







来源
QoE-Based Cooperative Task Offloading with Deep Reinforcement Learning in Mobile Edge Networks
简介
是论文中的一块,原文proposed task offloading mechansim for MENs(mobile edge networks)。由于与VFC有挺多的相通之处,特此学习。
正文
该机制分为三步:
- 任务优先级设立
- 重复任务删除
- 任务安排
Task Priority Assignment
本文使用的是一种多级反馈任务队列,分为高优先级,中优先级,和低优先级。若一个任务有hard deadline并且对实时性要求较高,则优先级最高;若是soft deadline,则中等;否则,低优先级。一般来说,高优先级的任务是被用户单元或者边缘服务器完成,中优先级被边缘服务器或云主机完成,低优先级任务大多对资源和CPU有严格要求,因此发送到云主机。
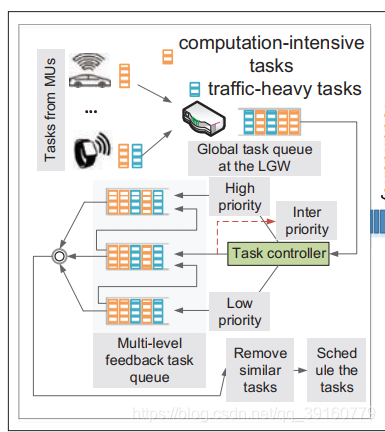
Redundant Task Elimination
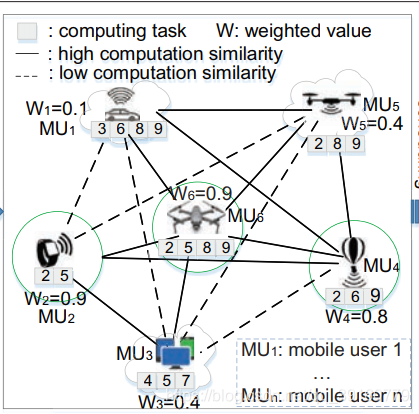
不同的用户连接在同一个设备上的时候,可能会使用同一类型的应用,从而导致类似且冗余的任务。如下图所示,可以构建一个基于任务相似性的虚拟函数图。如果两个用户之间的任务相似度高于某个给定门槛,就用实线连接,否则用虚线。这样,就能形成一些“域”(domain),我们的目标是最小化“域”之间的任务相似度。此外,还有权值w,代表了每一个用户在每个域内的交流和计算能力,这个权值只有在用户离开或进入域时才发生改变。所有用户都有权值w,我们就能选出最佳的用户了。
这些域被分为两类。一类域中拥有充足的资源,且相互的任务集合有低相似度。这一类的域可以快速地完成内部任务,因为同一任务只需要执行一次,多个域可以并行地完成所有任务。另一类域的计算资源不足,因此需要将任务发送给边缘服务器、云主机、又或者第一类域。
按照这种方法消除冗余任务,能充分利用以往的闲置单元,提升系统响应速度。
Task Scheduling
消除冗余任务之后,服务器就能快速调度任务,降低系统时延,这一步叫作任务调度。需要强调的是,我们这里所调度的任务只是有hard deadline的高优先级任务,以及可以被分派给边缘服务器的中优先级任务。如下图所示,同一域中的用户和边缘服务器相互合作,在基于DRL算法的基础上无缝完成任务调度目标。

调度步骤大概如下所示:
- 调度任务之前,各个域选出一个用户领导者。
- 领导者收集其他用户的需求,收集信息。
- 边缘服务器和领导者根据容量和负载,接受或拒绝用户需求,并生成每个域的匹配列表(matching list)。
- 通知各用户任务结果,并重复第二步,直到所有用户都至少被划分到一张匹配列表上。
总结
大概就是这样,模型值得参考。

















 1231
1231

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









