







什么是正则表达式
Regular Expression 使用单个字符串来描述、匹配一系列符合某个句法规则的字符串。简单说就是按照某种规则去匹配符合条件的字符串
REGEXPER
正则表达式工具:http://regexper.com

正则表达式基础
REGEXP对象
JavaScript通过内置对象RegExp支持正则表达式
有两种方法实例化RegExp对象
字面量:
实例:查找is字符
var reg = /\bis\b/; //无修饰符 
var reg = /\bis\b/g; //有修饰符g,代表全文档
构造函数
var reg = new RegExp('\\bis\\b'); //不带修饰符 
var reg = new RegExp('\\bis\\b', 'g'); //带修饰符g
修饰符
g:global全文搜索,不添加,搜索到第一个匹配停止
i:ignore case 忽略大小写,默认大小写敏感
m:multiple lines 多行搜索
元字符
正则表达式有两种基本字符类型组成
-原义文本字符 代表单词本来的含义的,例:abc就代表abc字符串
-元字符 在正则表达式中有特殊含义的非字母字符 有:* + ? $ ^ . | \ ( ) { } [ ]
注:元字符在不同的地方有不同的定义,比如 [ ^a ] 和 ^a 一个代表 a 取反、一个代表以 a 开始
| 字符 | 含义 |
|---|---|
| \t | 水平制表符 |
| \v | 垂直制表符 |
| \n | 换行符 |
| \r | 回车符 |
| \0 | 空字符 |
| \f | 换页符 |
| \cX | 与X对应的控制字符(Ctrl+X) |
字符类
基本字符匹配:一般情况下正则表达式一个字符对应字符串一个字符
例:表达式ab的含义是匹配ab字符
![]()
'abcdefg'.replace(/ab/g, 'x')![]()
字符类匹配:
——使用元字符 [] 来构造一个简单的类
——这个类是指符合某些特性的对象,一个泛指,而不是特指某个字符
——表达式 [abc] 把字符 a 或 b 或 c 归为一类,表达式可以匹配这类的字符
例:[abc]的含义是匹配a或b或c,而不是abc整个字符
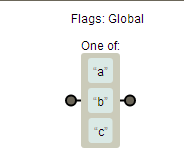
'a1b2c3d4'.replace([abc]/g, 'X')![]()
字符类取反
——使用元字符 ^ 取反
例:[^abc] 的含义是匹配除了a 或 b 或 c 之外的字母

'a1b2c3d4'.replace([^abc]/g, 'X')![]()
范围类
—— [a-z] 连接两个字符表示从 a 到 z 的任意字符
——这个闭区间,也就是包含 a 和 z 本身

'a1b2c3x4z9'.replace(/[a-z]/g, 'Q') ![]()
在[] 组成的类内部是可以连写的
例:[a-zA-Z] 表示从 a 到 z 和 从 A 到 Z 的任意字符

'a1b2c3x4z0AVKDJIOSJ'.replace(/[a-zA-X]/g, 'Q') ![]()
特殊情况,如果需要匹配字符 - 时则有需要其他写法
例:
[0-9] 代表 0 到 9 的任意字符
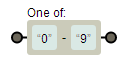
'2016-01-10'.replace(/[0-9]/g, 'A')![]()
[0-9-] 代表 0 到 9 的任意字符和 - 字符

'2018-06-16'.replace(/[0-9-]/g, 'A') ![]()
预定义类
| 字符 | 等价类 | 含义 |
|---|---|---|
| . | [^\r\n] | 除了回车符和换行符之外的所有字符 |
| \d | [0-9] | 数字字符 |
| \D | [^0-9] | 非数字字符 |
| \s | [\t\n\x0B\f\r] | 空白符 |
| \S | [^\t\n\x0B\f\r] | 非空白符 |
| \w | [a-zA-Z_0-9] | 单词字符(字母、数字下划线) |
| \W | [^a-zA-Z_0-9] | 非单词字符 |
实例:
匹配一个 ab + 数字 + 任意字符 的字符串
ab\d.
![]()
边界
| 字符 | 含义 |
|---|---|
| ^ | 以XXX开始 |
| $ | 以XXX结束 |
| \b | 单词边界 |
| \B | 非单词边界 |
例:

量词
匹配多次出现的字符
| 字符 | 含义 |
|---|---|
| ? | 出现零次或一次(最多出现一次) |
| + | 出现一次或多次(至少出现一次) |
| * | 出现零次或多次(任意词) |
| {n} | 出现n次 |
| {n,m} | 出现n到m次 |
| {n,} | 至少出现n次 |
贪婪模式和非贪婪模式
贪婪模式
尽可能多的去匹配
例:\d{3,6} 匹配的是每6个位一组123456而不是每3个为一组123 和 456
'12345678'.replace(/\d{3,6}/g, 'X') ![]()
非贪婪模式
\d{3,6} ?匹配的是每3个为一组123 和 456而不是每6个位一组123456
'12345678'.replace(/\d{3,6}?/g, 'X')![]()
分组
使用()可以达到分组的功能,使量词作用域分组
例:/([a-z]\d){3}/ 字母和数字的组合出现三次

'a1b2c3d4'.replace(/([a-z]\d){3}/g, 'Q') ![]()
或
在分组中使用 | 可以达到或的效果
例:'ByronsperByrCasper'.replace(/Byr(on|Ca)sper/g, 'x')

'ByronsperByrCasper'.replace(/Byr(on|Ca)sper/g, 'x') ![]()
反向引用
在分组使用 $ 捕获分组
例:'2016-11-25'.replace(/(\d{4})-(\d{2})-(\d{2})/g, '$2/$3/$1')

'2016-11-25'.replace(/(\d{4})-(\d{2})-(\d{2})/g, '$2/$3/$1') ![]()
忽略分组
不希望捕获某些分组,只需要在分组内加上?:就可以了
例:'2016-11-25'.replace(/(?:\d{4})-(\d{2})-(\d{2})/g, '$2/$3/$1')

'2016-11-25'.replace(/(?:\d{4})-(\d{2})-(\d{2})/g, '$2/$3/$1')![]()
前瞻
正则表达式从文本头部向尾部开始解析,文本尾部方向,称为“前”
前瞻就是在正则表达式匹配到规则的时候,向前面检查是否符合断言,后顾/后瞻方向相反
注:JavaScript不支持后顾
符合和不符合特定断言称为肯定/正向匹配和否定/负向匹配
| 名称 | 正则 | 含义 |
|---|---|---|
| 正向前瞻 | exp(?=assert) | |
| 负向前瞻 | exp(?!assert) | |
| 正向后顾 | exp(?<=assert) | Javascript不支持 |
| 负向后顾 | exp(?<!assert) | Javascript不支持 |
Js对象属性
g:global全文搜索,不添加,搜索到第一个匹配停止,默认false
i:ignore case 忽略大小写,默认大小写敏感,默认false
m:multiple lines 多行搜索,默认false
l:lastIndex : 是当前表达式匹配内容的最后一个字符的下一个位置
s: source:正则表达式的文本字符串
test方法和exec方法
test方法
用于测试字符串参数中是否存在匹配正则表达式模式的字符串
如果存在则返回true,否则返回false
exec方法
使用正则表达式模式对字符串执行搜索,并将更新全局RegExp对象的属性以反映匹配结果
如果没有匹配的文本则返回null,否则返回一个结果数组:
——index 声明匹配文本的第一个字符的位置
——input 存放被检索的字符串string
非全局调用
调用非全局的RegExp对象的exec()时,返回数组
第一个元素是与正则表达式相匹配的文本















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









