









前言
我一开始是学习树模型比较多,众所周知,树模型就知道树模型玩的就是特征,从我个人角度来说,一般是用特征去拟合参数,因此我做比赛的时候一般不怎么调参。工作之前我对推荐系统并不了解,更别说里面的各种精排模型了。
推荐论文的特征呢?
刚开始工作之后会浏览一些业内比较出名的模型,但是看的大多是YouTuBeDNN,DIN,DIEN等,其实我在看这些论文的或者相关解读的时候就很郁闷,特征呢?这类模型着重介绍用户的序列化行为,对特征工程几乎没有任何涉及,特别是这些模型几乎成了主流的时候,一度让我以为只要使用几个id类特征就可以取得十分好的结果,类比的话就是想协同过滤,矩阵分解等方法扩展到了DNN。不过随着了解,还是了解到了很多关于特征的骚操作。阿里20年的CAN也直接说明了这点(如下图所示,左边是特征工程,右边将行为序列使用DIEM)。
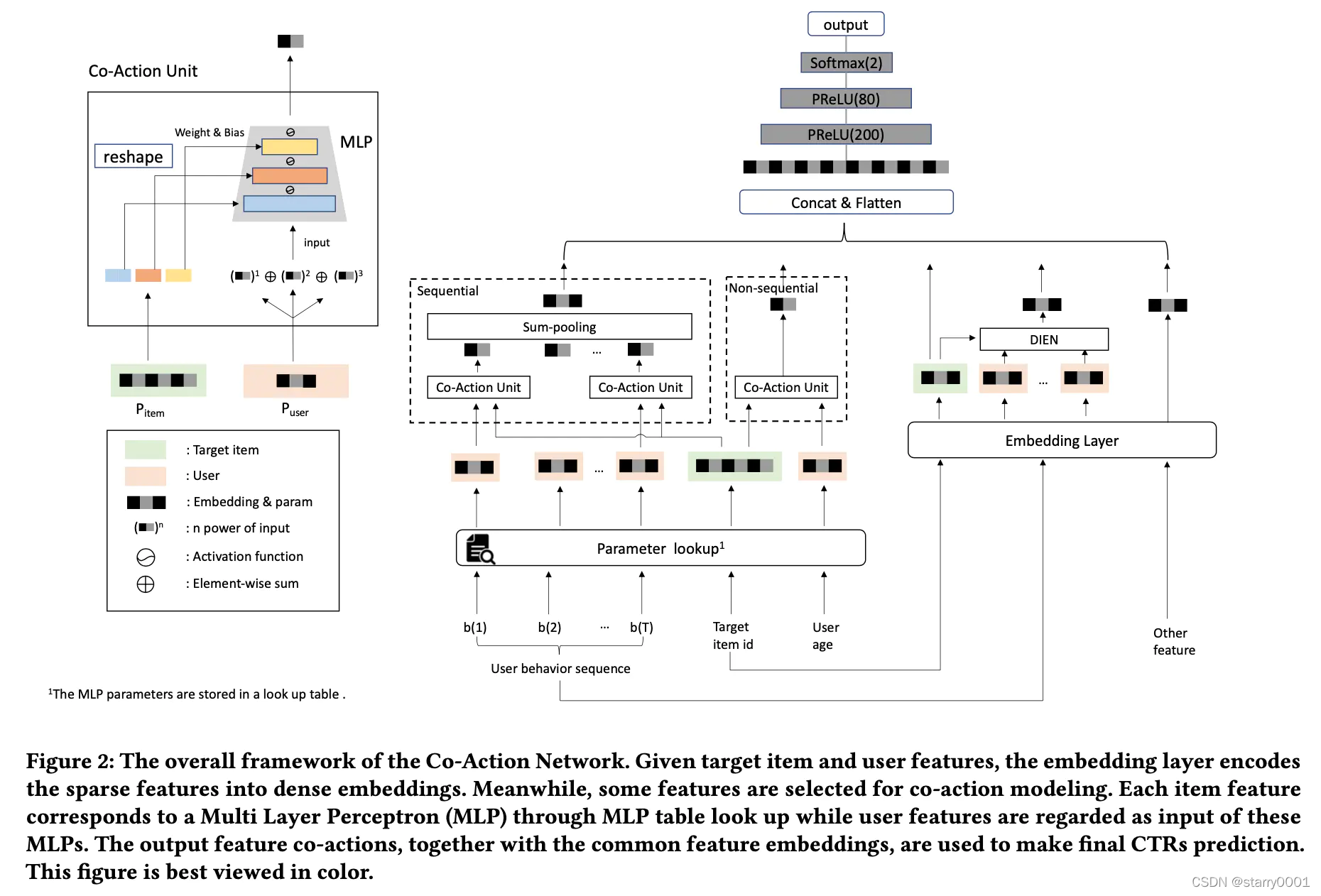
与我们实际操作的不同,大佬们在发表论文的时候其实更喜欢提出一种可推广的范式(毕竟没有哪篇论文会告诉我们它们使用了哪些特征,作为一篇顶会论文,讨论通过增加特征而取得SOTA也很难得到审稿人的青睐),而不是特定某几个强特之间的交叉(树模型就是靠个人精细化的特征工程)。比如向FM那样,不管三七二十一,全部两两交叉,可能真的是大力出奇迹吧。
常见的特征交叉方法以及应用模型
介绍DNN中各种特征交叉的模型之前,先给大家简单介绍一下常见的特征交叉。容我先举一个简单的例子。
假如目前我们的数据是:用户侧:userId,性别,年龄,物品侧:itemId,tag
需要预测的是user是否会购买某个item 。
1:逻辑回归
1:从逻辑回归(FTLR)的角度来说,我们做的交叉特征是特征的共现。比如某一条数据性别为"男",tag为"足球",那进行特征交叉的时候我们的特征是:{“男_足球:”,1}。
此时的特征交叉就是共现。(这是以工程的角度来考虑逻辑回归的,大部分实际的逻辑回归的工程代码都One-Hot然后使用共现交叉,因此工业级的逻辑回归大都是几千万的特征)。
这种特征交叉的实际意义就是:当用户侧和物品侧同时满足某一个要求时对最后的结果的影响。
2:树模型
2:向上面那种逻辑回归的交叉的例子其实树模型中自动就可以帮助我们交叉。那么树模型中特征交叉是怎么做的呢?
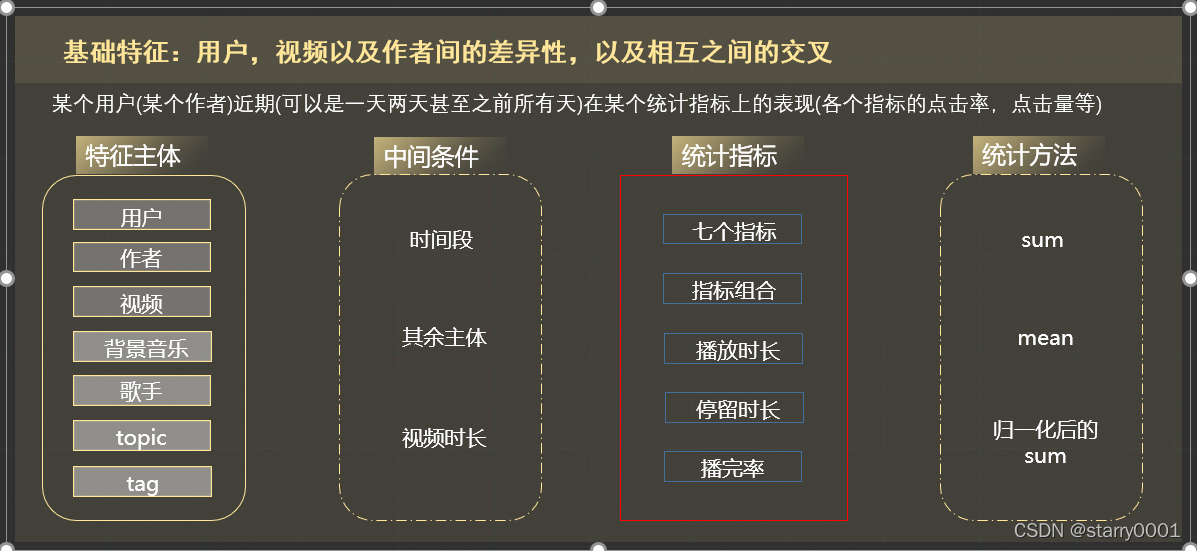
(该图是我21年微信大数据比赛的某张PPT,几乎可以概括树模型所有的统计特征和交叉特征)
在我们的例子中,性别和tag都是特征主体,中间条件是没有的,统计指标是购买。如果要进行特征交叉的话,我们还少了一个东西,那就是统计方法。比如我们做交叉的时候可以是:该性别的用户对该tag的购买次数,购买率,出现次数。不再是逻辑回归中的共现,引入了统计指标和统计方法。
在树模型中我们特征工程的意义是:将一些人为可以统计的信息告诉模型,这样数模型在切割空间的时候可以直接利用先验信息。比如在逻辑回归中我们需要训练之后才知道{”男_足球“}这一对特征对最后指标的作用。但是在树模型中我已经通过统计告诉你了,甚至可以认为树模型中引入了很多简单模型的结果(个人认为)。
当然由于统计信息具有滞后性,并且在工业中很难实时地通过kafka传递几千万个交叉特征,这也是树模型在很多实时性较高的系统中不被青睐的原因。
3:FM模型
3:第三种是embedding后的交叉。这类最典型的就是FM。将性别男进行embedding,然后将tag足球进行embedding。将两个embedding直接相乘,得到的值(一个小数)就是两个特征的交叉值。
这种交叉的的实际意义是:以纯FM模型为例的话,假如性别男和tag足球这一对交叉特征embedding后的值越大,说明这对特征对最后结果的正向的促进作用越大,也就是性别为男的用户购买带有足球tag的商品的可能性越大。
总结
以上就是常见的三种交叉方法,它们也分别适用于不同的模型中,第三类的交叉方法与DNN结合的更加广泛,在推荐系统中的应用更多。当然DNN中还有别的交叉方法,不过并没有这种来的直观,我们直接介绍常见的DNN模型中会设计到。
写在最后
该系列的文章我主要想好好回顾一下推荐系统DNN中特征交叉的一些方法,之后会加入DeppFM,DCN,DCNV2,PNN,xDeepFM,CAN等,希望与各位大佬一起思考下,各种范式的方法。或者给准备学习推荐系统的各位朋友做一个小的科普。















 7468
7468











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









