







 DCN模型结合了DNN和特征交叉的优势,自动学习有限阶的特征交叉,无需人工特征工程,计算代价低。通过cross网络和deep网络并行处理,实现了特征的高效交叉和高阶非线性特征学习。
DCN模型结合了DNN和特征交叉的优势,自动学习有限阶的特征交叉,无需人工特征工程,计算代价低。通过cross网络和deep网络并行处理,实现了特征的高效交叉和高阶非线性特征学习。
0.思考
DNN网络对特征进行不断的抽象,获得更高阶的特征,这个跟特征交叉不太一样。为什么呐?我理解更高阶特征表示为描述同一个东西的共性,看山是山的样子;特征交叉表示为特征A且特征B的时候,会产生什么样的效果,多种因素组合起来,刻画对象。DNN捕捉非线性高阶特征,特征交叉捕捉有限阶特征组合。
那么存在一个问题,特征交叉时,会出现某一个特征为0的情况,这时交叉项得到的组合特征也是0,怎么办?
对于这个问题的解决,有FM,学习每一维特征的隐向量,即使在历史行为中,这个特征没有出现,即为0,但,依然可以学出一个向量来表示这个特征,那么在后续线上遇见这种行为了,便可以参与计算,精准预测。
目的:
通过网络的形式进行特征交叉。
优点:
WDL中,wide侧的交叉组合特征依然需要依靠hand-craft来完成。而DCN能对sparse和dense的输入自动学习特征交叉,可以有效地捕获有限阶(bounded degrees)上的有效特征交叉,无需人工特征工程或暴力搜索(exhaustive searching),并且计算代价较低。
DCN主要有以下几点贡献:
- 提出一种新型的交叉网络结构,可以用来提取交叉组合特征,并不需要人为设计的特征工程;
- 这种网络结构足够简单同时也很有效,可以获得随网络层数增加而增加的多项式阶(polynomial degree)交叉特征;
- 十分节约内存(依赖于正确地实现),并且易于使用;
- 实验结果表明,DCN相比于其他模型有更出色的效果,与DNN模型相比,较少的参数却取得了较好的效果。
1.网络结构
DCN模型以一个嵌入和堆叠层(embedding and stacking layer)开始,接着并列连一个cross network和一个deep network,接着通过一个combination layer将两个network的输出进行组合。网络结构如下图所示:
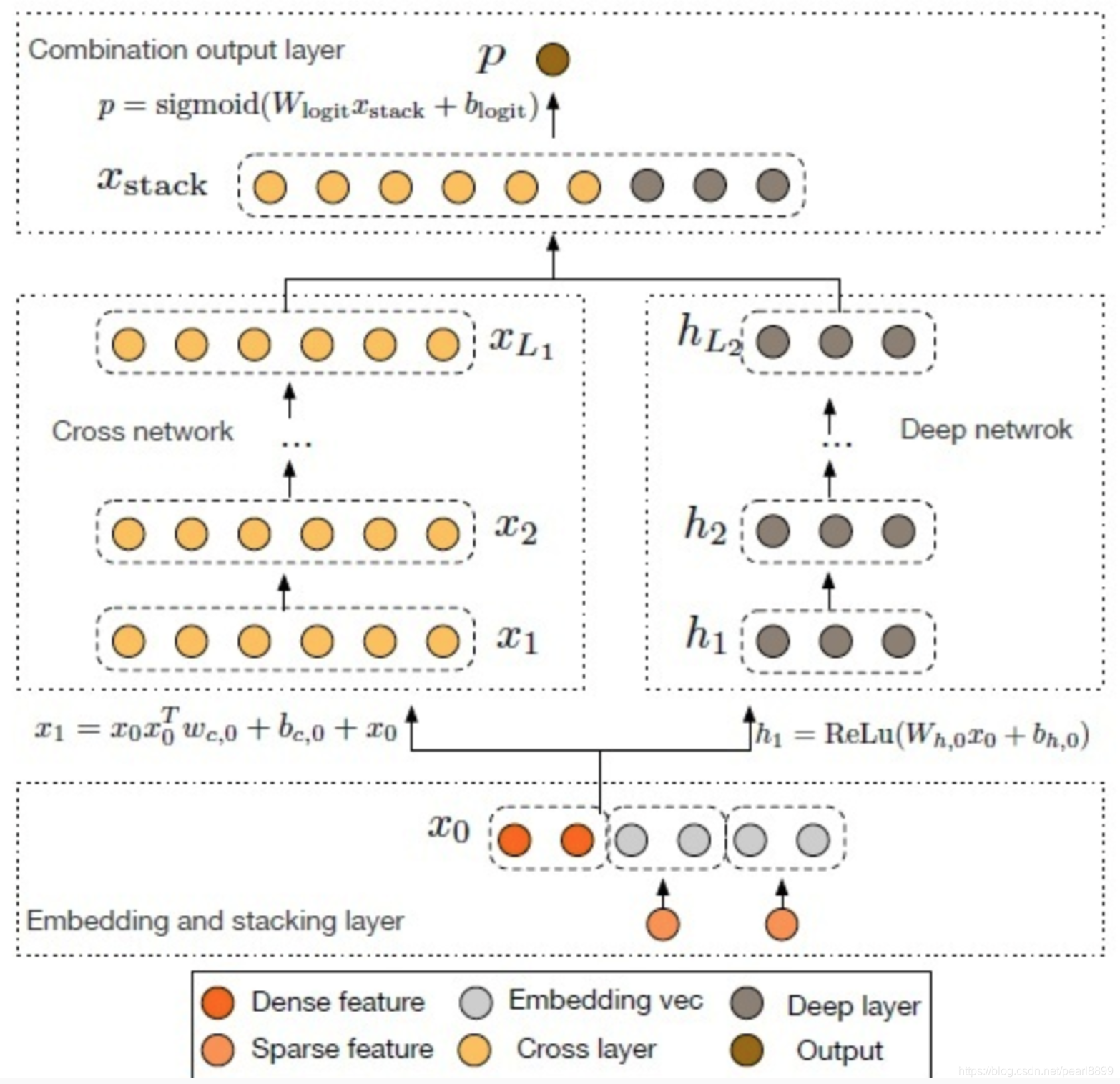
cross网络
在完成一个特征交叉f后,每个cross layer会将它的输入加回去,对应的mapping function F ,刚好等于残差xl+1 - 想xl ,这里借鉴了残差网络的思想。

特征的高阶交叉(high-degree interaction):cross network的独特结构使得交叉特征的阶(the degress of cross features)随着layer的深度而增长。
一个cross network的时间和空间复杂度对于输入维度是线性关系。因而,比起它的deep部分,一个cross network引入的复杂度微不足道,DCN的整体复杂度与传统的DNN在同一水平线上。如此高效(efficiency)是受益于 X0 * Xl^T (体现特征交叉的地方)的rank-one特性(两个向量的叉积),它可以使我们生成所有的交叉项,无需计算或存储整个matrix。
deep网络
交叉网络的参数数目少,从而限制了模型的能力(capacity)。为了捕获高阶非线性交叉,我们平行引入了一个深度网络。
深度网络就是一个全连接的前馈神经网络,每个深度层具有如下公式:

Combination Layer
最后,将两个network的输出进行拼接(concatenate),然后将该拼接向量(concatenated vector)喂给一个标准的逻辑回归模型。
类似于WDL模型,我们对两个network进行jointly train,在训练期间,每个独立的network会察觉到另一个。下面给出整个模型的实现代码:
![]()
2.代码
cross网络代码
根据cross层的计算逻辑,有一个优化的代码形式,先计算Xl ^T* W = C,再计算X0 *C,计算量大大降低。X0* Xl是一个矩阵,而Xl ^T* W是一个标量。
def cross_layer2(x0, x, name):
with tf.variable_scope(name):
input_dim = x0.get_shape().as_list()[1]
w = tf.get_variable("weight", [input_dim], initializer=tf.truncated_normal_initializer(stddev=0.01))
b = tf.get_variable("bias", [input_dim], initializer=tf.truncated_normal_initializer(stddev=0.01))
xb = tf.tensordot(tf.reshape(x, [-1, 1, input_dim]), w, 1)
return x0 * xb + b + x
def build_cross_layers(x0, params):
num_layers = params['num_cross_layers']
x = x0
for i in range(num_layers):
x = cross_layer2(x0, x, 'cross_{}'.format(i))
return xdeep网络的代码:
def build_deep_layers(x0, params):
# Build the hidden layers, sized according to the 'hidden_units' param.
net = x0
for units in params['hidden_units']:
net = tf.layers.dense(net, units=units, activation=tf.nn.relu)
return netCombination Layer
def dcn_model_fn(features, labels, mode, params):
x0 = tf.feature_column.input_layer(features, params['feature_columns'])
last_deep_layer = build_deep_layers(x0, params)
last_cross_layer = build_cross_layers(x0, params)
last_layer = tf.concat([last_cross_layer, last_deep_layer], 1)
my_head = tf.contrib.estimator.binary_classification_head(thresholds=[0.5])
logits = tf.layers.dense(last_layer, units=my_head.logits_dimension)
optimizer = tf.train.AdagradOptimizer(learning_rate=params['learning_rate'])
return my_head.create_estimator_spec(
features=features,
mode=mode,
labels=labels,
logits=logits,
train_op_fn=lambda loss: optimizer.minimize(loss, global_step=tf.train.get_global_step())
)3.thinking
这里的cross方法和FM的交叉组合方式有没有联系?或者说有何异同?
论文中,3.2小结简单有分析,两者思想近似,DCN是FM的一个升级版本。
一、在参数上,FM的xixj交叉特征取决于<vi, vj>。DCN是参数共享的,这样虽然有点慢,但会产生产生一些意想不到的特征组合方式,对噪声更加鲁棒。
二、交叉的特征维度上,FM只能交叉2维,DCN可以对全部特征进行交叉。
论文精读记录
收获:
DCN和FM和DNN在做特征交叉上有何区别?
FM是二阶特征交叉,DNN是特征的高阶交叉,非线性组合,是隐式的组合;DCN是有限阶的特征交叉组合,是显示的组合;随着特征交叉阶数的增加,参数线性增加;FM如果更高阶的交叉,参数会指数增长。
abstract:
特征工程是模型预测的关键,特征工程需要人工处理。DNN可以学到特征的交叉,得到隐式的结果(interactions implicitly ),对学习全部类型的交叉特征(cross features )不高效。DCN网络保留了DNN的优势,对特征交叉也提供了更加便捷的方式。显式的在每层使用特征交叉,不需要求人工特征工程。给DNN增加额外的开销几乎可以忽略不计。
Cross network由多层组成,交叉阶数随着深度增加而增加。DNN跟cross net相比,需要更多的参数,不能像cross net那样显式的交叉特征。
FM将稀疏特征映射到低维稠密向量中,通过内积的形式进行特征交叉。
FFm,允许一个特征学习出几个向量,每一个向量跟一个field有关。
FM和FFM这种浅层结构限制了他们的表达能力,一些工作将二者推向更高阶,但是一个受限的方面是参数梳理较大,对计算性能要求较高。
DNN可以学习出抽象的高阶交互特征(因为embeding向量和非线性激活方程)。deep crossing借鉴了残差网络,实现了通过堆叠方式,自动学习交叉特征。
DNN强在它的表示能力。在足够的隐层单元下,DNN可以拟合任意的方程。在实践中,也证明了DNN在一定参数下,达到不错的效果。一个关键因素是One key reason is that most func- tions of practical interest are not arbitrary.
另一个留存的问题是DNN是否高效的,在表示practical interest的方程时。kaggle比赛中,手动交叉的一些方案是低阶的,显式且高效;DNN学到的特征,是隐式的,高阶非线性的,这就需要设计一个模型,它有能力学习一些有界阶数的交互特征,表现出显式组合(bounded-degree feature interactions more efficiently and explicitly than a universal DNN ).
Wide and deep模型,有特征交叉的那么一点意思,手动交叉特征作为线性模型的输入,联合训练线性和dnn模型。不足的地方是:过于依赖特征交叉的方式,交叉特征的方式不高效。
Main contribution
对稀疏和稠密的输入,自动学习特征。高效捕捉有限阶的交互特征,和高阶非线性交互。不需要人工特征工程或者遍历搜索,计算代价小。
本文的主要贡献:
1.提出了一种显示的特征交叉网络,高效的学习有限阶交叉特征,无需人工交叉和遍历搜索。
2.交叉网络是高效的。经过设计,随着层数的增加多项式的阶数也在增加,每层参数不同。
3.交叉网络记忆高效,易于实现。
4.DCN比DNN有更小的log loss,二者参数接近。
2 DEEP & CROSS NETWORK (DCN)
DCN结构:开始于embeding和stacking层, 随后是并行的cross 和deep 层,然后combination 层,输出结果。
2.1 Embedding and Stacking Layer
类别特征进行onthot编码后,维度太大,将其embedding为稠密向量。
映射的权重矩阵Wembed ,随着网络不断的优化。
将embedding的向量跟dense特征stack起来,就是concat起来,变成一个向量作为模型的输入。
2.2 Cross Network
Cross network的主要思想是:用高效的方式,进行显示的特征交叉。
每一层都在拟合当前层跟前一层的残差。
复杂度分析:d* L*2,d是输入的维度,L是cross的层。复杂度是线性的。相比dnn,cross的复杂度可以忽略不计。得益于X0*Xl_T,是一维,不用计算存储矩阵,又能产生全部的交叉项目。
2.3 Deep Network
Fnn,激活函数是relu。
复杂度分析:d*M+ M + (M^2 + M) * (Ld - 1)
2.4 Combination Layer
Concat两个网络的输出,链接为一个向量,将其输入到一个标准的逻辑层logits layer ,输出两个类别的概率。
损失函数仍然是logloss,带上正则项。
3 CROSS NETWORK ANALYSIS
分析下DCN中的crossnet的效率。从三个方面:多项式、FM、efficient projection.
多项式方面:一通证明,说明给一个道理:有多少层,就多少层+1维的特征交叉,比如2层,那么就有三个维度的特征交叉,3层,就有四个维度的特征交叉。哪一维度出现在交叉项中,取决于阿发参数。
FM的泛化:具有FM的灵魂,比FM的结构更深。
模型中的每一个特征的学习,也独立于其他特征。交叉项的权重是对应参数的组合。参数共享可能使得模型学习起来不那么高效,但或许能学到一些意想不到的特征组合,抗造能力更强。相比于FM的高阶形式,crossnet的参数是线性增长,比FM节省参数。
Efficient Projection 高效投影?
每一层,相等于x0和xl的一对映射,维度还是原来输入的维度=x0的维度。x0和xl相乘组合后,会有d^2个,w矩阵需要是[d^2, d]维,将cross之后的结果再映射回到d维。
参考:
1.论文:https://arxiv.org/pdf/1708.05123.pdf
2.https://zhuanlan.zhihu.com/p/43364598
3.代码:https://github.com/yangxudong/deeplearning/blob/master/DCN/deep_cross_network.py

















 3316
3316

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









