






自然语言处理(NLP)主要自然语言理解(NLU)和自然语言生成(NLG)。GLUE(General Language Understanding Evaluation)九项任务涉及到自然语言推断、文本蕴含、情感分析、语义相似等多个任务。BERT、XLNet、RoBERTa、ERINE、T5等知名模型都会在此基准上进行测试。
榜单地址:GLUE Benchmark
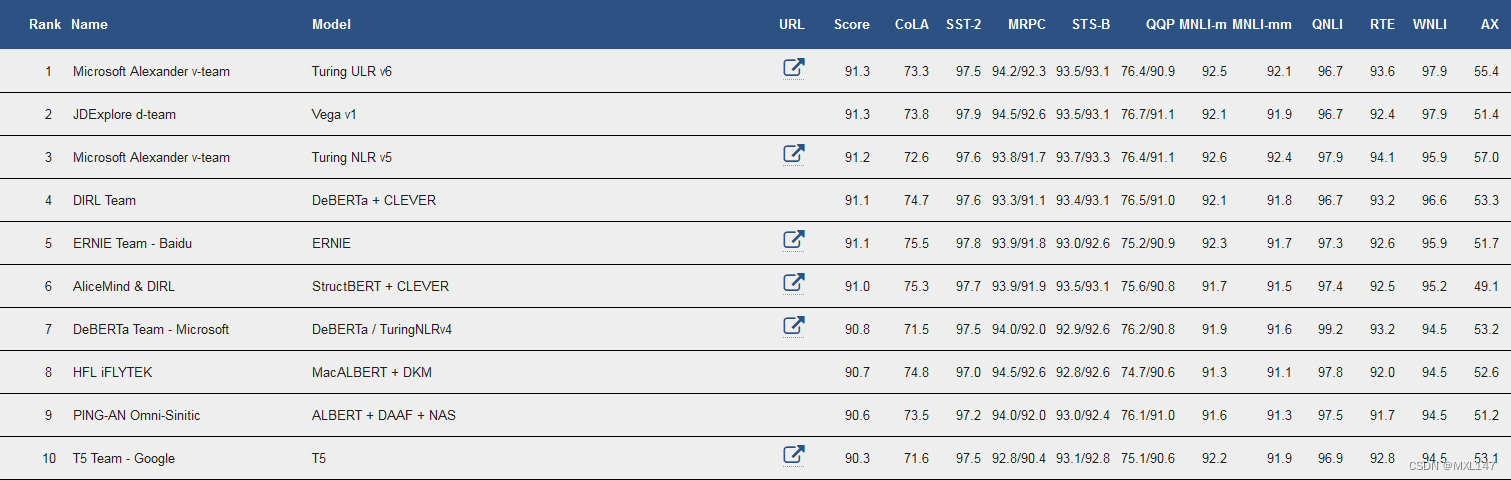
CoLA:句子合乎语法与不合乎语法二分类,0表示不合乎语法,1表示合乎语法。
SST-2:情感分类,正面情感和负面情感二分类
MRPC:语义是否等效二分类
STS-B:句子含义相似性得分[0,5]
QQP:句子对是否等效二分类
MNLI:句子对前提和假设关系三分类:蕴含,矛盾,中立
QNLI:问题与句子是否蕴含二分类
RTE:句子对是否蕴含二分类
WNLI:句子对是否蕴含二分类
1、 CoLA数据集
CoLA(The Corpus of Linguistic Acceptability,语言可接受性语料库),单句子分类任务,语料来自语言理论的书籍和期刊。
样本个数:训练集8, 551个,开发集1, 043个,测试集1, 063个。
任务:句子合乎语法与不合乎语法二分类,0表示不合乎语法,1表示合乎语法
评估指标为: MCC(马修斯相关系数, 在正负样本分布十分不均衡的情况下使用的二分类评估指标)
train.tsv与dev.tsv数据样式相同,共分为4列。 第一列数据, 如gj04, bc01等代表每条文本数据的来源即出版物代号; 第二列数据, 0或1, 代表每条文本数据的语法是否正确, 0代表不正确, 1代表正确; 第三列数据, '', 是作者最初的正负样本标记, 与第二列意义相同, ''表示不正确; 第四列即是被标注的语法使用是否正确的文本句子.

test.tsv中的数据内容共分为2列。第一列数据代表每条文本数据的索引; 第二列数据代表用于测试的句子.
2、 SST-2数据集
SST-2(The Stanford Sentiment Treebank,斯坦福情感树库),单句子分类任务,包含电影评论中的句子和它们情感的人类注释。
样本个数:训练集67, 350个,开发集873个,测试集1, 821个。
任务:情感分类,正面情感(标签为1)和负面情感(标签为0)
评估指标为: accuracy
train.tsv共分为2列, 第一列数据代表具有感情色彩的评论文本; 第二列数据, 0或1, 代表每条文本数据是积极或者消极的评论, 0代表消极, 1代表积极.

test.tsv共分为2列, 第一列数据代表每条文本数据的索引; 第二列数据代表用于测试的句子.

3、 MRPC数据集
MRPC(The Microsoft Research Paraphrase Corpus,微软研究院释义语料库)是从在线新闻源中自动抽取句子对语料库,并人工注释句子对中的句子是否在语义上等效。类别不平衡,68%正样本。
样本个数:训练集3, 668个,开发集408个,测试集1, 725个。
任务:意义是否等效二分类。
评价准则:准确率(accuracy)和F1值。
train.tsv分为5列, 第一列数据, 0或1, 代表每对句子是否具有相同的含义, 0代表含义不相同, 1代表含义相同. 第二列和第三列分别代表每对句子的id, 第四列和第五列是句子.

test.tsv分为5列, 第一列数据代表每条文本数据的索引; 其余列的含义与train.tsv中相同.

4、STS-B数据集
STSB(The Semantic Textual Similarity Benchmark,语义文本相似性基准测试)是从新闻标题、视频标题、图像标题以及自然语言推断数据中提取的句子对的集合,其相似性评分为0-5的浮点数。
样本个数:训练集5, 749个,开发集1, 379个,测试集1, 377个。
任务:回归任务,预测为1-5之间的相似性得分的浮点数。
评价准则:Pearson-Spearman Corr。
train.tsv中的数据内容共分为10列, 第一列数据是数据索引; 第二列代表每对句子的来源, 如main-captions表示来自字幕; 第三列代表来源的具体保存文件名, 第四列代表出现时间(年); 第五列代表原始数据的索引; 第六列和第七列分别代表句子对原始来源; 第八列和第九列代表相似程度不同的句子对; 第十列代表句子对的相似程度由低到高, 值域范围是[0, 5].
test.tsv中的数据内容共分为9列, 含义与train.tsv前9列相同.
5、QQP数据集
QQP(The Quora Question Pairs, Quora问题对数集)是社区问答网站Quora中问题对的集合。任务是确定一对问题在语义上是否等效。与MRPC一样,QQP也是正负样本不均衡的,不同是的QQP负样本占63%,正样本是37%。我们使用标准测试集,为此我们从作者那里获得了专用标签。我们观察到测试集与训练集分布不同。
样本个数:训练集363, 870个,开发集40, 431个,测试集390, 965个。
任务:判定句子对是否等效,等效、不等效两种情况,二分类任务。
评价准则:准确率(accuracy)和F1值。
train.tsv中的数据内容共分为6列, 第一列代表文本数据索引; 第二列和第三列数据分别代表问题1和问题2的id; 第四列和第五列代表需要进行’是否重复’判定的句子对; 第六列代表上述问题是/不是重复性问题的标签, 0代表不重复, 1代表重复.
test.tsv中的数据内容共分为3列, 第一列数据代表每条文本数据的索引; 第二列和第三列数据代表用于测试的问题句子对.
6、MNLI数据集
MNLI(The Multi-Genre Natural Language Inference Corpus, 多类型自然语言推理数据库)是通过众包方式对句子对进行文本蕴含标注的集合。给定前提(premise)语句和假设(hypothesis)语句,任务是预测前提语句是否包含假设(蕴含, entailment),与假设矛盾(矛盾,contradiction)或者两者都不(中立,neutral)。
样本个数:训练集392, 702个,开发集dev-matched 9, 815个,开发集dev-mismatched9, 832个,测试集test-matched 9, 796个,测试集test-dismatched9, 847个。因为MNLI是集合了许多不同领域风格的文本,所以又分为了matched和mismatched两个版本的数据集,matched指的是训练集和测试集的数据来源一致,mismached指的是训练集和测试集来源不一致。
任务:句子对,一个前提,一个是假设。前提和假设的关系有三种情况:蕴含(entailment),矛盾(contradiction),中立(neutral)。句子对三分类问题。
评价准则:matched accuracy/mismatched accuracy。
train.tsv中的数据内容共分为12列, 第一列代表文本数据索引; 第二列和第三列数据分别代表句子对的不同类型id; 第四列代表句子对的来源; 第五列和第六列代表具有句法结构分析的句子对表示; 第七列和第八列代表具有句法结构和词性标注的句子对表示, 第九列和第十列代表原始的句子对, 第十一和第十二列代表不同标准的标注方法产生的标签, 在这里,他们始终相同, 一共有三种类型的标签, neutral代表两个句子既不矛盾也不蕴含, entailment代表两个句子具有蕴含关系, contradiction代表两个句子观点矛盾.
test_matched.tsv中的数据内容共分为10列, 与train.tsv的前10列含义相同.
7、QNLI数据集
QNLI(Qusetion-answering NLI,问答自然语言推断)是从斯坦福问答数据集(SQuAD)转换而来。
样本个数:训练集104, 743个,开发集5, 463个,测试集5, 461个。
任务:判断问题和句子是否蕴含,蕴含和不蕴含,二分类。
评价准则:准确率(accuracy)。
train.tsv中的数据内容共分为4列, 第一列代表文本数据索引; 第二列和第三列数据代表需要进行’是否蕴含’判定的句子对; 第四列数据代表两个句子是否具有蕴含关系, 0/not_entailment代表不是蕴含关系, 1/entailment代表蕴含关系.
test.tsv中的数据内容共分为3列, 第一列数据代表每条文本数据的索引; 第二列和第三列数据代表需要进行’是否蕴含’判定的句子对.
8、RTE数据集
RTE(The Recognizing Textual Entailment datasets,识别文本蕴含数据集),自然语言推断任务,它是将一系列的年度文本蕴含挑战赛的数据集进行整合合并而来。
样本个数:训练集2, 491个,开发集277个,测试集3, 000个。
任务:判断句子对是否蕴含,句子1和句子2是否互为蕴含,二分类任务。
评价准则:准确率(accuracy)。
train.tsv和test.tsv样式与QNLI数据集基本相同。
9、WNLI数据集
WNLI(Winograd NLI,Winograd自然语言推断),自然语言推断任务,数据集来自于竞赛数据的转换。训练集两个类别是均衡的,测试集是不均衡的,65%是不蕴含。
样本个数:训练集635个,开发集71个,测试集146个。
任务:判断句子对是否相关,蕴含和不蕴含,二分类任务。
评价准则:准确率(accuracy)。
train.tsv和test.tsv样式与QNLI数据集基本相同。














 368
368











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









