





文章简介
研究原因:使用少量标记样本导致的不确定性。
研究基础:前人使用预训练特征提取器实现在先前解决的任务上获取知识。
研究方法:
1、基于传输的方法;处理特征向量,将其接近高斯分布,提高精度。
2、优化式启发算法:训练期间使用未标记的测试样本进行直推式的小样本学习。
背景问题:
背景:深度学习广泛应用于图像分类和目标检测等视觉任务,但需非常大的且质量较高的数据集进行训练。
面临困难:获取或注释数据的成本高,无法满足数据集要求。
解决前景:小样本学习(使用很少的标记示例进行学习)
目前存在的方法:
a)“归纳式小样本”:在训练期间,仅几个带标签样本可用,并且独立地对每个输入的测试进行预测。
b)“直推式小样本学习”:对一批(未标记的)测试输入进行预测,允许考虑其联合分布。
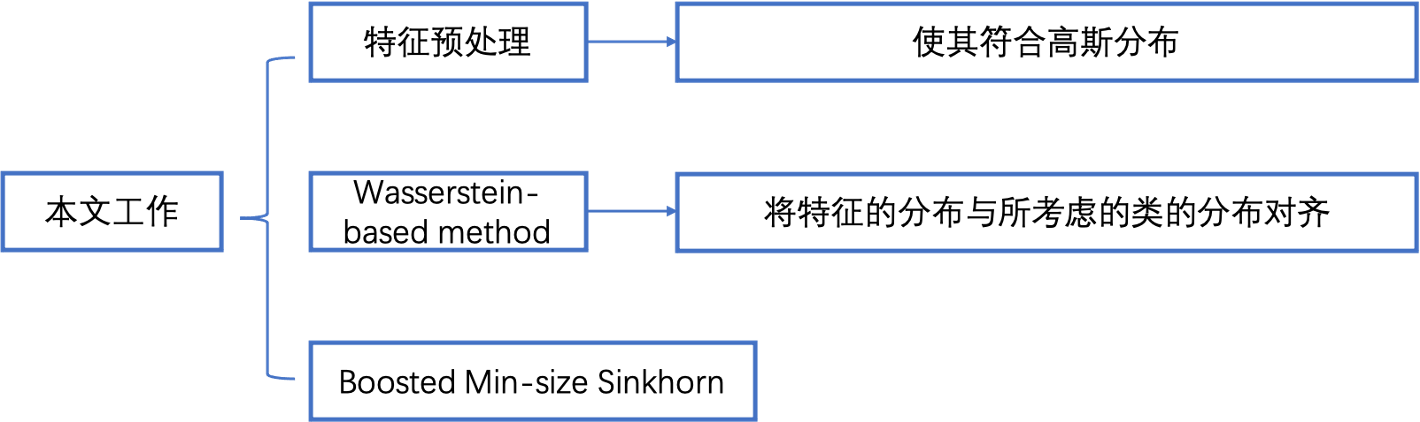
本文方法:
1、特征预处理方法:可以在小样本传输设置中提高准确性。
2、直推式学习中,提出一种基于传输的优化算法,获得更好的性能。
本文模型结构:
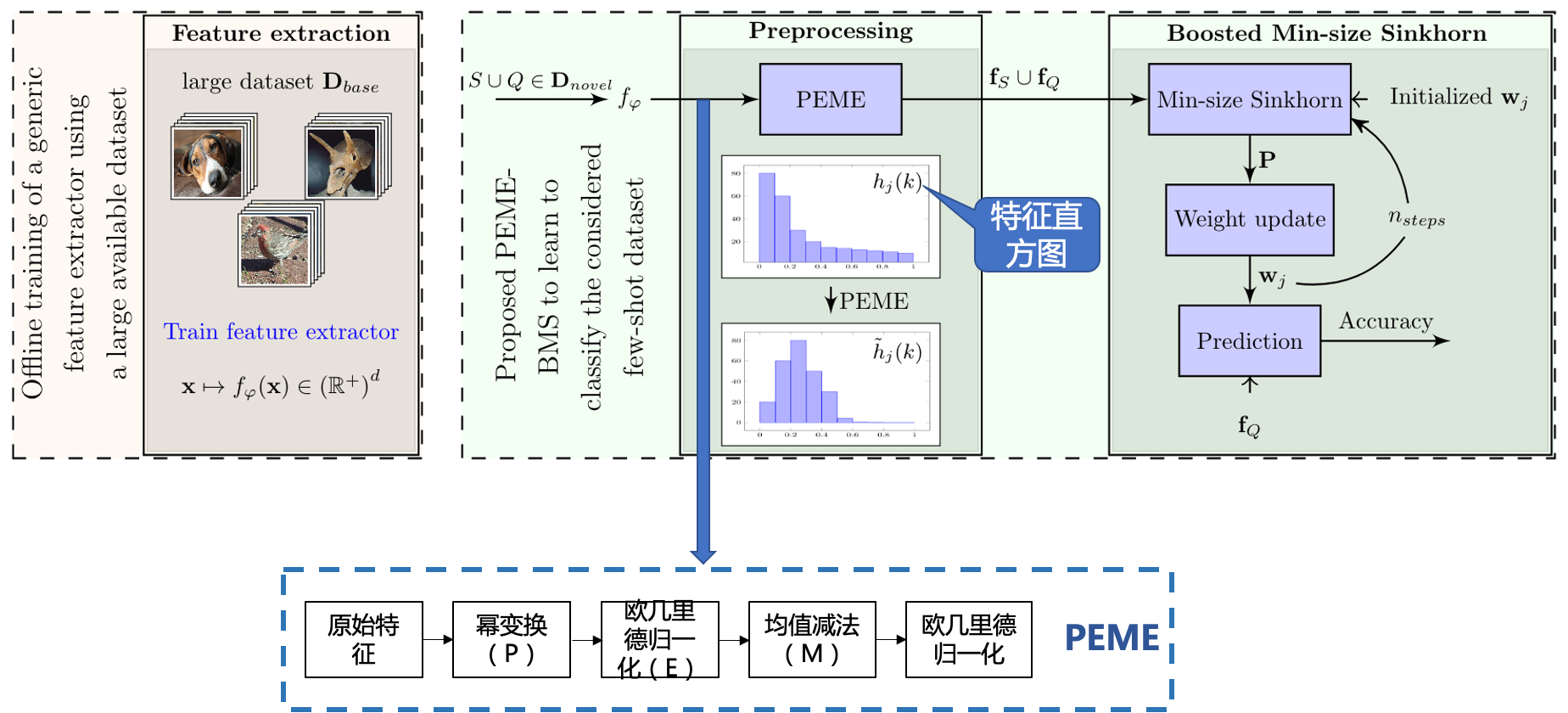
通过骨干网络提取特征,采用PEME进行特征预处理,再进行直推式学习预测。
小样本学习现状:
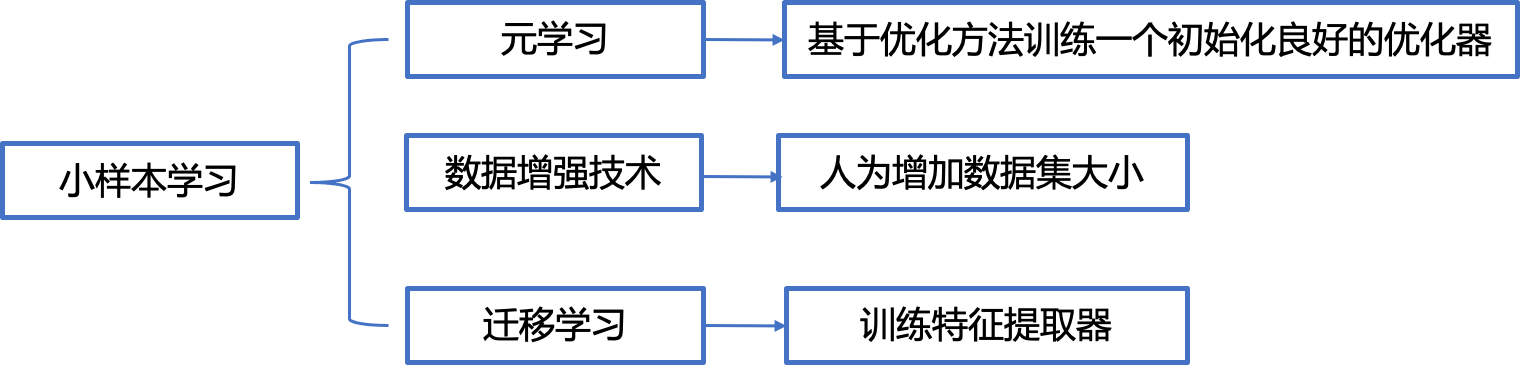
本文工作流程图:
归纳式和直推式学习介绍
Inductive learning:从训练集中归纳出一定的规则(模型),把该规则应用到测试数据上得到结果。
Transductive learning:直接从训练数据和测试数据中直推出测试的结果,允许测试样本参与模型的构建。

实验方法定义
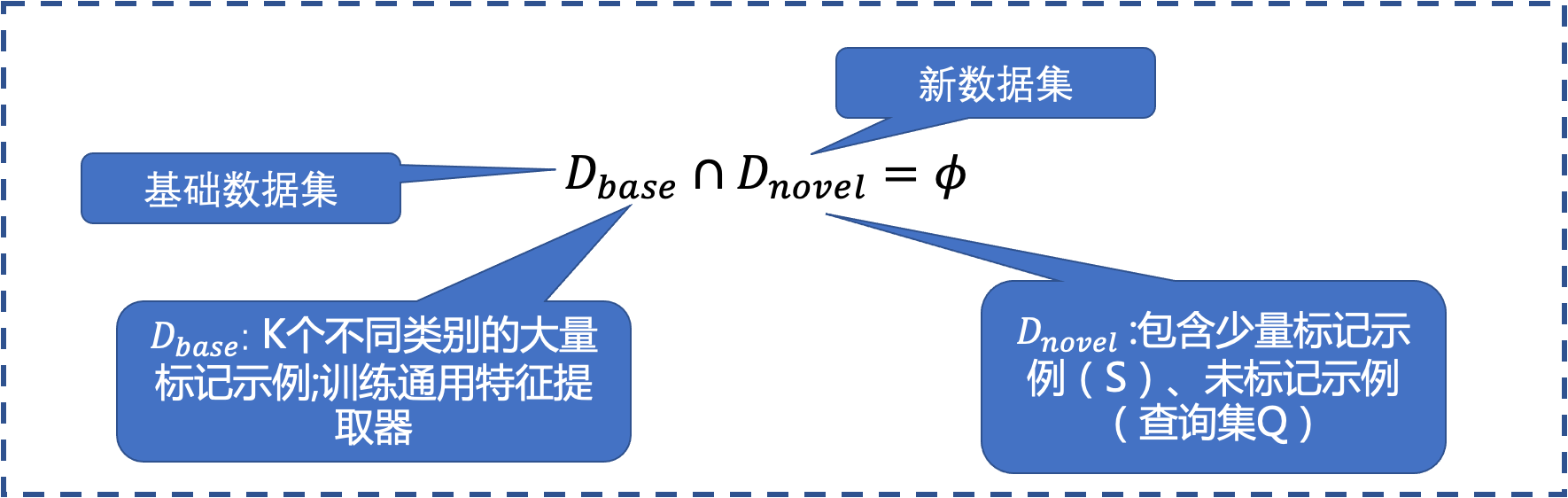
参数含义:
- 新数据集中的类数n(称为n-way)

- 每个类的标记样本数(称为 s-shot)
- 每类未标记样本的数量q类
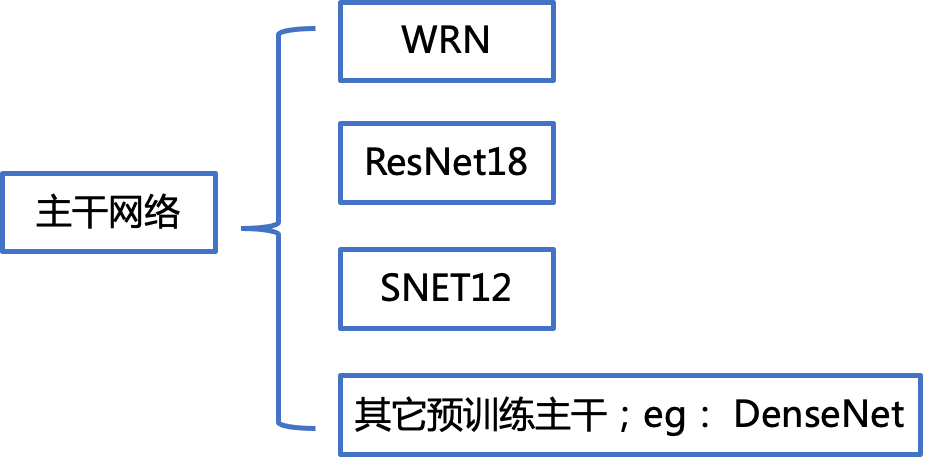
骨干网络
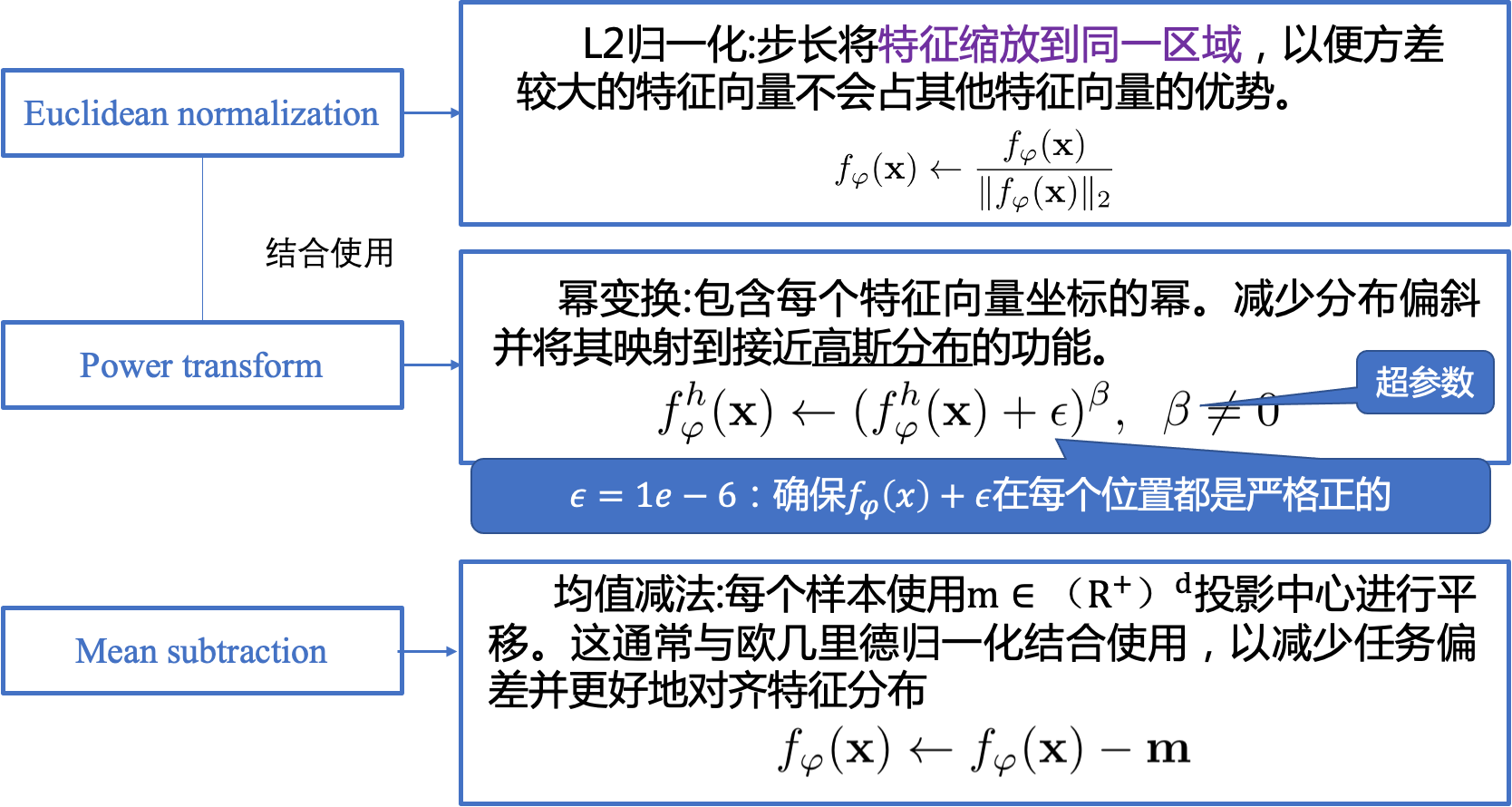
特征预处理
采用不同主干网络、调整训练顺序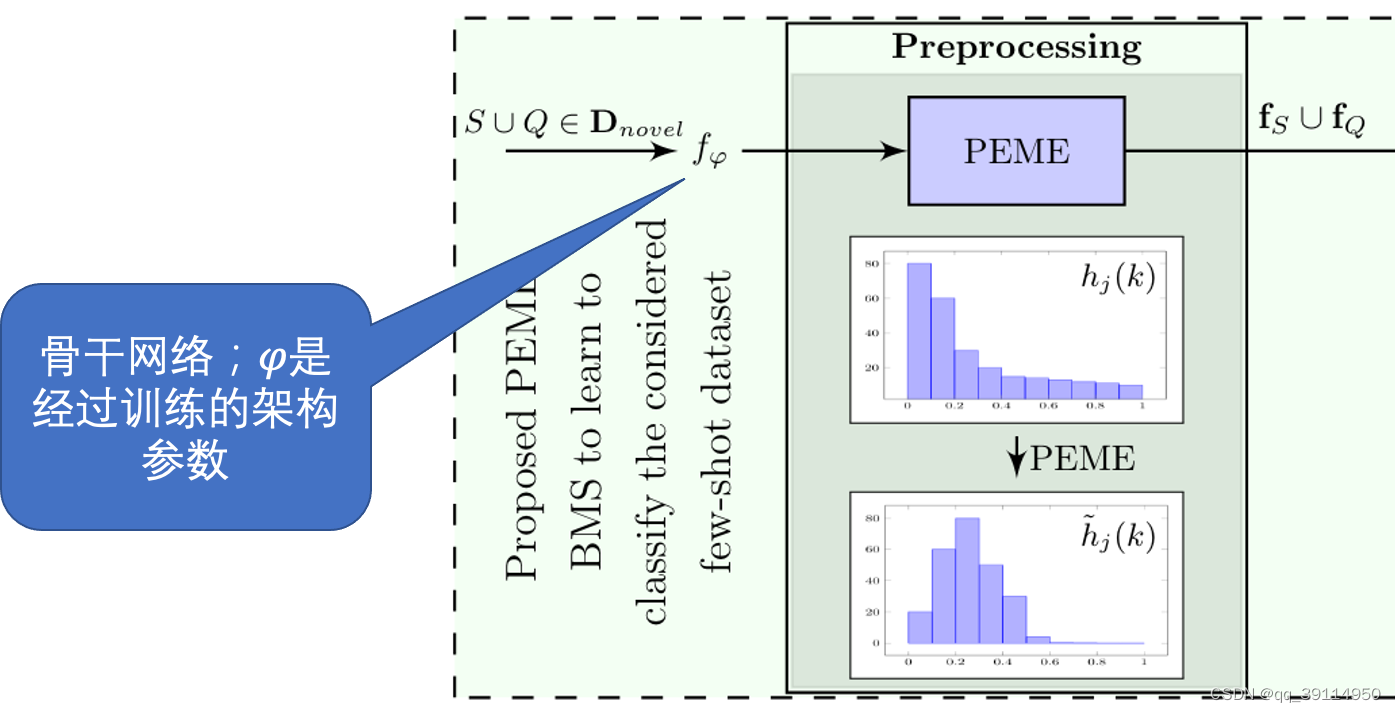
PEME结构介绍
BMS结构介绍 (Boosted Min-size Sinkhorn)
定义一个权重矩阵𝑊,它有𝑛列(即每个类一列)和𝑑行(即每个特征向量维度一行),对于𝑊W中的列𝑗,我们将其表示为类𝑗j的权重参数,通过下面方程计算:
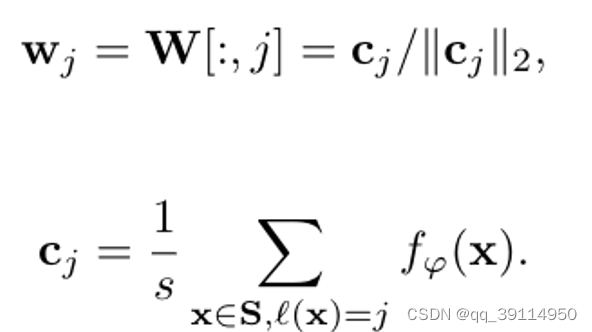
𝑊包含了每个类支持集中特征向量的平均值,然后对每个列进行归一化处理,使∀𝑗,
。

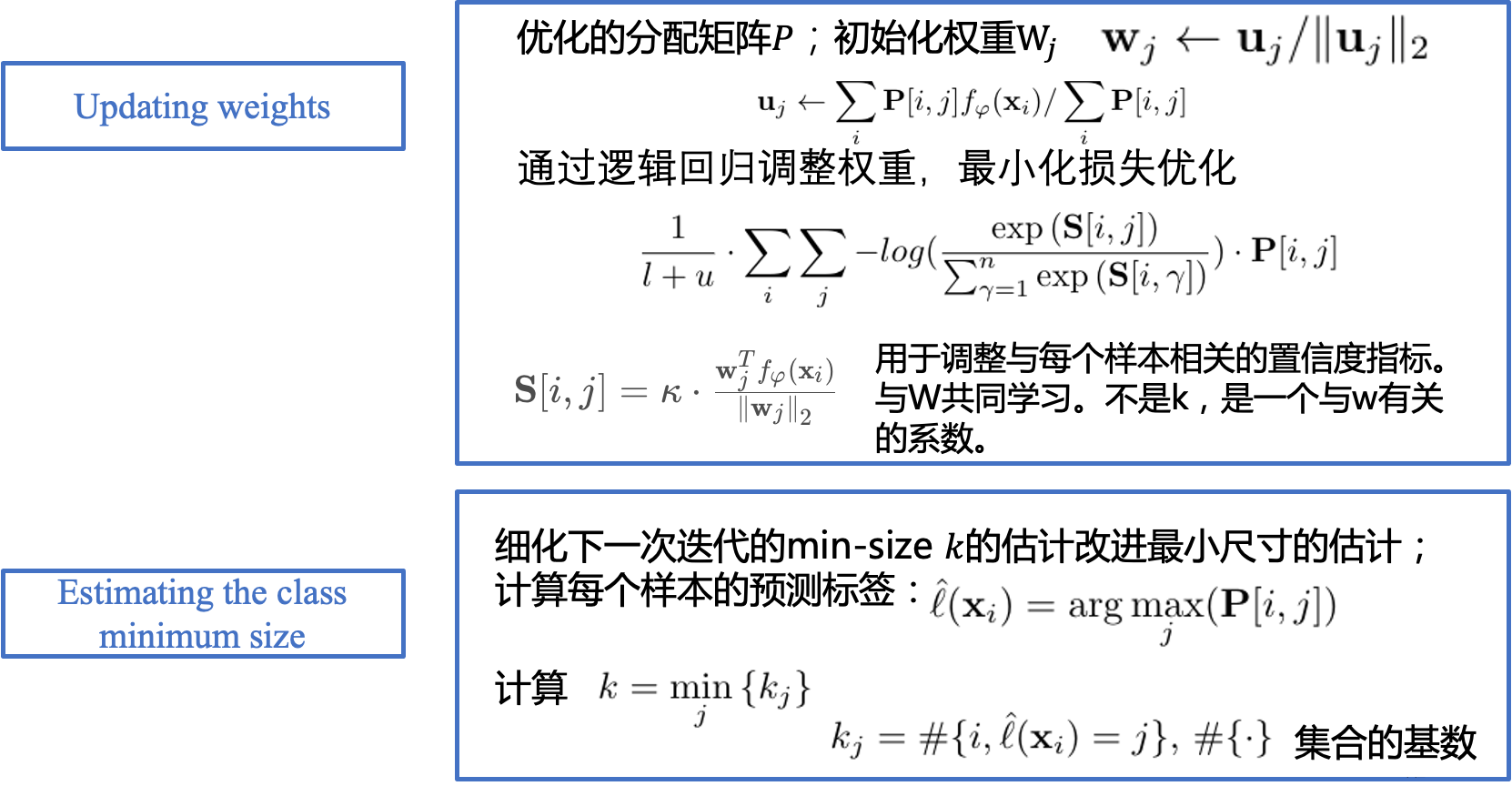

BMS算法

BMS和BMS*区别
















 859
859











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









