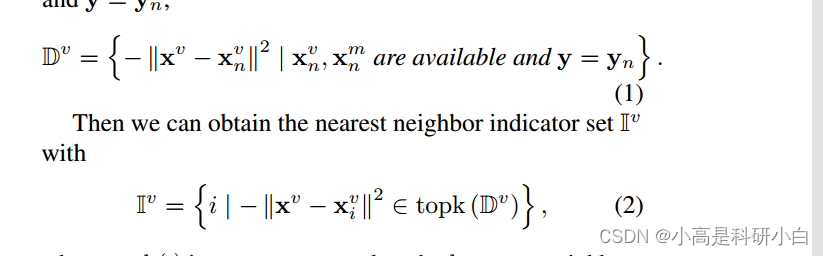
这里的 topk(·) 是一个运算符,根据距离集合Dv 从训练集中选择 k 个最近邻。需要注意的是,在测试时,缺失视图
是通过从与标签无关的训练集中选择最近邻来插补。
使用统计信息进行插补。给定最近邻指示集合,我们通过其邻居集合
统计性地表征缺失视图
的分布。形式上,我们假设缺失视图
符合多元高斯分布
其中
和
是从邻居集合计算得到的均值向量和协方差矩阵。
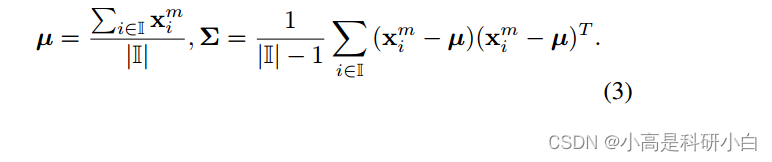
那么,通过从多元高斯分布中进行多次抽样,就可以对
进行插补。更具体地,给定一个不完整的训练实例
,我们可以通过进行次抽样获得
个完整的训练实例
。插补框架可以参考图1a。
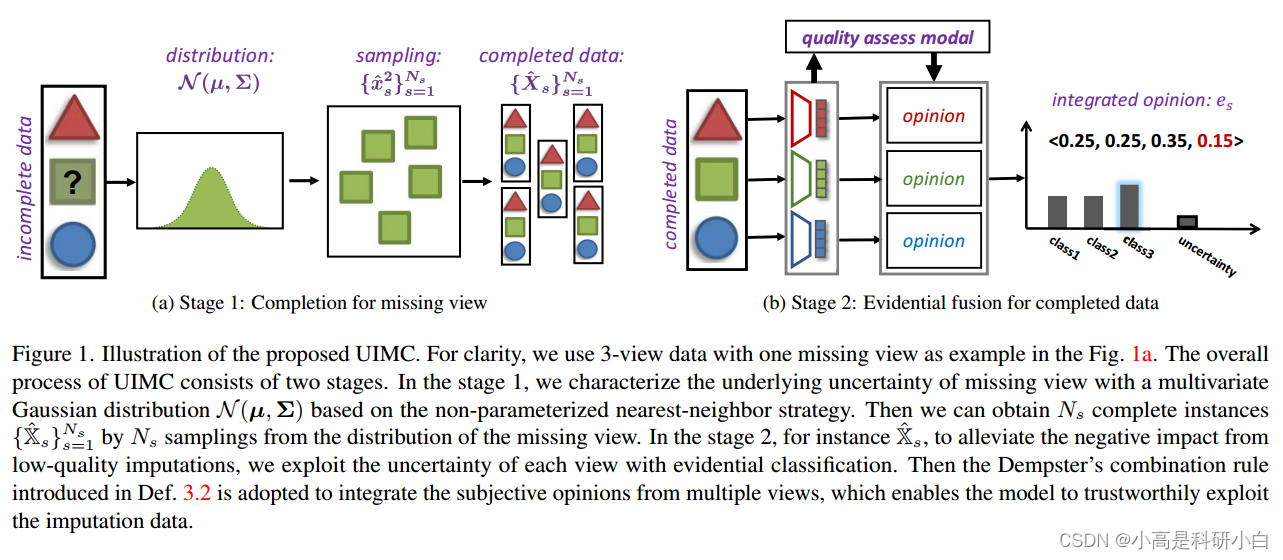
图1. 提出的 UIMC 方法的示意图。为了清晰起见,我们在图1a中以三个视图的数据为例,其中一个视图缺失。UIMC 的整体流程包括两个阶段。
在第一阶段,我们利用非参数最近邻策略基于多元高斯分布 表征缺失视图的潜在不确定性。然后,通过从缺失视图的分布中进行
次抽样,我们可以获得
个完整实例
。
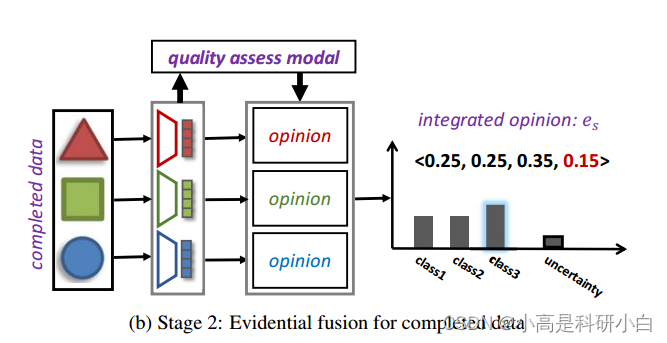
在第二阶段,对于每个实例 ,为了减轻由低质量插补引起的负面影响,我们利用证据分类来探索每个视图的不确定性。然后,采用定义3.2中介绍的Dempster's组合规则来整合多个视图的主观意见,使模型能够可靠地利用插补数据。
3.3. Classifying Imputed Multi-View Samples
在获得插补的多视图训练数据后,我们考虑通过利用插补样本的不确定性来减轻由低质量插补引起的负面影响。由于插补中存在固有的噪声,插补的多视图数据通常具有较高的不确定性。因此,我们首先基于证据多视图学习框架估计不同视图的不确定性,然后进行基于不确定性的决策融合。总体框架如图1b所示。
与传统的分类算法不同, [44,45] 定义了一个理论框架,用于获取主观意见,其中包括主观概率(置信度)
和总体不确定性
,其中
表示类别数量,且
。主观意见与具有参数
的狄利克雷分布相关联。具体而言,信任度
可以轻松地从相应的狄利克雷分布的参数中导出,其中
,其中
是狄利克雷强度。
为了获得每个视图 的狄利克雷分布参数,我们构建了证据神经网络,通过将传统神经网络分类器的 softmax 层替换为激活函数(例如 softplus),以便将正输出视为证据向量
。然后,对于视图
,狄利克雷分布
的参数通过
获得。在变分框架下,证据分类的损失函数
是分类损失
和正则化项
的组合[46]。具体而言,分类目标函数可以被视为传统交叉熵损失在由
决定的单纯形上的积分。具体而言,它被记为:
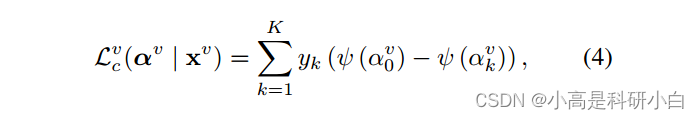
其中 是由一个独热向量表示的标签
的第
个元素,
是二位对数函数。为了获得一个合理的狄利克雷分布,我们使用以下方程为狄利克雷分布添加一个先验作为正则化项:
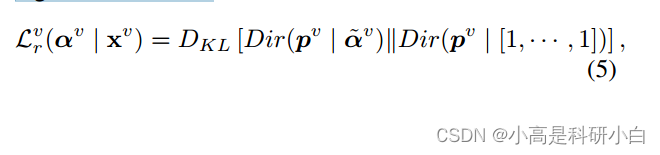
其中,是在将与标签相对应的
替换为1之后的狄利克雷分布。
是均匀狄利克雷分布。然后,对于每个视图,总体损失函数可以写成:
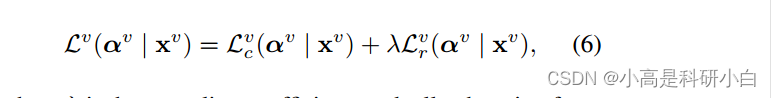
其中, 是缓解系数,在训练过程中从 0 逐渐变化到 1,用于控制约束强度。通过最小化
,我们可以获得狄利克雷分布
。然后,相应的主观意见可以通过
和
推导得到。
现在我们考虑根据不确定性整合来自不同视图的主观意见。Dempster-Shafer理论允许将来自不同来源的主观意见整合,以产生更全面的意见 [47]。具体而言,两个不同视图的Dempster组合规则在定义3.2中定义。相应地,整合后的多视图主观意见可以通过 推导得到。整合后的多视图狄利克雷分布
的相应参数通过
获得。
定义 3.2(Dempster组合规则):经过整合后的主观意见可以从两个主观意见
和
中获得,其中
.具体而言,可以写成:
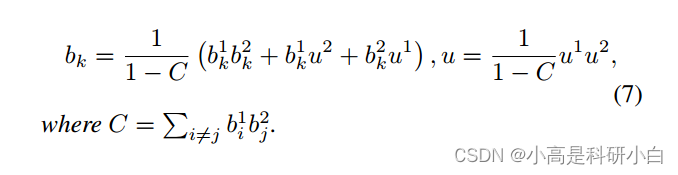
为了获得可靠的单视图和整合后的狄利克雷分布,我们采用了一种多任务策略。具体而言,在分类阶段的最终损失函数由单视图和多视图的组合构成:
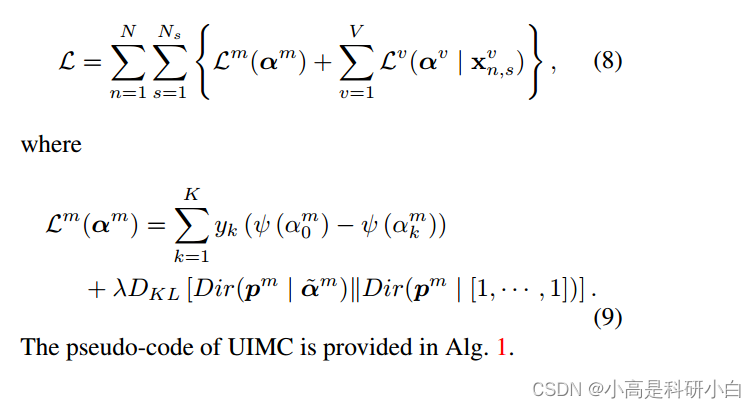
UIMC的伪代码见图1。

3.4. Predicting with Multiple Imputations

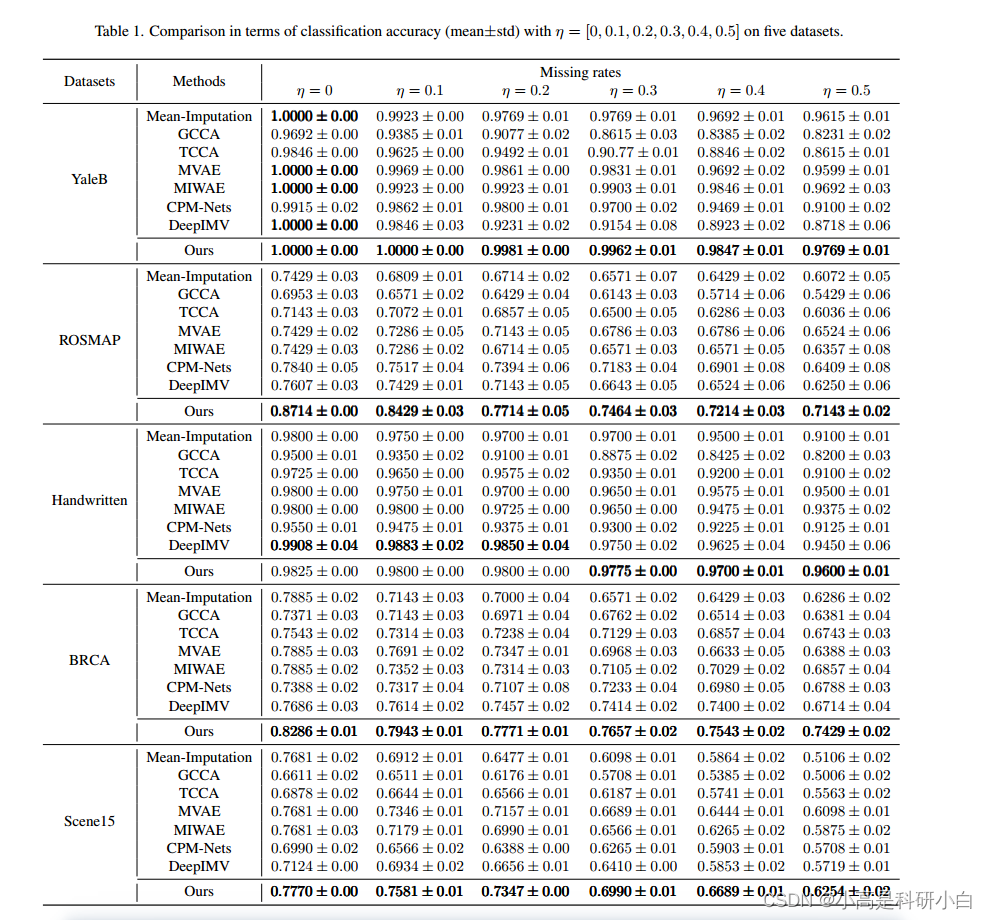
4.实验
5.结论
本文提出了一种新颖的不完整多视图分类框架,称为Uncertainty-induced Incomplete Multi-View Data Classification(UIMC),它可以优雅地探索和利用由插补引起的不确定性,从而产生有效性和置信度。具体而言,UIMC专注于在考虑插补质量的情况下插补缺失视图。由于UIMC从缺失视图的估计分布中进行多次抽样,它不可避免地引入了不确定性。我们采用证据分类器来表征视图特定的不确定性,并进一步利用Dempster's组合规则来融合多个(插补的)视图的不确定意见。我们进行了广泛的实验证明,实证结果坚实地验证了所提出的UIMC的有效性和稳定性。这项工作的局限性在于插补分布在多视图融合和分类之前已经确定。因此,我们未来的工作将重点放在联合学习缺失视图的参数化分布和多视图分类器,以便这两个组件能够相互促进。另一条有趣的研究方向是通过理论分析展示为缺失视图引入不确定性的必要性。















 558
558











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









