







音频降噪模型汇总
前言
从事语音降噪增强算法开发多年了,上学期间和入行的前段都是做传统信号处理算法。19年以后基于深度学习的语音降噪模型凭借其优秀的处理效果,一时风头无两,似乎每个人都开始走上了模型降噪的路子。
特别是从2020年微软开始举办的Deep Noise Suppression Challenge – INTERSPEECH 2020(DNS)开始,各个高校、科研院所和相关企业都参与进来施展武艺。后续又举办了Deep Noise Suppression Challenge – ICASSP 2021和Deep Noise Suppression Challenge – INTERSPEECH 2021。
比赛中多数只关注实时/非实时性,赛道约束的比较少,对模型的参数量和计算量要求比较开放,所以基本上参赛的模型都把自己武装得很“强壮”,把已知的有用的技巧融合到自己的模型中,更有一些模型基本是模块的排列组合。所以本人非常希望主办方能够开辟一条小模型赛道,可以迅速应用于现实,提升通话品质。
实际工作中,想要模型落地,考虑的可不止这些,目前端侧对算法开销要求比较苛刻,PC还好一些,像手机、平板这些设备的算法落地需要更加严格的模型选型和剪枝、量化。
模型选型,需要从模型的效果、参数量、计算量、占用内存大小、时延等方面着手开始考虑拆解问题,当然了,如果小模型就可以满足降噪的效果需求,那恭喜你,可以跳过下面的步骤,去训练模型、马上就可以工程化落地了。如果小模型不能work,那就需要根据落地设备的存储空间和开销限制,寻找若干个效果远超降噪效果需求的大模型,然后通过压缩手段(剪枝、量化等)将模型的参数量和计算量降下来,过程中可能出现效果下降的现象,这就是一个经验性尝试的打磨过程了。
本文将近些年的经典网络和最近提出的新网络的关键参数、简介、开源代码都整理在这里,目前只是比较简单的梳理汇总,后续会针对每一个模型详细分析或者转载其他博主的优秀文章。希望对语音降噪算法的学习和应用过程有所帮助,如果不准确的地方,请大家批评指正。
干货分享:手码不易欢迎收藏点赞加关注
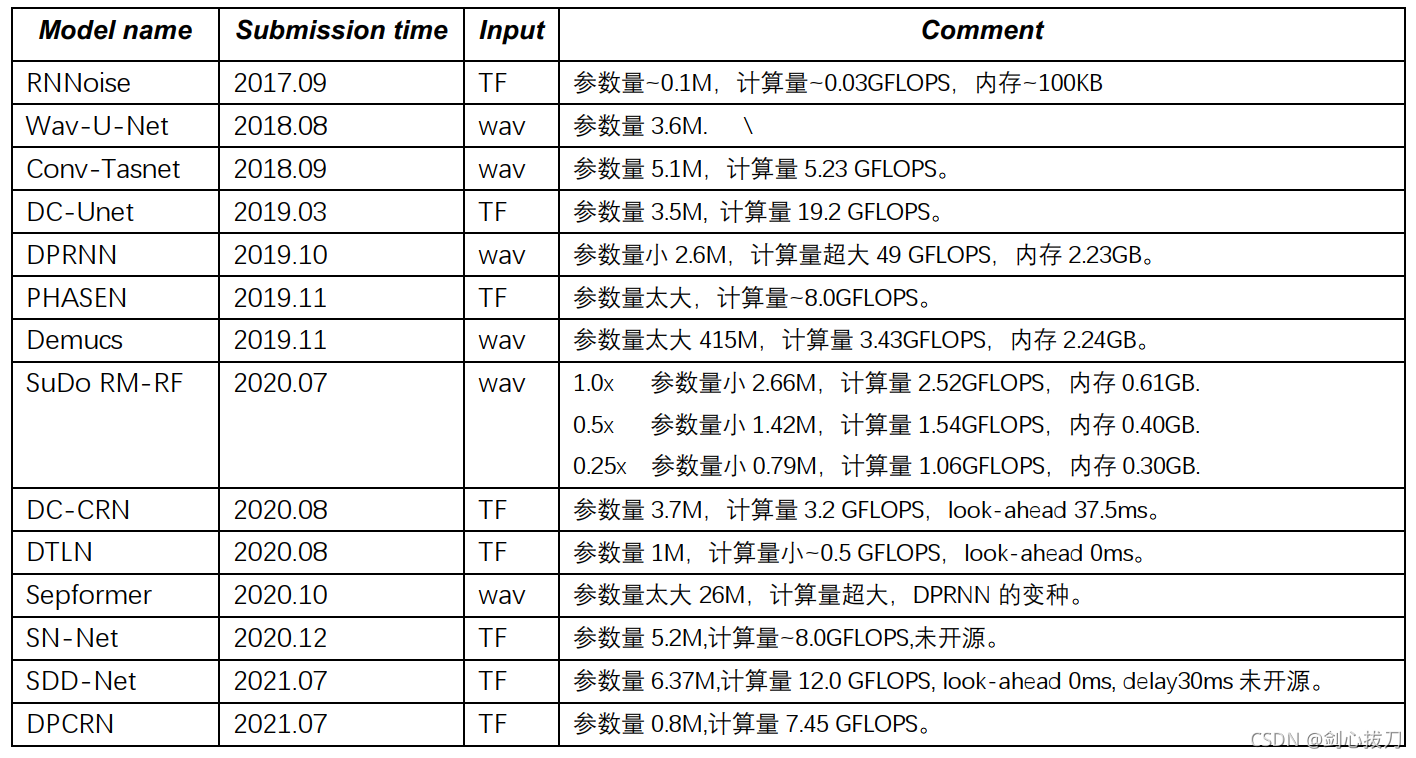
一、模型全景
二、模型简介
RNNoise
Jean-Marc Valin
Mozilla Corporation Mountain View, CA, USA
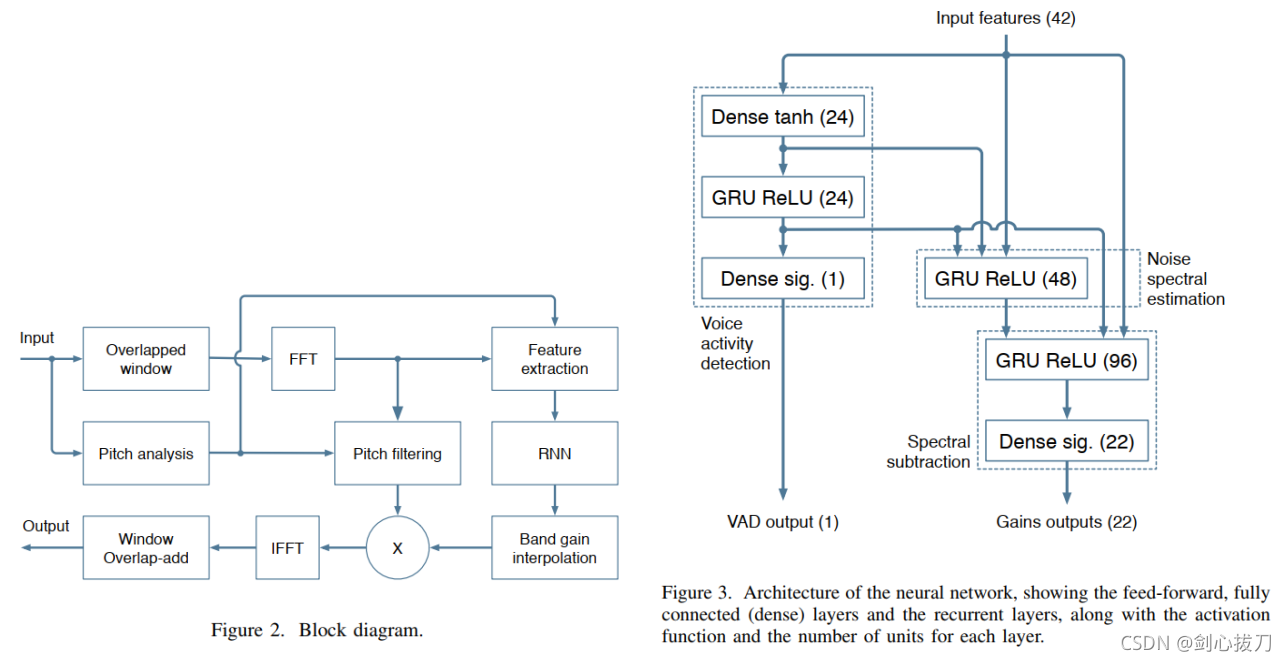
主要思想是将传统信号处理与深度学习相结合来创造一个模型又小速度又快的实时噪声抑制算法。
为了避免大量的输出(避免使用大量神经元),决定不直接使用语音样本或者能量谱。作为代替,考虑一种符合人类听觉感知的频率尺度——巴克频带尺度。总共用了22个频带而不是480(复杂)个频谱值。
1、模型框图
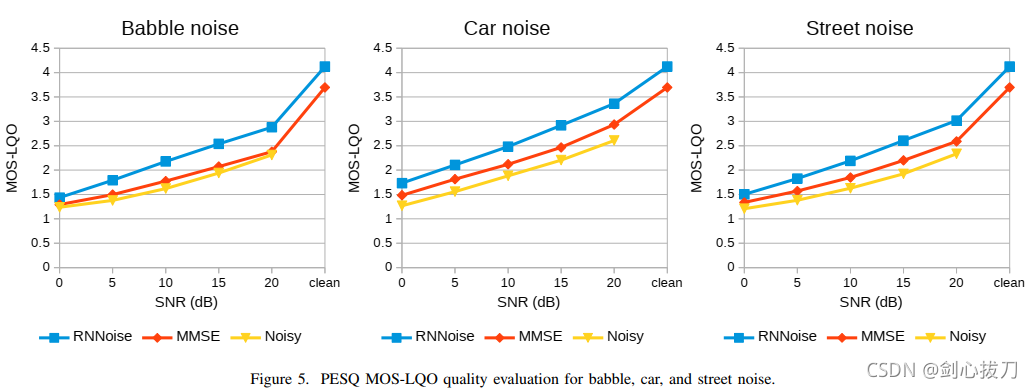
 2、效果
2、效果
3、代码
https://github.com/xiph/rnnoise
4、笔记转载
RNNoise超详细解读
Wav-U-net
Daniel Stoller Sebastian Ewert Simon Dixon
Queen Mary University of London Spotify
1、模型框图
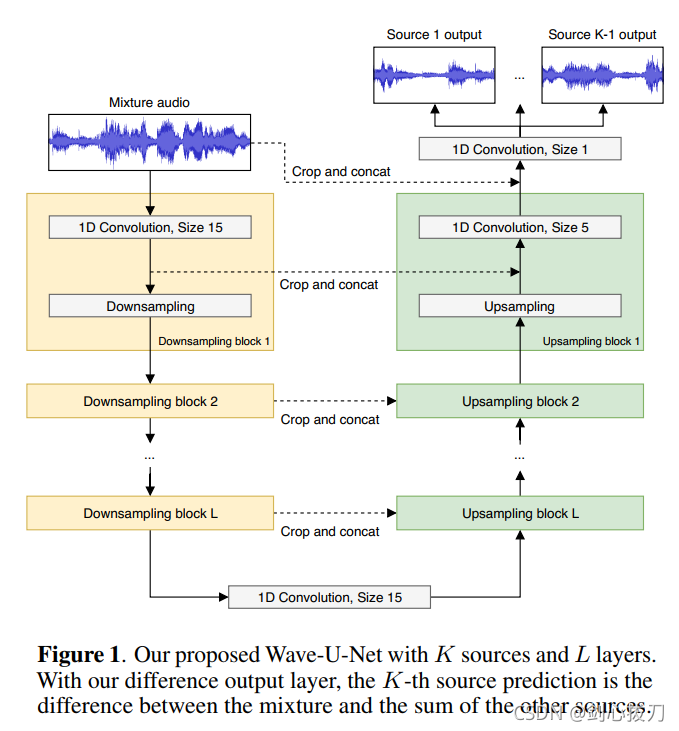
2、效果

3、代码
https://github.com/f90/Wave-U-Net
Conv-TasNet
Yi Luo, Nima Mesgarani
论文提出了一种全卷积时域音频分离网络—Conv-TasNet,这是 Yi Luo 在继 2017 年提出 TasNet 之后,又一端到端的时域语音分离模型。Conv-TasNet通过使用线性编码器生成了一种对语音波形的表示形式,并针对单个说话人的分离进行了优化。然后将一组加权函数(masks)应用于编码器的输出来实现说话人分离。最后使用线性解码器得到分离出的语音波形。使用由一维空洞卷积块组成的时域卷积网络(TCN)计算掩码,这使得网络可以对语音信号的长期依赖性进行建模,同时保持较小的模型尺寸。
1、 模型框图
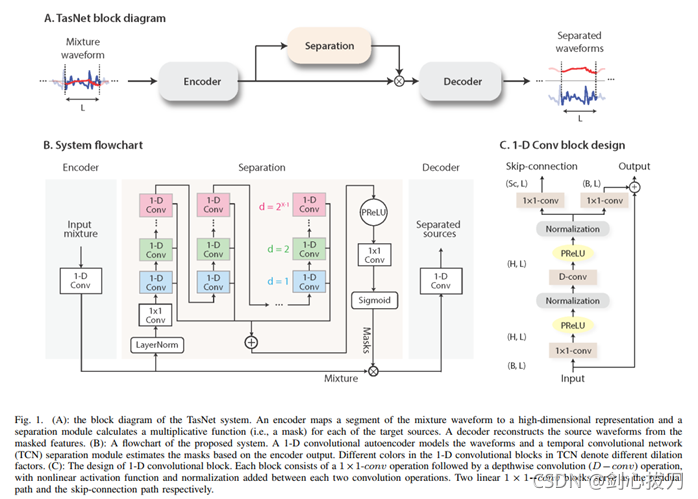
2、 效果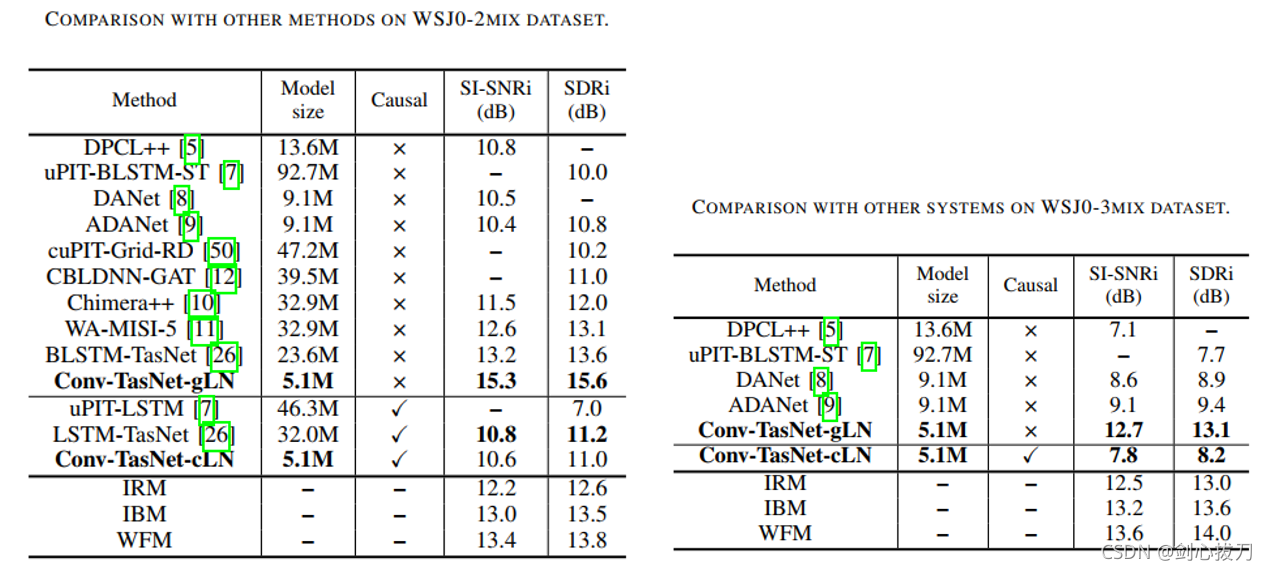 3、代码
3、代码
https://github.com/kaituoxu/Conv-TasNet
4、笔记转载
【论文笔记之Conv-TasNet】: Surpassing Ideal Time–Frequency Magnitude Masking for Speech Separation
DC-U-Net
Hyeong-Seok Choi
Department of Transdisciplinary Studies, Seoul National University, Seoul, Korea
DC-Unet结合了深度复数网络和Unet的优点来处理复数值谱图,利用复数信息在极坐标系下估计语音的幅值和相位。同时提出了weighted-SDR loss。该方法是通过许多卷积来提取上下文信息,从而导致较大的模型和复杂度。
1、 模型框架
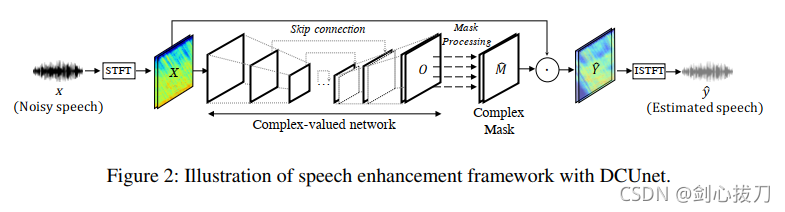
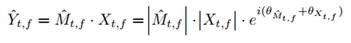
2、weighted-SDR loss

3、效果
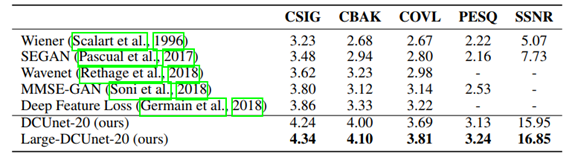
4、代码
https://github.com/chanil1218/DCUnet.pytorch
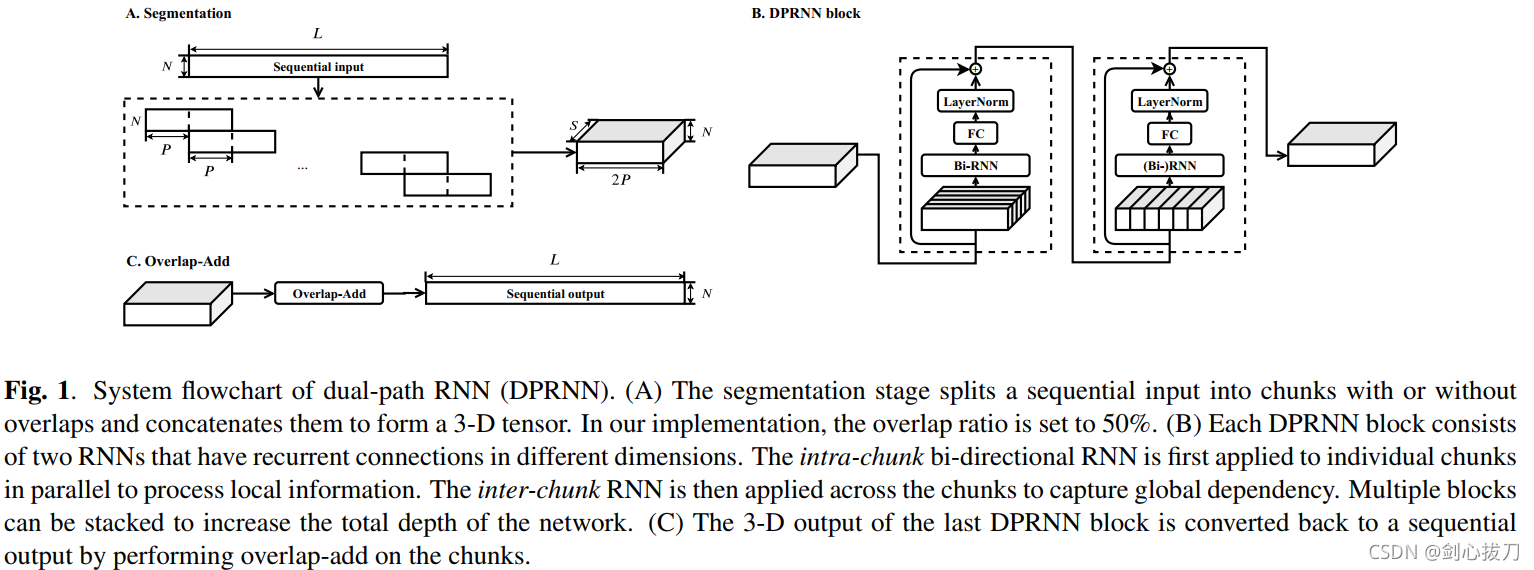
DPRNN
Yi Luo†∗, Zhuo Chen‡, Takuya Yoshioka‡
†Department of Electrical Engineering, Columbia University, NY, USA
‡Microsoft, One Microsoft Way, Redmond, WA, USA
DPRNN将长序列输入分割为较小的块,并迭代地应用块内和块间RNN。
1、模型框架
2、效果
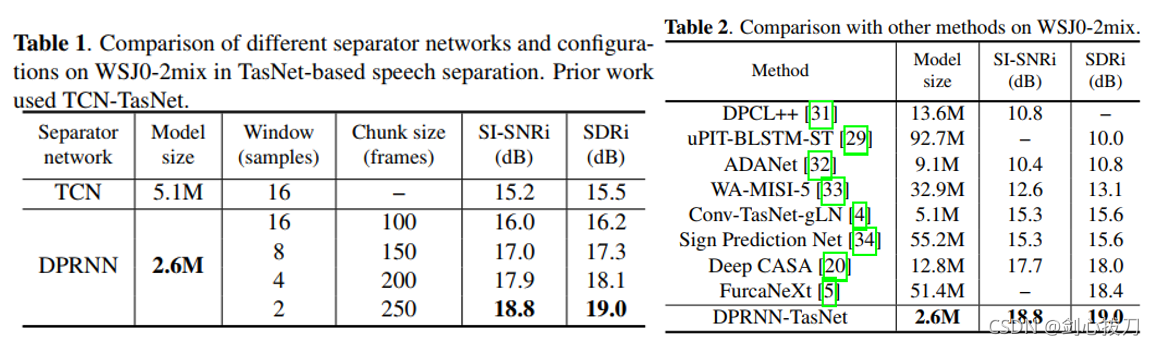
3、代码
https://github.com/ShiZiqiang/dual-path-RNNs-DPRNNs-based-speech-separation
4、笔记转载
论文研究12:DUAL-PATH RNN for audio separation
阅读笔记”Dual-path RNN for Speech Separation“
PHASEN
Dacheng Yin1, Chong Luo2, Zhiwei Xiong1, and Wenjun Zeng2
1University of Science and Technology of China
2Microsoft Research Asia
PHASEN 可以准确估计信号的幅值和相位信息。创新点如下:
- 设计了一套双流网络结构(TSB, two-stream block,幅度流和相位流),并且双流之间有信息交互,交互发生在 TSB 模块结束的部分;
- 设计了频域变换块(FTB,frequency transformation blocks)模块,用于获得频域上的长时间跨度的关系, FTB 分布在 TSB 模块的开始和结束位置, FTB 高效整合全局频域相关性,尤其是谐波相关性, 通过对于 FTB 参数的可视化,发现 FTB 自发地学到了谐波相关性。
1、模型框架
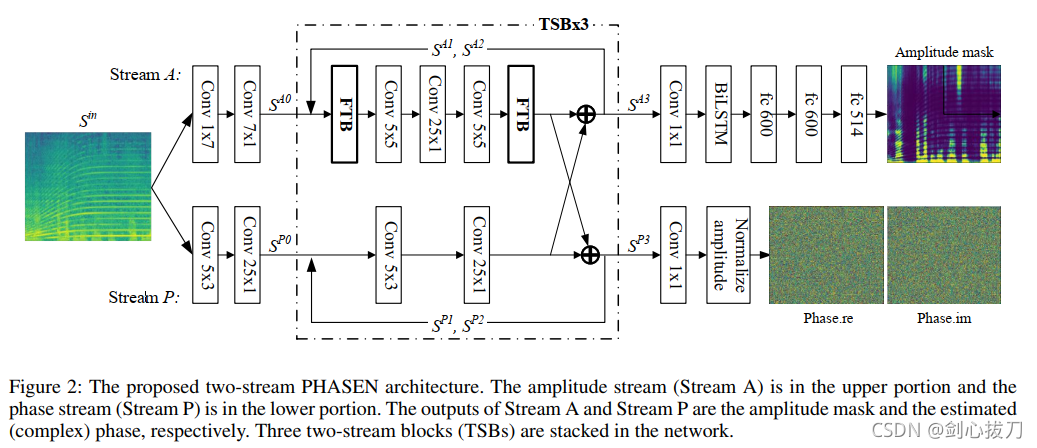
双流结构由强度流以及相位流构成。其中,强度流主要由卷积操作,频域变换模块(FTB)以及双向 LSTM 组成,而相位流为纯卷积网络。强度流的预测结果为幅值掩膜 M,其取值为正的实数,相位流的预测结果是相位谱φ,其取值为复数,由实部和虚部组成。记输入的时频表征为 S_in,则输出 S_out=abs(S_in )∙M∙φ 。其中,∙ 代表逐项相乘操作。为了充分利用双流的信息,采用 gating 的方式在强度流和相位流之间增加了信息交互机制,从而让强度或者相位处理过程中能利用另外一路的信息作为参考。增加了信息交互后,把网络的主体划分为3个 Two Stream Block(TSB)。每一个 TSB 的结构相同,在 TSB 的最后,均有一步信息交互操作。实验表明,双向的信息交互对相位预测至关重要。
在设计强度流的过程中,发现图像处理中常用的小尺寸二维卷积操作无法处理语音信号中的谐波相关性。不同于自然图像,语音信号在转化为时-频表征时的相关性不仅有邻域成分,而且有谐波成分,而这些谐波相关性是一种分布在频域上的全局相关性,例如:频率 f_0 倾向于和 2f_0,1/2 f_0,3f_0,3/2 f_0,1/3 f_0,2/3 f_0… 这些谐波相关的频率同时发生,这些频率分布在整个频率轴上。之前的工作中使用的 U-net,空洞卷积等卷积结构都适用于处理邻域相关性,但是无法高效地感受到这种全局频域相关性。为此,提出了频域变换模块(Frequency Transformation Block, FTB)来处理包括谐波在内的全局频域相关性。
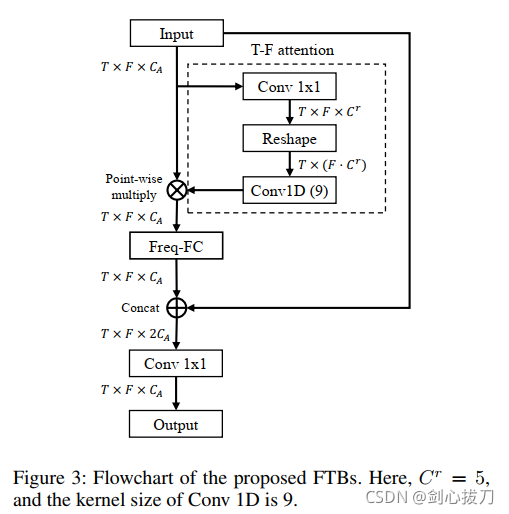
FTB 的结构如上图所示,简单来说,它利用注意力(attention)机制来挖掘非邻域(non-local)相关性。在整体架构中,每一个TSB中强度流的输入和输出端各有一个 FTB,确保每一个 TSB 中处理的信息以及双流交互的信息都能关注到谐波相关性。
2、效果
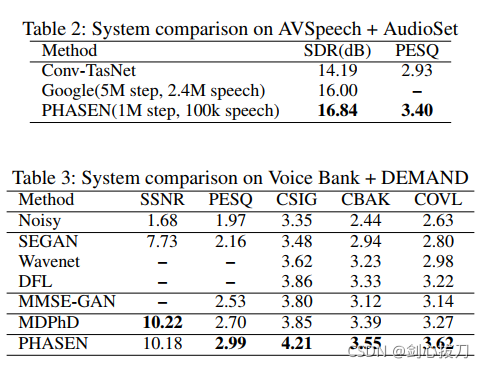
3、代码
https://github.com/huyanxin/phasen
4、笔记转载
AAAI 2020丨从嘈杂视频中提取超清人声,语音增强模型PHASEN已加入微软视频服务
Demucs
Alexandre Défossez Nicolas Usunier Léon Bottou
Facebook AI Research
Demucs是一个waveform-to-waveform 模型,由U-Net 结构和双向 LSTM构成。
1、 模型框架
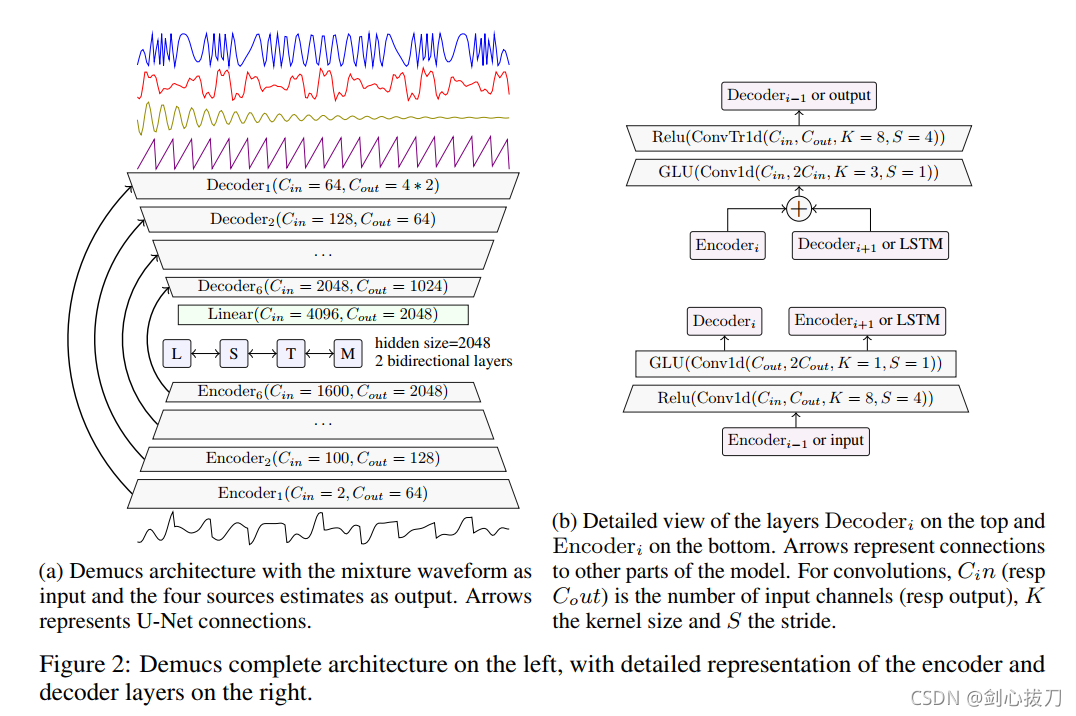
2、效果
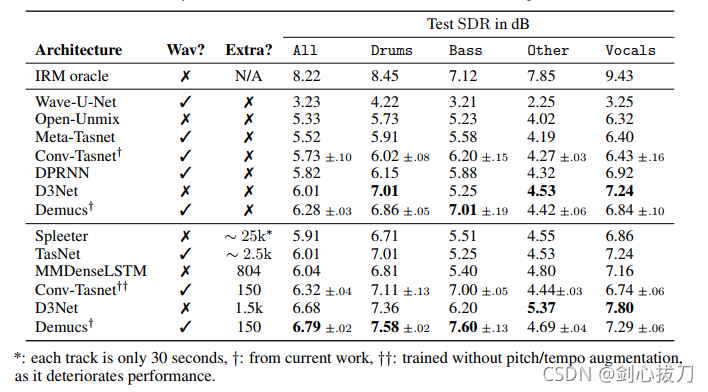
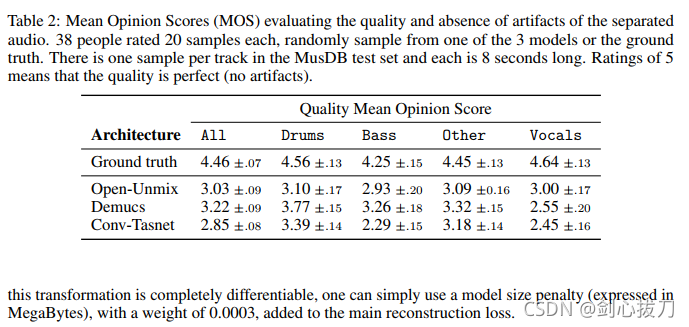
3、代码
https://github.com/facebookresearch/demucs
SuDoRM-RF
Efthymios Tzinis, Zhepei Wang, Paris Smaragdis
University of Illinois at Urbana-Champaign
Adobe Research
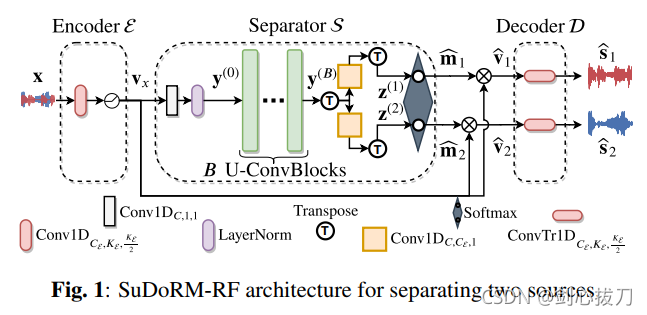
全称:SUccessive DOwnsampling and Resampling of Multi-Resolution Features多分辨率特征的连续下采样和重采样。
该模型,a)可以部署在资源有限的设备上,b)训练速度快,并实现良好的分离性能,c)在增加参数数量时具有良好的扩展性。
适合用于移动设备,能够在有限的浮点运算次数、内存要求和参数数量下获得高质量的音频源分离和较小的时延。
1、 模型框架
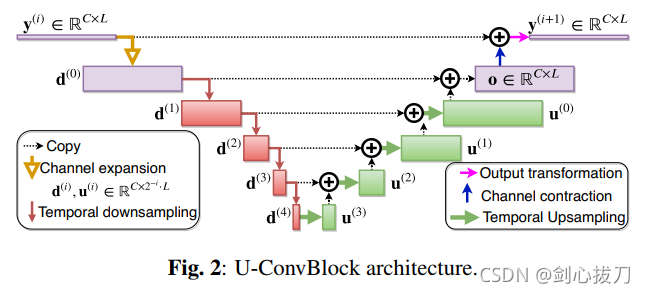
2、效果
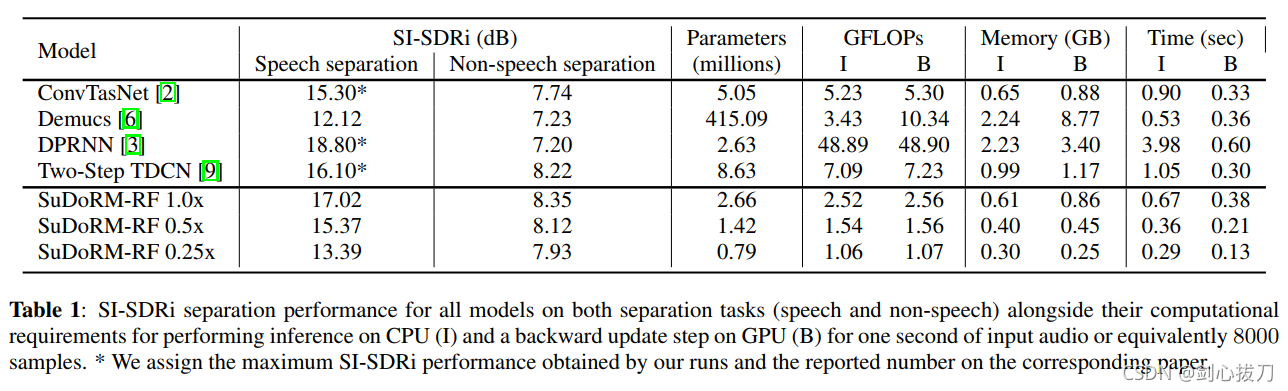
3、代码
https://github.com/etzinis/sudo_rm_rf
DC-CRN
Yanxin Hu1;∗, Yun Liu2;∗, Shubo Lv1, Mengtao Xing1, Shimin Zhang1, Yihui Fu1, Jian Wu1, Bihong Zhang2, Lei Xie1
1Audio, Speech and Language Processing Group (ASLP@NPU), School of Computer Science, Northwestern Polytechnical University, Xi’an, China
2AI Interaction Division, Sogou Inc., Beijing, China
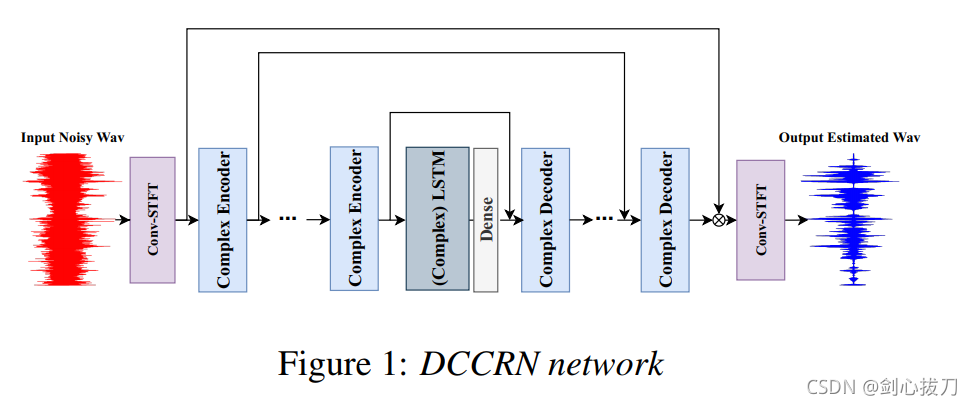
DCCRN组合了DCUNET 和CRN的优势,在相同的模型参数大小情况下,仅用了1/6的DCUNET计算量,就达到了DCUNET的效果。
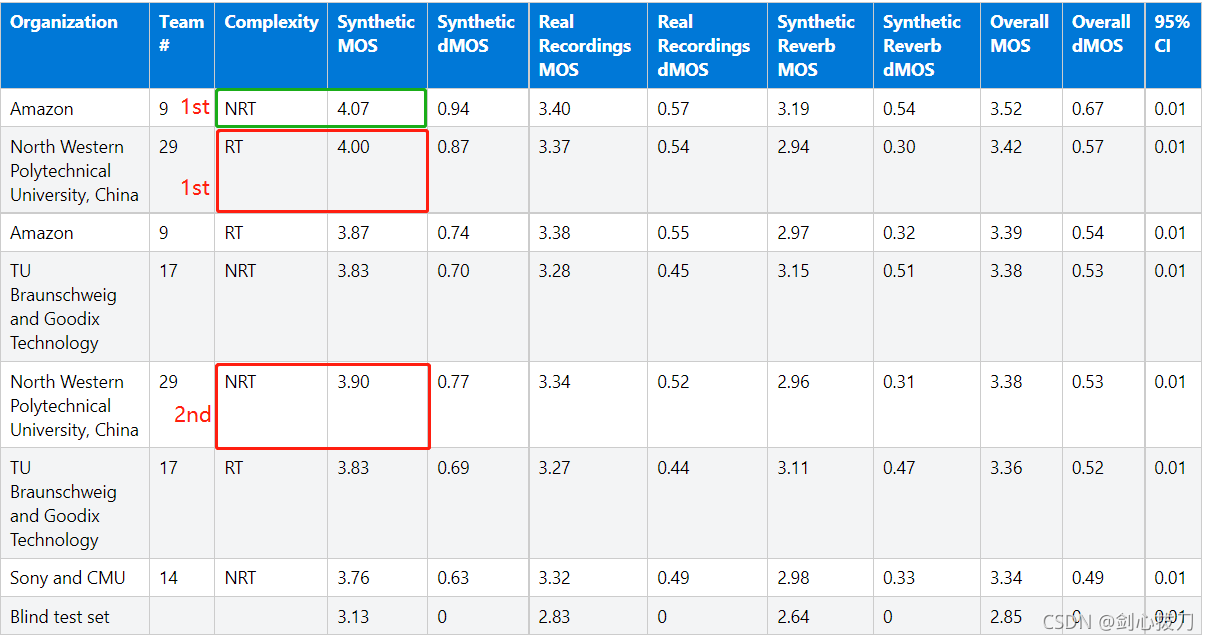
成就:Interspeech 2020 Deep Noise Suppression (DNS),实时赛道第一名,非实时赛道第二名。
非实时赛道的第一名是Amazon的PoCoNet模型,由于是非实时,就不展开介绍了。
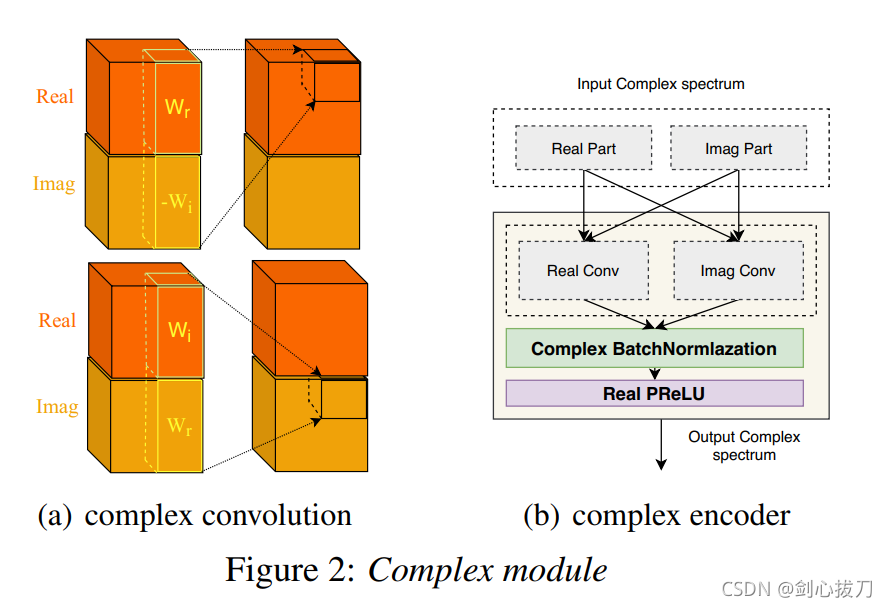
1、 模型框架
2、效果
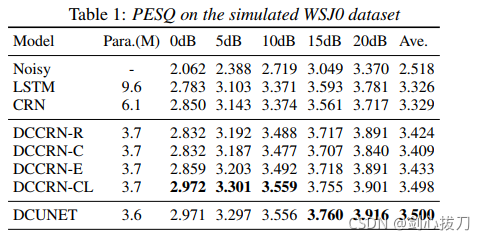
可以看到DCCRN-CL 和DCUNET 参数大小和PESQ指标都很接近,但是DCCRN-CL的计算量是DCUNET的1/6。
3、代码
https://github.com/huyanxin/DeepComplexCRN
https://github.com/maggie0830/DCCRN
4、笔记分享
Deep Complex Convolution Recurrent Network(DCCRN模型)
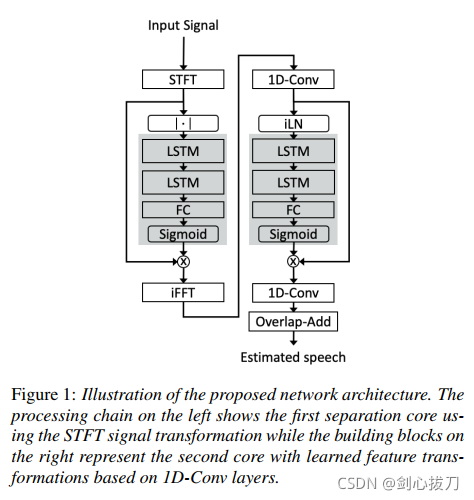
DTLN
Nils L. Westhausen and Bernd T. Meyer
Communication Acoustics & Cluster of Excellence Hearing4all Carl von Ossietzky University, Oldenburg, Germany
1、 模型框架
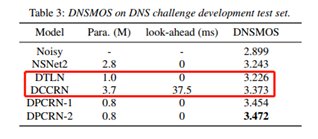
2、效果
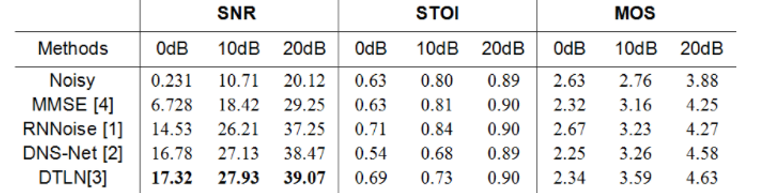
3、代码
https://github.com/breizhn/DTLN
4、笔记转载
阅读笔记—DTLN
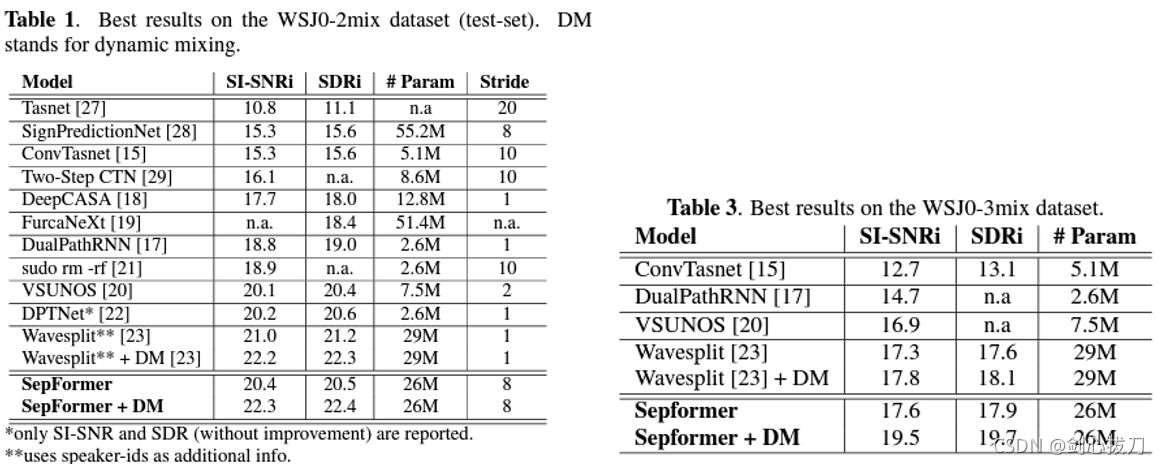
Sepformer
Cem Subakan1, Mirco Ravanelli1, Samuele Cornell2, Mirko Bronzi1, Jianyuan Zhong3
1Mila-Quebec AI Institute, Canada, 2Universit`a Politecnica delle Marche, Italy 3University of Rochester, USA
是DPRNN的一个变种算法,主要由multi-head attention 和 feed-forward layers组成。采用了DPRNN引入的双路径框架,并将RNN替换为a multiscale pipeline composed of transformers,可以学习短期和长期依赖关系。
1、 模型框架

2、效果
3、代码
https://github.com/speechbrain/speechbrain/
SDD-Net
Andong Li1;2, Wenzhe Liu1;2, Xiaoxue Luo1;2, Guochen Yu1;3, Chengshi Zheng1;2, Xiaodong Li1;2
1Key Laboratory of Noise and Vibration Research, Institute of Acoustics, Chinese Academy of
Sciences, Beijing, China
2University of Chinese Academy of Sciences, Beijing, China
3Communication University of China, Beijing, China
Deep Noise Suppression Challenge – INTERSPEECH 2021 第一名
1、 模型框架
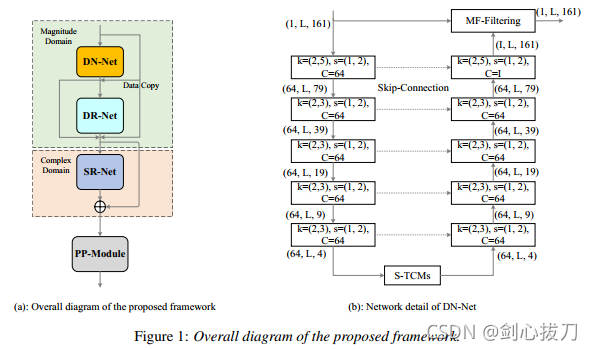
2、效果
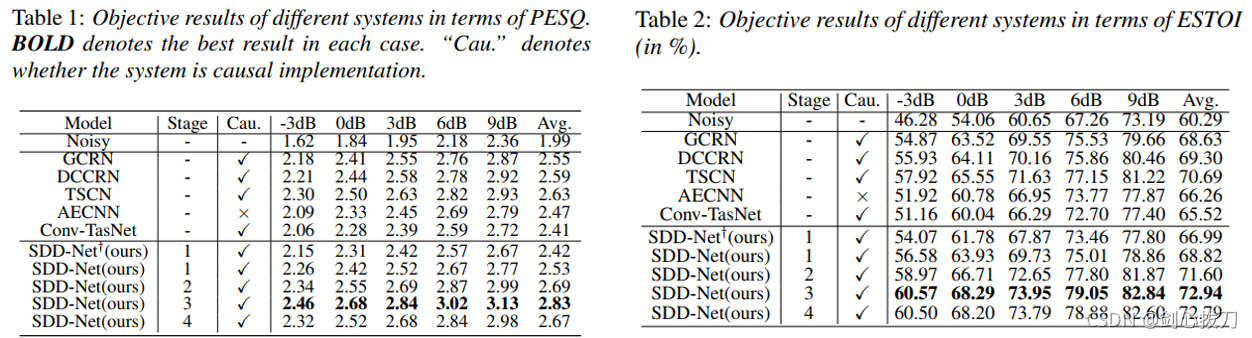
3、未找到开源代码
DPCRN
Xiaohuai Le1;2;3, Hongsheng Chen1;2;3, Kai Chen1;2;3, Jing Lu1;2;3
1Key Laboratory of Modern Acoustics, Nanjing University, Nanjing 210093, China
2NJU-Horizon Intelligent Audio Lab, Horizon Robotics, Beijing 100094, China
3Nanjing Institute of Advanced Artificial Intelligence, Nanjing 210014, China
Deep Noise Suppression Challenge – INTERSPEECH 2021 第四名
1、 模型框架
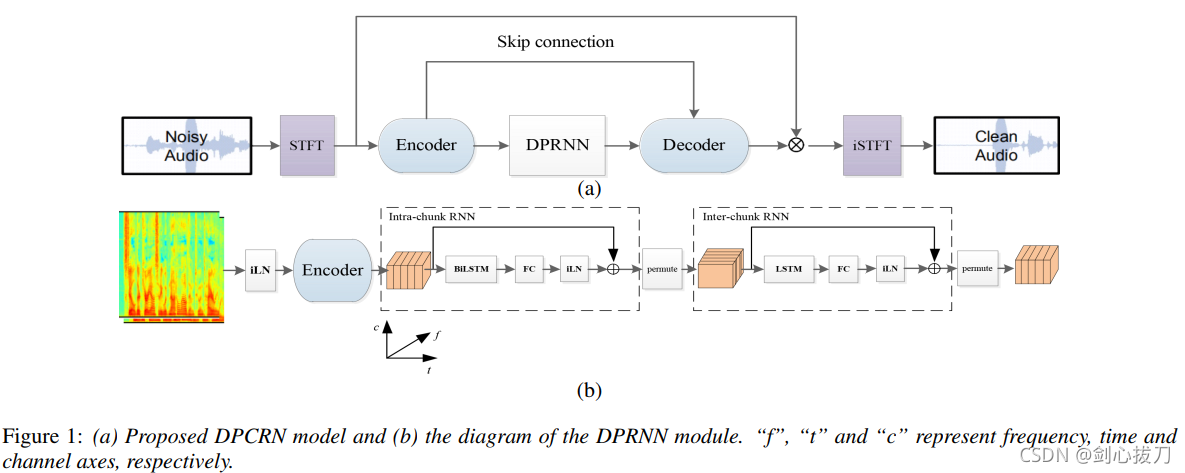
2、效果
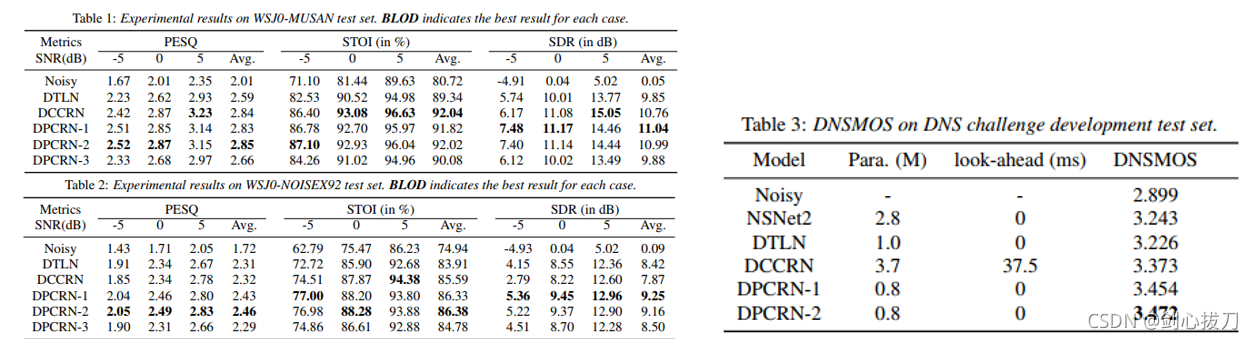
3、代码
https://github.com/Le-Xiaohuai-speech/DPCRN_DNS3
4、笔记转载
DPCRN: Dual-Path Convolution Recurrent Network for Single Channel Speech Enhancement—论文翻译


















 5130
5130

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











